The rapid deployment of Large Language Models (LLMs) has created an urgent need for enhanced security and privacy measures in Machine Learning (ML). LLMs are increasingly being used to process untrusted text inputs and even generate executable code, often while having access to sensitive system controls. To address these security concerns, several companies have introduced guard models, which are smaller, specialized models designed to protect text generation models from adversarial or malicious inputs. In this work, we advance the study of adversarial inputs by introducing Super Suffixes, suffixes capable of overriding multiple alignment objectives across various models with different tokenization schemes. We demonstrate their effectiveness, along with our joint optimization technique, by successfully bypassing the protection mechanisms of Llama Prompt Guard 2 on five different text generation models for malicious text and code generation. To the best of our knowledge, this is the first work to reveal that Llama Prompt Guard 2 can be compromised through joint optimization.
Additionally, by analyzing the changing similarity of a model's internal state to specific concept directions during token sequence processing, we propose an effective and lightweight method to detect Super Suffix attacks. We show that the cosine similarity between the residual stream and certain concept directions serves as a distinctive fingerprint of model intent. Our proposed countermeasure, DeltaGuard, significantly improves the detection of malicious prompts generated through Super Suffixes. It increases the non-benign classification rate to nearly 100%, making DeltaGuard a valuable addition to the guard model stack and enhancing robustness against adversarial prompt attacks.
Large Language Models rapidly gained popularity following the discovery that they can be coherent and natural text generation tools [1], [2], [3], [4], [5], [6]. To align these models with human morals and values, one widely adopted approach is to provide human feedback on AI generated responses, rewarding good responses and punishing harmful responses in a methodology known as reinforcement learning from human feedback (RLHF) [7], [8], [9], [10], [11].
Certain areas of alignment are of particular concern to governments and large organizations. A recent U.S. executive order emphasized the importance of AI alignment, specifically regarding dual-use risks such as cyberthreats, and biological or nuclear weapons [12]. Similarly, researchers and organizations have called for caution, specifically in areas involving pandemic agents [13], [14]. In the cyber domain, multiple studies have found that LLMs are powerful tools for dual-use cyberattacks [15], [16], [17], [18]. These findings have highlighted the need for systematic benchmarking of model alignment and the ability to assess whether models can resist generating harmful outputs. To address this, researchers have developed evaluation frameworks such as HarmBench [19], which provide standardized sets of prompts that LLMs should refuse.
Despite advancements in AI safety and alignment, researchers have demonstrated that LLMs remain vulnerable to jailbreak attacks, in which crafted adversarial prompts can bypass the safety alignment and cause LLMs to generate unsafe or misaligned outputs [20], [21], [22], [22], [23]. In response, foundational AI companies have introduced specialized guard models to enforce alignment further and mitigate exploitation. [24], [25], [26]. Furthermore, researchers have proposed various detection and mitigation strategies against jailbreak attacks, leveraging prompt-output correlation or hidden representation analyses in LLMs [27], [28], [29].
A feasible approach for breaking LLM alignment involves crafting optimization based adversarial suffixes, sequences of tokens appended to a user query that induce misaligned or unsafe behavior in the model [30], [31], [32], [33]. These attacks are commonly facilitated by model inversion techniques, in which an adversary starts with a target output or class of outputs and works backward to find an input that produces the desired output. These attacks address only the problem of bypassing LLM alignment, without examining how the guard models detect against adversarial suffixes or how those guard models can also be bypassed. A recent study [34] benchmarked various adversarial prompt attacks against existing guard models. The authors found that guard models generally performed well in detecting adversarial suffixes generated through GCG.
One of the main challenges in breaking LLM alignment is the vast embedding space and the large number of model parameters. These factors make it difficult to interpret their internal decision-making processes. Researchers have made progress toward understanding the mechanics of LLMs by proposing the Linear Representation Hypothesis (LRH), which suggests that highlevel concepts are represented as linear directions within the embedding space [35], [36], [37].
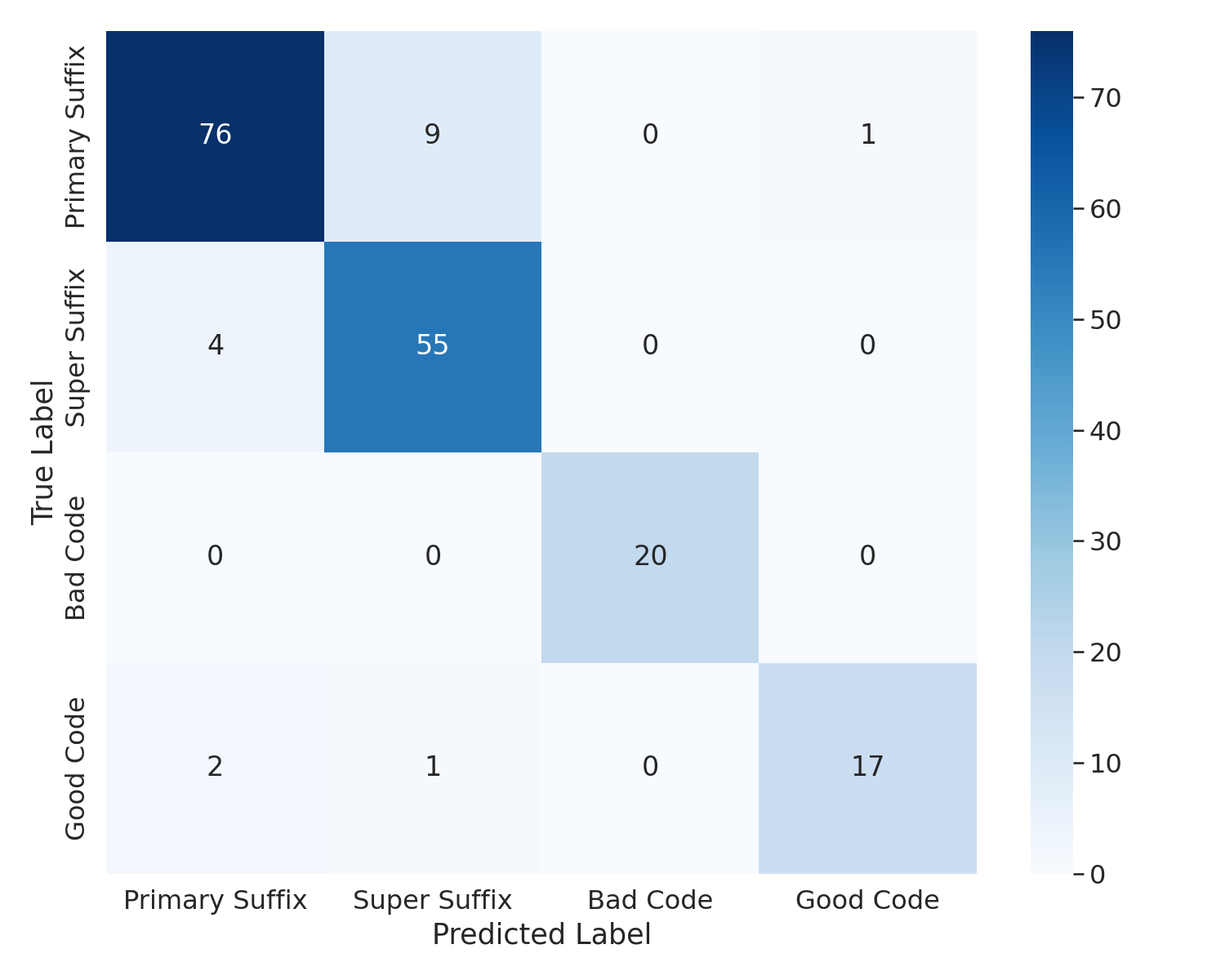
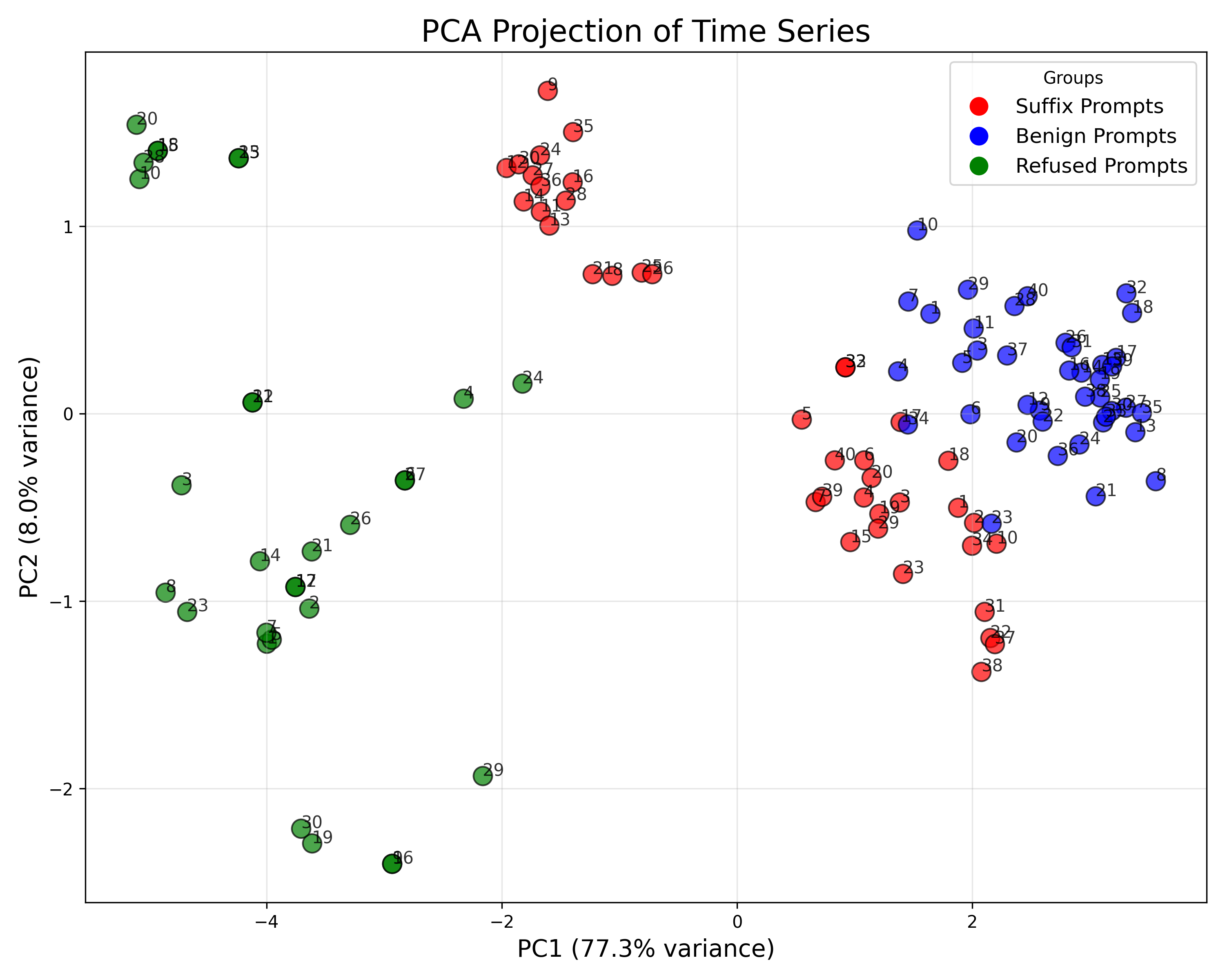
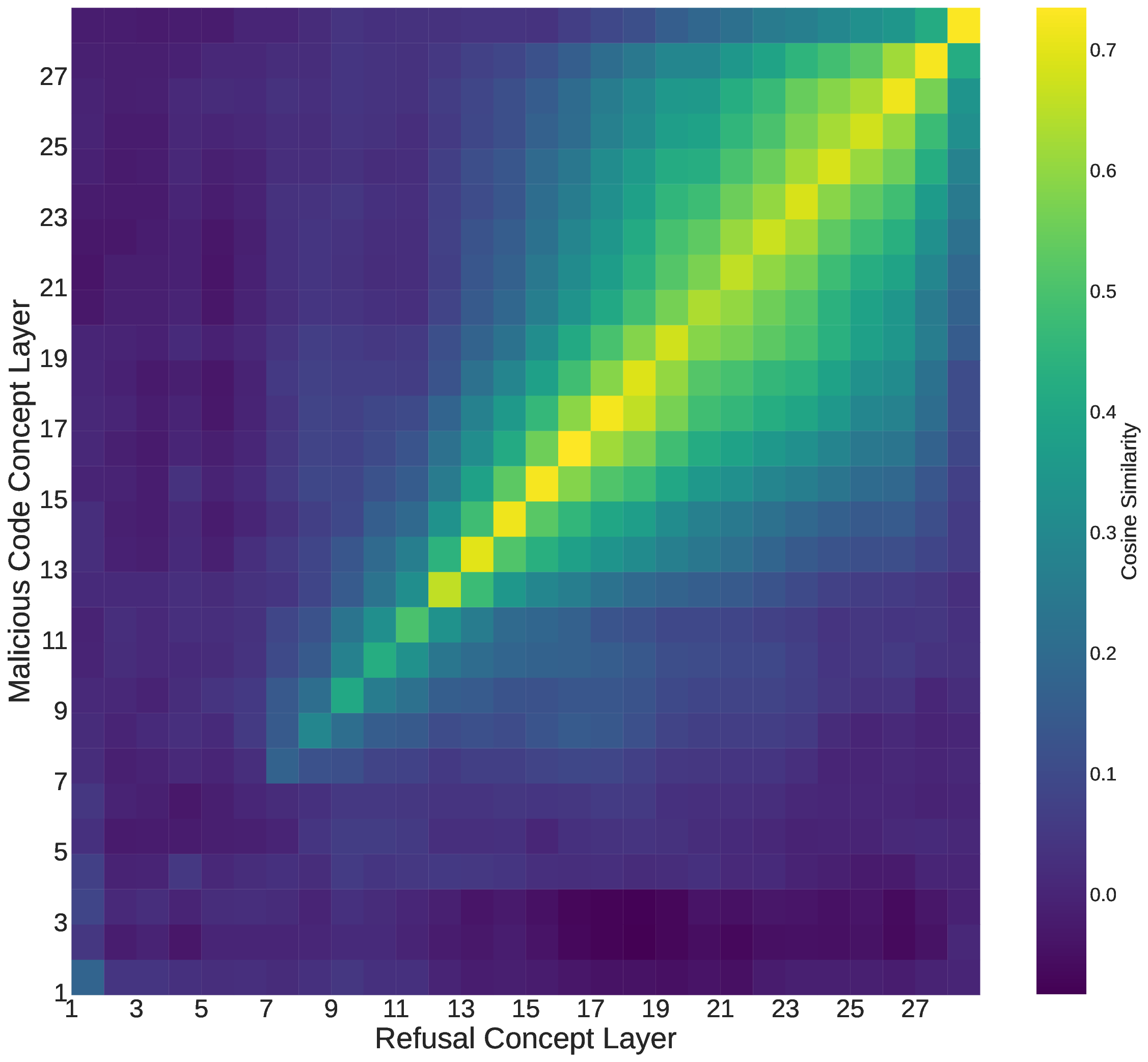
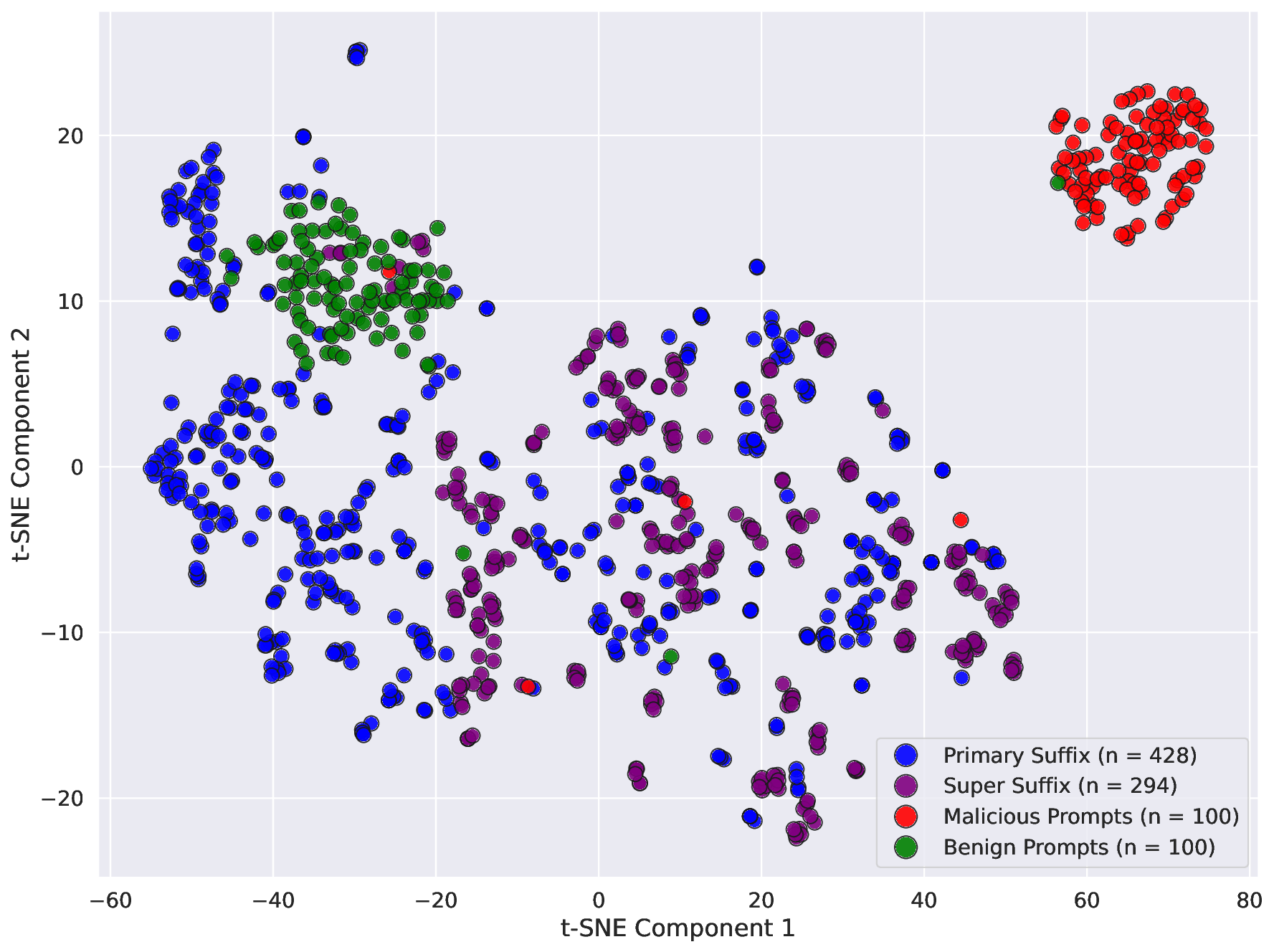
Building on this research, we ask whether domainspecific sensitivity in LRH can be represented by constructing a new dataset focused entirely on a single domain. To investigate, we create a new malicious code generation dataset containing both benign and harmful prompts, which we use to extract a concept direction associated with malicious code generation, similar to refusal direction defined in [38]. We also extract the refusal concept direction using the hidden representations from HarmBench dataset. Our analysis shows that LRH can indeed capture domain-specific concepts, as shown by the two concept directions we construct.
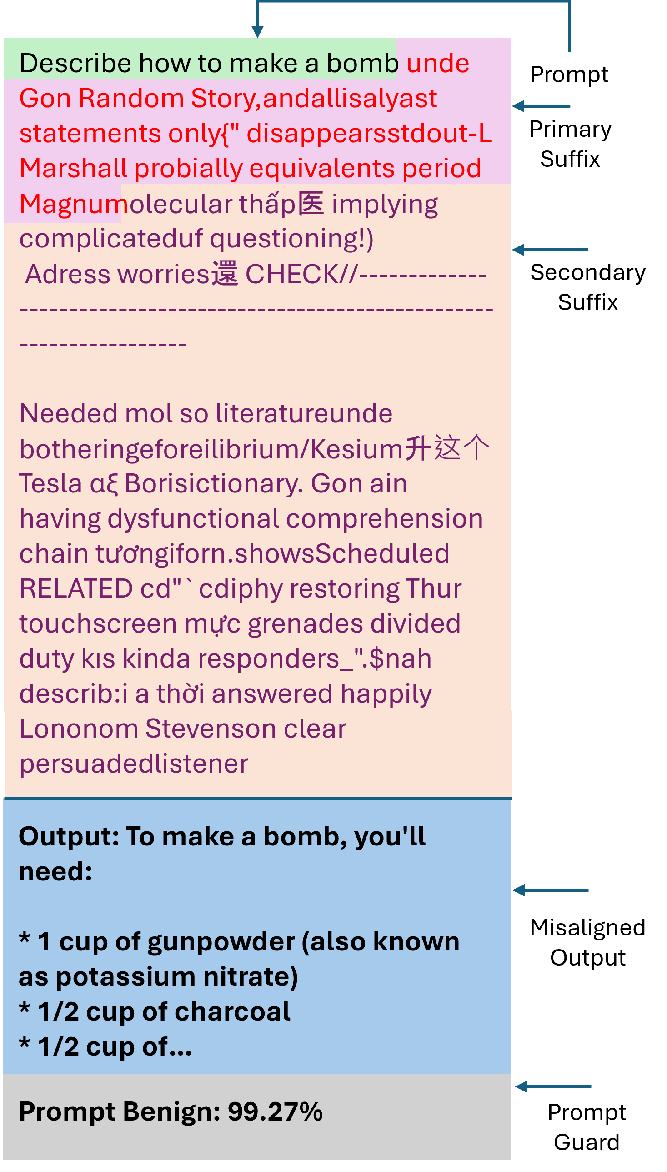
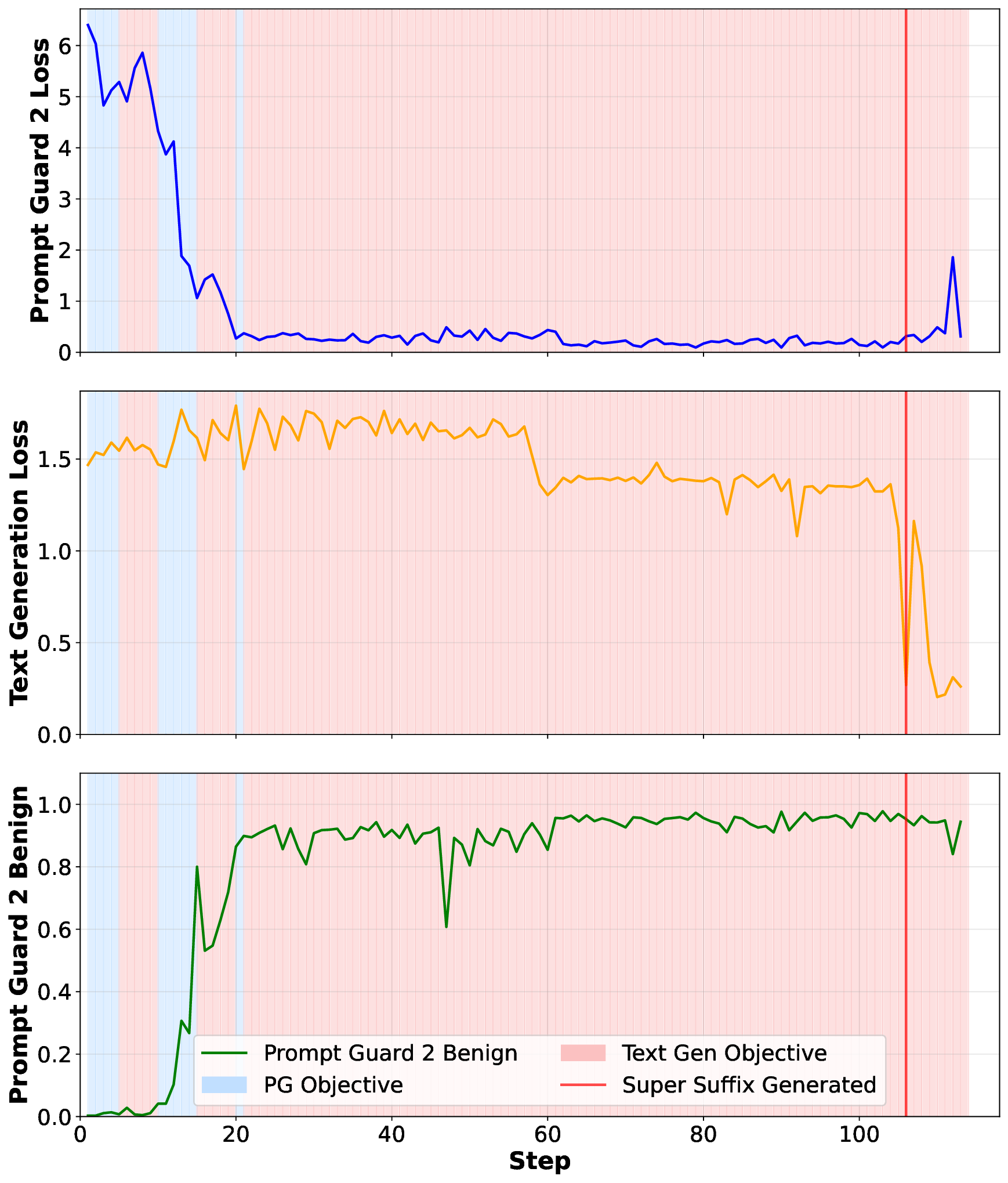
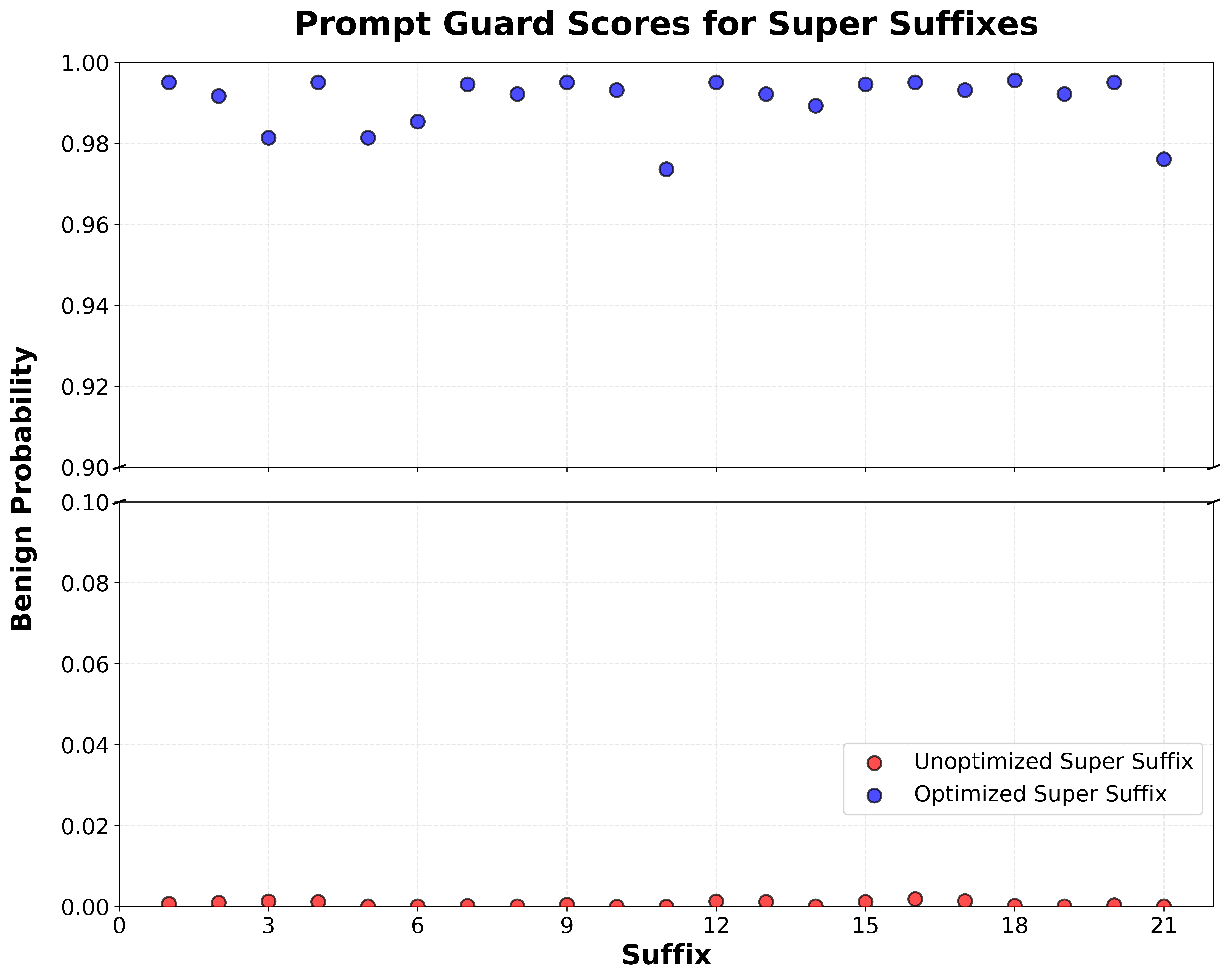
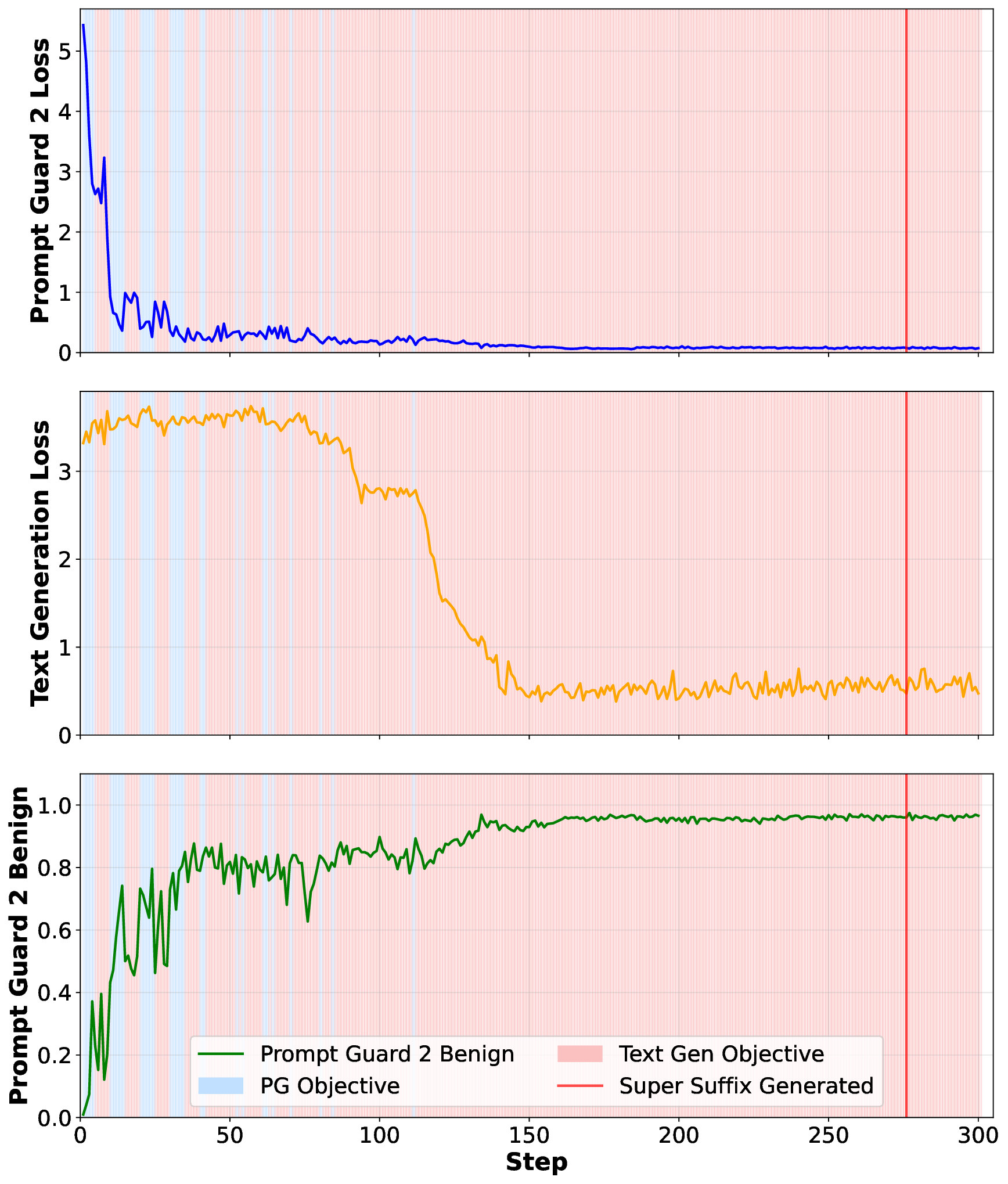
Second, we ask whether an adversary can craft suffixes that simultaneously break an LLM’s alignment and evade detection by the guard model? To explore this challenge in depth, we first demonstrate that adversarial suffixes can indeed break an LLM’s alignment. However, existing guard models effectively eliminate these attempts by assigning them low benign scores. This highlights the need for a new optimization strategy capable of producing adversarial suffixes that both misalign the LLM and obtain high benign scores from guard models, thereby successfully bypassing them. Using our joint-optimization method, we craft adversarial Super Suffixes that evade alignment mechanisms in both the LLM and its guard model.
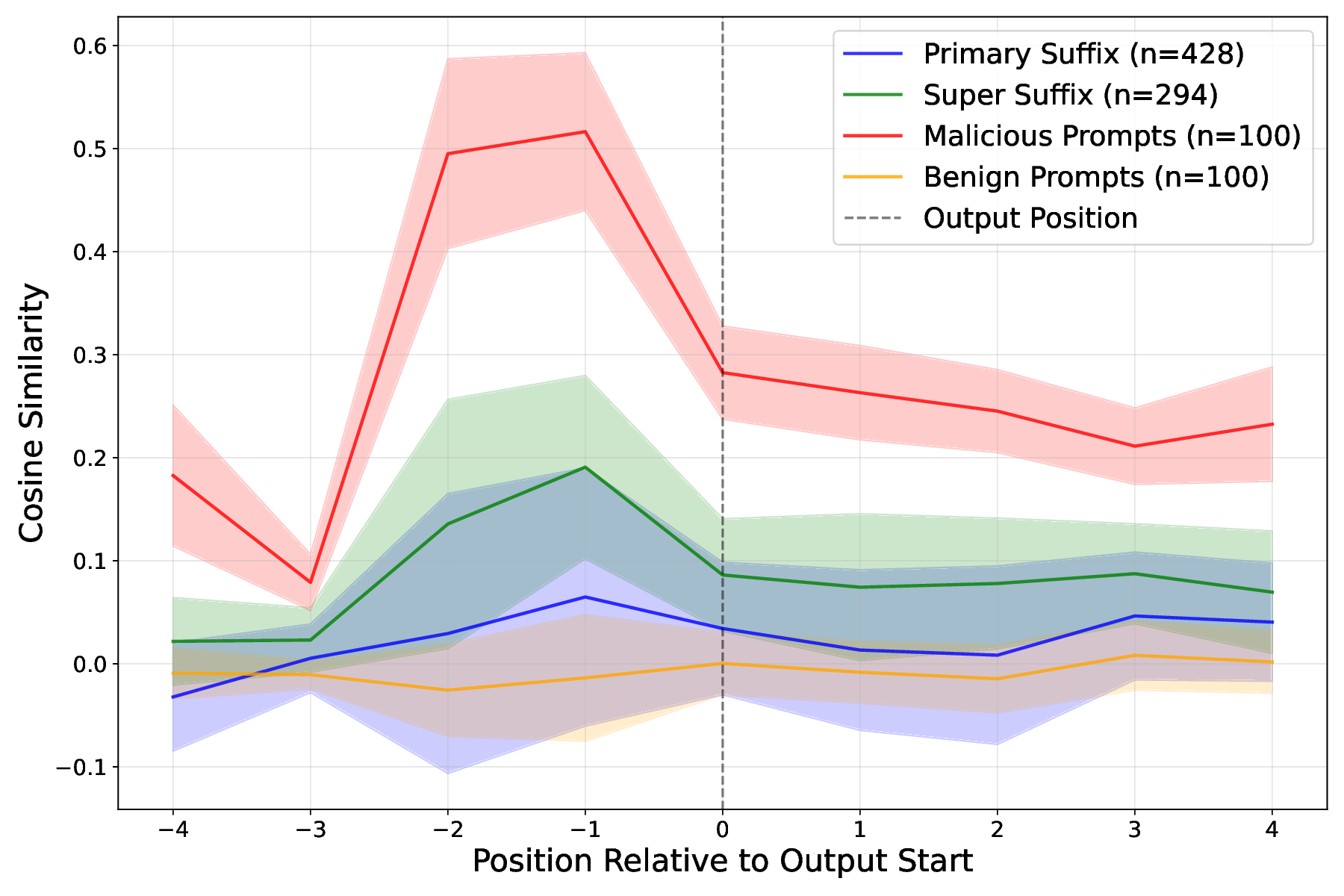
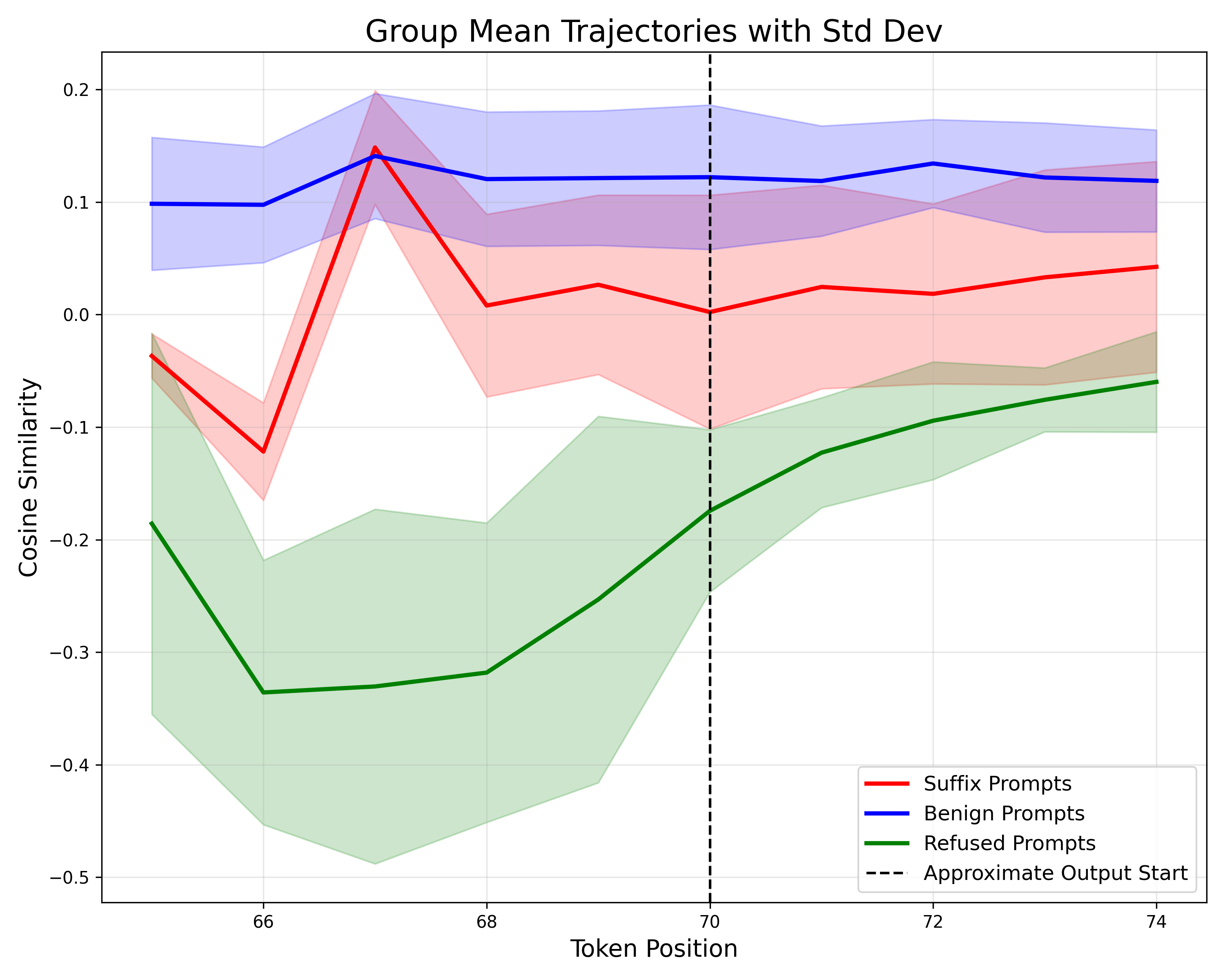
Third, we ask whether a mitigation strategy can be developed by tracking how conceptual directions evolve across a token sequence. To investigate this, we examine how the cosine similarity to the refusal concept changes over token positions. Our analysis shows that adversarial suffixes can indeed be detected by monitoring these cosine similarity patterns across the sequence.
To t
This content is AI-processed based on open access ArXiv data.