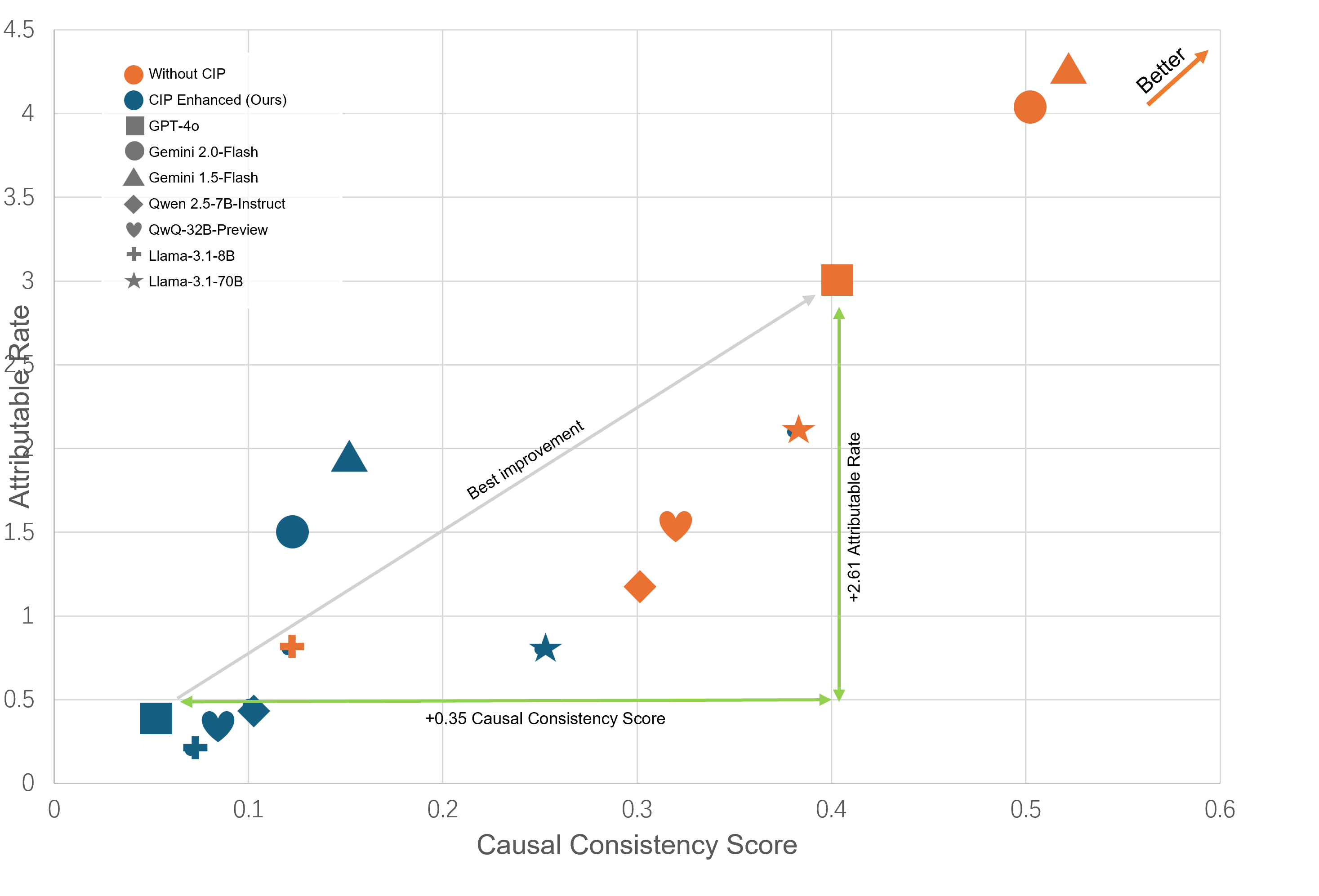
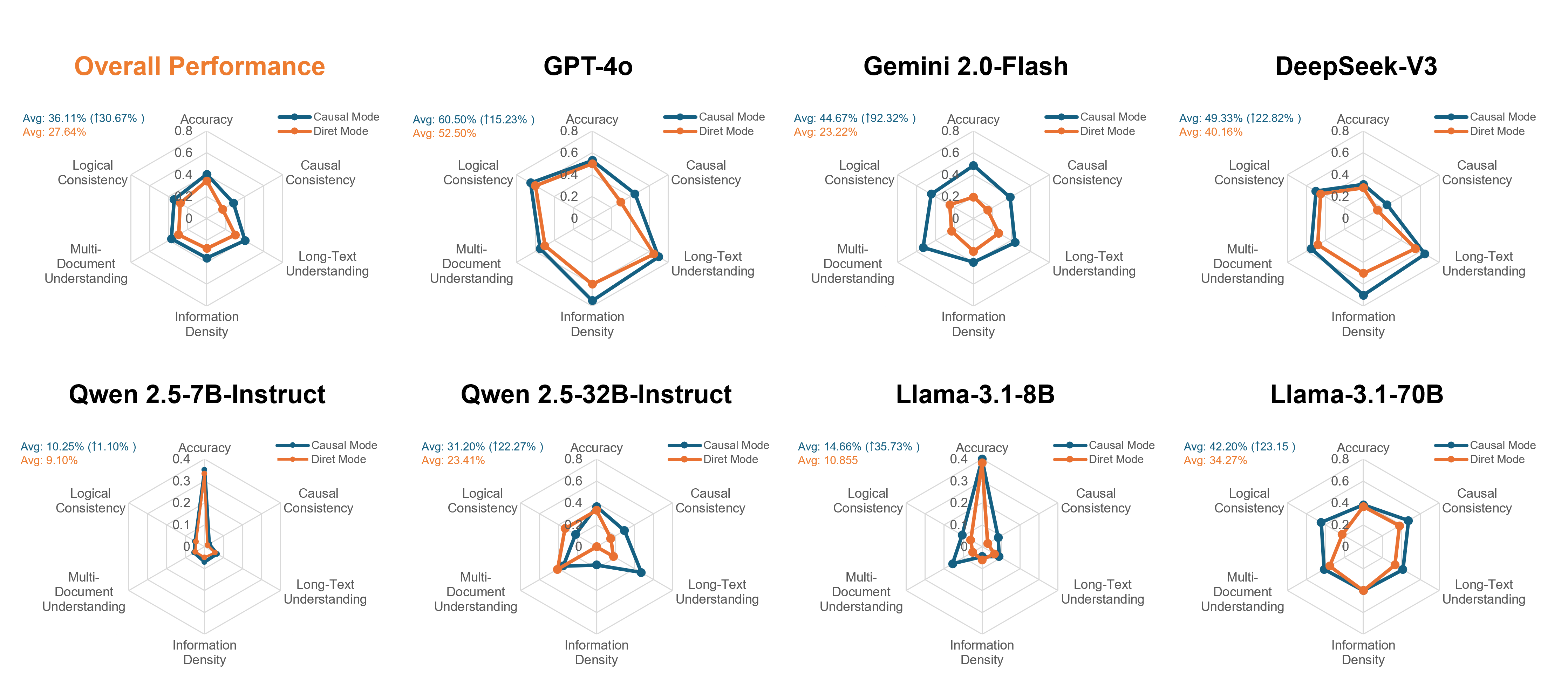
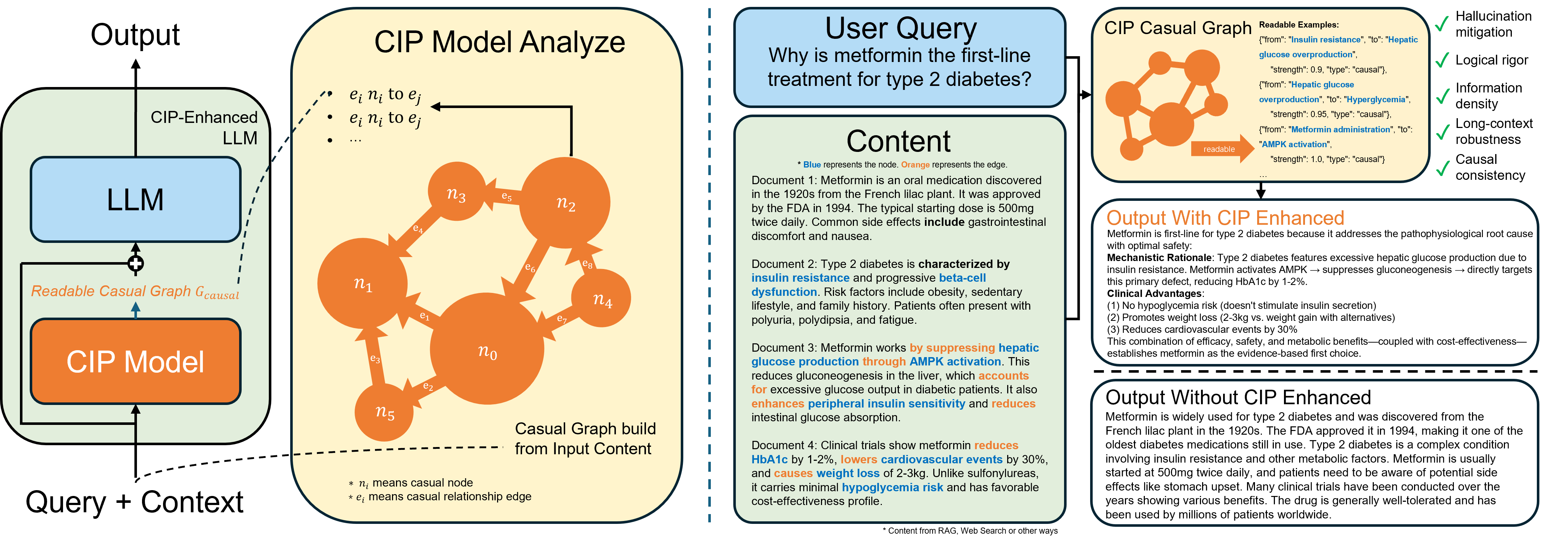
Large language models often hallucinate when processing long and noisy retrieval contexts because they rely on spurious correlations rather than genuine causal relationships. We propose CIP, a lightweight and plug-and-play causal prompting framework that mitigates hallucinations at the input stage. CIP constructs a causal relation sequence among entities, actions, and events and injects it into the prompt to guide reasoning toward causally relevant evidence. Through causal intervention and counterfactual reasoning, CIP suppresses non causal reasoning paths, improving factual grounding and interpretability. Experiments across seven mainstream language models, including GPT-4o, Gemini 2.0 Flash, and Llama 3.1, show that CIP consistently enhances reasoning quality and reliability, achieving 2.6 points improvement in Attributable Rate, 0.38 improvement in Causal Consistency Score, and a fourfold increase in effective information density. API level profiling further shows that CIP accelerates contextual understanding and reduces end to end response latency by up to 55.1 percent. These results suggest that causal reasoning may serve as a promising paradigm for improving the explainability, stability, and efficiency of large language models.
The rise of large language models (LLMs) is reshaping the paradigm of information processing and human-computer interaction [20,33], demonstrating unprecedented potential in knowledgeintensive fields such as medical diagnosis [1] and legal document analysis [25]. However, despite these models' growing capabilities, a fundamental challenge-hallucinations-remains a major obstacle to their reliable application [4,13]. When presented with lengthy and complex documents, models tend to generate content that is inconsistent with the facts or even fabricated. In critical scenarios like medicine and law, such confident, erroneous outputs can not only lead to catastrophic consequences but also severely erode user trust in AI systems, becoming a key bottleneck hindering their widespread deployment.
To mitigate hallucinations, Retrieval-Augmented Generation (RAG) has been widely adopted to inject external factual knowledge into LLMs by retrieving relevant documents. However, RAG acts primarily as an “information transporter” rather than an “information discriminator, " often delivering noisy, irrelevant, or contradictory content-especially when processing long documents. This indiscriminate injection of retrieval noise exacerbates the very issue it aims to solve, as LLMs are left to reason over chaotic contexts without guidance on causal relevance, thereby reinforcing misinterpretation and hallucination.
Hallucinations in large language models (LLMs) are not merely the byproduct of insufficient retrieval or missing factual knowledge, but manifestations of deeper systemic flaws in how models generate and evaluate information. As argued by [18], hallucinations arise from the joint effect of statistical pressure and evaluation bias.
During pre-training, LLMs are optimized to maximize linguistic fluency across massive corpora, learning to reproduce “credible fallacies” without distinguishing truth from plausibility. This tendency becomes especially severe when dealing with long documents containing sparse factual anchors, where the model’s statistical prior dominates reasoning. Simultaneously, as [7] highlights, the dominant post-training and evaluation paradigms penalize expressions of uncertainty. Models are thus incentivized to make confident guesses rather than to abstain or indicate ambiguity when faced with noisy, contradictory, or incomplete evidence. These forces jointly drive the model to fabricate details to maintain narrative coherence.
Current methods mainly attempt to mitigate hallucinations by supplying additional external information, thereby improving retrieval fidelity. However, this approach burdens the model with noisy or spurious correlations within the retrieved content, which can easily mislead reasoning and amplify hallucinations.In contrast, incorporating causal logic aims to enhance reasoning fidelityenabling large language models to assess the causal relevance of retrieved evidence rather than treating all information as equally valid. By grounding inference in causal consistency instead of surfacelevel statistical alignment, models can move from information accumulation toward reasoned understanding, fundamentally reducing hallucinations rather than merely masking them.
Causal Inference Plugin (CIP) is a lightweight, plug-and-play prompting framework that restructures raw retrieval outputs into explicit causal relation chains among entities, events, and actions. Drawing on causal inference principles, CIP focuses on extracting, filtering, and representing only causally relevant evidence. Through this process, it reformulates retrieved content into structured causal graphs or chains that serve as inputs for reasoning, enabling large language models to process information according to causal dependencies rather than surface-level correlations Our CIP has three key advantages. (1) Improving Output Quality: By extracting causal knowledge through CIP, we not only substantially reduce the hallucination rate but also achieve a marked enhancement in overall output quality. Specifically, CIP enables (a) enhanced logical rigor, ensuring the model’s responses follow clear causal reasoning; (b) improved information density, effectively eliminating redundant or fragmented expressions and thereby increasing the “effective information density” of the generated text; and (c) enhanced long-text comprehension capabilities, as demonstrated by superior performance on multi-document and long-context understanding tasks.
(2) Plug-and-Play: CIP is designed as a modular, input-level auxiliary unit that seamlessly integrates with existing mainstream LLMs without requiring parameter modifications. We validated its compatibility and effectiveness across seven industry-leading models, including [2,3,6,10,14,16,31], achieving consistent performance gains. (3) Resource-Efficient: CIP is highly efficient in both training and deployment. Built upon a 7B-parameter language model and fine-tuned using LoRa technology [12], i
This content is AI-processed based on open access ArXiv data.