Title: Robust MLLM Unlearning via Visual Knowledge Distillation
ArXiv ID: 2512.11325
Date: 2025-12-12
Authors: Yuhang Wang, Zhenxing Niu, Haoxuan Ji, Guangyu He, Haichang Gao, Gang Hua
📝 Abstract
Recently, machine unlearning approaches have been proposed to remove sensitive information from well-trained large models. However, most existing methods are tailored for LLMs, while MLLM-oriented unlearning remains at its early stage. Inspired by recent studies exploring the internal mechanisms of MLLMs, we propose to disentangle the visual and textual knowledge embedded within MLLMs and introduce a dedicated approach to selectively erase target visual knowledge while preserving textual knowledge. Unlike previous unlearning methods that rely on output-level supervision, our approach introduces a Visual Knowledge Distillation (VKD) scheme, which leverages intermediate visual representations within the MLLM as supervision signals. This design substantially enhances both unlearning effectiveness and model utility. Moreover, since our method only fine-tunes the visual components of the MLLM, it offers significant efficiency advantages. Extensive experiments demonstrate that our approach outperforms state-of-the-art unlearning methods in terms of both effectiveness and efficiency. Moreover, we are the first to evaluate the robustness of MLLM unlearning against relearning attacks.
💡 Deep Analysis
📄 Full Content
Robust MLLM Unlearning via Visual Knowledge Distillation
Yuhang Wang 1 Zhenxing Niu 1 Haoxuan Ji 2 Guangyu He 1 Haichang Gao 1 Gang Hua 3
Abstract
Recently, LLM unlearning approaches have been
proposed to remove sensitive information from
well-trained large models.
However, unlearn-
ing for Multimodal Large Language Models
(MLLMs) remains at an early stage. Inspired
by recent studies on the internal mechanisms of
MLLMs, we propose to disentangle visual and
textual knowledge within MLLMs and introduce
a dedicated approach that selectively erases target
visual knowledge while preserving textual knowl-
edge. Unlike previous unlearning methods that
rely on output-level supervision, our approach in-
troduces a Visual Knowledge Distillation (VKD)
scheme, which leverages intermediate visual rep-
resentations within the MLLM as supervision sig-
nals. This design substantially enhances both un-
learning effectiveness and model utility. More-
over, since our method only fine-tunes the visual
components of MLLM, it offers significant effi-
ciency advantages. Extensive experiments demon-
strate that our approach outperforms state-of-the-
art unlearning methods in terms of both effective-
ness and efficiency. Furthermore, we are the first
to evaluate the robustness of MLLM unlearning
against re-learning attacks.
1. Introduction
Recently, Multimodal Large Language Models (MLLMs)
have achieved remarkable progress. However, growing con-
cerns over data privacy have become a significant barrier
to the widespread application of LLMs and MLLMs. This
is because training large models typically involves the use
of vast amounts of Internet data, which often contain sensi-
tive personal information such as social security numbers
or personal photographs. Moreover, numerous studies (Pi
et al., 2024; Li et al., 2024a; Cohen et al., 2024) have shown
that large models can memorize portions of their training
1Xidian
University,
China
2XJTU
University,
China
3Amazon.com,
USA. Correspondence to:
Zhenxing Niu
.
data and reproduce them verbatim in their outputs. This
poses a substantial risk of privacy leakage. Therefore, the
advent of data privacy and protection regulations—such as
the European Union’s GDPR (Regulation, General Data
Protection, 2018) and the California Consumer Privacy Act
(CCPA) (Goldman, 2020)—now mandates these large model
providers to honor data deletion requests from individu-
als (Dang, 2021).
The most straightforward approach to protecting privacy is
to discard the trained model entirely, remove the individual’s
data from the training set, and retrain a new model from
scratch. However, retraining is computationally expensive
and resource-intensive, particularly for large models. As a
result, the field of machine unlearning (Garg et al., 2020;
Ginart et al., 2019; Cao & Yang, 2015; Gupta et al., 2021;
Sekhari et al., 2021; Brophy & Lowd, 2021; Ullah et al.,
2021) has emerged, aiming to efficiently revise trained mod-
els by selectively forgetting specific data while preserving
performance on the remaining data. Nowadays, many LLM
unlearning methods have been proposed, such as Gradient
Ascent (GA) (Thudi et al., 2022), its variations (Liu et al.,
2022), and Negative Preference Optimization (NPO) (Zhang
et al., 2024), etc. However, MLLM unlearning remains at
an early stage.
LLM unlearning problem is clearly defined—erasing the
knowledge of a specific entity from the model. In contrast,
defining unlearning for MLLMs is far more complex, as two
distinct forms of knowledge are associated with the entity
of interest: textual knowledge, linked to the entity’s general
information, and visual knowledge/visual patterns, linked
to the entity’s appearance. For instance, for a well-known
individual, the name (e.g., “Robin Williams”) and textual
attributes (such as occupation or home address) constitute
the textual knowledge, while the person’s facial appear-
ance represents the visual knowledge. Consequently, there
remains ambiguity in defining MLLM unlearning: some
studies argue that it should involve erasing both textual and
visual knowledge (Liu et al., 2025), whereas others contend
that only the visual knowledge should be removed while
preserving the textual knowledge (Huo et al., 2025).
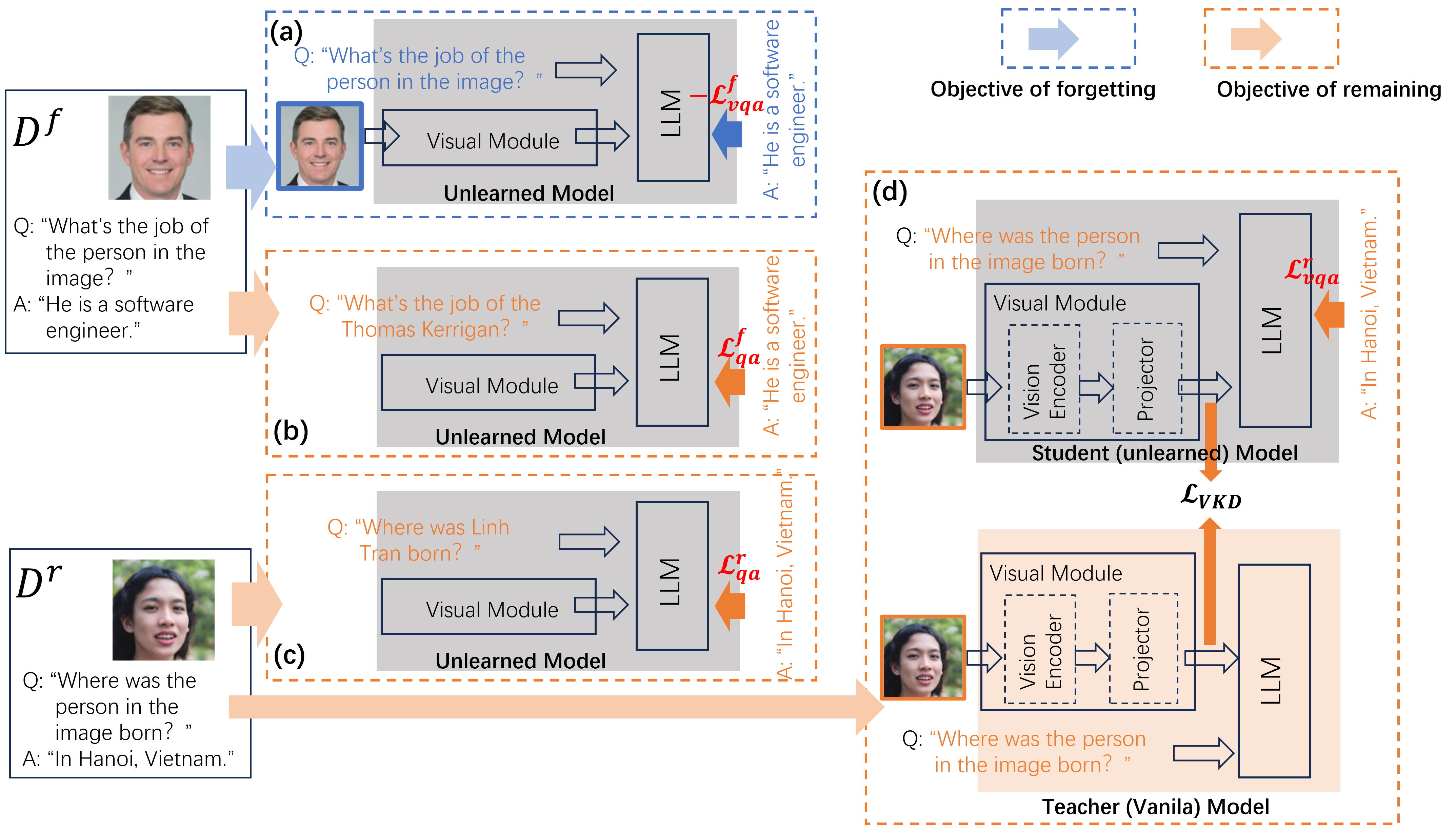
In this paper, we follow (Huo et al., 2025) to define the
MLLM unlearning objective as erasing visual knowledge
while preserving textual knowledge, as this formulation of-
1
arXiv:2512.11325v2 [cs.CV] 1 Feb 2026
Robust MLLM Unlearning via Visual Knowledge Distillation
fers greater flexibility. The essence of this definition lies
in disentangling visual and textual knowledge, thereby al-
lowing selective removal of either component when neces-
sary. Even when the goal is to erase both textual and visual
knowledge, this can be achieved by sequentially performing
MLLM unlearning followed by LLM unlearning.
An MLLM typically consists of three components: a vision
encoder, an LLM backbone, and a projector that bridges the
t