Title: Condensation-Concatenation Framework for Dynamic Graph Continual Learning
ArXiv ID: 2512.11317
Date: 2025-12-12
Authors: Tingxu Yan, Ye Yuan
📝 Abstract
Dynamic graphs are prevalent in real-world scenarios, where continuous structural changes induce catastrophic forgetting in graph neural networks (GNNs). While continual learning has been extended to dynamic graphs, existing methods overlook the effects of topological changes on existing nodes. To address it, we propose a novel framework for continual learning on dynamic graphs, named Condensation-Concatenation-based Continual Learning (CCC). Specifically, CCC first condenses historical graph snapshots into compact semantic representations while aiming to preserve the original label distribution and topological properties. Then it concatenates these historical embeddings with current graph representations selectively. Moreover, we refine the forgetting measure (FM) to better adapt to dynamic graph scenarios by quantifying the predictive performance degradation of existing nodes caused by structural updates. CCC demonstrates superior performance over state-of-the-art baselines across four real-world datasets in extensive experiments.
💡 Deep Analysis
📄 Full Content
1
Condensation-Concatenation Framework for
Dynamic Graph Continual Learning
1st Tingxu Yan
College of Computer and Information Science
Southwest University
ChongQing, China
929549561@qq.com
2nd Ye Yuan*
College of Computer and Information Science
Southwest University
ChongQing, China
*yuanyekl@swu.edu.cn
Abstract
Dynamic graphs are prevalent in real-world scenarios, where continuous structural changes induce catastrophic forgetting in
graph neural networks (GNNs). While continual learning has been extended to dynamic graphs, existing methods overlook the
effects of topological changes on existing nodes. To address it, we propose a novel framework for continual learning on dynamic
graphs, named Condensation-Concatenation-based Continual Learning (CCC). Specifically, CCC first condenses historical graph
snapshots into compact semantic representations while aiming to preserve the original label distribution and topological properties.
Then it concatenates these historical embeddings with current graph representations selectively. Moreover, we refine the forgetting
measure (FM) to better adapt to dynamic graph scenarios by quantifying the predictive performance degradation of existing nodes
caused by structural updates. CCC demonstrates superior performance over state-of-the-art baselines across four real-world datasets
in extensive experiments.
Index Terms
Continual Learning, Dynamic Graphs, Catastrophic Forgetting
I. INTRODUCTION
Graphs serve as fundamental structures for modeling relational data in domains like social networks. Graph Neural Networks
(GNNs) have become the standard framework for graph representation learning with significant success. However, real-world
graphs are dynamic, continually evolving through the addition and deletion of nodes and edges. This temporal dimension
challenges conventional GNNs designed for static graphs, leading to catastrophic forgetting where learning new patterns
overwrites previously acquired knowledge.
Although continual learning research has expanded to dynamic graphs, evaluation frameworks lack graph-specific adaptations.
Metrics like forgetting rate, borrowed from static domains, fail to capture structural cascading effects. Existing methods employ
broad preservation strategies while overlooking that topological changes influence representations of numerous existing nodes.
To tackle these limitations, we propose the Condensation-Concatenation Framework for Dynamic Graph Continual Learning
(CCC) framework. CCC compresses historical graph snapshots into compact semantic representations and integrates them with
current embeddings through concatenation. This approach aims to capture structural change propagation while maintaining
representation stability.
Our contributions are:
• Identification of limitations in existing continual learning evaluation metrics for dynamic graphs.
• Proposal of the CCC framework combining graph condensation with feature concatenation.
• Comprehensive experimental validation demonstrating superior performance in balancing knowledge retention with new
information integration.
II. RELATED WORK
Graph Neural Networks. Graph Neural Networks (GNNs) [1] aim to apply deep learning to graph-structured data. The core
of their approach is to aggregate information from neighboring nodes for learning node representations. Graph Convolutional
Network (GCN) [2] established a spectral graph convolution framework through first-order neighborhood approximation.
GraphSAGE [3] proposed a framework based on sampling and aggregation instead of using all neighboring nodes.In addition,
numerous other GNN studies [4]–[80] have also made significant contributions and proven valuable in various graph learning
tasks.
arXiv:2512.11317v1 [cs.LG] 12 Dec 2025
2
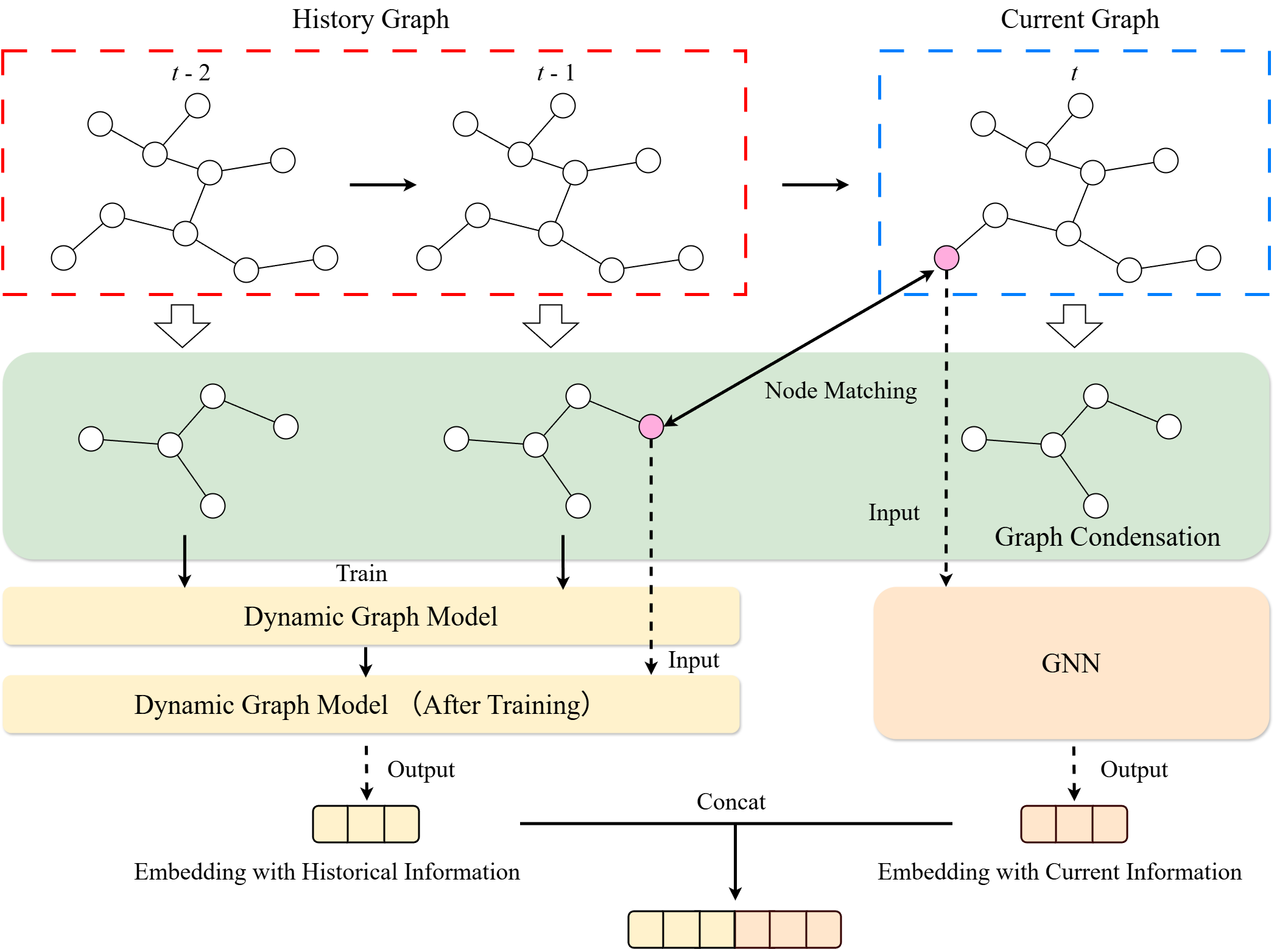
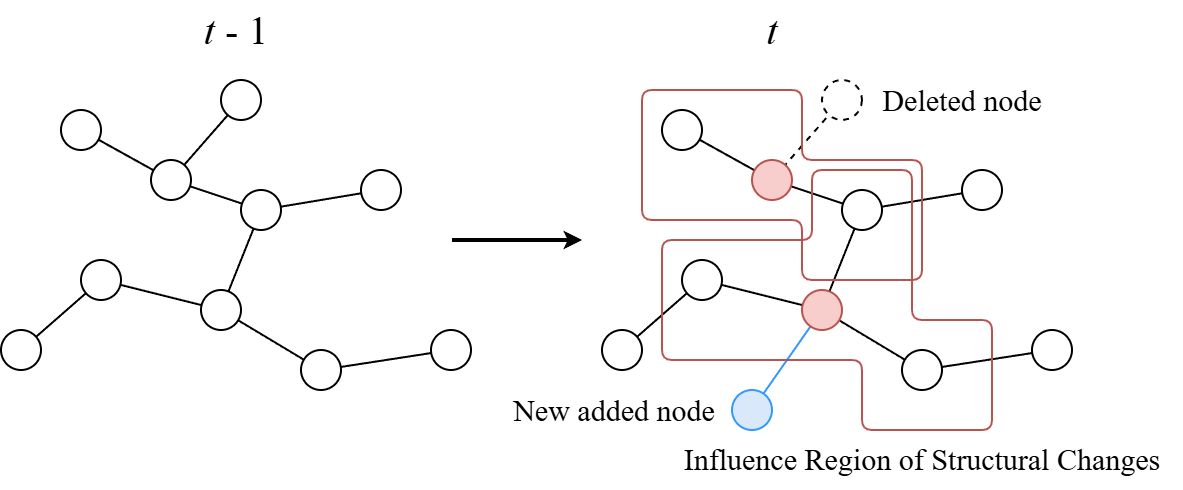
Fig. 1: An overview of CCC. The historical graph sequence is first condensed to capture historical information. Subsequently,
by detecting the k-hop structural change regions triggered by node and edge additions/deletions, the embeddings extracted
from the condensed historical graph are selectively concatenated with the current embeddings of the affected nodes.
Continual Learning. Continual learning allows models to learn from sequentially arriving data while avoiding catastrophic
forgetting of previously acquired knowledge. Existing approaches can be categorized into three groups:
Regularization-based methods protect learned knowledge by incorporating constraints into the loss function. TWP [81] applies
regularization based on parameter sensitivity to topological structures. DyGRAIN identifies affected nodes from a receptive
field perspective for selective updates.
Memory replay-based methods consolidate knowledge by storing and replaying historical data. ER-GNN [82] adopts multiple
strategies to select replay nodes. SSM uses sparsified subgraphs as memory units to retain topological information. DSLR [83]
selects replay nodes based on coverage and trains a link prediction module. PUMA condenses original grap