Design Space Exploration of DMA based Finer-Grain Compute Communication Overlap
Reading time: 5 minute
...
📝 Original Info
Title: Design Space Exploration of DMA based Finer-Grain Compute Communication Overlap
ArXiv ID: 2512.10236
Date: 2025-12-11
Authors: ** Shagnik Pal¹², Shaizeen Aga¹, Suchita Pati¹, Mahzabeen Islam¹, Lizy K. John² ¹ Advanced Micro Devices Inc. ² University of Texas at Austin (연락처: shagnik@utexas.edu 등) — **
📝 Abstract
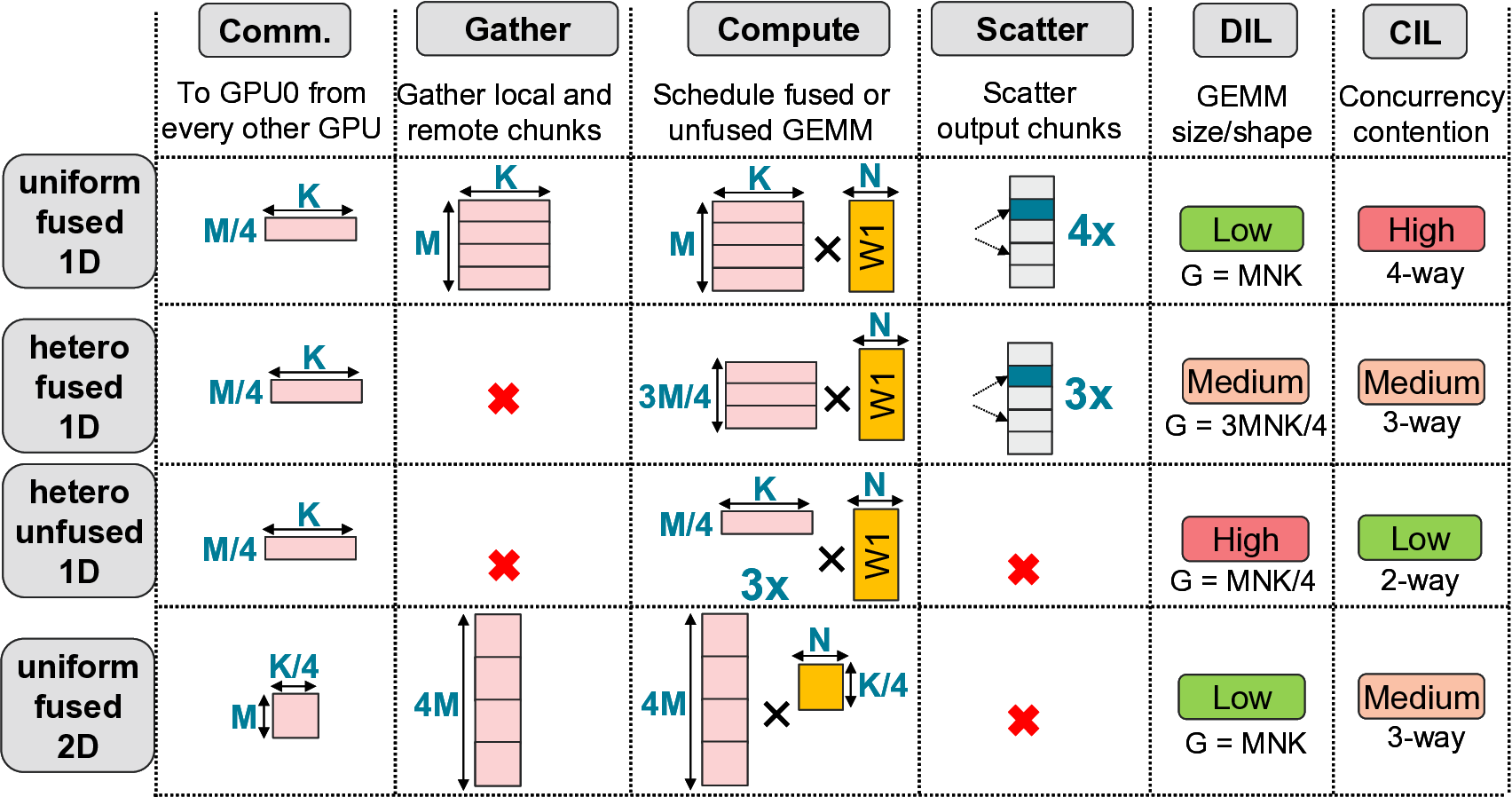
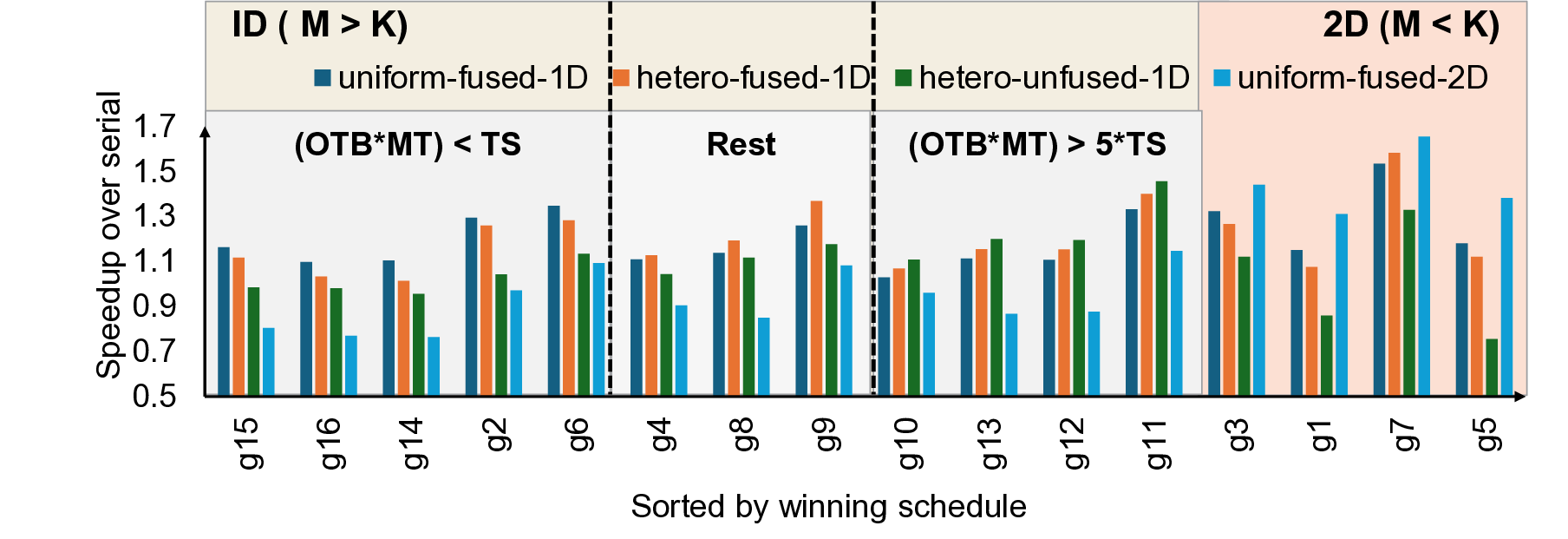
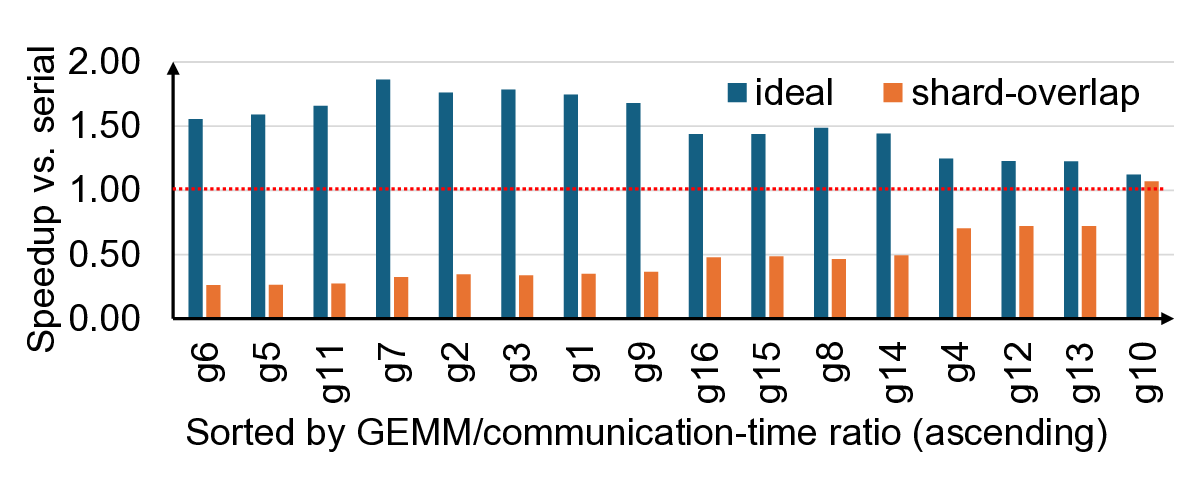
As both ML training and inference are increasingly distributed, parallelization techniques that shard (divide) ML model across GPUs of a distributed system, are often deployed. With such techniques, there is a high prevalence of data-dependent communication and computation operations where communication is exposed, leaving as high as 1.7x ideal performance on the table. Prior works harness the fact that ML model state and inputs are already sharded, and employ careful overlap of individual computation/communication shards. While such coarse-grain overlap is promising, in this work, we instead make a case for finer-grain compute-communication overlap which we term FiCCO, where we argue for finer-granularity, one-level deeper overlap than at shard-level, to unlock compute/communication overlap for a wider set of network topologies, finer-grain dataflow and more. We show that FiCCO opens up a wider design space of execution schedules than possible at shard-level alone. At the same time, decomposition of ML operations into smaller operations (done in both shard-based and finer-grain techniques) causes operation-level inefficiency losses. To balance the two, we first present a detailed characterization of these inefficiency losses, then present a design space of FiCCO schedules, and finally overlay the schedules with concomitant inefficiency signatures. Doing so helps us design heuristics that frameworks and runtimes can harness to select bespoke FiCCO schedules based on the nature of underlying ML operations. Finally, to further minimize contention inefficiencies inherent with operation overlap, we offload communication to GPU DMA engines. We evaluate several scenarios from realistic ML deployments and demonstrate that our proposed bespoke schedules deliver up to 1.6x speedup and our heuristics provide accurate guidance in 81% of unseen scenarios.
💡 Deep Analysis
📄 Full Content
Design Space Exploration of DMA based
Finer-Grain Compute Communication Overlap
Shagnik Pal1,2, Shaizeen Aga1, Suchita Pati1, Mahzabeen Islam1, Lizy K. John2
1Advanced Micro Devices Inc. , 2The University of Texas at Austin
shagnik@utexas.edu, {shaizeen.aga, suchita.pati, mahzabeen.islam}@amd.com, ljohn@ece.utexas.edu
Abstract—As both ML training and inference are increasingly
distributed, parallelization techniques that shard (divide) ML
model state and inputs, generally into the number of GPUs of
a distributed system, are often deployed. With such techniques,
there is a high prevalence of on-critical-path data-dependent com-
munication and computation operations where communication is
exposed, leaving as high as 1.7× ideal performance on the table.
To recover this lost performance, prior works harness the fact
that ML model state and inputs are already sharded and employ
careful overlap of individual computation/communication shards
when possible. While such coarse-grain overlap is promising,
in this work, we instead make a case for finer-grain compute-
communication overlap which we term FiCCO, where we argue
for finer-granularity, one-level deeper overlap than at shard-level,
to unlock compute/communication overlap for a wider set of
network topologies, finer-grain dataflow and more.
We show that FiCCO opens up a wider design space of exe-
cution schedules than possible at shard-level alone. At the same
time, decomposition of ML operations into smaller operations
(done in both shard-based and finer-grain techniques) causes
operation-level inefficiency losses. To balance the two, we first
present a detailed characterization of these inefficiency losses,
then present a design space of FiCCO schedules, and finally
overlay the schedules with concomitant inefficiency signatures.
Doing so helps us design heuristics that frameworks and runtimes
can harness to select bespoke FiCCO schedules based on the
nature of underlying ML operations. Finally, to further minimize
contention inefficiencies inherent with operation overlap, we
offload communication to GPU DMA engines. We evaluate
several scenarios from realistic ML deployments and demonstrate
that our proposed bespoke schedules deliver up to 1.6× speedup
and our heuristics provide accurate guidance in 81% of unseen
scenarios.
Index Terms—Finer-grain overlap, GPUs, ML, DMAs
I. INTRODUCTION
The steep and continual increase of compute and memory
needs of ML [41] has led to increased reliance on distributed
computing over multiple GPUs. For instance, training Llama3
models involved close to 16K GPUs [15]. Such distributed
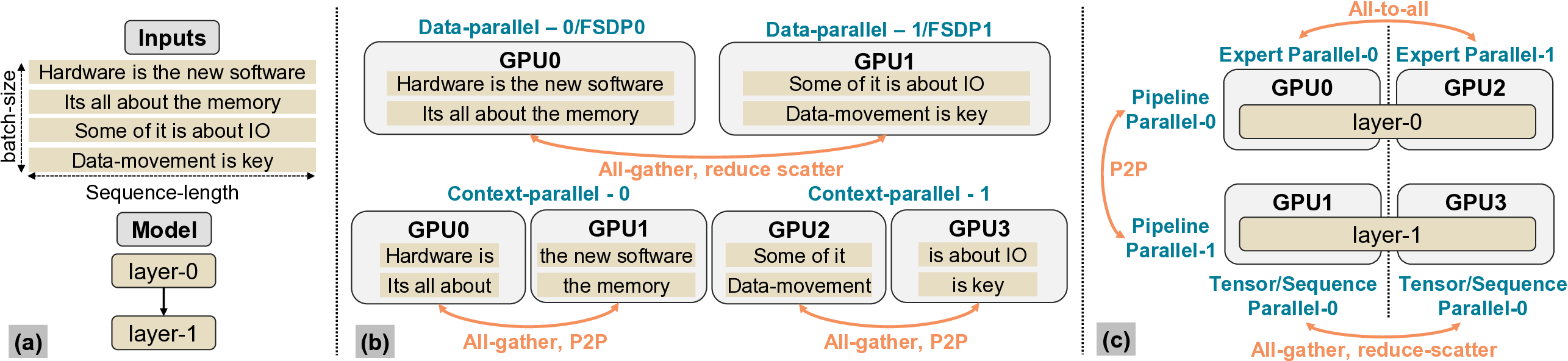
setups deploy various ML model parallelization strategies [26],
[33], [35], [60] which shard ML model state and inputs over
participating GPUs necessitating communication collectives
such as all-gather amongst GPUs to communicate model state
(e.g., activations) at periodic intervals.
While communication can be hidden in the shadow of
independent computation where possible, said communication
can be exposed otherwise. An example of the former is fully-
sharded data parallel [60] technique where weights are parti-
tioned across GPUs and the communication of weights of the
GEMM (G)
Collective (C)
FiCCO
speedup
Serial
Execution
FiCCO
Execution
C0
C1
C2
GPU
DMA
GPU
G1
G2
G3
1
2
Inefficiencies
FiCCO
search
space
3
FiCCO
heuristics
G0
a b
c
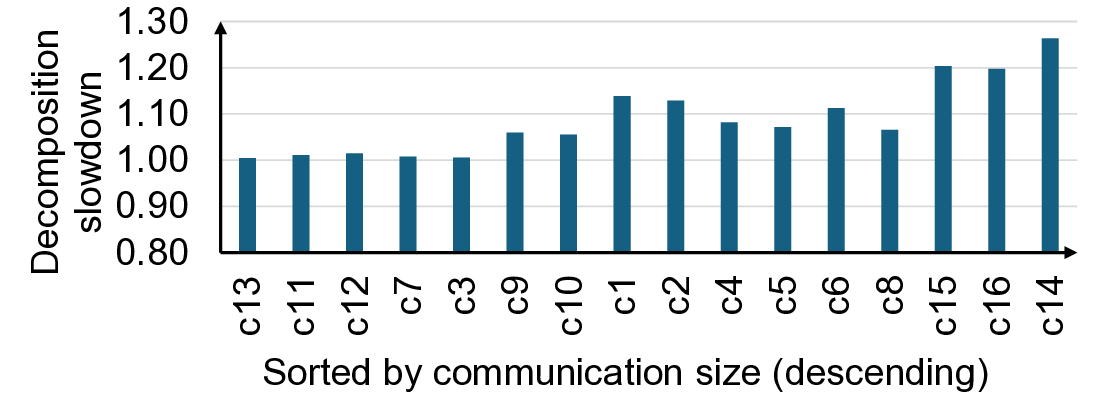
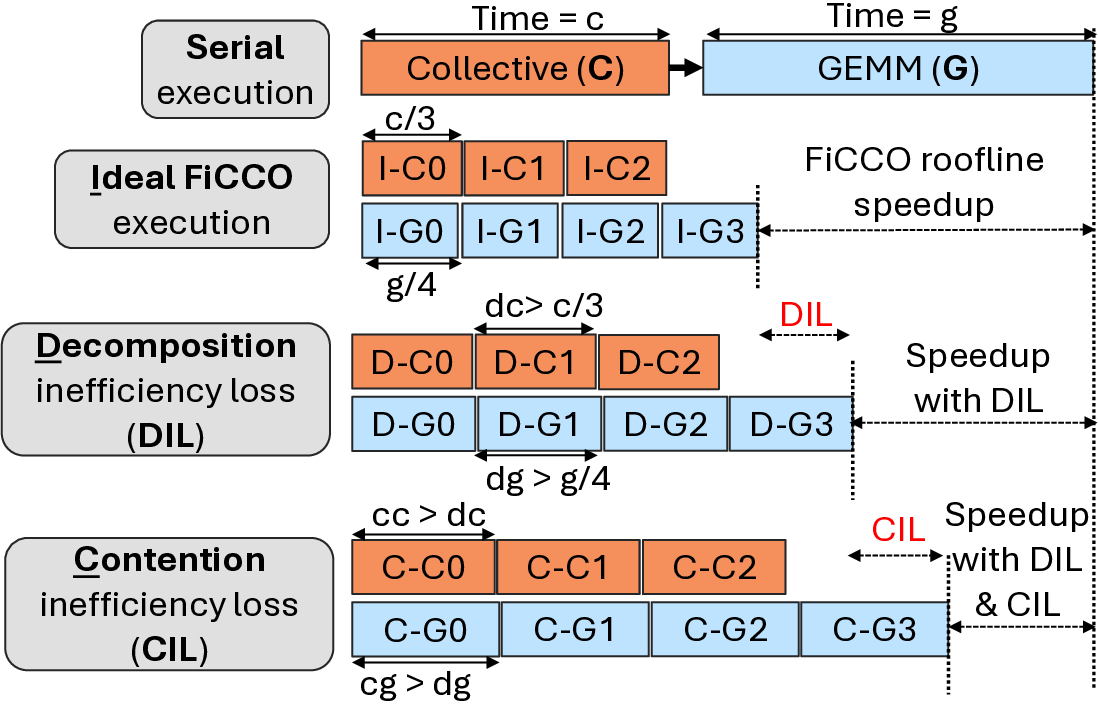
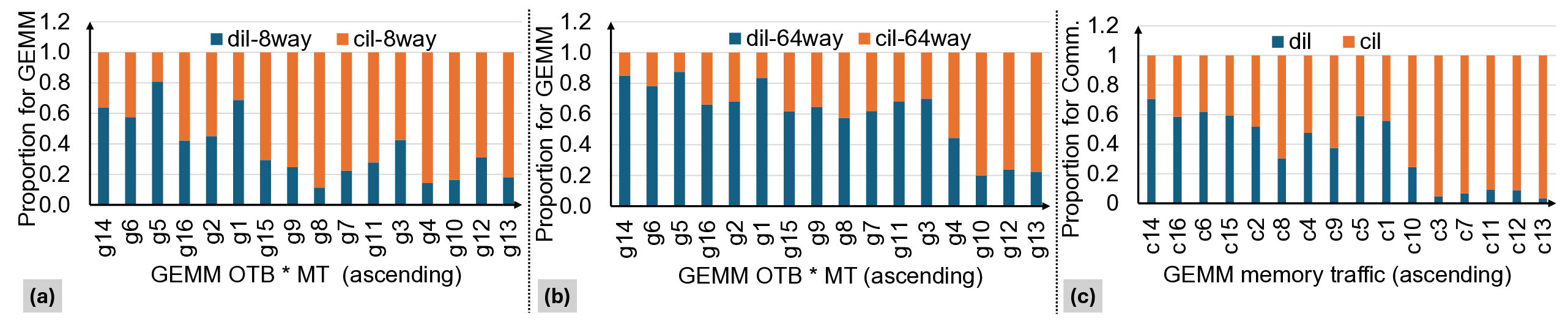
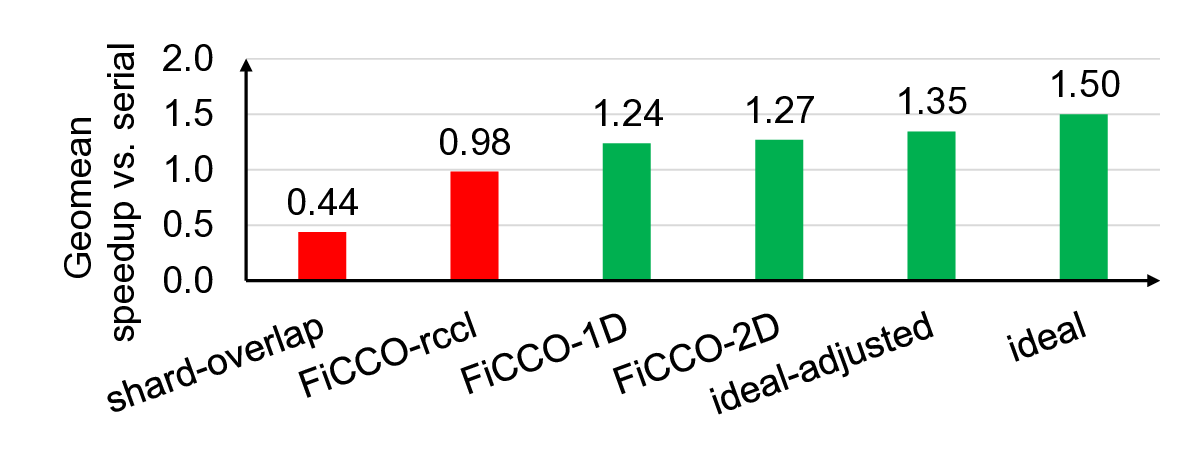
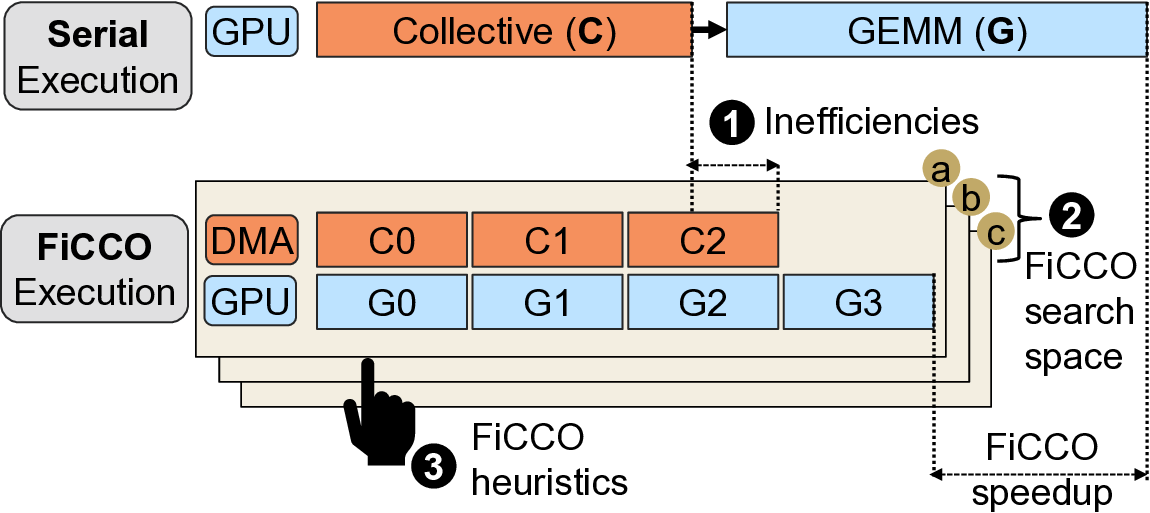
Fig. 1: Speedup with finer-grain decomposition of data-
dependent communication and computation (FiCCO).
next layer can be overlapped with the computation of the cur-
rent layer. Several examples of the latter are highly prevalent in
ML and include tensor-sequence parallelism [31] and context-
parallelism [35], wherein communication on critical-path feeds
into a data-dependent computation. In such cases, exposed
communication leaves as high as 1.7× ideal performance on
the table, and addressing this is the focus of this work.
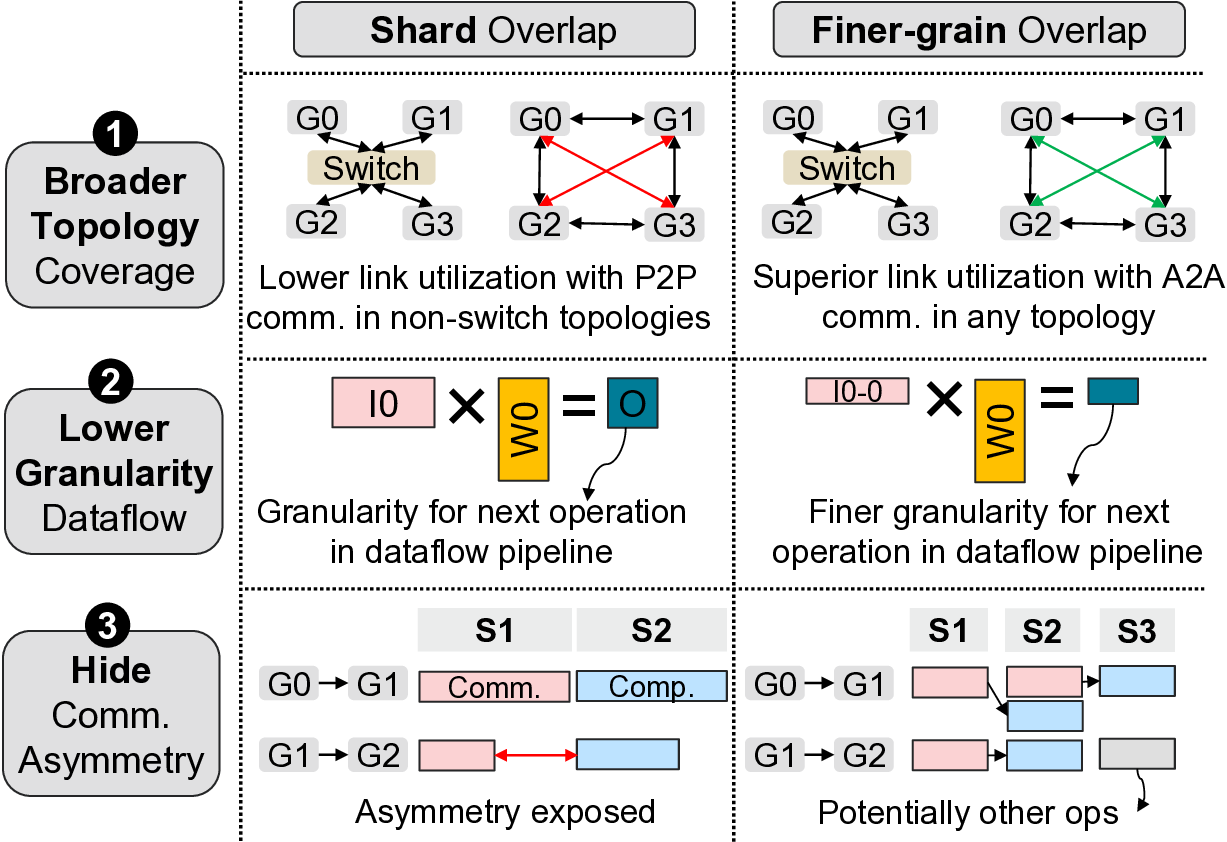
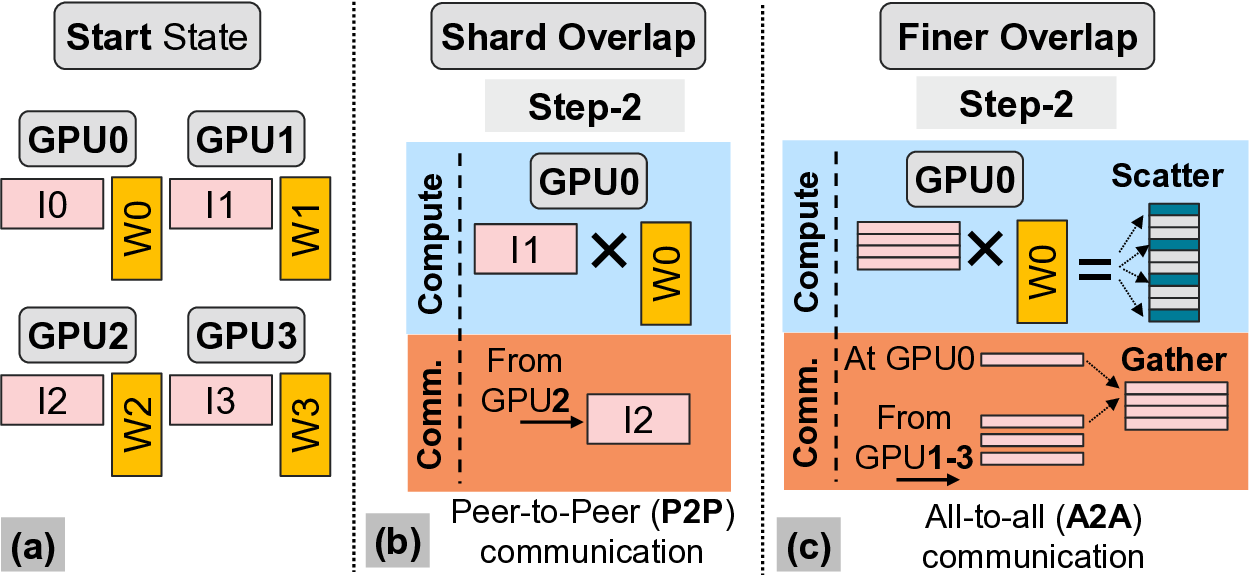
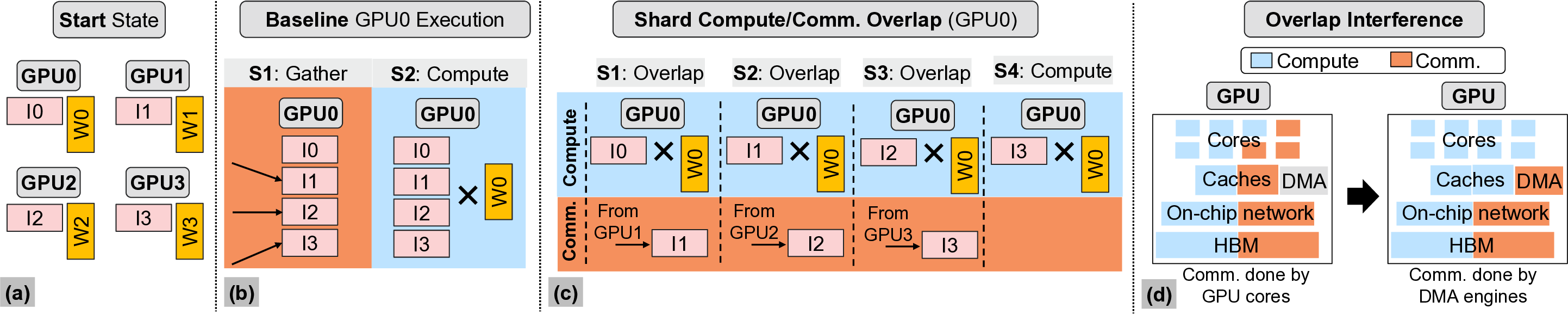
To address above challenge, as ML parallelization tech-
niques already shard ML models and inputs (e.g., tensor
parallelism shards model weights of single layer equally
across GPUs), prior works [2], [24] overlap computation and
communication at shard granularity (shard-level) to deliver
speedups. However, such coarse-grain shard-based techniques
manifest a severe limitation in that they harness peer-to-peer
communication operations (i.e., a GPU communicating with
only one other GPU at a time) which while suitable for switch-
based GPU networks (flexible bandwidth allocation), leaves
network links idle with direct-connection based GPU networks
delivering considerably lower performance (up to 3.9× lower).
Further, as they inherently operate at shard-granularity they
limit granularity of subsequent operations.
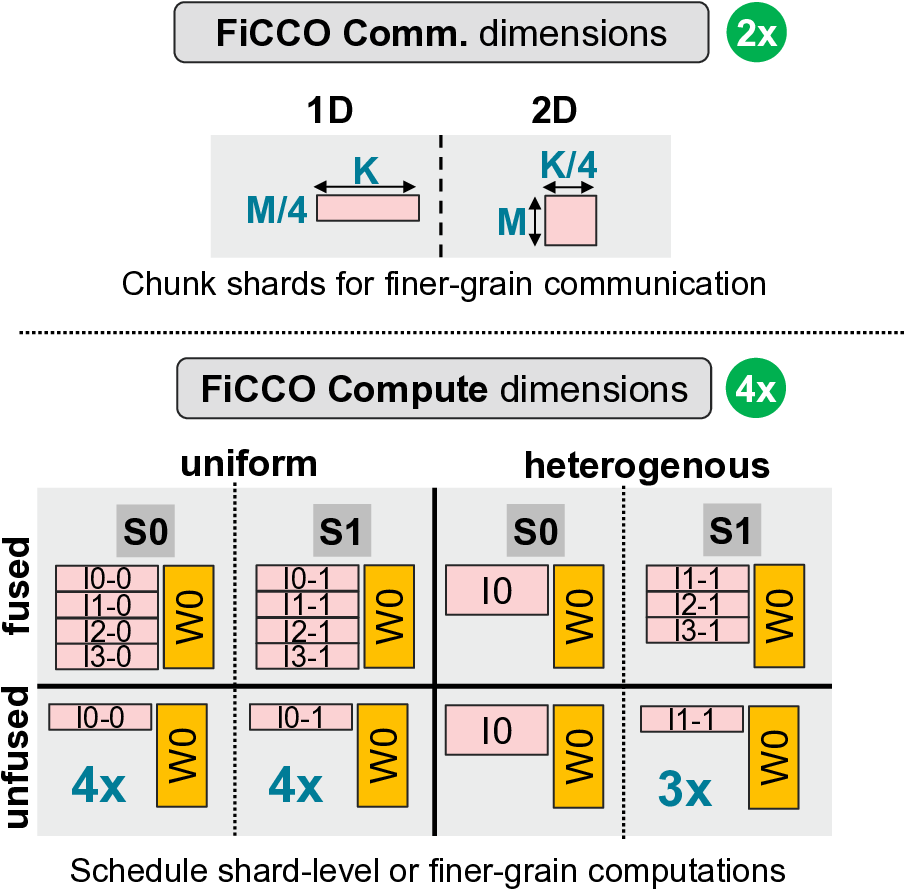
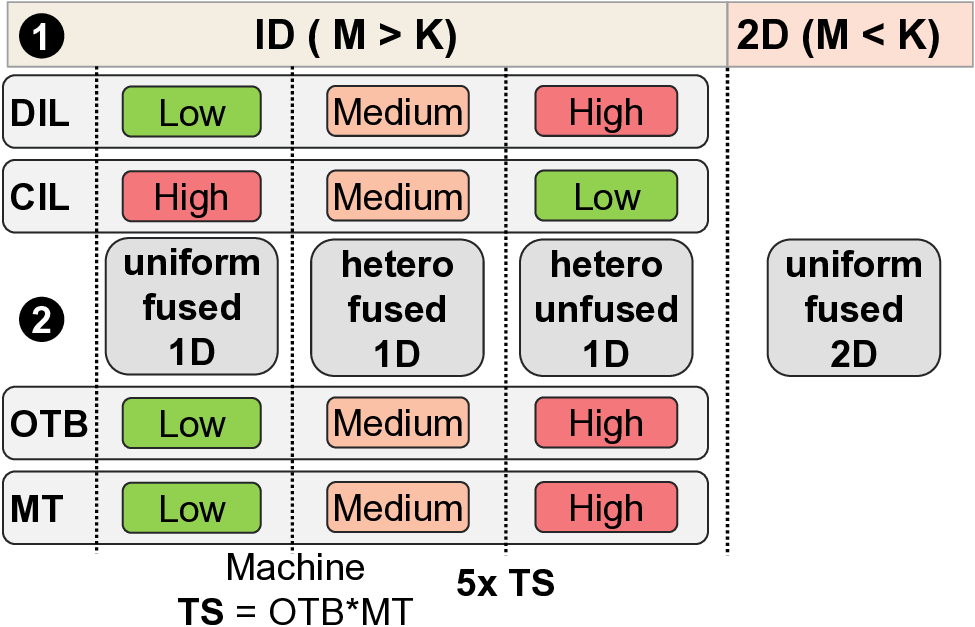
We
observe
in
this
work
that
finer-grain
compute-
communication overlap which we term FiCCO, wherein com-
munication is decomposed at one-level deeper granularity (i.e.,
transfer sizes one-eighth that of shard-based overlap in an eight
GPU system) allow overcoming of above discussed li