Large Language Models demonstrate strong reasoning and generation abilities, yet their behavior in multi-turn tasks often lacks reliability and verifiability. We present a task completion framework that enables LLM-based agents to act under explicit behavioral guidance in environments described by reinforcement learning formalisms with defined observation, action, and reward signals.
The framework integrates three components: a lightweight task profiler that selects reasoning and generation strategies, a reasoning module that learns verifiable observation - action mappings, and a generation module that enforces constraint-compliant outputs through validation or deterministic synthesis. We show that as the agent interacts with the environment, these components co-evolve, yielding trustworthy behavior.
Most real-world tasks from troubleshooting software to planning multi-step operations or interacting with users require agents to perform consistent action selection across turns and maintain constraint-compliant behavior generation throughout execution. Although recent advances (Yao et al. 2023;Shinn et al. 2023;Schick et al. 2023;Richards 2023;Packer et al. 2024;Wang et al. 2023;Nakajima 2023) in agentic LLMs have improved their task completion abilities through mechanisms such as memory, tool use, and reflection, these mechanisms remain largely implicit and difficult to guide or steer, making it challenging for those building agentic systems on top of these models to maintain verifiable and reliable task completion (Ganguly et al. 2025;Matton, Chen, and Grosse 2025).
Our goal is to provide LLM-based agents with a task completion framework that allows them to operate under explicit behavioral guidance. In this framework, trust denotes the agent’s capacity to act in ways that are both verifiable (its reasoning of action selection can be inspected and validated) and reliable (its generated behaviors consistently comply with task constraints and environment feedback) (Li 2025;de Cerqueira, Oliveira, and Rodrigues 2025).
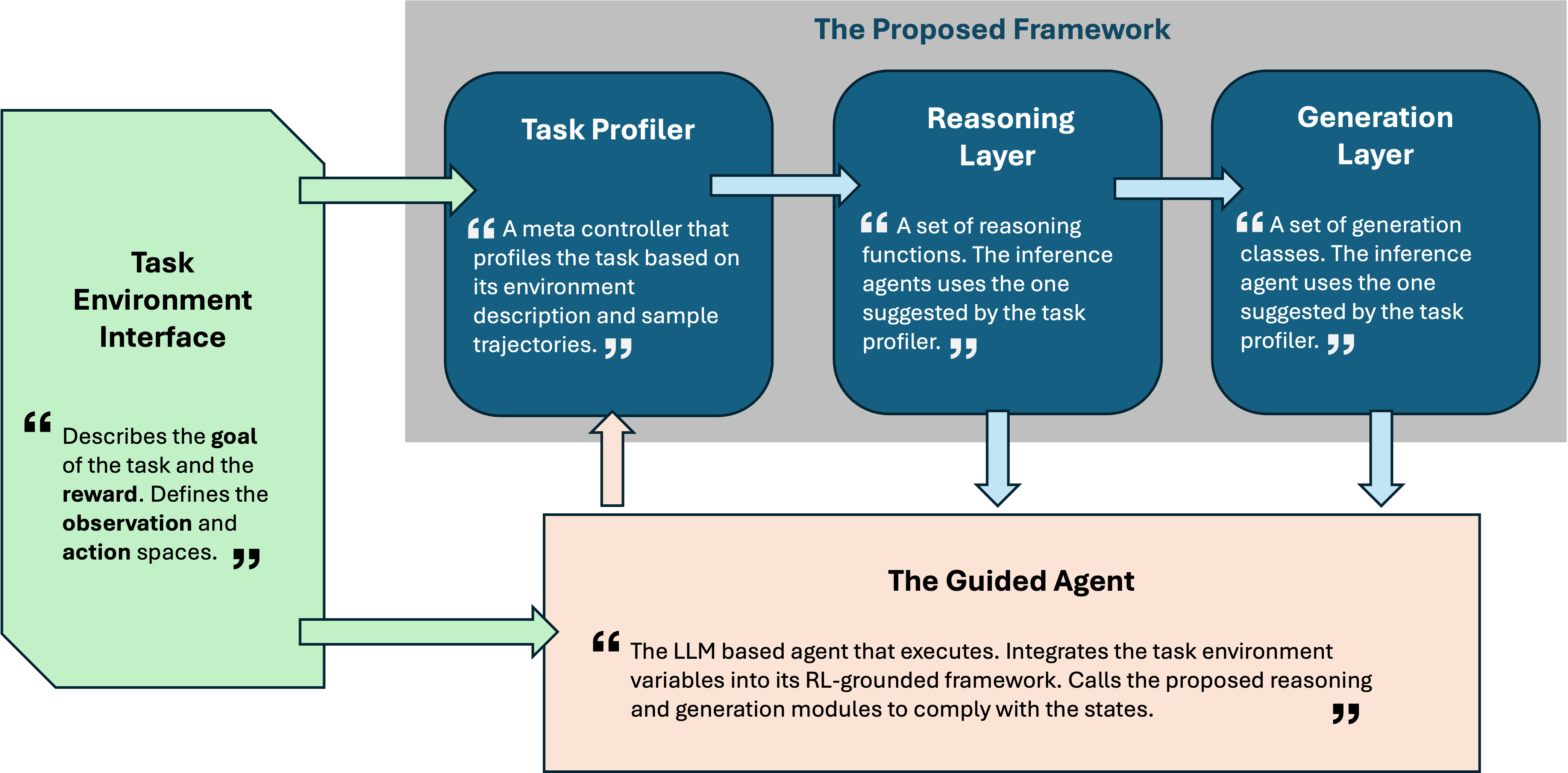
We target tasks described in reinforcement learning (RL) formalisms, where environments define actions, observa-tions, rewards. Within this setting, we develop a task completion framework that enables LLM agents to learn to act in a verifiable and reliable manner. Our framework has three main components as shown in Figure 1 and described below.
The first component is a lightweight task profiler that analyzes the given task environment variables. The profiler acts as a meta-learner, determines the task’s structural properties (e.g., temporal dependencies or constraint intensity), and guides the LLM agent toward the most suitable strategies for action selection and behavior generation.
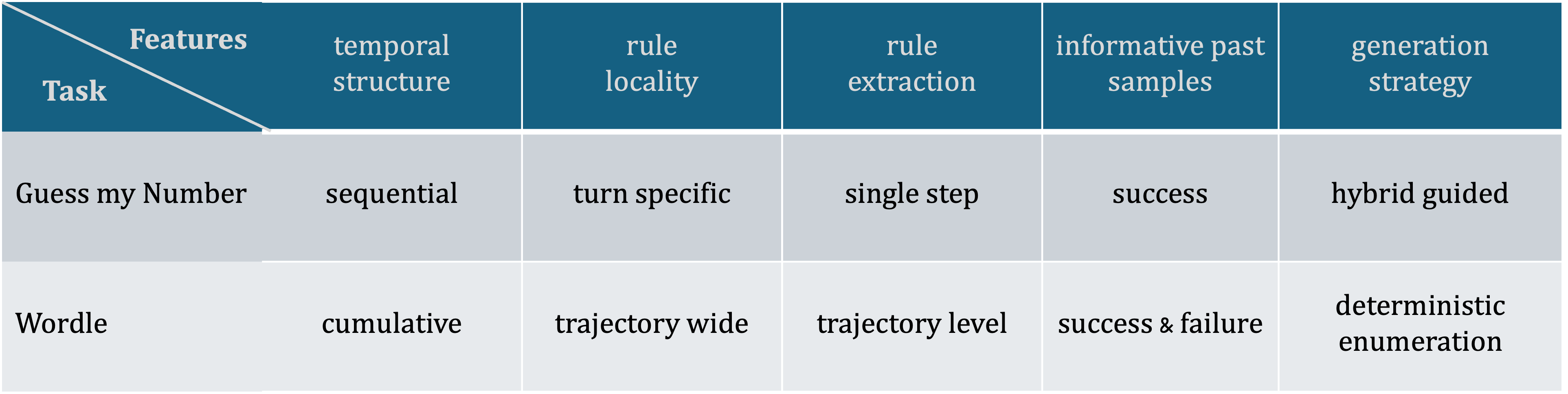
Building on this guidance, the second component, the reasoning module, governs the selection of structured actions across temporal windows. It analyzes past trajectories from the agent’s task executions and extracts observation-action mappings that consistently yield high rewards. Guided by the task profiler, the reasoning module can adapt its temporal scope: in tasks where success depends on short-term decisions, it focuses on single-turn mappings, whereas in temporally dependent tasks, it aggregates information over longer horizons. The extracted mappings are stored as a persistent procedural memory and integrated with the underlying LLM’s native reasoning during subsequent task executions. Throughout the paper, we refer to these mappings as rules and use two terms interchangeably1 .
Finally, the third component, the generation module, ensures constraint-compliant behavior generation by validating or revising the agent’s outputs so that they satisfy all task constraints and reasoning-derived mappings. Its compliance strategy is determined by the task profiler: for lightly constrained tasks, the module may simply verify the validity of the model’s native output, whereas for constraint-heavy tasks, it employs structured procedures such as deterministic enumeration or online code generation. In these cases, the module uses environment variables and reasoning mappings as input specifications to generate valid, verifiable outputs that align with task feedback.
As the agent executes a given task, these components interact continuously: the task profiler refines its understanding of the environment over epochs 2 . , the reasoning module progressively learns better observation-action map-Figure 1: The Proposed Framework pings from collected trajectories. , and the generation module evolves along it, adapting its output strategies to the updated reasoning state. Together, they steer the native behavior of the underlying LLM into a transparent, feedbackguided process where every action is both verifiable and reliable.
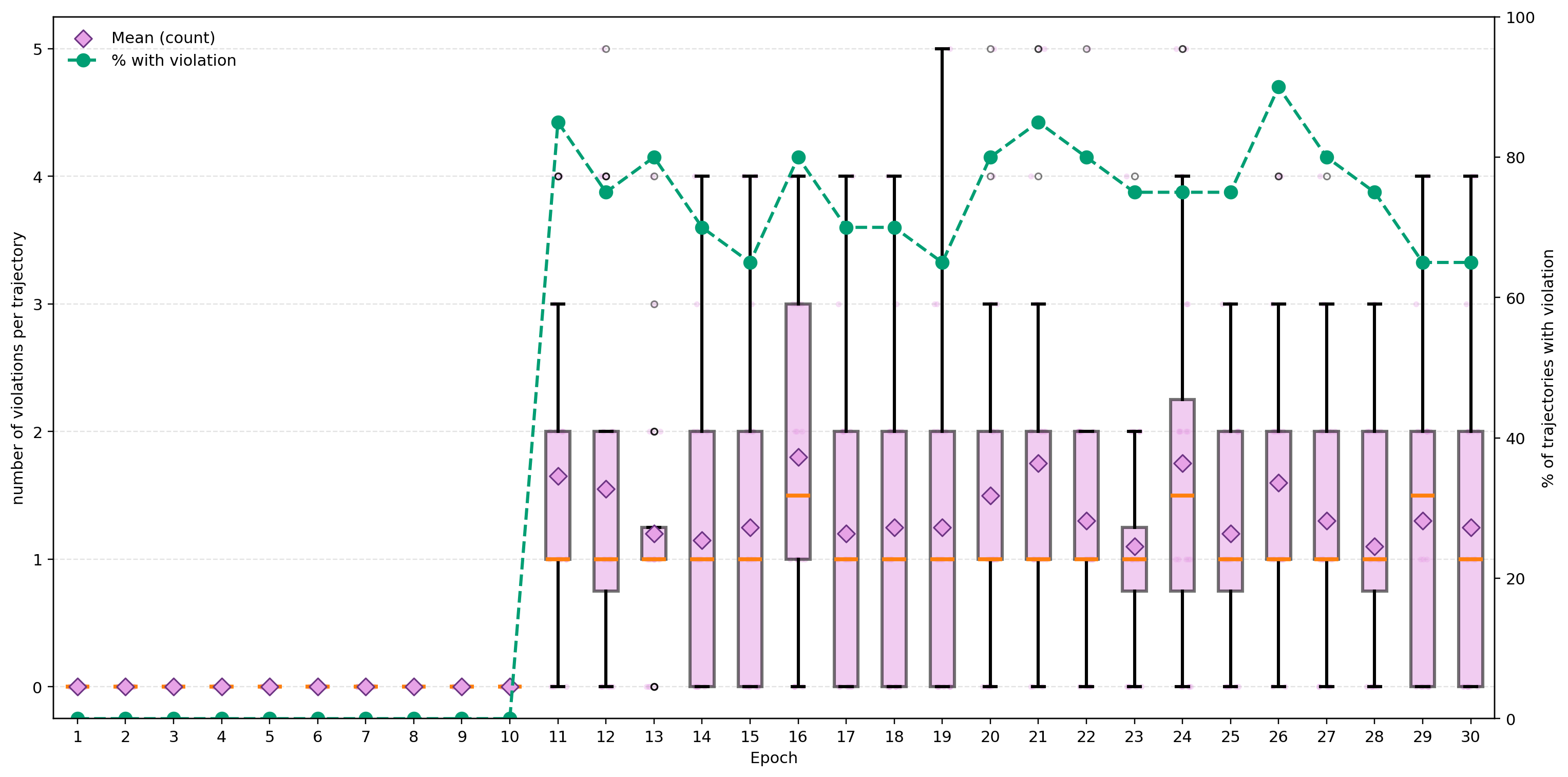
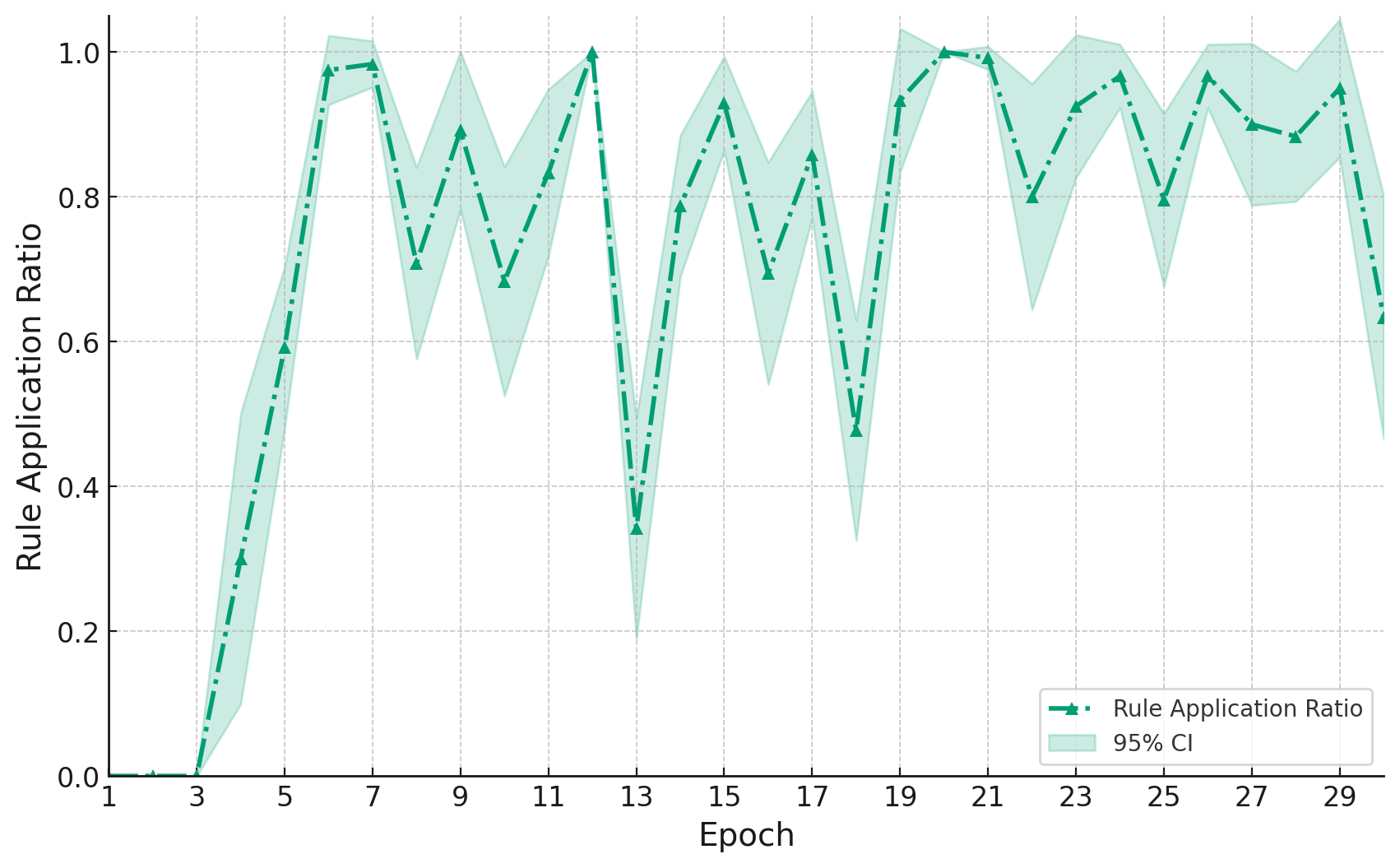
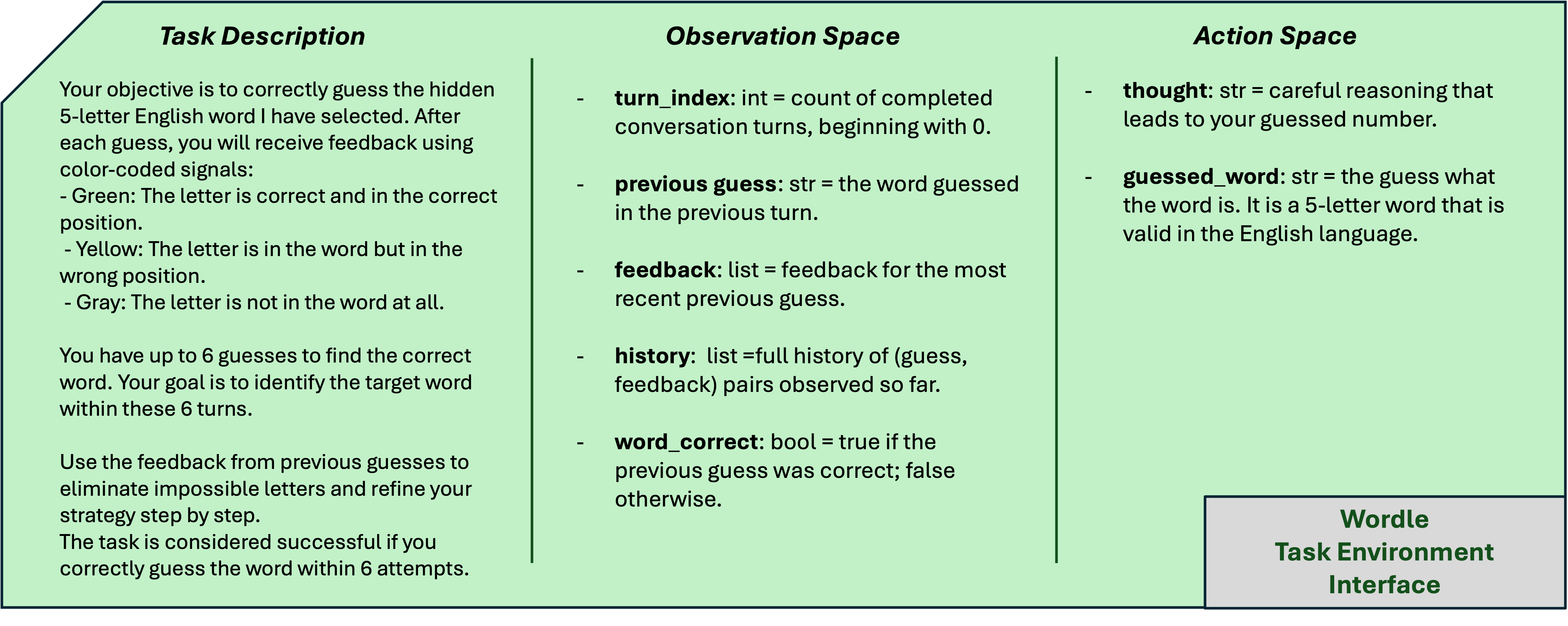
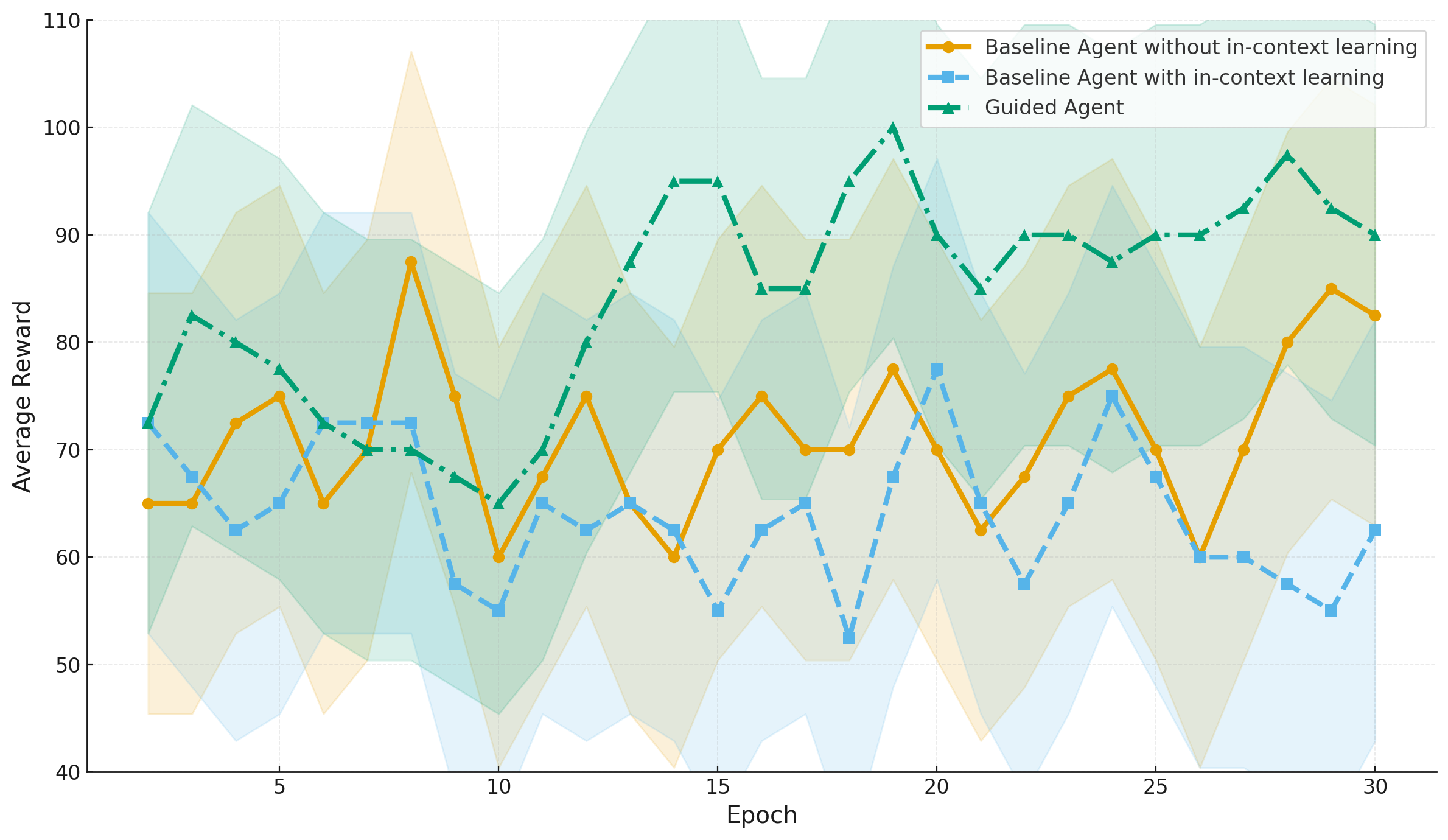
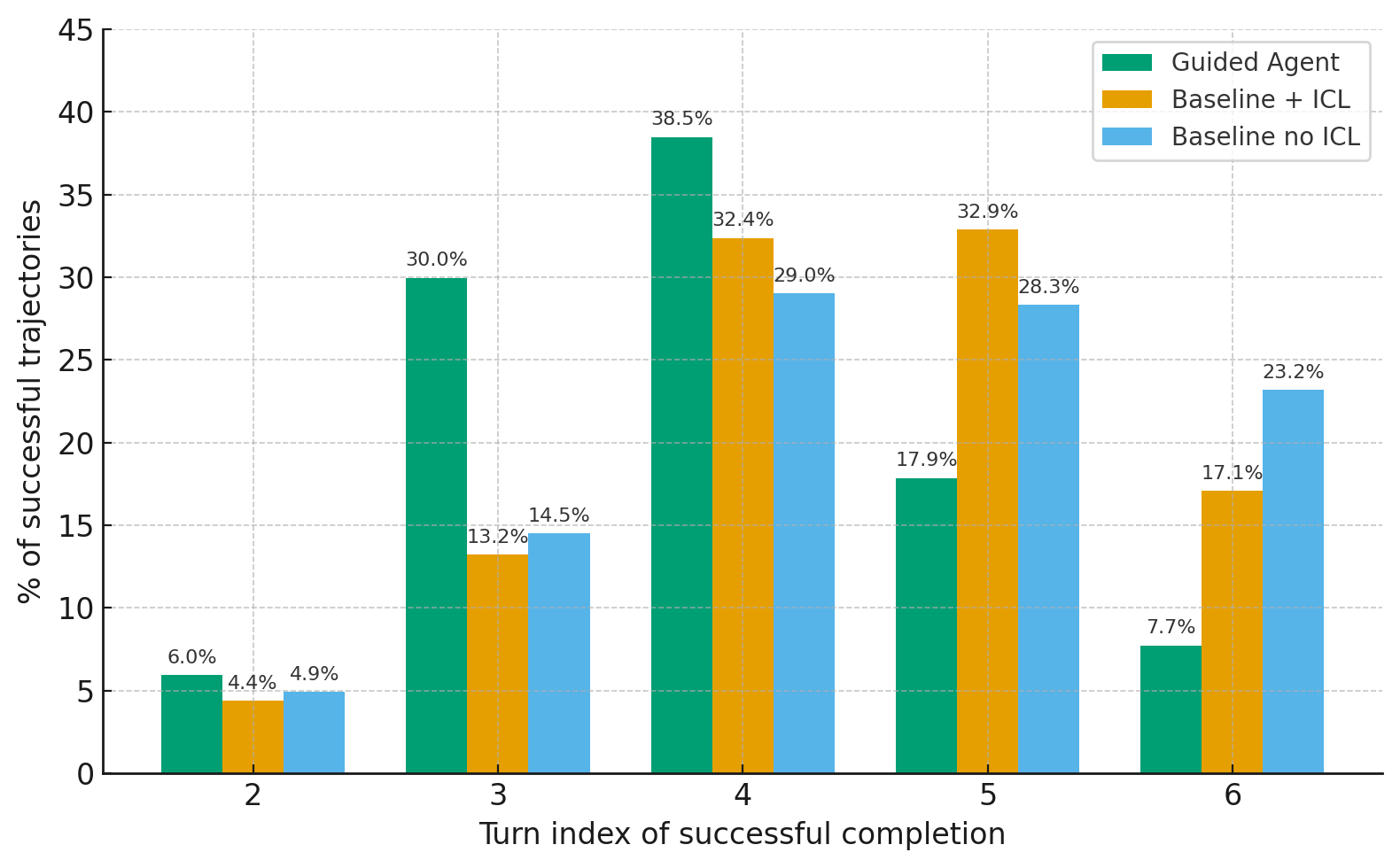
In this paper, we present the first evaluation results of the proposed framework on two representative multi-turn environments: Guess My Number and Wordle. The evaluation focuses on three complementary metrics: a) average task completion reward, b) consistency of action selection, and c) compliance with constraints, which together capture agent verifiability and reliability. Across both environments, agents guided in our framework consistently outperform native baselines with and without in-context learning.
Figure 1 shows the high-level interaction of our framework with a given task’s environment interface and the LLM agent assigned for the task. Our framework provides a generic task environment interface to describe the execution environment (i.e. observation and action state variables, reward mechanism, and goal description) of a given task. Once the environment is described, all components of the framework and the LLM agent conform to this interface.
In the following, we first describe the rest
This content is AI-processed based on open access ArXiv data.