📝 Original Info Title: Log Anomaly Detection with Large Language Models via Knowledge-Enriched FusionArXiv ID: 2512.11997Date: 2025-12-12Authors: Anfeng Peng, Ajesh Koyatan Chathoth, Stephen Lee📝 Abstract System logs are a critical resource for monitoring and managing distributed systems, providing insights into failures and anomalous behavior. Traditional log analysis techniques, including template-based and sequence-driven approaches, often lose important semantic information or struggle with ambiguous log patterns. To address this, we present EnrichLog, a training-free, entry-based anomaly detection framework that enriches raw log entries with both corpus-specific and sample-specific knowledge. EnrichLog incorporates contextual information, including historical examples and reasoning derived from the corpus, to enable more accurate and interpretable anomaly detection. The framework leverages retrieval-augmented generation to integrate relevant contextual knowledge without requiring retraining. We evaluate EnrichLog on four large-scale system log benchmark datasets and compare it against five baseline methods. Our results show that EnrichLog consistently improves anomaly detection performance, effectively handles ambiguous log entries, and maintains efficient inference. Furthermore, incorporating both corpus- and sample-specific knowledge enhances model confidence and detection accuracy, making EnrichLog well-suited for practical deployments.
💡 Deep Analysis
📄 Full Content Log Anomaly Detection with Large Language Models via
Knowledge-Enriched Fusion
Anfeng Peng
University of Pittsburgh
Pittsburgh, USA
Ajesh Koyatan Chathoth
Eaton Corporation
Pittsburgh, USA
Stephen Lee
University of Pittsburgh
Pittsburgh, USA
Abstract
System logs are a critical resource for monitoring and managing
distributed systems, providing insights into failures and anomalous
behavior. Traditional log analysis techniques, including template-
based and sequence-driven approaches, often lose important se-
mantic information or struggle with ambiguous log patterns. To
address this, we present EnrichLog, a training-free, entry-based
anomaly detection framework that enriches raw log entries with
both corpus-specific and sample-specific knowledge. EnrichLog
incorporates contextual information, including historical examples
and reasoning derived from the corpus, to enable more accurate
and interpretable anomaly detection. The framework leverages
retrieval-augmented generation to integrate relevant contextual
knowledge without requiring retraining. We evaluate EnrichLog
on four large-scale system log benchmark datasets and compare it
against five baseline methods. Our results show that EnrichLog con-
sistently improves anomaly detection performance, effectively han-
dles ambiguous log entries, and maintains efficient inference. Fur-
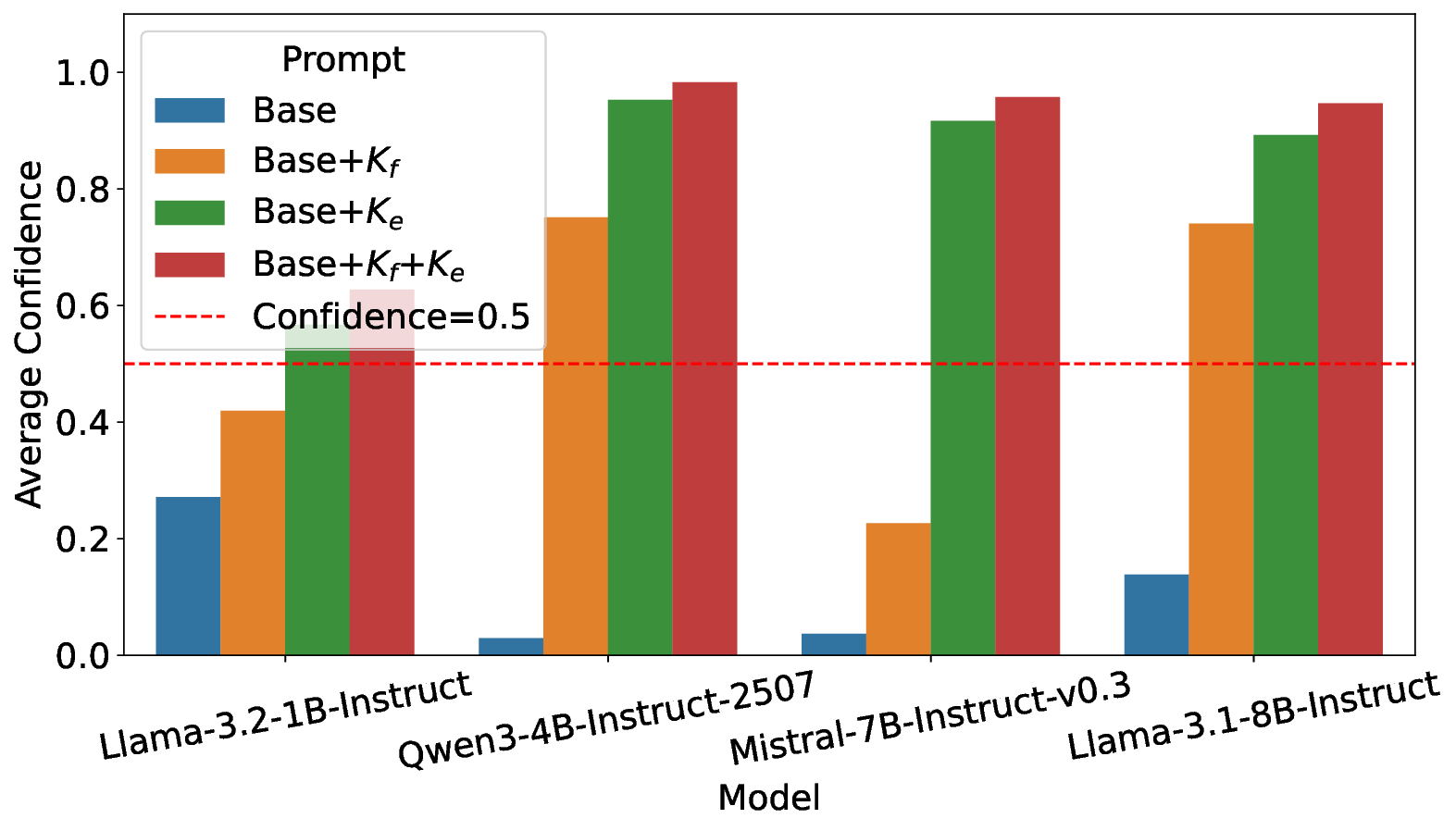
thermore, incorporating both corpus- and sample-specific knowl-
edge enhances model confidence and detection accuracy, making
EnrichLog well-suited for practical deployments.
Keywords
Anomaly Detection, Artificial Intelligence, Large Language Model
ACM Reference Format:
Anfeng Peng, Ajesh Koyatan Chathoth, and Stephen Lee. 2018. Log Anomaly
Detection with Large Language Models via Knowledge-Enriched Fusion. In
Proceedings of Make sure to enter the correct conference title from your rights
confirmation email (Conference acronym ’XX). ACM, New York, NY, USA,
12 pages. https://doi.org/XXXXXXX.XXXXXXX
1
Introduction
System logs are a vital source of operational intelligence in large-
scale distributed systems used for diagnosing system failures, iden-
tifying performance degradations, and potential security incidents.
In production environments, these logs are continuously streamed
from thousands of microservices, containers, and infrastructure
components, producing petabyte-scale datasets that capture rich
temporal and contextual information about system behavior [17, 21,
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for profit or commercial advantage and that copies bear this notice and the full citation
on the first page. Copyrights for components of this work owned by others than the
author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or
republish, to post on servers or to redistribute to lists, requires prior specific permission
and/or a fee. Request permissions from permissions@acm.org.
Conference acronym ’XX, Woodstock, NY
© 2018 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 978-1-4503-XXXX-X/2018/06
https://doi.org/XXXXXXX.XXXXXXX
38]. These logs contain critical system events that provide valuable
evidence for detecting anomalies, such as system malfunctions, mis-
configurations, or security breaches [1, 6, 15, 40]. As such, timely
and accurate analysis of these logs is essential to prevent cascading
failures and ensure system security and reliability.
Despite their importance, anomaly detection from system logs
remains challenging. Logs are often semi-structured, containing
both structured metadata (e.g., timestamps) and unstructured free-
text messages. In addition, log formats often differ across systems,
services, and software versions, making it difficult to design a single
model that generalizes effectively across diverse environments. To
address this, logs are first processed using a log parser that extracts
log templates and converts raw entries into structured represen-
tations. These structured log templates are then analyzed using
rule-based or machine learning-based techniques to detect anoma-
lous patterns [6]. However, due to the wide variation in log formats
across systems, separate models are often required for each environ-
ment, limiting their scalability. Moreover, log parsers themselves
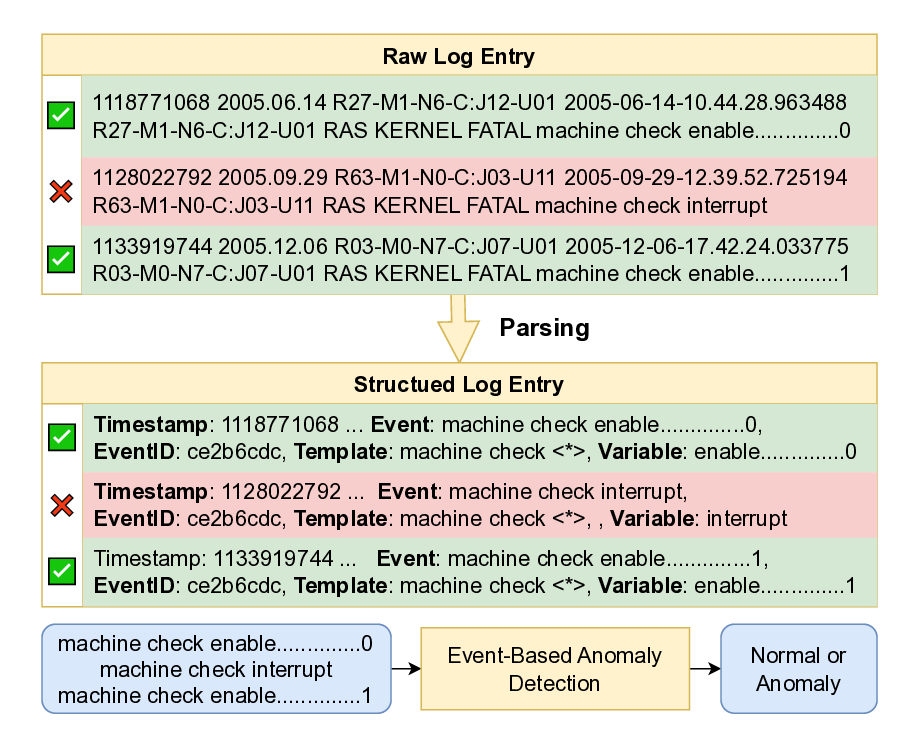
can introduce errors. Syntax-based log parsers that use predefined
or heuristics to extract log templates may map both normal and
anomalous events to the same log template (see Figure 1). When
downstream models analyze only on these templates, they risk
missing contextual signals in the raw log text, which may cause
false positives and missed anomalies.
Recent advances in large language models (LLMs) have moti-
vated researchers to explore template-driven log anomaly detection
with retrieval-augmented generation (RAG) [12, 24, 37, 49]. In these
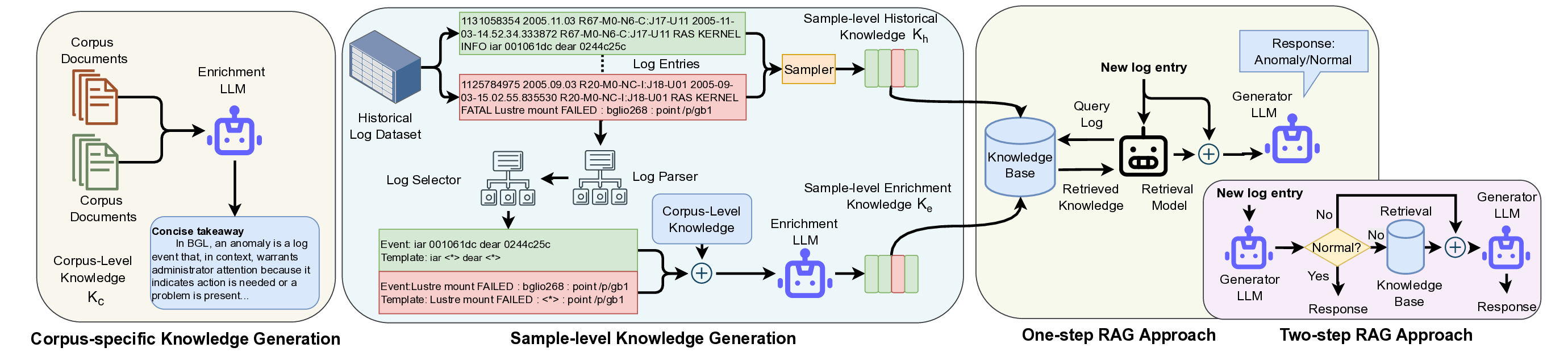
approaches, annotated log templates are
📸 Image Gallery
Reference This content is AI-processed based on open access ArXiv data.