Title: High-Dimensional Data Processing: Benchmarking Machine Learning and Deep Learning Architectures in Local and Distributed Environments
ArXiv ID: 2512.10312
Date: 2025-12-11
Authors: Julian Rodriguez, Piotr Lopez, Emiliano Lerma, Rafael Medrano, Jacobo Hernandez
📝 Abstract
This document reports the sequence of practices and methodologies implemented during the Big Data course. It details the workflow beginning with the processing of the Epsilon dataset through group and individual strategies, followed by text analysis and classification with RestMex and movie feature analysis with IMDb. Finally, it describes the technical implementation of a distributed computing cluster with Apache Spark on Linux using Scala.
💡 Deep Analysis
📄 Full Content
High-Dimensional Data Processing: Benchmarking
Machine Learning and Deep Learning Architectures
in Local and Distributed Environments
Jos´e Juli´an Rodr´ıguez Guti´errez, Piotr Enriquevitch Lopez Chernyshov, Emiliano Lerma Garc´ıa,
Rafael Medrano Vazquez, and Jacobo Hern´andez Varela
Licenciatura en Ingenier´ıa de Datos e Inteligencia Artificial
Divisi´on de Ingenier´ıas Campus Irapuato-Salamanca
Guanajuato, M´exico
{jj.rodriguez.gutierrez, pe.lopezchernyshov, e.lermagarcia, r.medranovazquez, j.hernandezvarela}@ugto.mx
Abstract—This document reports the sequence of practices and
methodologies implemented during the Big Data course. It details
the workflow beginning with the processing of the Epsilon dataset
through group and individual strategies, followed by text analysis
and classification with RestMex and movie feature analysis with
IMDb. Finally, it describes the technical implementation of a
distributed computing cluster with Apache Spark on Linux using
Scala.
Index Terms—Big Data, Spark, Epsilon, RestMex, IMDb,
Scala, Clustering, Classification, Regression
I. INTRODUCTION
The present study develops as an integral big data project
encompassing three complementary analyses across different
domains. The first case study, centered on the Epsilon dataset,
served as an introduction to massive data handling through
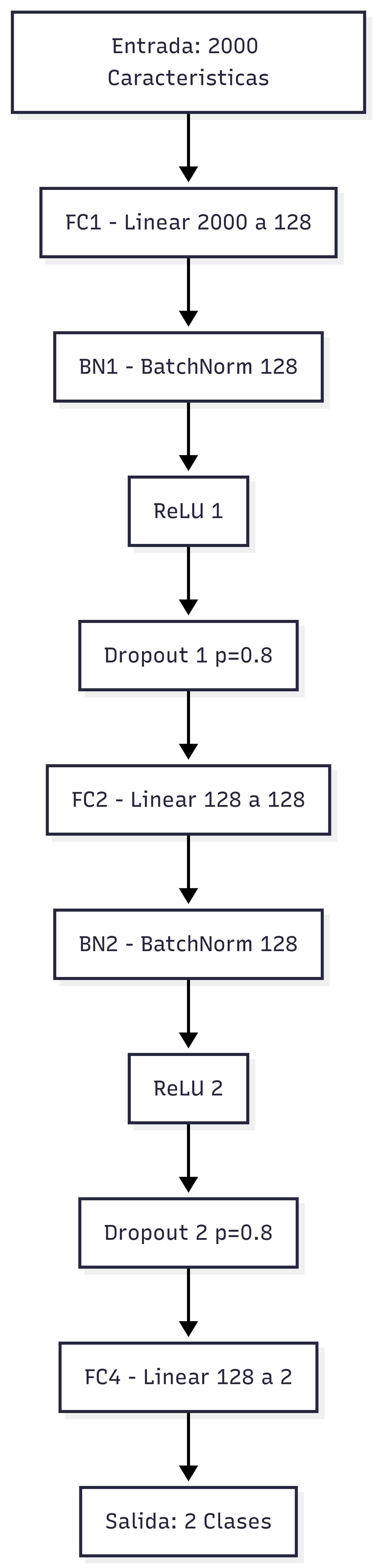
the implementation of a Multi-Layer Perceptron (MLP) with
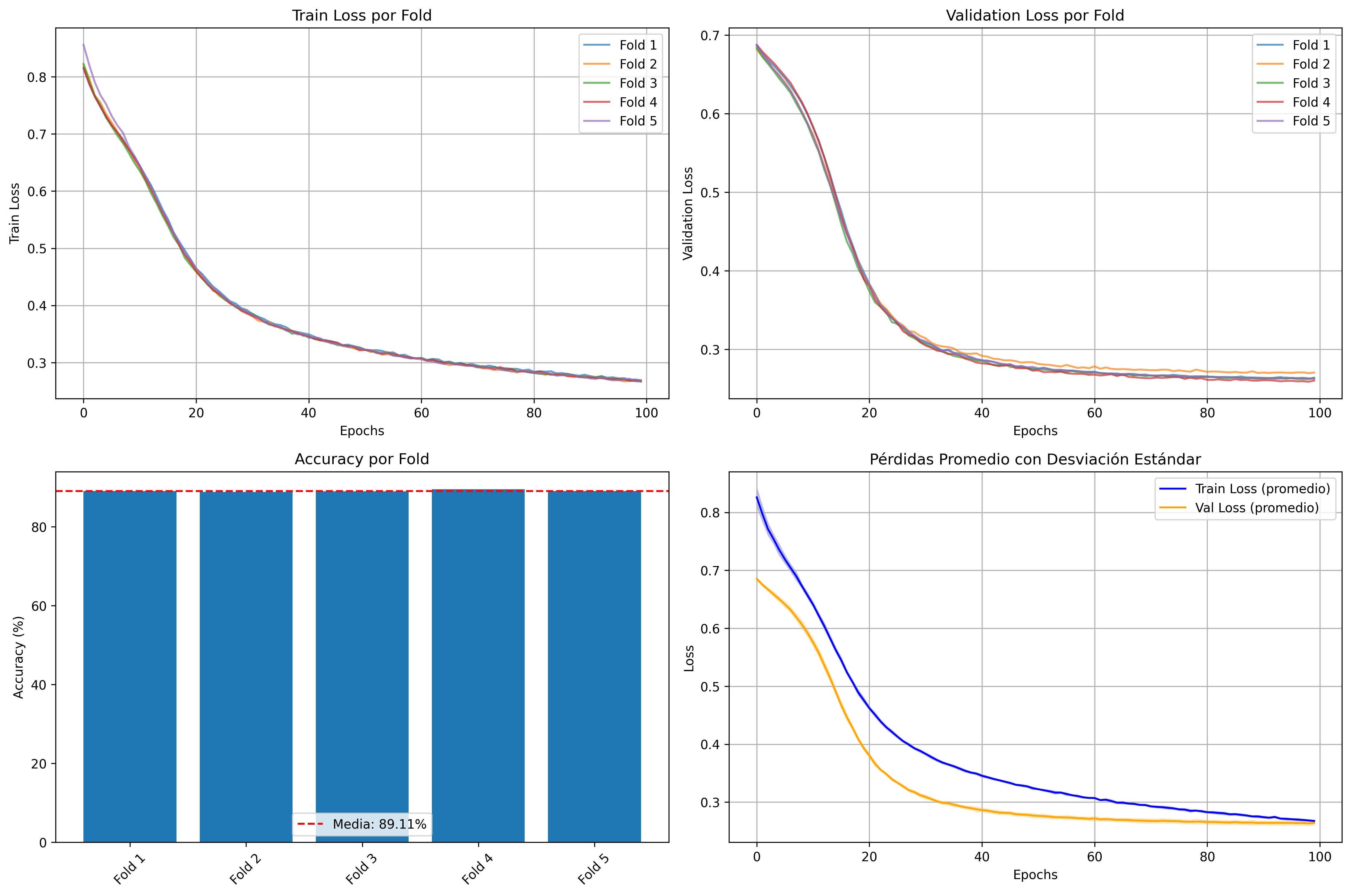
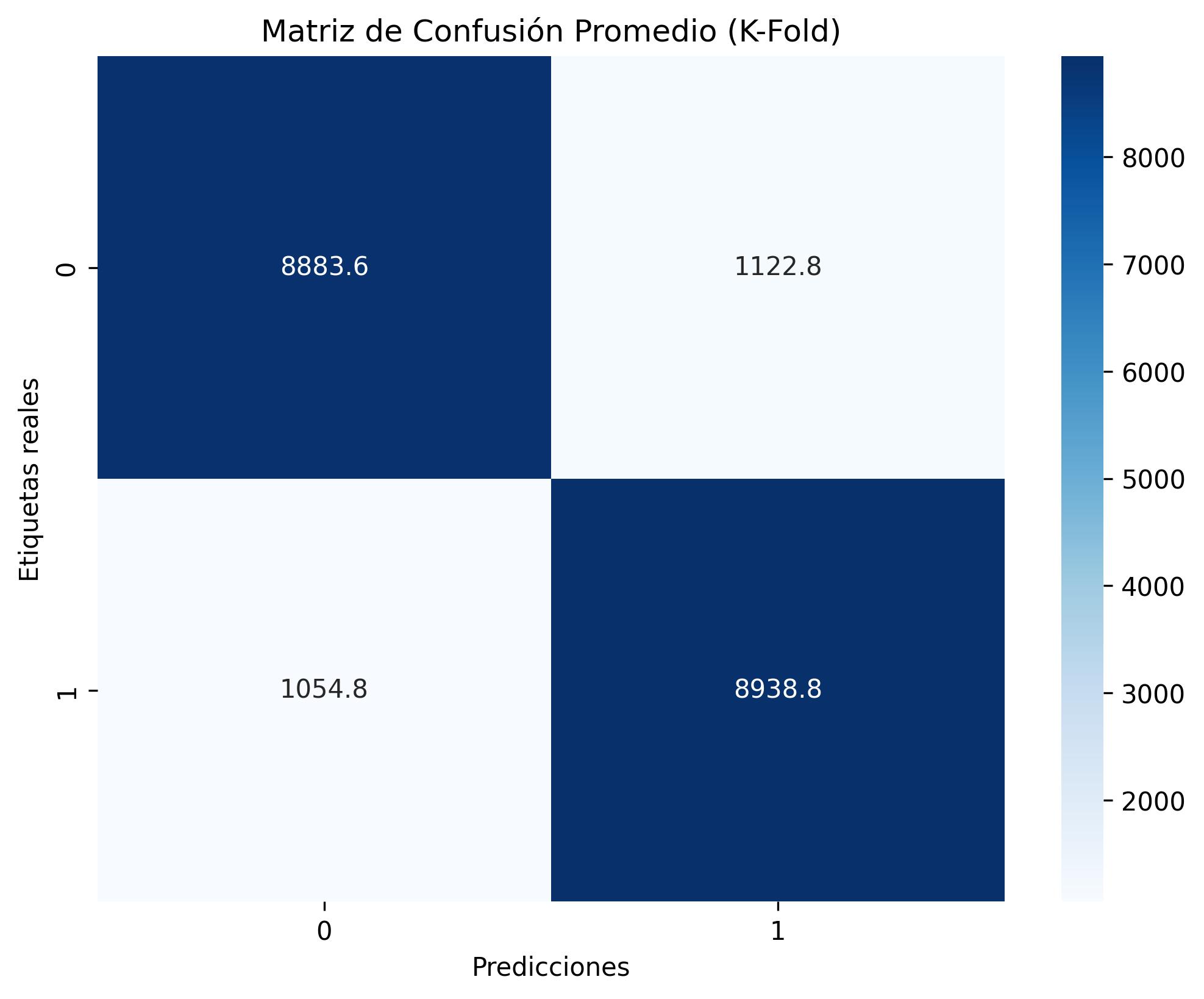
architecture 2000-128-128-2, trained on 100,000 instances
with 2,000 features. Using PyTorch with GPU acceleration
(CUDA), the model achieved 88.98% accuracy after 100
training epochs, with a batch size of 128 and Adam opti-
mization (learning rate=10−5, weight decay=10−4). The im-
plementation included regularization techniques through Batch
Normalization and Dropout (p = 0.8), reducing validation
loss from 0.6847 to 0.2670. This exercise established the
methodological foundations for efficient processing of high-
dimensionality datasets.
The second analysis, focused on the Rest-Mex dataset,
implemented a complete pipeline for polarity classification in
Mexican tourist reviews. Text preprocessing techniques were
applied including tokenization, stopword removal, and lemma-
tization, followed by vectorization using CountVectorizer or
TF-IDF. The supervised classification model categorized re-
views into three classes (Positive/Negative/Neutral), address-
ing the inherent imbalance of the tourist dataset through class
weighting techniques.
Finally, the IMDb dataset analysis represents the project’s
culmination, integrating deep textual analysis through TF-
IDF (5,000 features with HashingTF and minDocFreq=3)
over descriptions, titles, and metadata of 85,855 films. An
intelligent contextual imputation system was implemented
based on director, genre, actor, and writer averages, signifi-
cantly reducing missing values in critical variables. Optimized
XGBoost Regressor through Grid Search (36 hyperparameter
combinations) with 3-fold cross-validation achieved an RMSE
of 0.6001 and R2 of 0.79 in continuous rating prediction. The
optimal hyperparameters found were: maxDepth=12, eta=0.03,
numRound=500, minChildWeight=3.
Sentiment analysis of descriptions revealed a distribution
of 46.83% neutral, 32.65% positive, and 20.52% negative,
information that was incorporated as an additional feature. Ex-
ploratory analysis identified Christopher Nolan (8.22), Satyajit
Ray (8.02), and Hayao Miyazaki (8.01) as the directors with
the highest average ratings, while Film-Noir (6.64), Biography
(6.62), and History (6.54) emerged as the best-rated genres.
This methodological progression—from binary classifica-
tion in Epsilon, through sentiment analysis in Rest-Mex,
to continuous rating prediction in IMDb—demonstrates the
versatility of machine learning techniques applied to different
scales and data types, establishing a robust framework for big
data analysis across multiple domains.
II. STATE OF THE ART
A. Stochastic Gradient Descent for Large-Scale SVM(Epsilon)
In the field of large-scale binary classification, Shalev-
Shwartz et al. (2011) developed Pegasos, a stochastic sub-
gradient descent algorithm for SVM that proved especially
efficient for massive datasets. The algorithm achieves a com-
plexity of ˜O(1/λϵ) iterations to reach ϵ accuracy, where each
iteration operates on a single training example. This efficiency
makes it particularly suitable for large-scale text classification
problems.
Pegasos’ approach works directly on the primal objective,
avoiding the need to maintain the complete kernel matrix
in memory, which represents a significant advantage when
working with high-dimensionality datasets like Epsilon. Re-
ported experiments show speedups of up to an order of
magnitude over conventional SVM methods on datasets with
sparse features, achieving accuracies above 85% in binary
arXiv:2512.10312v1 [cs.DC] 11 Dec 2025
classification problems with millions of examples. The work
establishes that the algorithm’s convergence does not directly
depend on th