The rapid proliferation of artificial intelligence (AI) models and methods presents growing challenges for research software engineers and researchers who must select, integrate, and maintain appropriate models within complex research workflows. Model selection is often performed in an ad hoc manner, relying on fragmented metadata and individual expertise, which can undermine reproducibility, transparency, and overall research software quality.
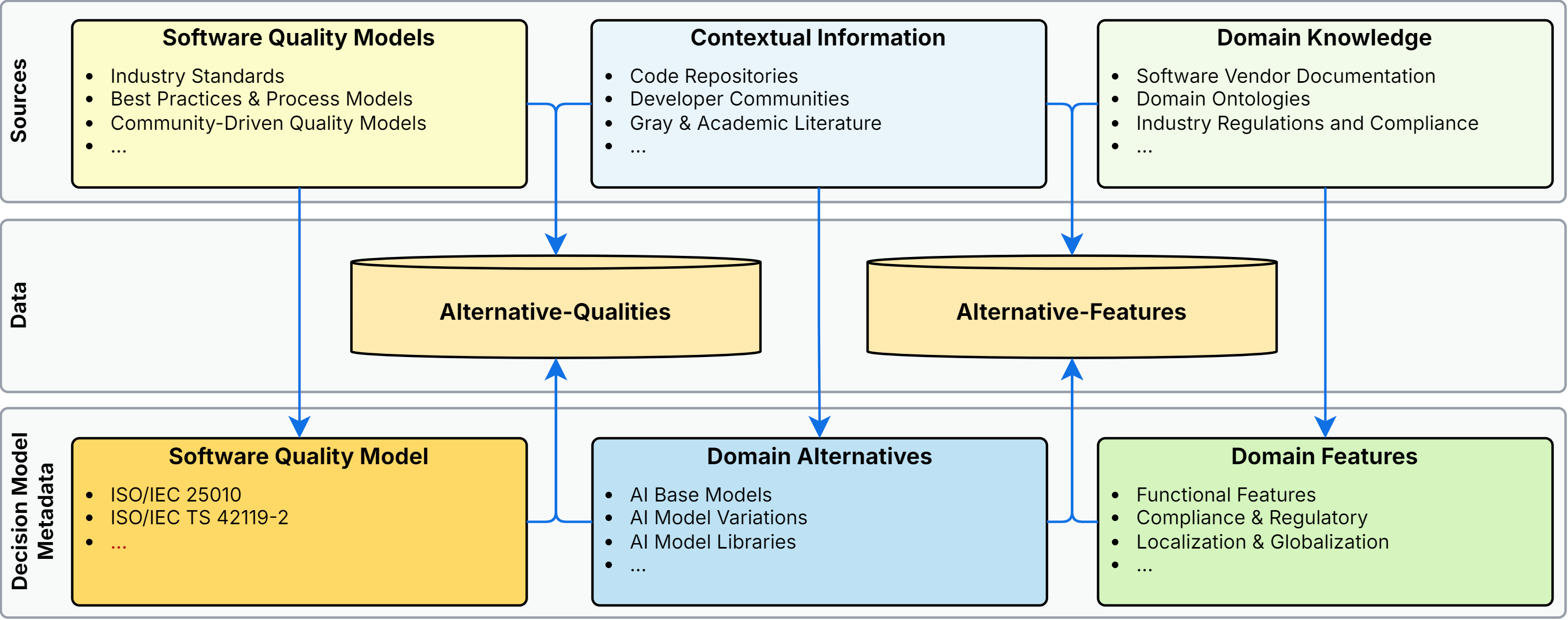
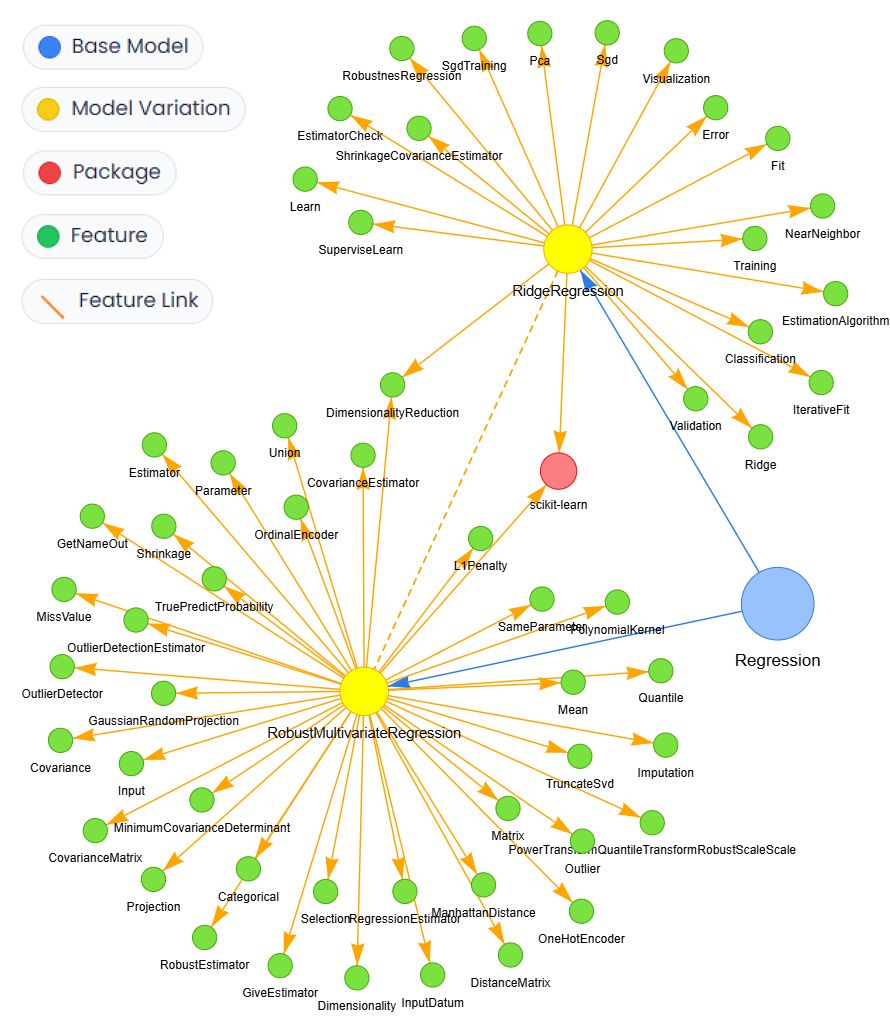
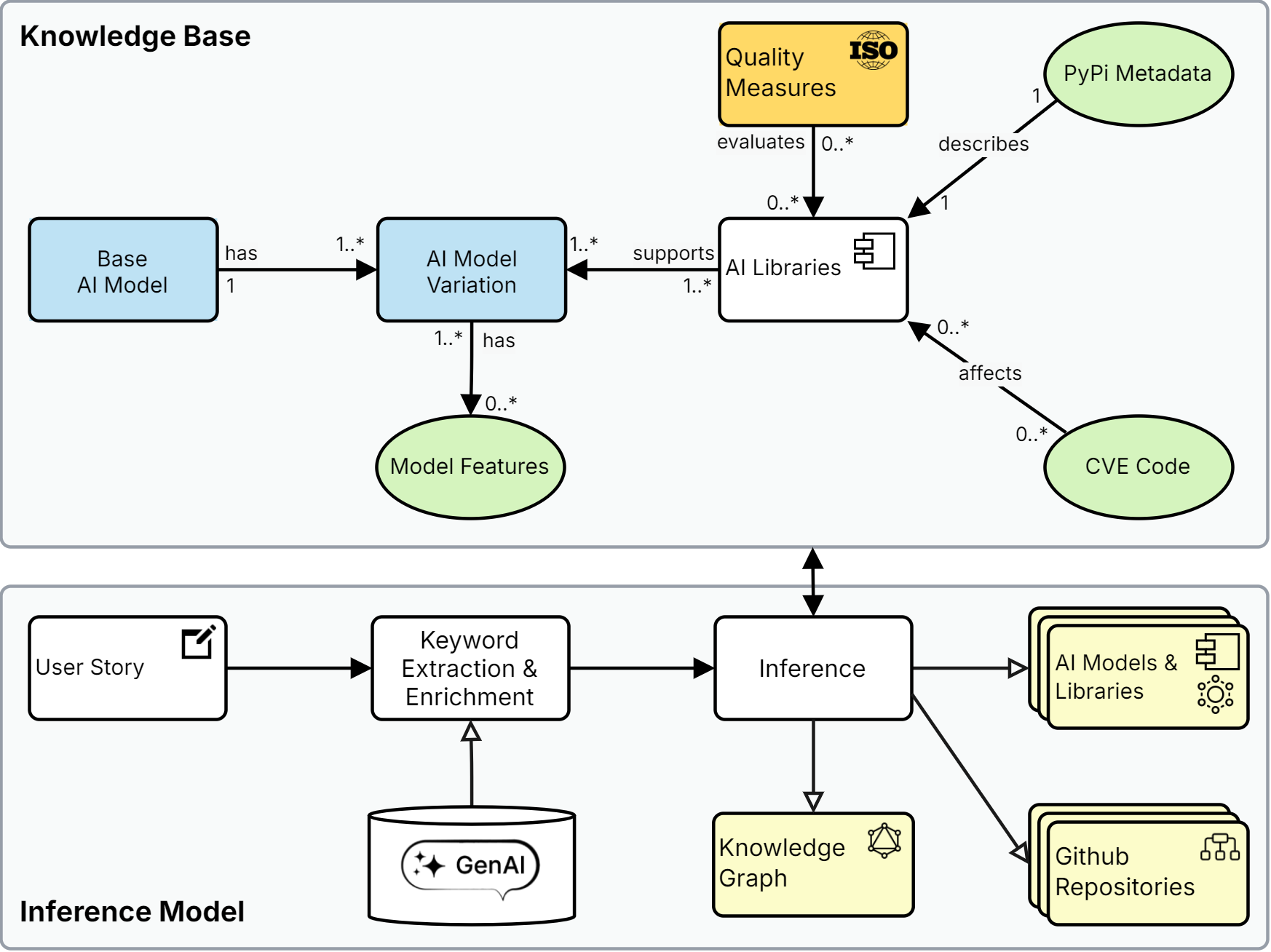
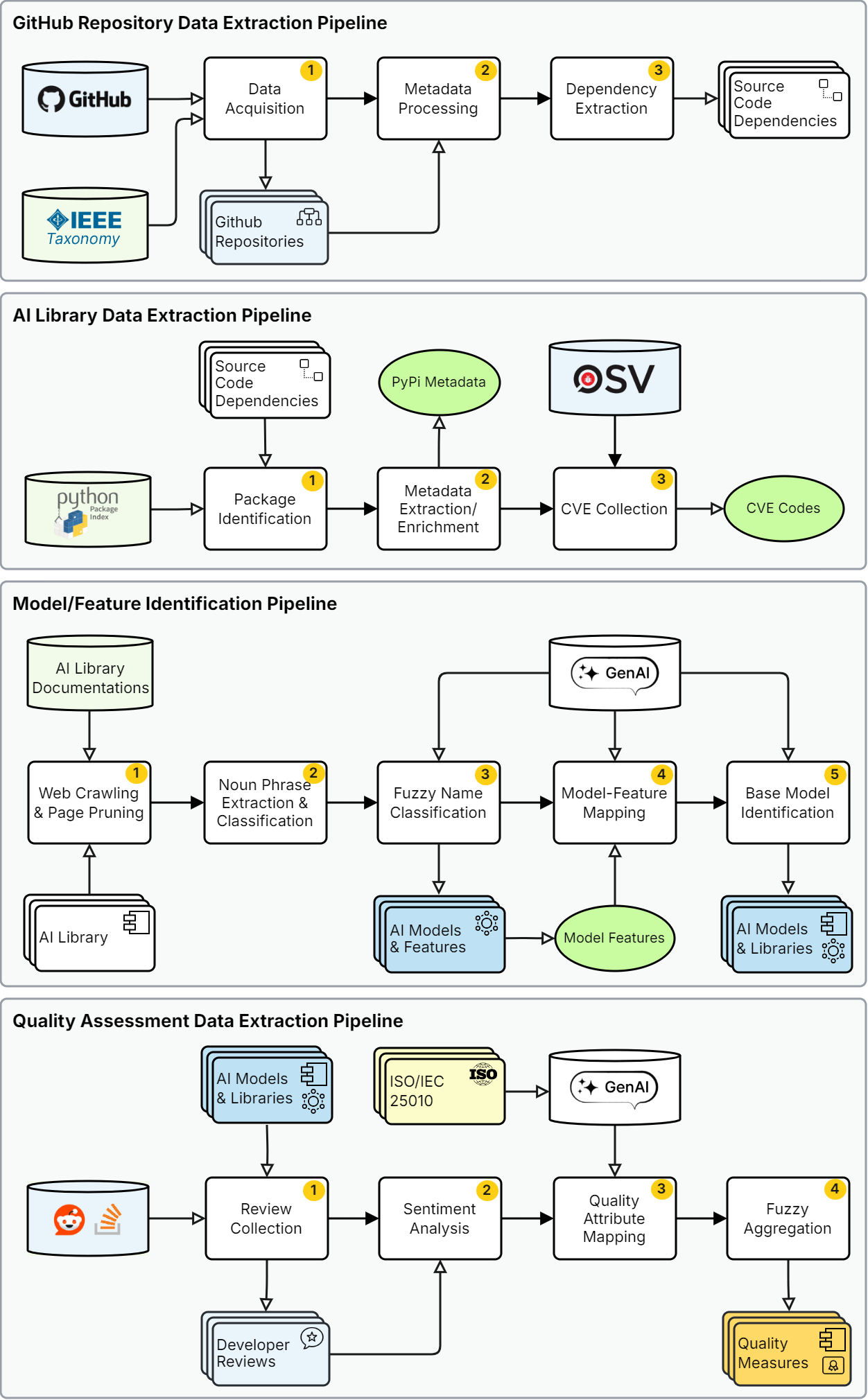
This work proposes a structured and evidence-driven approach to support AI model selection that aligns with both technical and contextual requirements. We conceptualize AI model selection as a Multi-Criteria Decision-Making (MCDM) problem and introduce an evidence-based decision-support framework that integrates automated data collection pipelines, a structured knowledge graph, and MCDM principles. Following the Design Science Research methodology, the proposed framework (ModelSelect) is empirically validated through 50 real-world case studies and comparative experiments against leading generative AI systems.
The evaluation results show that ModelSelect produces reliable, interpretable, and reproducible recommendations that closely align with expert reasoning. Across the case studies, the framework achieved high coverage and strong rationale alignment in both model and library recommendation tasks, performing comparably to generative AI assistants while offering superior traceability and consistency.
By framing AI model selection as an MCDM problem, this work establishes a rigorous foundation for transparent and reproducible decision support in research software engineering. The proposed framework provides a scalable and explainable pathway for integrating empirical evidence into AI model recommendation processes, ultimately improving the quality and robustness of research software decision-making.
💡 Deep Analysis
📄 Full Content
Evidence-Driven Decision Support for AI Model Selection in
Research Software Engineering
Alireza Joonbakhsha, Alireza Rostamia, AmirMohammad Kamaliniaa, Ali Nazeria, Farshad Khunjusha,
Bedir Tekinerdoganb, Siamak Farshidi b,1,∗
aDepartment of Computer Science and Engineering, Shiraz University, Shiraz, Iran
bWageningen University & Research, Wageningen, The Netherlands
Abstract
Context: The rapid proliferation of artificial intelligence (AI) models and methods has created new challenges for
research software engineers (RSEs) and researchers who must select, integrate, and maintain appropriate models within
complex research workflows. This selection process is often ad hoc, relying on fragmented metadata and individual
expertise, which can compromise reproducibility, transparency, and research software quality.
Objective: This work aims to provide a structured and evidence-driven approach to assist research software engineers
and practitioners in selecting AI models that best align with their technical and contextual requirements.
Method: The study conceptualizes AI model selection as a Multi-Criteria Decision-Making (MCDM) problem and in-
troduces an evidence-based decision-support framework that integrates automated data collection pipelines, a structured
knowledge graph, and MCDM principles. Following the Design Science Research (DSR) methodology, the framework,
referred to as ModelSelect, is empirically validated through 50 real-world case studies and comparative experiments
with leading generative AI systems.
Results: The evaluation demonstrates that the framework yields reliable, interpretable, and reproducible recom-
mendations that closely align with expert rationales. Across the case studies, ModelSelect achieved high coverage
and rationale alignment in model and library recommendation tasks, performing comparably to generative AI assistants
while providing greater traceability and consistency.
Conclusion: Modeling AI model selection as an MCDM problem provides a rigorous foundation for transparent and
reproducible decision support in research software engineering. The proposed framework offers a scalable and explainable
pathway for integrating empirical evidence into AI model recommendation processes and improving the quality of research
software decision-making.
Keywords:
AI/ML Model Selection, Decision Support Systems, Generative AI, Knowledge Graphs, Empirical
Evaluation, Research Software Engineering
1. Introduction
In recent years, AI and its subset ML have enjoyed an
unprecedented proliferation in terms of popularity and us-
age [1, 2], as AI/ML2 models and methods can be em-
ployed to carry out plenty of tasks that were previously
performed manually, with superior performance for a va-
riety of applications.
As a result, AI has become an
eye-catching option, sparking a significant amount of re-
search on utilizing it in numerous domains and ecosystems
[3] such as healthcare [4], biology [5], chemistry [6], and
finance [7] for applications like classification, prediction
[4, 5], and decision-making [1]. This use of AI in other
domains is often performed under the umbrella of data
∗Corresponding author
1Email: siamak.farshidi@wur.nl
2For the sake of convenience, this work refers to AI/ML as AI, AI
model as model, and AI model feature as feature from now on.
science. This multidisciplinary field focuses on combining
domain/business knowledge with AI and software develop-
ment to extract knowledge from data through AI models
and methods [8].
The field of AI is rapidly growing, with new models and
methods being developed and proposed at an accelerat-
ing pace [9, 10]. For instance, the number of AI papers
published monthly doubles approximately every 23 months
[11]. These models vary significantly in features such as ar-
chitecture, size, input/output modality, and more [12, 13].
For instance, one study reviewed 150 variations of text
classification using the deep learning model alone [14], each
with its own technical features and qualitative strengths
and shortcomings.
This complexity poses a significant barrier for Research
Software Engineers (RSEs) tasked with developing AI soft-
ware for research. RSEs typically come from domains out-
side of AI and often lack the expertise needed to navi-
arXiv:2512.11984v1 [cs.SE] 12 Dec 2025
gate the AI landscape [15].
They face the task of se-
lecting the best model for their specific context, a deci-
sion that extends far beyond standard accuracy metrics.
It involves considering a model’s architecture [16], inter-
pretability [17], and practical project requirements like
data privacy, regulatory compliance, and deployment con-
straints [18, 19].
To exacerbate the problem, AI development is costly,
both in terms of time and quality [20], and choosing inap-
propriate models may lead to wasted time, resources, and
costs, or to poor solution performance [21]. Furthermore,
model choice affects fairness, accuracy, and user trust of
the said solution [22]. Th