Large Language Models (LLMs) are increasingly embedded in academic writing practices. Although numerous studies have explored how researchers employ these tools for scientific writing, their concrete implementation, limitations, and design challenges within the literature review process remain underexplored. In this paper, we report a user study with researchers across multiple disciplines to characterize current practices, benefits, and \textit{pain points} in using LLMs to investigate related work. We identified three recurring gaps: (i) lack of trust in outputs, (ii) persistent verification burden, and (iii) requiring multiple tools. This motivates our proposal of six design goals and a high-level framework that operationalizes them through improved related papers visualization, verification at every step, and human-feedback alignment with generation-guided explanations. Overall, by grounding our work in the practical, day-to-day needs of researchers, we designed a framework that addresses these limitations and models real-world LLM-assisted writing, advancing trust through verifiable actions and fostering practical collaboration between researchers and AI systems.
The integration of Large Language Models (LLMs) into academic practices has seen a rapid and substantial increase, particularly since the release of ChatGPT in late 2022 (Liang et al. 2024;Kannan 2024;Quthor 2024). This accelerated adoption is evident across various scientific disciplines, with Computer Science papers exhibiting the most significant and fastest growth in LLM usage, reaching up to 17.5% of abstracts and 15.3% of introductions by February 2024 (Liang et al. 2024). These tools also used in scientific processes such as solving mathematical problems, assisting with proofs, generating code, and discovering patterns in large datasets (Liang et al. 2024;Kannan 2024;Si, Yang, and Hashimoto 2024). The widespread diffusion of these technologies is transforming both how research is conducted and disseminated (Kannan 2024).
Within this broader landscape, their role in literature reviews sections has gained particular attention, as AI tools can rapidly scan vast databases, identify relevant studies, summarize findings, and highlight emerging themes (Quthor 2024). However, these tools have several drawbacks, such as the tendency to generate fabricated information, known as “hallucinations,” which requires rigorous post-hoc human validation for scientific accuracy (Liang et al. 2024;Bolanos et al. 2024;Salimi and Hajinia 2024). Usability remains a barrier for many existing tools, combining workflow misalignment and reliability issues with the cognitive effort required to craft precise and effective prompts (Bolanos et al. 2024;Salimi and Hajinia 2024).
Although prior work has explored how researchers engage with Generative AI (GenAI) for academic writing (Liao et al. 2024;Bail 2024;Gruda 2024), the practical aspects of this engagement-how researchers structure their LLMbased pipelines, what limitations they encounter, and which strategies they adopt during the literature review processremain underexplored. In this paper, our goal is to characterize these concrete challenges researchers face when using GenAI for literature review-particularly workflow integration, and trust in model outputs-and to uncover the design bottlenecks that limit current tools and practices. We conducted a user study across different domains, based on the following research questions:
RQ1. Adoption and Use. How do researchers integrate GenAI, particularly LLM-based systems, into the process of writing literature reviews?
RQ2. Benefits, Challenges and Validation. What benefits and challenges do researchers encounter when employing GenAI for literature review, and how do researchers verify and ensure the reliability of information retrieved or generated by LLMs?
RQ3. Workflow. What end-to-end workflows emerge for literature review?
Main Findings. Based on semi-structured interviews, we found that our participants don’t trust AI to accurately retrieve or summarize related work due to frequent hallucinations and inaccuracies in generated content. They also move back and forth between verification and generation which leads to a fragmented workflow: researchers often use one tool to find sources, another to summarize or verify content, and a third to draft sections. To maintain accuracy, they rely heavily on verification-cross-checking retrieved papers against original PDFs or DOIs and ensuring that generated findings align with the source material-and on prompt engineering, using instructions such as “preserve the author’s intent” or “not to change my writing style”. While these practices are necessary, they are time-consuming, inefficient, and demand considerable effort.
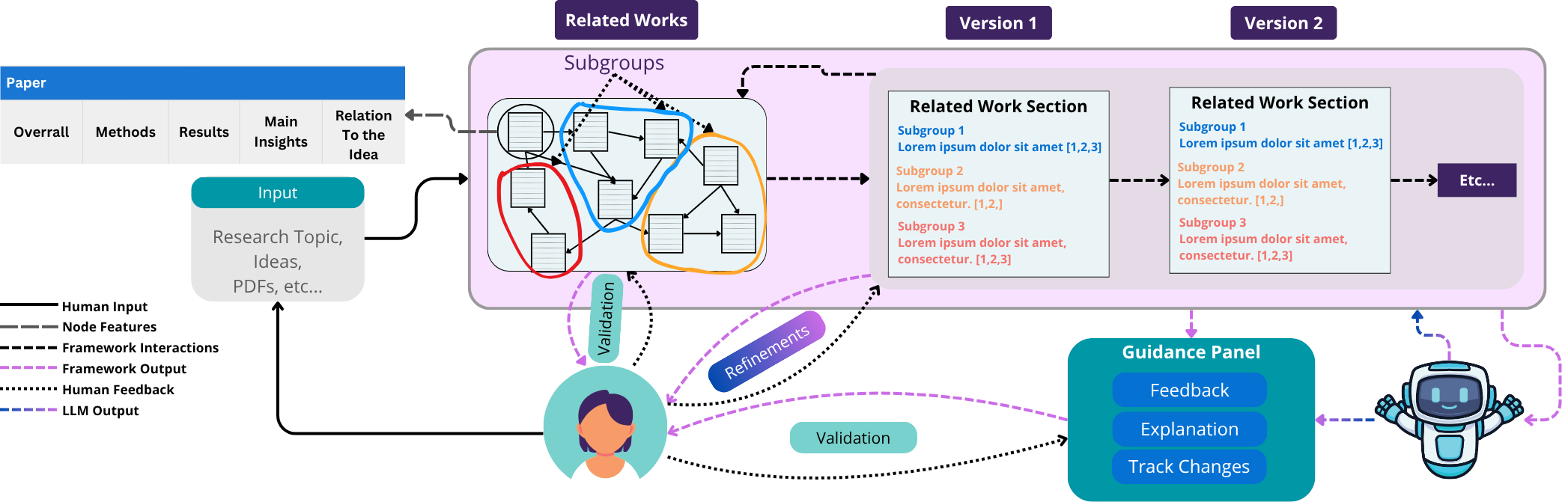
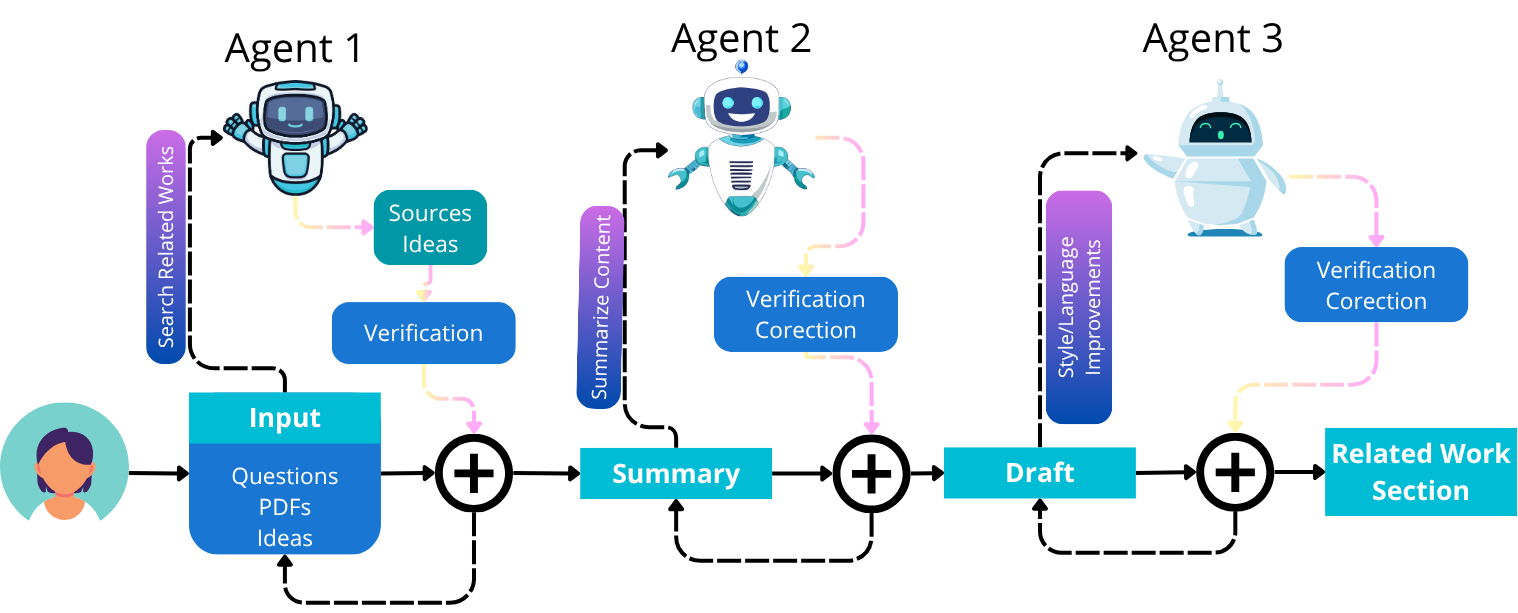
Contribution. Based on the empirical findings, we propose six design goals for future LLM-based research assistants that emphasize knowledge organization and comparison, citation grounding with stable revisions, preserving author preferences, and guided interaction with transparent rationales. In addition, we propose a high-level framework that operationalizes such goals with human-in-the-loop validation and iterative feedback. We emphasize that GenAI should not function merely as an independent text generator or reviewer, but as an assistant that actively supports researchers in developing their work in a reliable and trustworthy manner.
In addition to the plethora of GenAI applications in research, unified AI frameworks for scientific discovery aim to create autonomous research assistants capable of hypothesis generation, experiment design, and literature synthesis (Reddy and Shojaee 2025). These “AI scientists” could significantly accelerate cross-domain innovation, provided collaboration continues among AI researchers, domain experts, and philosophers of science (Reddy and Shojaee 2025). While fully autonomous discovery remains aspirational, near-term developments promise hybrid systems that augment human scientific reasoning and creativity.
Agentic AI extends traditional generative systems by endowing them with autonomy, reasoning, and goal-oriented beha
This content is AI-processed based on open access ArXiv data.