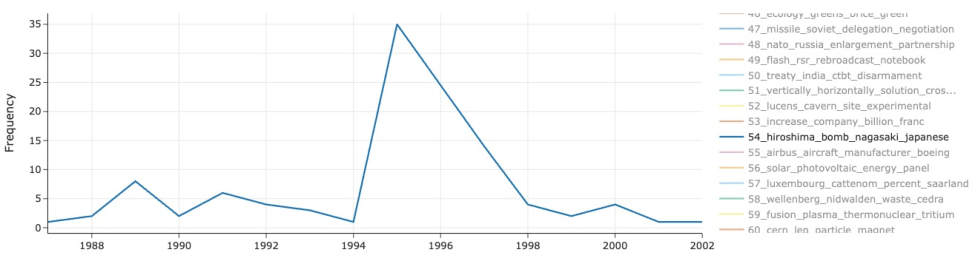
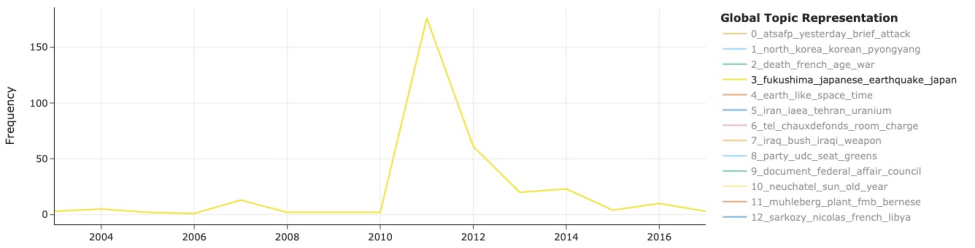
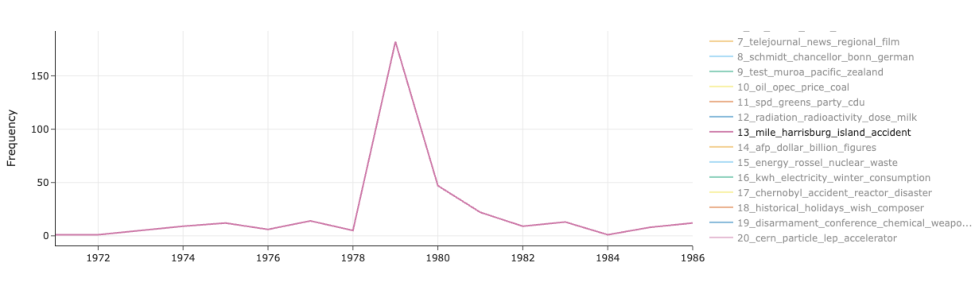Title: Automating Historical Insight Extraction from Large-Scale Newspaper Archives via Neural Topic Modeling
ArXiv ID: 2512.11635
Date: 2025-12-12
Authors: Keerthana Murugaraj, Salima Lamsiyah, Marten During, Martin Theobald
📝 Abstract
Extracting coherent and human-understandable themes from large collections of unstructured historical newspaper archives presents significant challenges due to topic evolution, Optical Character Recognition (OCR) noise, and the sheer volume of text. Traditional topic-modeling methods, such as Latent Dirichlet Allocation (LDA), often fall short in capturing the complexity and dynamic nature of discourse in historical texts. To address these limitations, we employ BERTopic. This neural topic-modeling approach leverages transformerbased embeddings to extract and classify topics, which, despite its growing popularity, still remains underused in historical research. Our study focuses on articles published between 1955 and 2018, specifically examining discourse on nuclear power and nuclear safety. We analyze various topic distributions across the corpus and trace their temporal evolution to uncover long-term trends and shifts in public discourse. This enables us to more accurately explore patterns in public discourse, including the co-occurrence of themes related to nuclear power and nuclear weapons and their shifts in topic importance over time. Our study demonstrates the scalability and contextual sensitivity of BERTopic as an alternative to traditional approaches, offering richer insights into historical discourses extracted from newspaper archives. These findings contribute to historical, nuclear, and social-science research while reflecting on current limitations and proposing potential directions for future work.
💡 Deep Analysis
📄 Full Content
Automating Historical Insight Extraction from
Large-Scale Newspaper Archives via Neural Topic
Modeling
Keerthana Murugaraj ,1,∗Salima Lamsiyah ,1 Marten During
2
and Martin Theobald
1
1Department of Computer Science, University of Luxembourg, 2, place de l’Universit´e, 4365, Esch-Belval
Esch-sur-Alzette, Luxembourg and 2Centre for Contemporary & Digital History (C2DH), University of
Luxembourg, 11 Porte des Sciences, 4366, Esch-Belval Esch-sur-Alzette, Luxembourg
∗Corresponding author. keerthana.murugaraj@uni.lu
Abstract
Extracting coherent and human-understandable themes from large collections of unstructured historical
newspaper archives presents significant challenges due to topic evolution, Optical Character Recognition (OCR)
noise, and the sheer volume of text. Traditional topic-modeling methods, such as Latent Dirichlet Allocation
(LDA), often fall short in capturing the complexity and dynamic nature of discourse in historical texts. To
address these limitations, we employ BERTopic. This neural topic-modeling approach leverages transformer-
based embeddings to extract and classify topics, which, despite its growing popularity, still remains underused
in historical research. Our study focuses on articles published between 1955 and 2018, specifically examining
discourse on nuclear power and nuclear safety. We analyze various topic distributions across the corpus and
trace their temporal evolution to uncover long-term trends and shifts in public discourse. This enables us to more
accurately explore patterns in public discourse, including the co-occurrence of themes related to nuclear power
and nuclear weapons and their shifts in topic importance over time. Our study demonstrates the scalability
and contextual sensitivity of BERTopic as an alternative to traditional approaches, offering richer insights into
historical discourses extracted from newspaper archives. These findings contribute to historical, nuclear, and
social-science research while reflecting on current limitations and proposing potential directions for future work.
Key words: Historical Text Mining, Unsupervised Automated Analysis, Neural Topic Modeling, BERTopic, Nuclear
Discourse, Temporal Text Evolution
1. Introduction
Newspapers have long been a vital primary source for
historians, offering key insights into past events, societal
trends,
and cultural narratives.
They help establish
historical timelines, verify facts, and identify trends,
providing detailed accounts of people, places, and events.
Alongside other primary sources, newspapers continue
to shape our understanding of history through rich first-
hand documentation (Tibbo, 2002; Sun and Qin, 2025).
Traditional methods of analyzing newspapers, such as
manual reading and bibliographic approaches relying on
subjective expertise, have notable drawbacks, especially
when dealing with large volumes of unstructured textual
archives. These methods can be time-consuming, prone
to human bias,
and inefficient for organizing and
analyzing extensive collections of documents. To address
these challenges, computational approaches have been
increasingly employed in recent studies to interpret
factual content and perform text classification tasks
(Huang et al., 2022; Tsai et al., 2025). In contrast to
traditional methods, text mining techniques based on
Natural Language Processing (NLP)—particularly topic
modeling—offer a scalable and automated solution for
uncovering latent patterns within large corpora, without
the need for manual categorization (Fridlund and Brauer,
2013; Vorobeva et al., 2025; Cvrˇcek and Berrocal,
1
arXiv:2512.11635v1 [cs.CL] 12 Dec 2025
2
Keerthana Murugaraj et al.
2025). Topic modeling identifies latent topics within
vast document collections, thereby providing a more
efficient, objective, and scalable solution to the challenges
historians face in organizing and analyzing their research
(Yang et al., 2011; Yamashita and Uchida, 2025)
In
this
paper,
we
explore
the
effectiveness
of
BERTopic
(Grootendorst,
2022),
a
state-of-the-art
neural-based topic-modeling technique,
in analyzing
historical newspaper archives. It leverages transformer-
based embeddings (Vaswani et al., 2017) to capture
nuanced
relationships
between
words
and
topics,
outperforming classical topic-modeling methods such as
Latent Dirichlet Allocation (LDA) (Blei et al., 2003),
probabilistic Latent Semantic Analysis (pLSA), and
Non-negative Matrix Factorization (NMF) (Lee and
Seung, 1999). By using pre-trained language models,
BERTopic has demonstrated superior performance in
terms of generating coherent and human-understandable
topics, even in large and complex document collections
(Medvecki et al., 2023; Mutsaddi et al., 2025). The
contextualized embedding-based representations enable
the model to better understand subtle thematic shifts
over time, a feature particularly useful for analyzing
historical data where linguistic and contextual variations
are significant.
Our work builds upon the foundations lai