As AI and web agents become pervasive in decision-making, it is critical to design intelligent systems that not only support sustainability efforts but also guard against misinformation. Greenwashing, i.e., misleading corporate sustainability claims, poses a major challenge to environmental progress. To address this challenge, we introduce EmeraldMind, a fact-centric framework integrating a domain-specific knowledge graph with retrieval-augmented generation to automate greenwashing detection. EmeraldMind builds the EmeraldGraph from diverse corporate ESG (environmental, social, and governance) reports, surfacing verifiable evidence, often missing in generic knowledge bases, and supporting large language models in claim assessment. The framework delivers justification-centric classifications, presenting transparent, evidence-backed verdicts and abstaining responsibly when claims cannot be verified. Experiments on a new greenwashing claims dataset demonstrate that EmeraldMind achieves competitive accuracy, greater coverage, and superior explanation quality compared to generic LLMs, without the need for fine-tuning or retraining.
Greenwashing refers to the corporate practice of conveying a misleading impression of environmental responsibility through advertisements, statements across media channels, and traditional communication platforms. Common examples include presenting regulatory compliance as a product's environmental benefit, or advertising green claims to entire products when they pertain only to specific parts or aspects. Greenwashing misleads consumers and investors with false sustainability claims, undermining trust, hindering genuine environmental efforts, and allowing harmful practices to persist while delaying urgent action on climate change.
Journalists assess potential greenwashing by seeking evidence in regulatory records from authorities such as the Advertising Standards Authority (ASA) or corporate Environmental, Social, and Governance (ESG) reports. ESG reports are documents that organizations publish on an annual basis to disclose their performance and practices, via standardized, non-financial metrics, i.e., key performance indicators (KPIs). These KPIs follow frameworks defined by the European Union’s Sustainable Finance Disclosure Regulation (SFDR) and Corporate Sustainability Reporting Directive (CSRD). Monitoring these metrics and cross-checking them against other corporate information, such as advertising campaigns and news coverage, can uncover inconsistencies, including environmental impacts that are inaccurately reported or overstated.
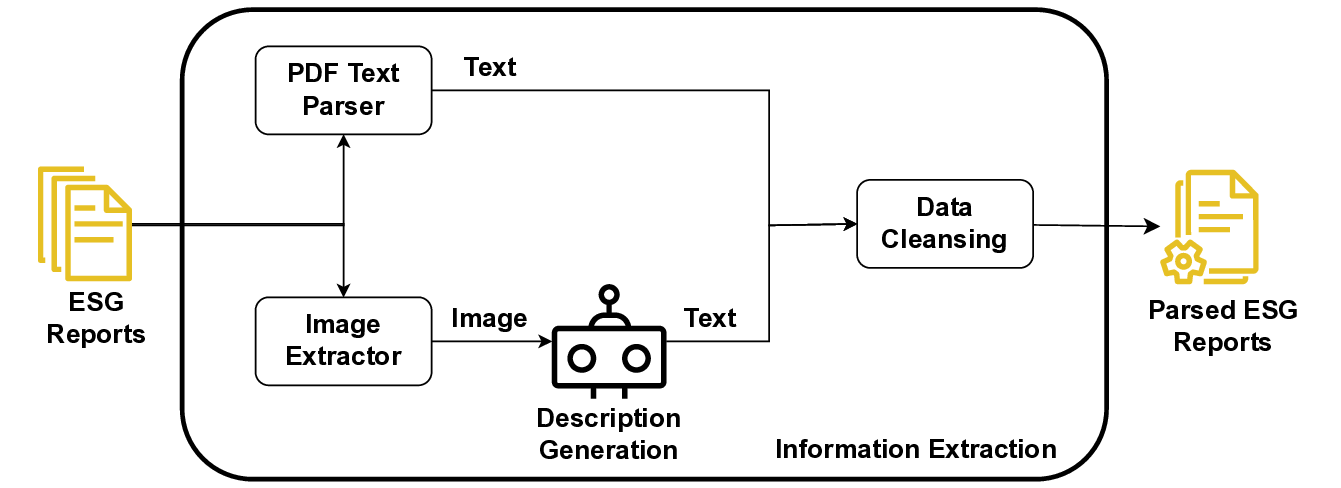
Greenwashing detection represents a specialized subset of fact-checking research; however, it presents some unique challenges when realized through automated retrievalaugmented generation (RAG) pipelines. The first refers to the extraction and modeling of domain-specific information that can be used in automated verification pipelines [15,1,18]. Traditional fact-checking pipelines relying on generic sources, such as scholarly literature or general web information, often fail to retrieve and assess the specialized evidence needed for metrics like emissions KPIs, which may also be proprietary. As a result, the verification results can be incomplete or misleading [6,20]. Thus, greenwashing detection demands tailored retrieval and processing of multimodal content from specialized knowledge sources like ESG reports and regulatory records beyond general repositories.
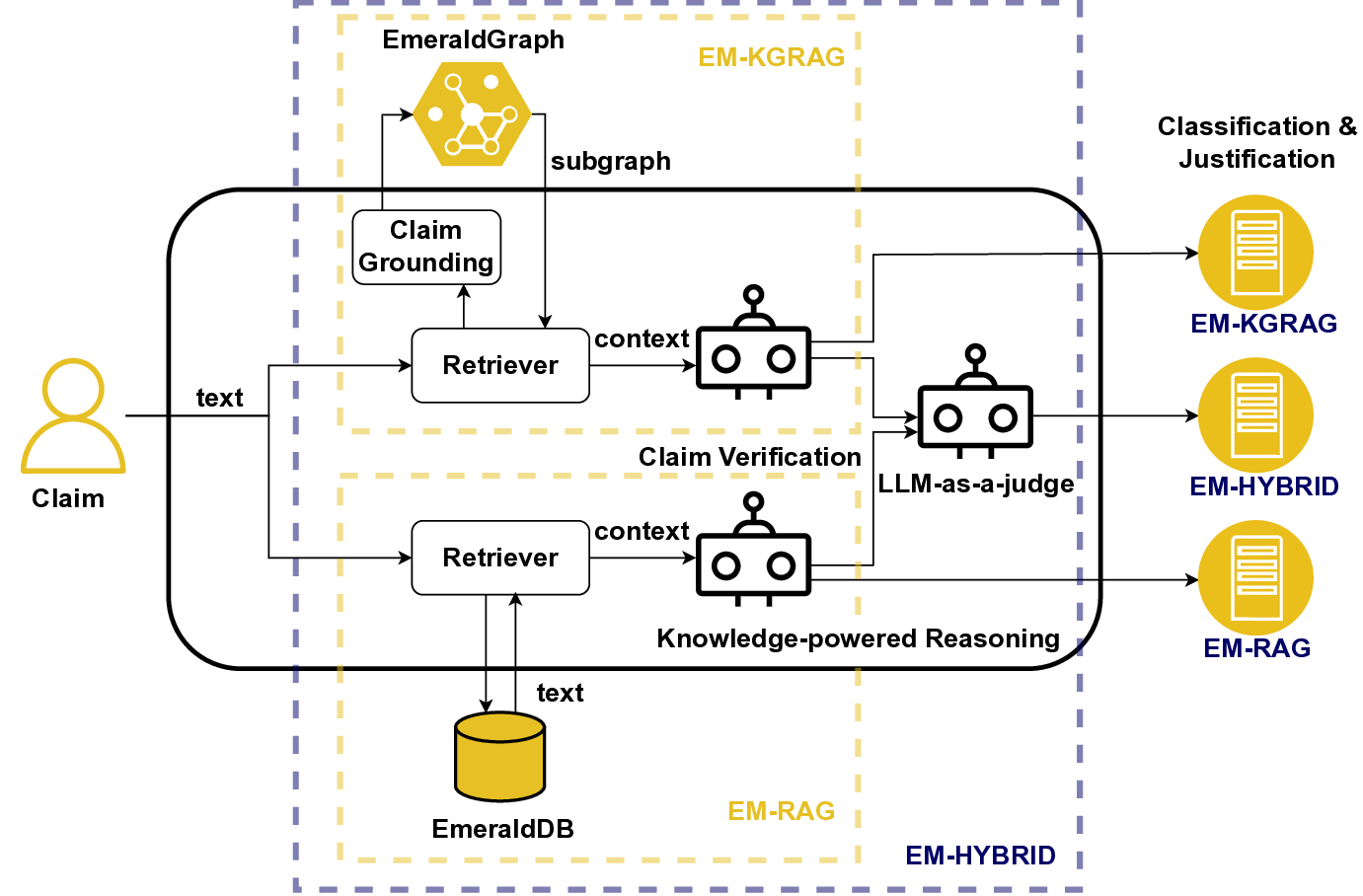
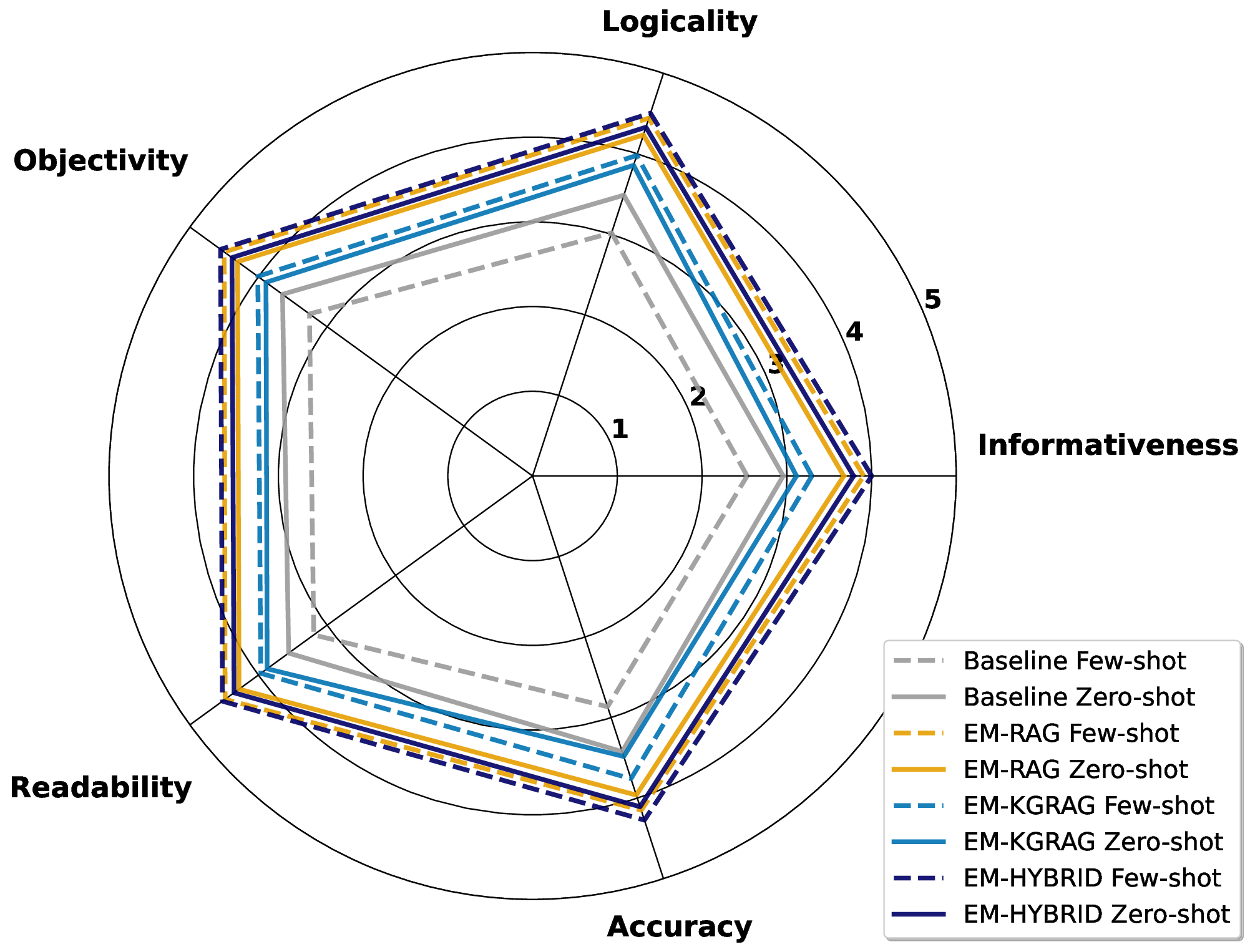
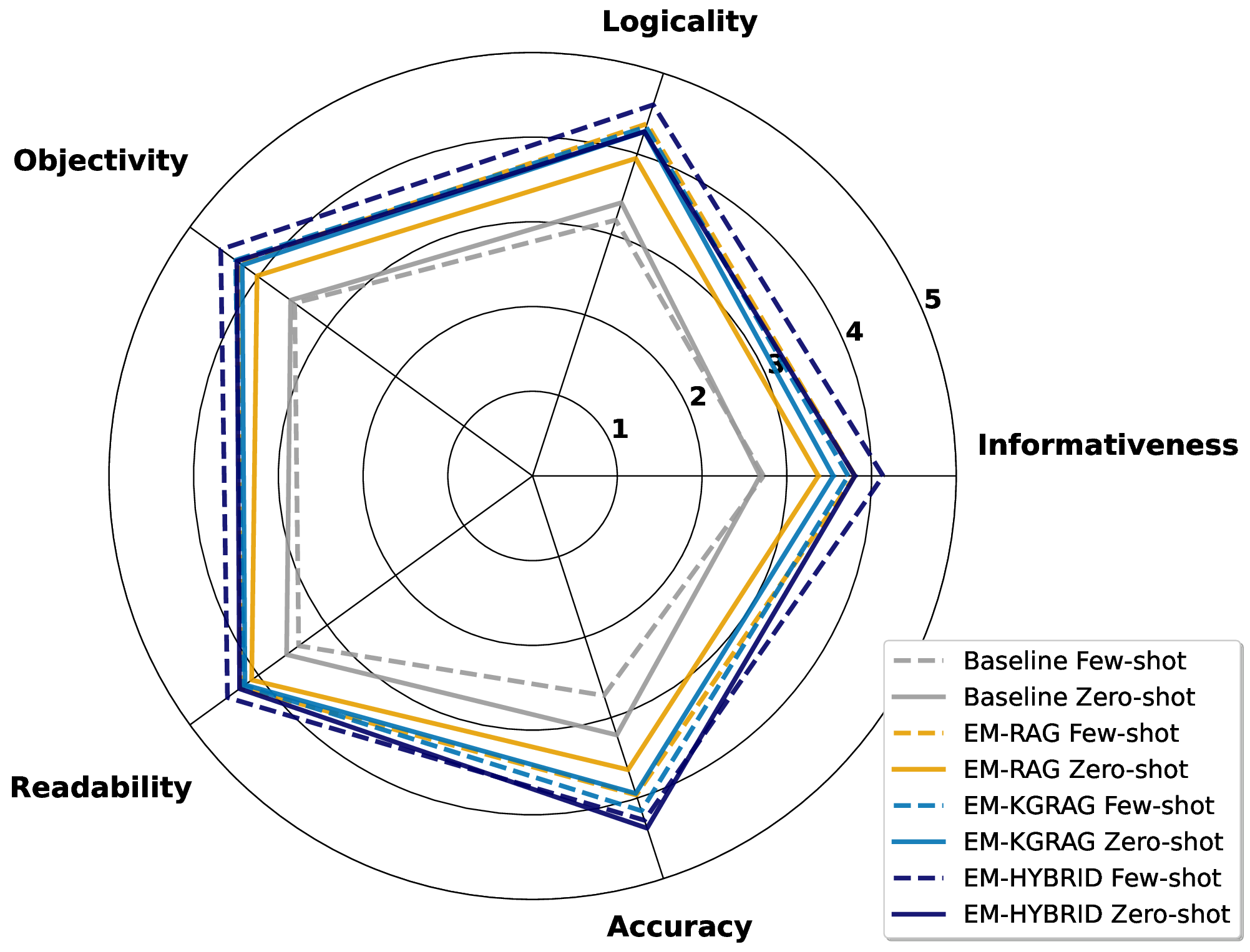
Second, the design space of RAG pipelines can be vast, with systems sourcing and combining information from diverse repositories (e.g., internal knowledge bases, web data, ESG reports). This leads to highly variable outputs that depend heavily on retrieval quality and prompting strategies and sensitivities that are further amplified by the ambiguity inherent in the definition of greenwashing [3]. In highstakes domains like sustainability, a simple true/false label is insufficient; models must provide evidence-backed justifications to ensure trust and accountability among stakeholders [38,30,20,29]. Accuracy-focused evaluation can be misleading, as high scores may result from excessive absten-tions, i.e., cases where the system does not make a judgment, or ungrounded guesses, both of which obscure the system’s reasoning and limit practical adoption. For real-world use, RAG-based systems must maintain high coverage, balancing accuracy with comprehensive, evidence-backed assessments. In this respect, the challenge lies in designing a suitable RAG pipeline that maximizes the number of claims assessed with well-supported, evidence-based justifications, while minimizing both the unsupported predictions and abstentions.
Third, a major obstacle for training, fine-tuning, and evaluating greenwashing detection pipelines remains the scarcity of annotated datasets [3]. While domain-specific fine-tuning yields superior performance [21], it requires substantial annotated data, which is costly, time-intensive to create, and demands significant domain expertise. Overall, the greenwashing detection problem can be defined as: Given a textual sustainability claim, determine whether it constitutes greenwashing and provide a fact-based justification; if the evidence is insufficient, abstain from issuing a verdict.
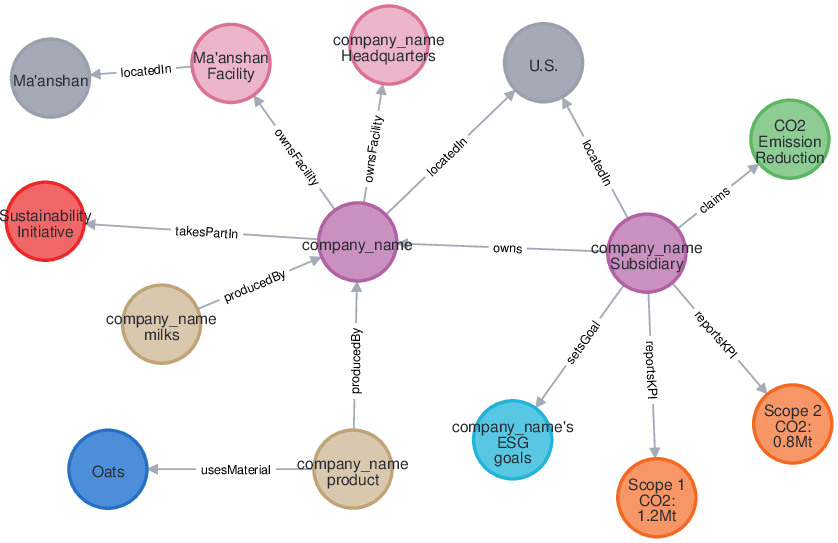
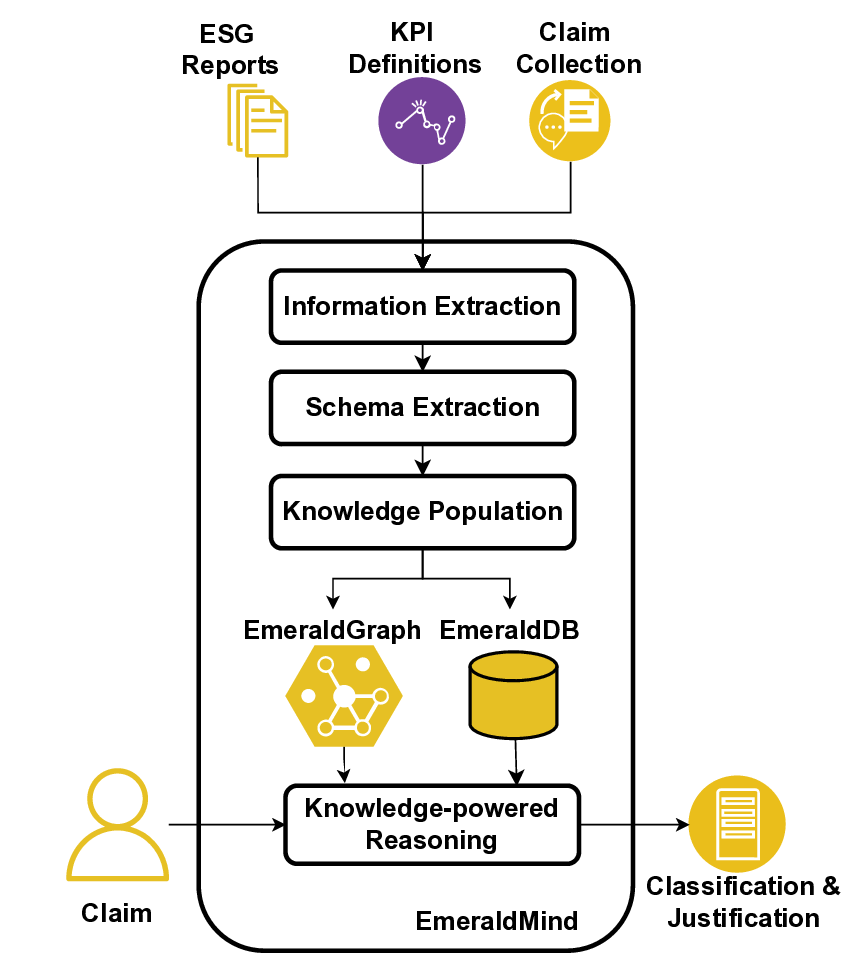
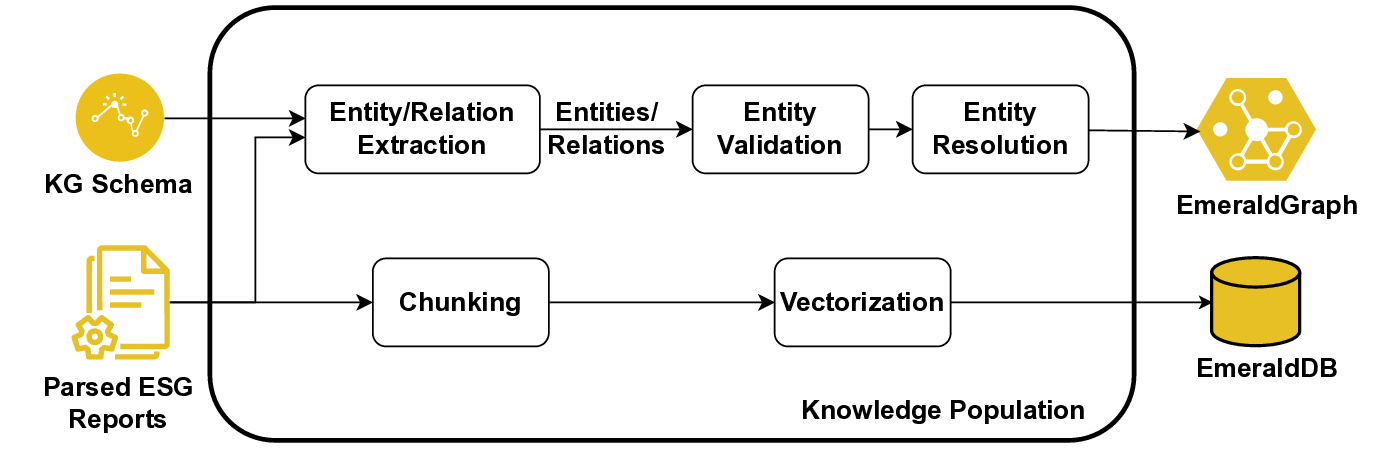
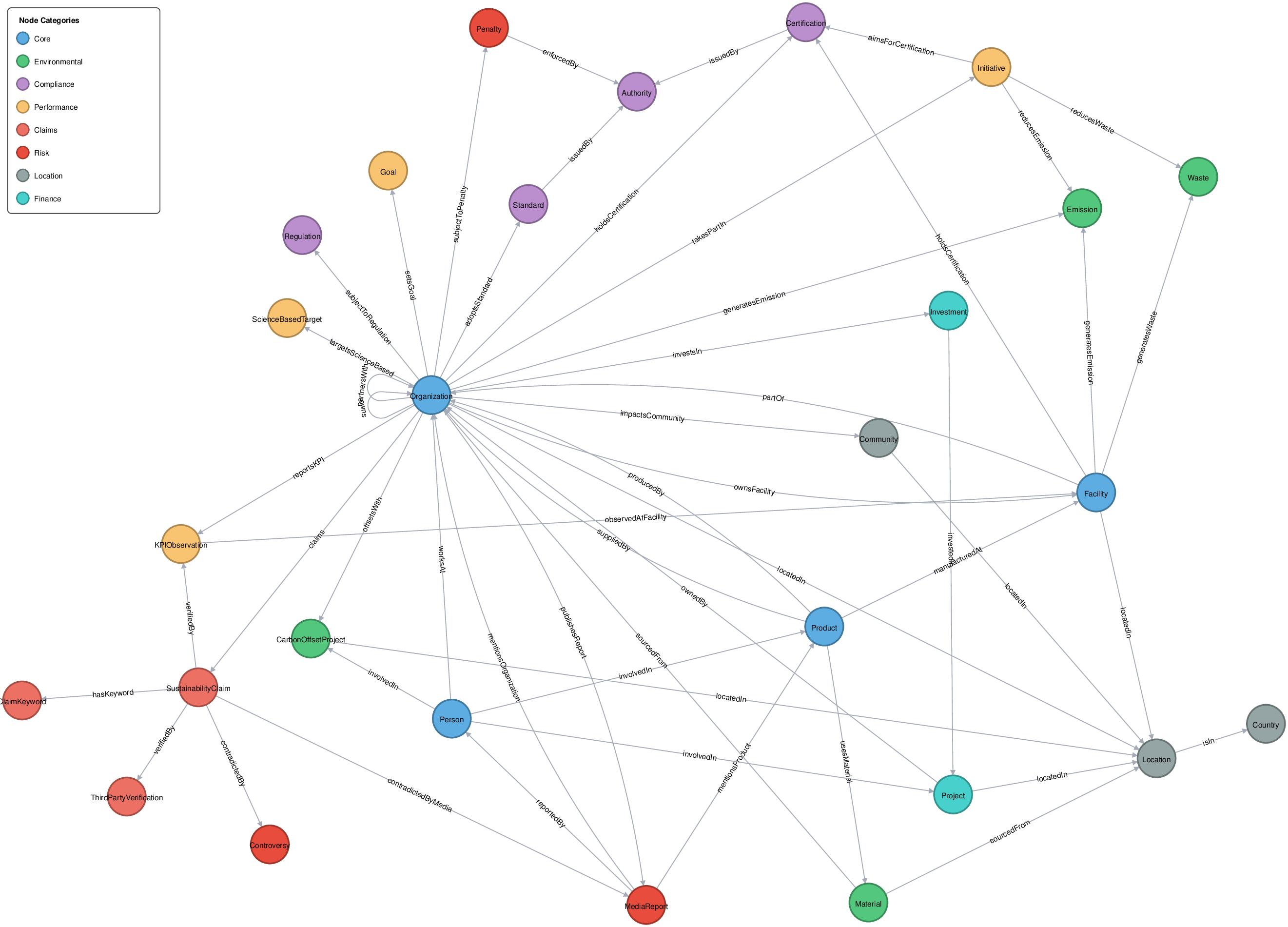
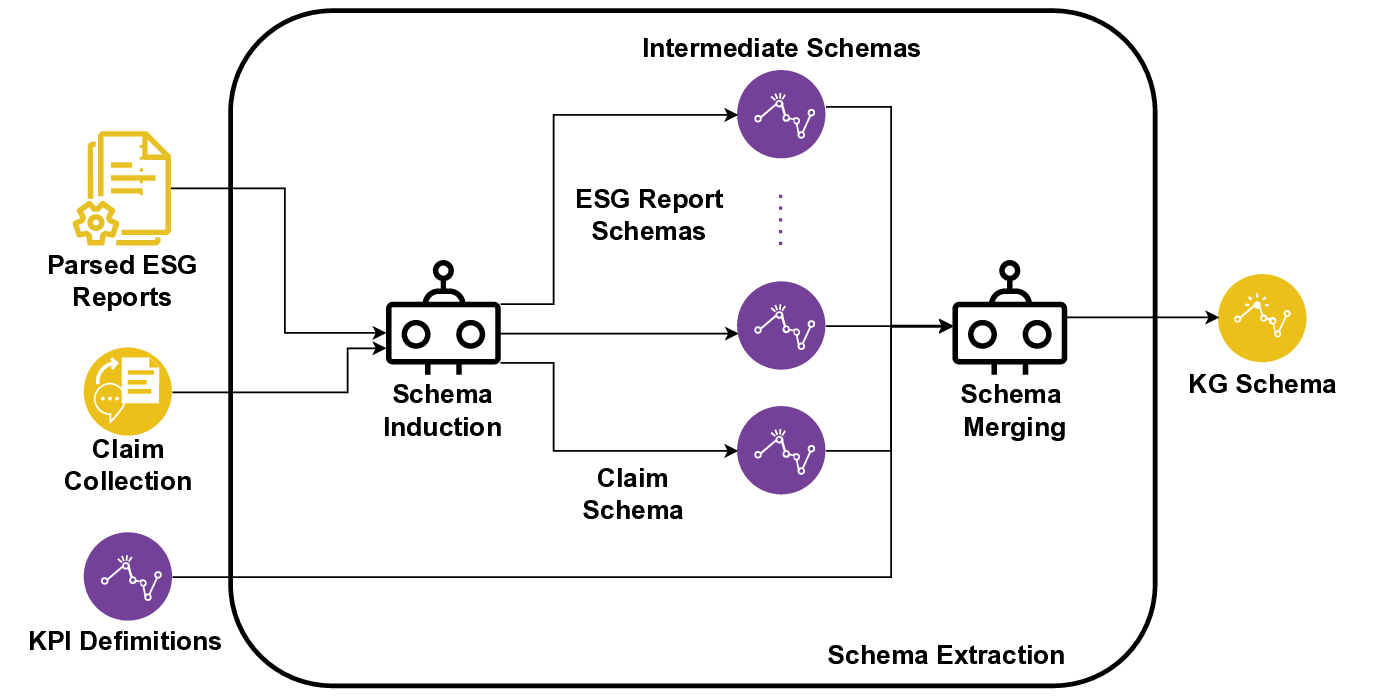
In this paper, we propose EmeraldMind, which is a domain-specific RAG framework for greenwashing detection. Our framework is built on two complementary custom sustainability knowledge stores: the EmeraldGraph that captures ESG-specific entities and relations, as extracted from ESG reports, KPI definitions [9], and widely known greenwashing claim examples, and the EmeraldDB that captures raw ESG text, with tailored retrieval mechanisms to gather relevant evidence for each claim. By grounding LLM reasoning in this domain-specific knowledge, our system produces a verdict plus an evidence-backed justification, or abstains when insufficient facts exist, enabling auditable outputs that address accuracy-only evaluation limitations. To evaluate our framework, we propose a semi-synthetic data benchmark named EmeraldData, which ca
This content is AI-processed based on open access ArXiv data.