Title: Contiguous Storage of Grid Data for Heterogeneous Computing
ArXiv ID: 2512.11473
Date: 2025-12-12
Authors: ** Fan Gu, Xiangyu Hu (Technical University of Munich, Germany) **
📝 Abstract
Structured Cartesian grids are a fundamental component in numerical simulations. Although these grids facilitate straightforward discretization schemes, their naïve use in sparse domains leads to excessive memory overhead and inefficient computation. Existing frameworks address are primarily optimized for CPU execution and exhibit performance bottlenecks on GPU architectures due to limited parallelism and high memory access latency. This work presents a redesigned storage architecture optimized for GPU compatibility and efficient execution across heterogeneous platforms. By abstracting low-level GPU-specific details and adopting a unified programming model based on SYCL, the proposed data structure enables seamless integration across host and device environments. This architecture simplifies GPU programming for end-users while improving scalability and portability in sparse-grid and gird-particle coupling numerical simulations.
💡 Deep Analysis
📄 Full Content
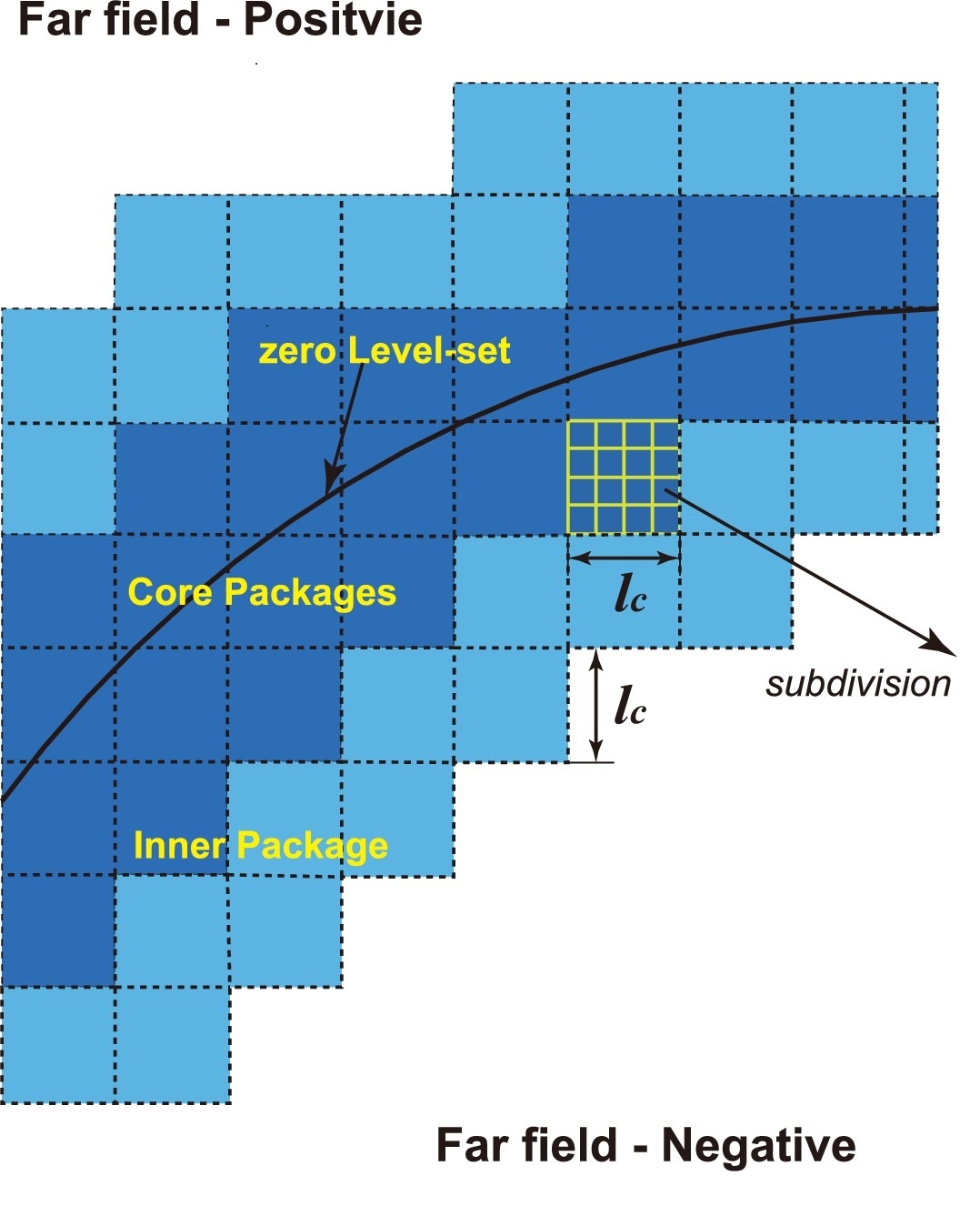
Figure 1: Particle generation from an extruded prism. The gray surface indicates the
clipped zero level set, the framed boxes indicate the core data package blocks used to
describe the surface and the small spheres indicate the SPH particles generated and phys-
ically relaxed for later numerical simulation.
1
arXiv:2512.11473v1 [cs.CE] 12 Dec 2025
Contiguous Storage of Grid Data for Heterogeneous
Computing
Fan Gu, Xiangyu Hu∗
Technical University of Munich, Garching 85748, Germany
Abstract
Structured Cartesian grids are a fundamental component in numerical simu-
lations. Although these grids facilitate straightforward discretization schemes,
their naïve use in sparse domains leads to excessive memory overhead and in-
efficient computation. Existing frameworks address are primarily optimized
for CPU execution and exhibit performance bottlenecks on GPU architec-
tures due to limited parallelism and high memory access latency. This work
presents a redesigned storage architecture optimized for GPU compatibility
and efficient execution across heterogeneous platforms. By abstracting low-
level GPU-specific details and adopting a unified programming model based
on SYCL, the proposed data structure enables seamless integration across
host and device environments. This architecture simplifies GPU program-
ming for end-users while improving scalability and portability in sparse-grid
and gird-particle coupling numerical simulations.
∗Corresponding author.
Email addresses: ge86gur@mytum.de (Fan Gu), xiangyu.hu@tum.de (Xiangyu Hu )
1. Introduction
Many numerical methods in scientific computing, computer graphics, and
computational physics rely on structured Cartesian grids to discretize scalar
and vector fields. These grids are widely used in level set methods[6], compu-
tational fluid dynamics (CFD) solvers [2, 3], and volumetric data processing
pipelines [4]. While Cartesian grids offer simplicity and regularity for finite
difference and finite volume methods, large-scale simulations often involve
highly sparse domains where only a small fraction of the grid is actively used
at any time.
Naively storing and updating such sparse data results in excessive mem-
ory consumption and suboptimal memory access patterns, particularly on
modern hardware architectures with hierarchical memory system and paral-
lel processing constraints. To address this, data structures such as OpenVDB
[4] and SPGgrid [7] have been developed to reduce memory overhead and
improve computational performance. These frameworks leverage hierarchi-
cal spatial partitioning or page-based layouts to exploit sparsity. However,
they are primarily optimized for CPU-based execution, and often suffer from
performance degradation when ported to Graphic Processing Unit (GPU) ar-
chitectures. Key challenges include high random-access latency and limited
concurrency during data update.
GPU has become prevalent in accelerating a wide range of numerical
simulations due to their high parallel processing capability. Despite the high
computing power provided, leveraging GPU typically requires the adoption
of specialized programming models, such as CUDA(NVIDIA), HIP(AMD),
SYCL, and others, which presents a steep learning curve for end-users.
3
In our prior implementations in the open-source SPH (Smoothed Particle
Hydrodynamics) multi-physics library SPHinXsys [3, 9], memory allocation
for activated grid regions was managed via dynamic memory pools. While
this approach yields efficient memory usage, the resulting data structures are
not inherently compatible with GPU execution. In this work, we present a
redesigned storage architecture aimed at improving computational efficiency
and enabling GPU compatibility. The new design is optimized for unified
usage across both host and device platforms, abstracting underlying imple-
mentation details from the user.
This work introduces an optimized data structure tailored for GPU execu-
tion, along with a newly developed computing kernels. The key contributions
are:
1. Abstraction of GPU-specific and SYCL-specific implementation details,
thereby simplifying usage for end-users.
2. Unified codebase enabling seamless execution on both CPU and GPU
platforms through a single code logic.
3. Heterogeneous computing is achieved for both sparse-grid and grid-
particle coupling numerical simulations.
The proposed method incorporates computing kernels, data structures
and execution strategies. The computing kernel orchestrates the computa-
tional process, while data structure manage storage and synchronization of
data across CPU and GPU. Upon execution, the computing kernel automat-
ically retrieves the appropriate host or device variable based on the selected
execution strategy, thus ensuring consistency and portability.
4
2. Literature Overview
OpenVDB [4] employs a shallow B+ trees to store data efficiently, using
various strategies to accelerate both sequential and stencil-based data access.
By dynamically organizing data with a hier