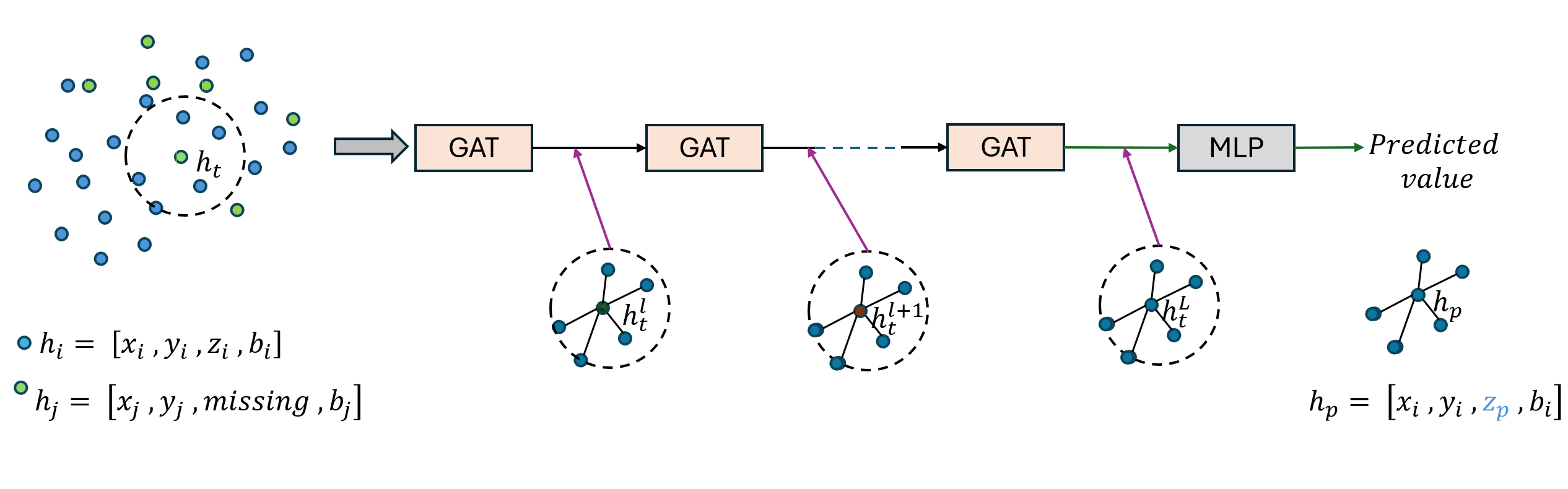
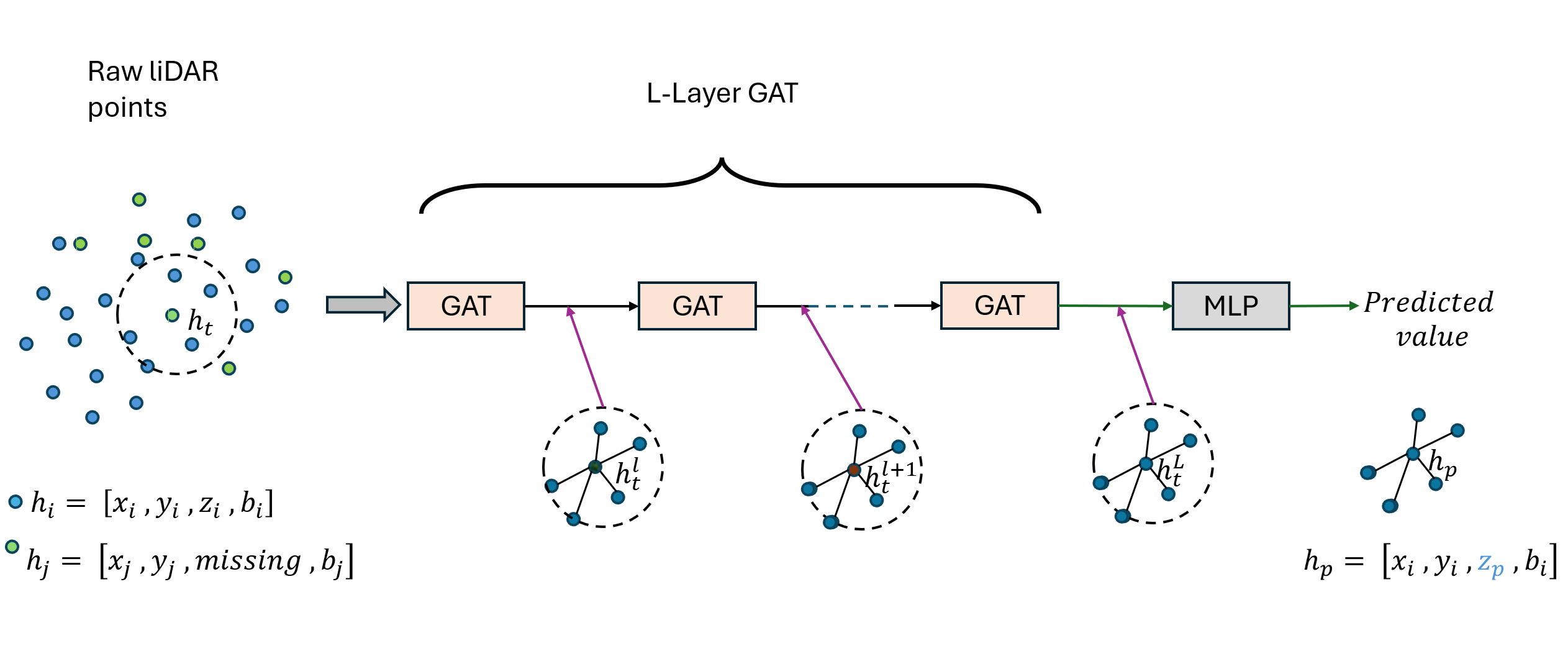
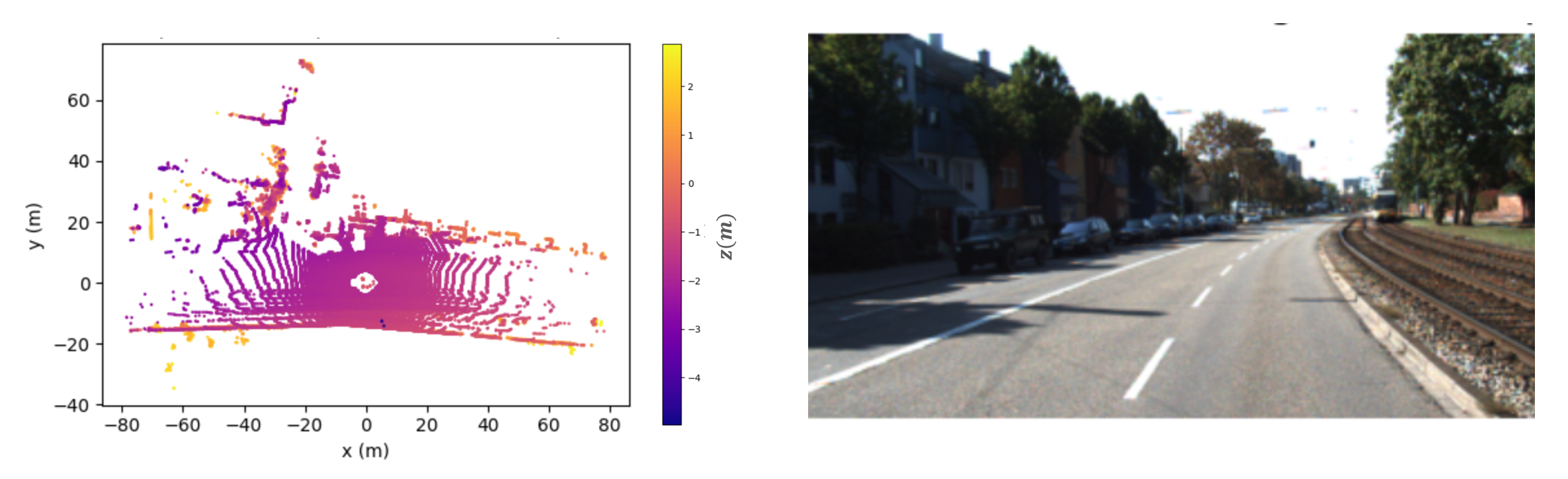
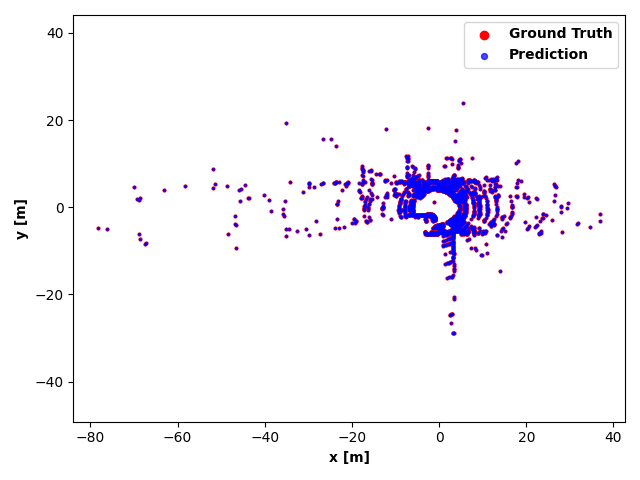
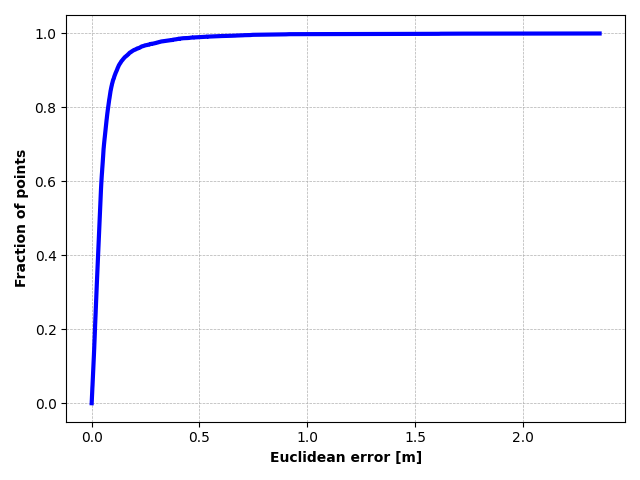
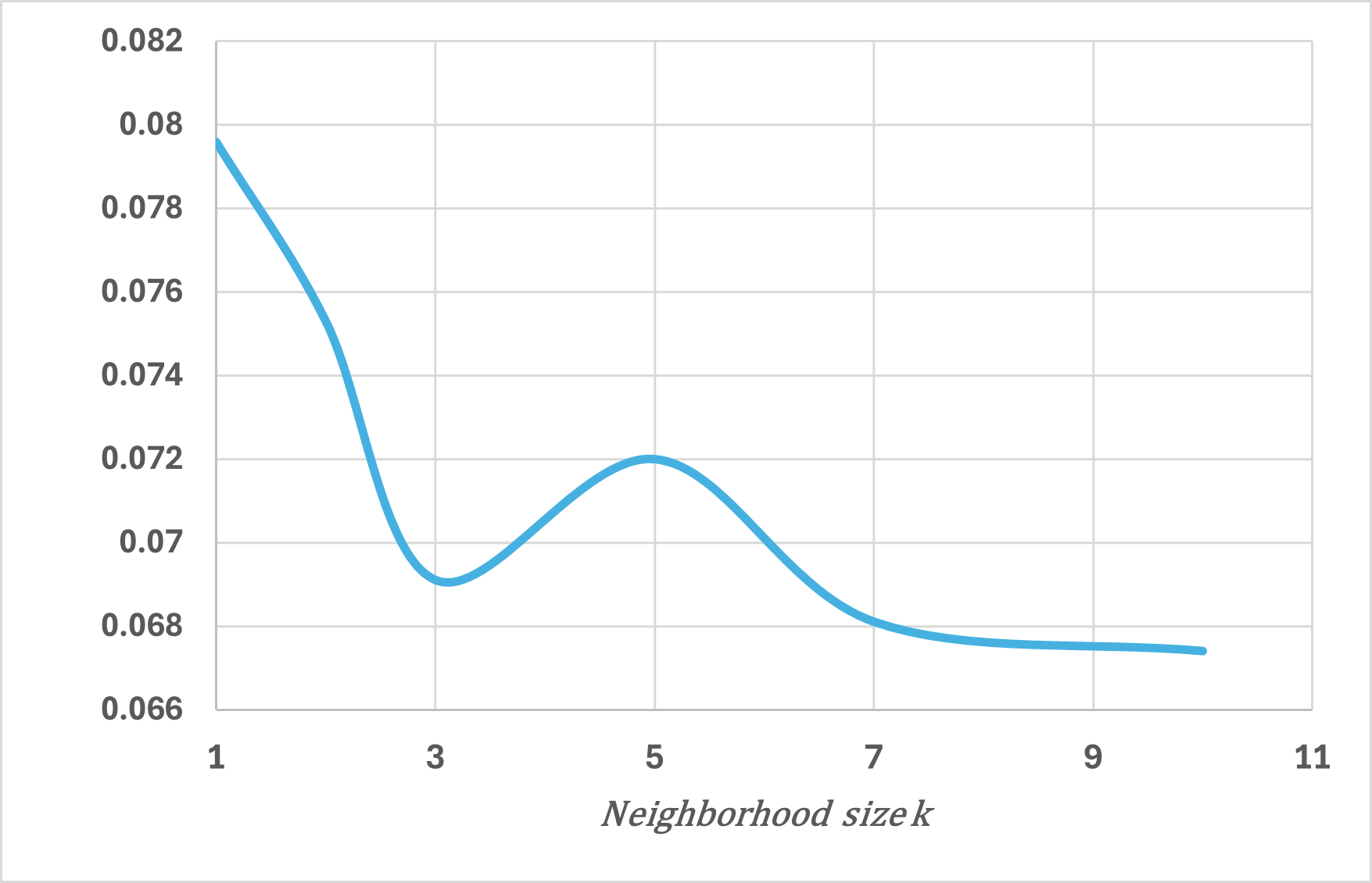
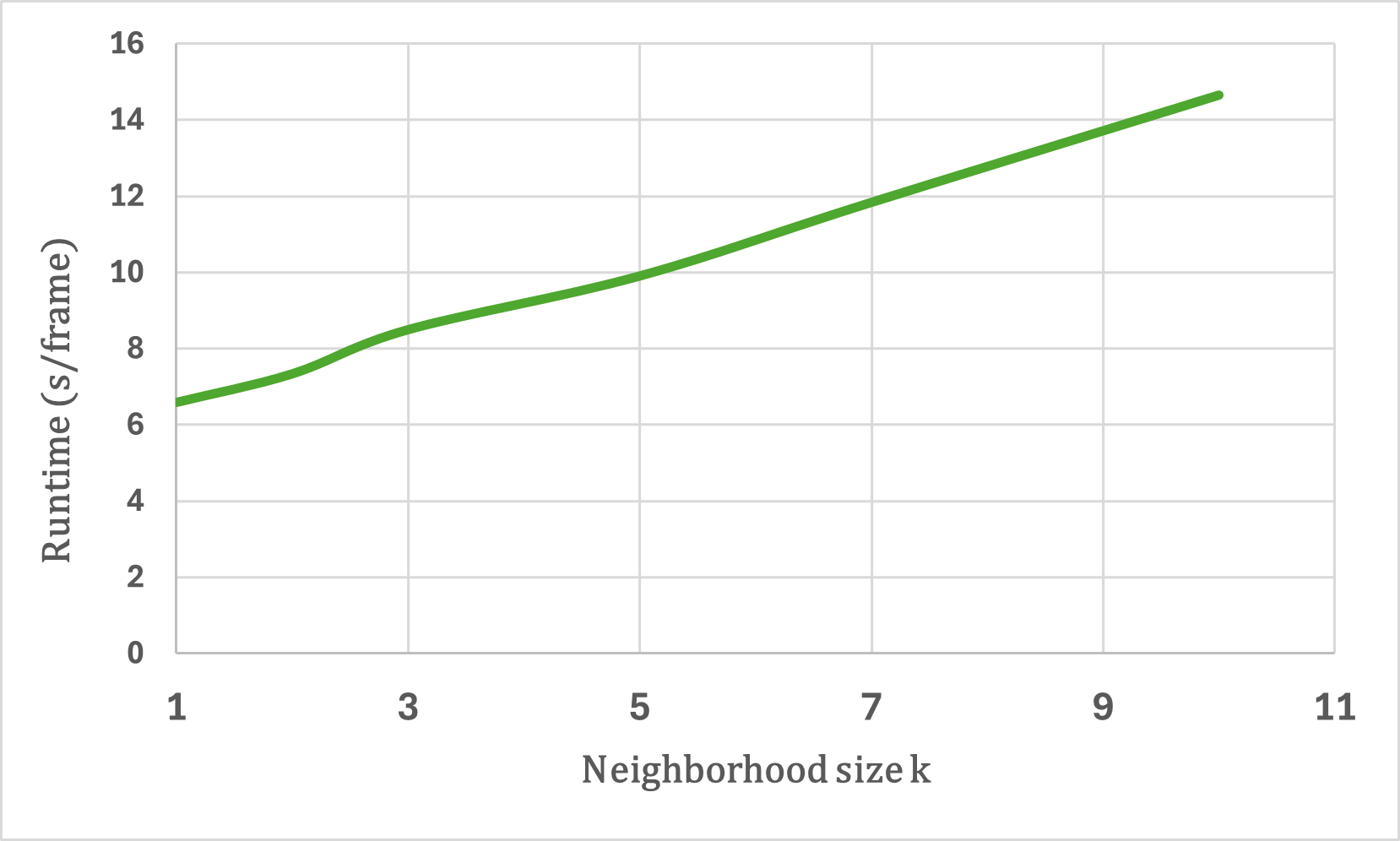
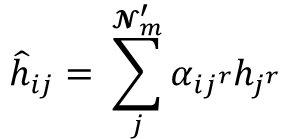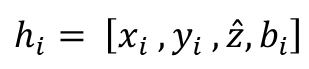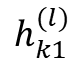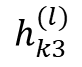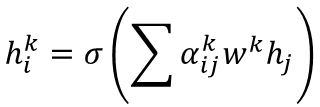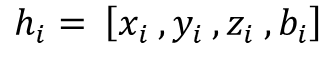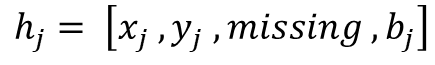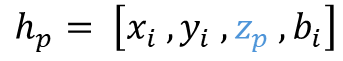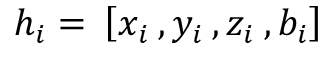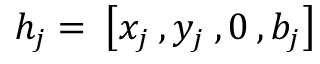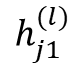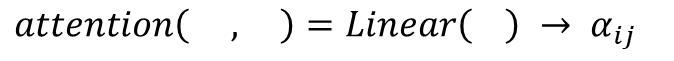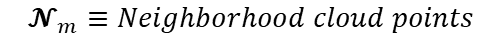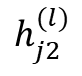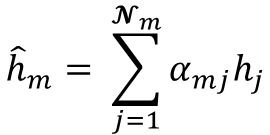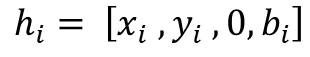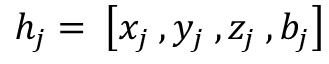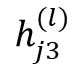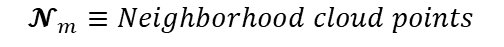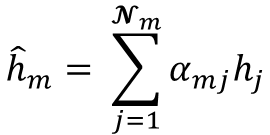Vertical beam dropout in spinning LiDAR sensors triggered by hardware aging, dust, snow, fog, or bright reflections removes entire vertical slices from the point cloud and severely degrades 3D perception in autonomous vehicles. This paper proposes a Graph Attention Network (GAT)-based framework that reconstructs these missing vertical channels using only the current LiDAR frame, with no camera images or temporal information required. Each LiDAR sweep is represented as an unstructured spatial graph: points are nodes and edges connect nearby points while preserving the original beam-index ordering. A multi-layer GAT learns adaptive attention weights over local geometric neighborhoods and directly regresses the missing elevation (z) values at dropout locations. Trained and evaluated on 1,065 raw KITTI sequences with simulated channel dropout, the method achieves an average height RMSE of 11.67 cm, with 87.98% of reconstructed points falling within a 10 cm error threshold. Inference takes 14.65 seconds per frame on a single GPU, and reconstruction quality remains stable for different neighborhood sizes k. These results show that a pure graph attention model operating solely on raw point-cloud geometry can effectively recover dropped vertical beams under realistic sensor degradation.
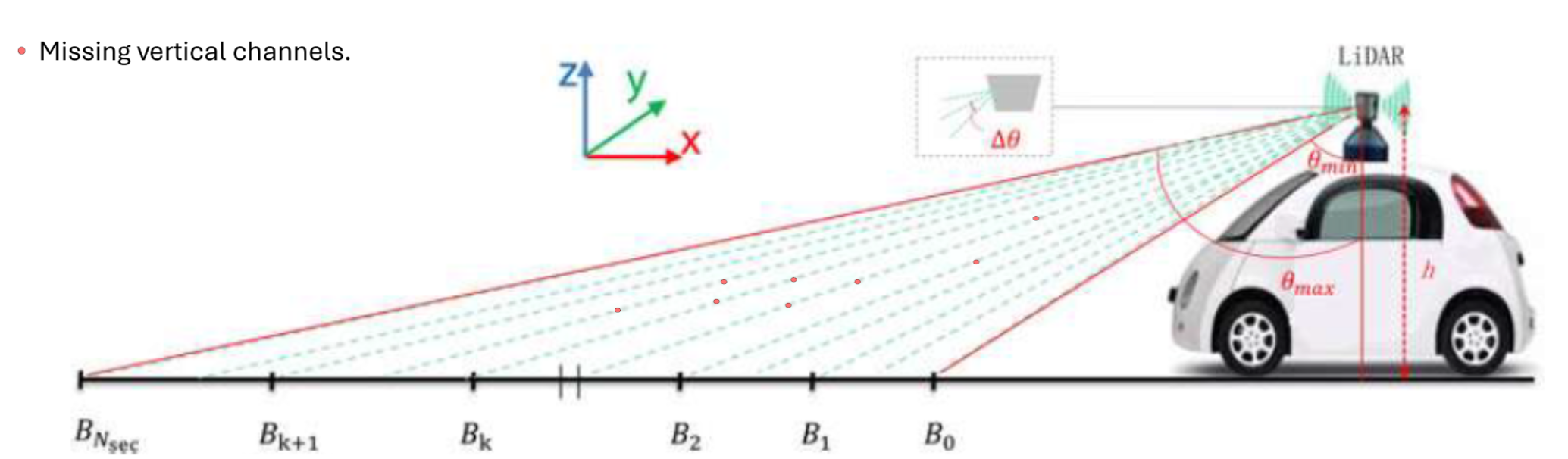
LiDAR sensing has become fundamental to modern autonomous driving systems, providing dense 3D measurements that support obstacle detection, ground estimation, and overall scene understanding [1], [2]. Rotating multi-beam LiDAR units generate a structured point cloud through a fixed set of vertical channels, each contributing a scan line as the sensor sweeps the environment. The integrity of these vertical beams is critical: they encode the elevation structure of the scene and determine how reliably the system can distinguish drivable surfaces from obstacles.
In practice, however, LiDAR acquisitions are often incomplete. Vertical beam dropout-caused by hardware aging, calibration drift, reflective materials, fog, dust, or snow-removes entire slices of the scan and produces discontinuities in the elevation profile [3]. Several studies have documented how missing or corrupted beams degrade downstream perception, including object detection, depth reasoning, and free-space estimation [4], [5]. The impact is especially pronounced in the vertical dimension, where height information (z or r sin ϕ) plays a central role in maintaining geometric consistency and identifying obstacles around the vehicle [6], [7].
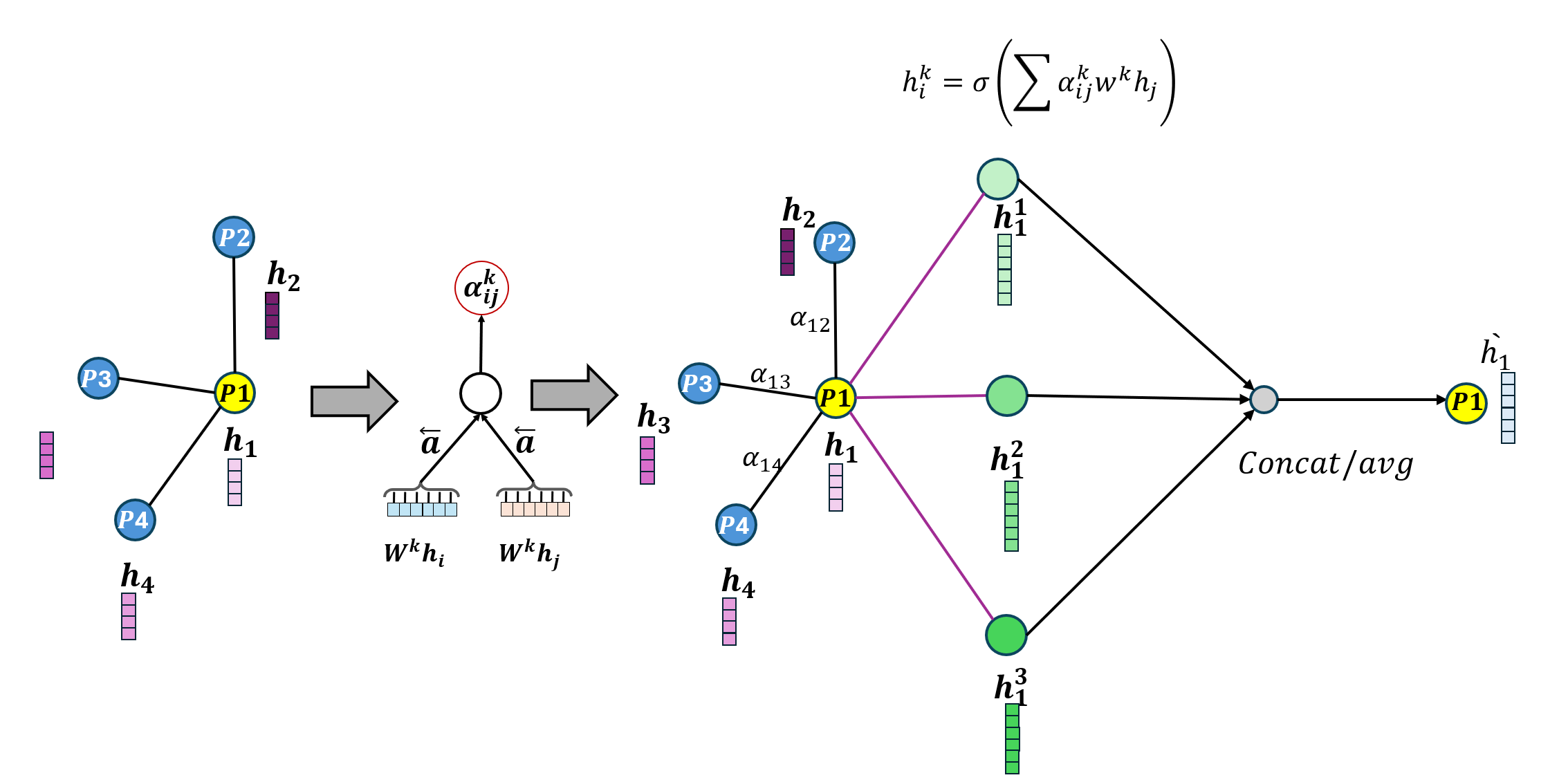
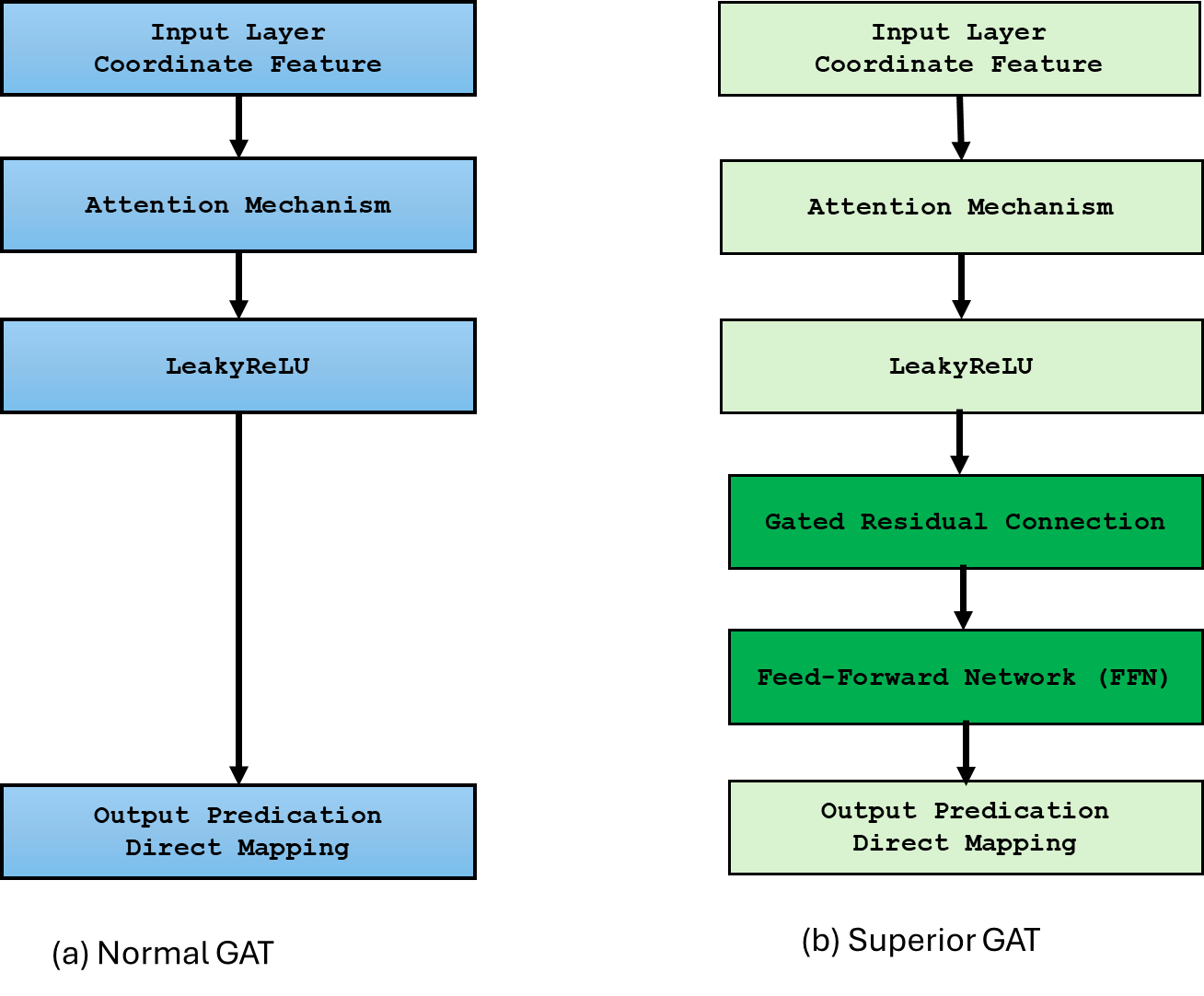
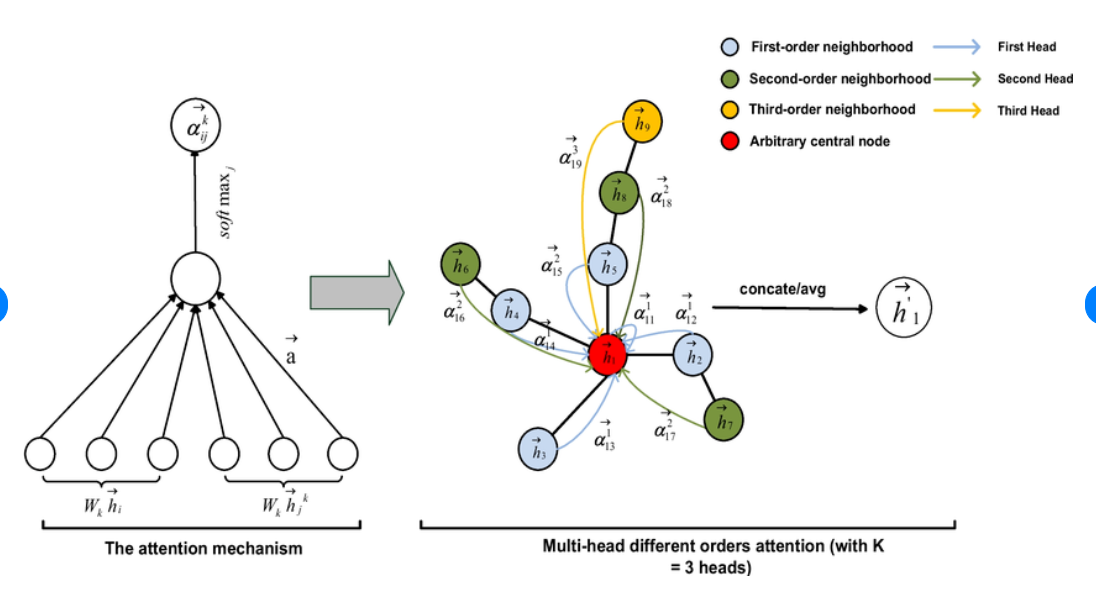
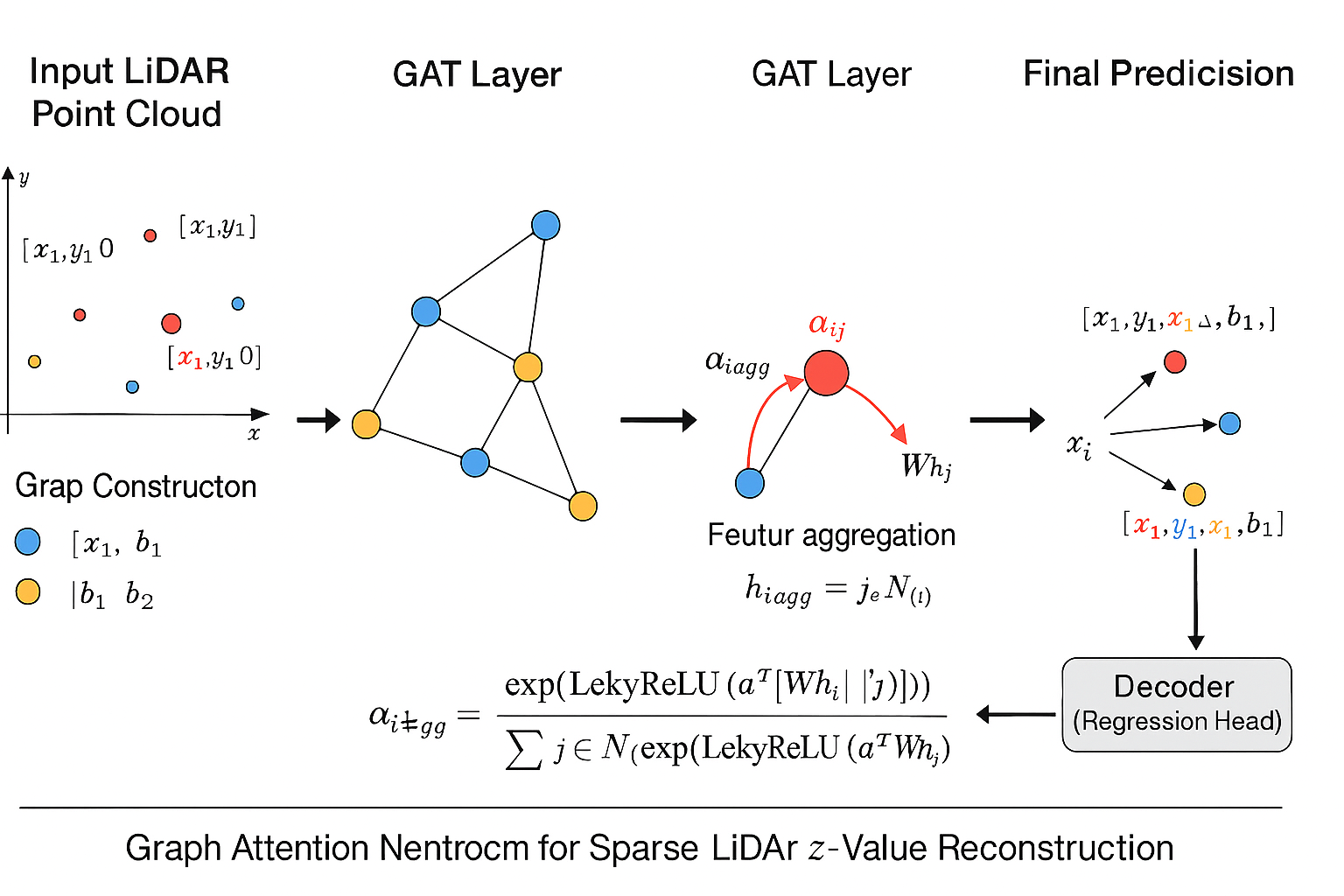
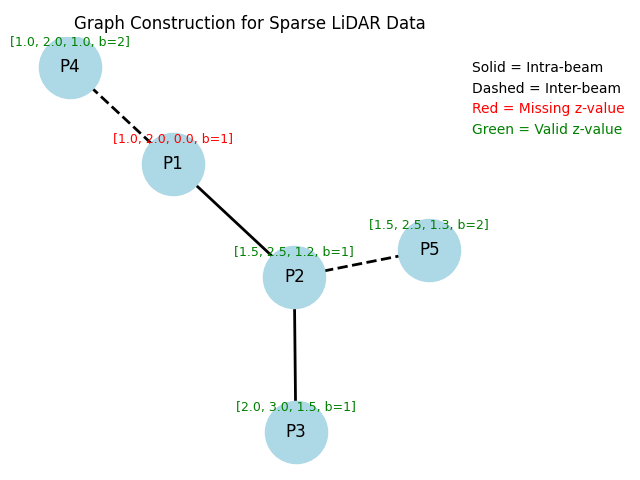
Most existing LiDAR-processing pipelines are designed to operate on whatever points the sensor returns, focusing primarily on classification or segmentation rather than repairing missing data. Approaches that attempt to fill gaps typically rely on voxel-based CNNs or interpolation methods, which struggle to capture the irregular, non-uniform structure of real scans and often overlook the relationships between adjacent beams [8]. At the same time, recent developments in graph neural networks (GNNs) have shown strong performance on LiDAR tasks that benefit from modeling spatial neighborhoods and beam-index relationships [9]- [11]. Within this family, Graph Attention Networks (GATs) [12] are particularly well suited because they adaptively weight contributions from neighboring points, allowing the model to emphasize the most informative geometric cues. This work addresses the specific challenge of reconstructing missing vertical beams in sparse LiDAR scans. We represent each LiDAR sweep as an unstructured spatial graph in which points are nodes and edges connect local geometric neighbors. Instead of relying on camera images or temporal aggregation, the problem is formulated entirely within a single LiDAR frame. The goal is to recover the missing elevation values at dropout locations by leveraging the structural continuity that exists across adjacent beams and along each scan line.
To accomplish this, we develop a multi-layer GAT framework tailored to beam reconstruction. By aggregating information through attention-based message passing, the network learns how height varies across local neighborhoods and how this variation reflects the underlying geometry of the scene. This enables the model to restore the vertical structure in a manner that preserves both fine-grained detail and global consistency. The proposed formulation offers a purely LiDARbased solution capable of reconstructing vertical dropout in environments where camera data is unavailable or unreliable.
The remainder of this paper is organized as follows. Section II reviews related work on LiDAR degradation, reconstruction, and graph-based processing. Section III presents the proposed graph formulation and GAT reconstruction method. Section IV reports experimental results on raw KITTI sequences, and Section V concludes the paper. Early studies on LiDAR perception have shown that the spatial structure of point clouds is highly sensitive to sparsity and vertical sampling density. The survey in [1] highlights how reduced vertical resolution directly weakens 3D object localization, particularly for tall or partially occluded objects. Similarly, the authors in [5] demonstrate that changes in beam distribution measurably affect vehicle detection performance, reinforcing the importance of maintaining consistent vertical coverage. The work in [6] further shows that the vertical arrangement of points carries strong geometric cues used in modern detectors, while [7] links vertical geometry to ground-object separation and obstacle recognition. Together, these studies make clear that missing vertical beams can degrade downstream perception reliability, especially in autonomous driving scenarios.
Several approaches have attempted to compensate for sparse LiDAR data by generating denser or more structured point clouds. The GLiDR model introduced in [9] employs a topologically regularized graph generative network to recover missing structure, but its objective focuses on global shape consistency rather than restoring beam-level information. The method in [13] enhances 3D detection under limited LiDAR points through learned depth cues and spatial priors, yet it does not explicitly reconstruct dropped LiDAR channels. While these techniques reduce the impact of spar
This content is AI-processed based on open access ArXiv data.