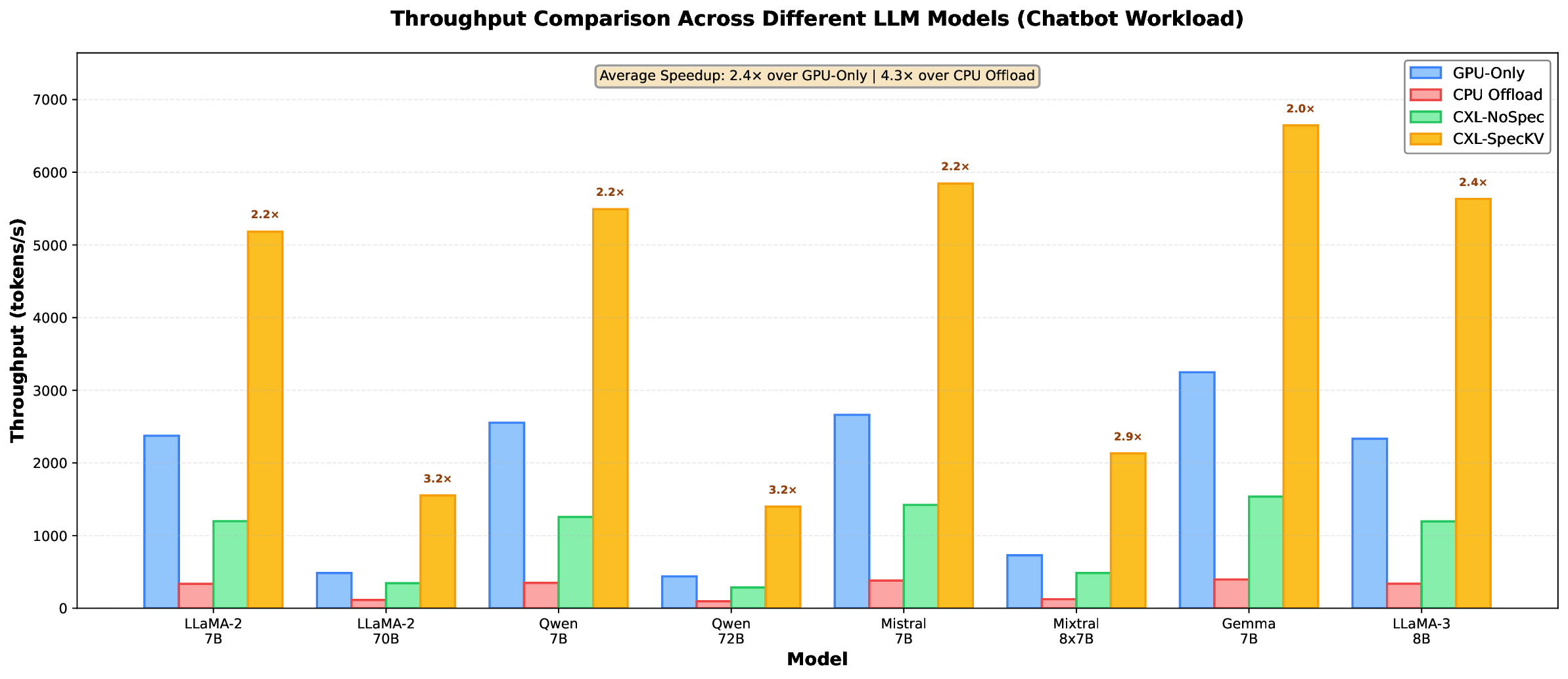
Large Language Models (LLMs) have revolutionized natural language processing tasks, but their deployment in datacenter environments faces significant challenges due to the massive memory requirements of key-value (KV) caches. During the autoregressive decoding process, KV caches consume substantial GPU memory, limiting batch sizes and overall system throughput. To address these challenges, we propose \textbf{CXL-SpecKV}, a novel disaggregated KV-cache architecture that leverages Compute Express Link (CXL) interconnects and FPGA accelerators to enable efficient speculative execution and memory disaggregation. Our approach introduces three key innovations: (i) a CXL-based memory disaggregation framework that offloads KV-caches to remote FPGA memory with low latency, (ii) a speculative KV-cache prefetching mechanism that predicts and preloads future tokens' cache entries, and (iii) an FPGA-accelerated KV-cache compression and decompression engine that reduces memory bandwidth requirements by up to 4$\times$. When evaluated on state-of-the-art LLM models, CXL-SpecKV achieves up to 3.2$\times$ higher throughput compared to GPU-only baselines, while reducing memory costs by 2.8$\times$ and maintaining accuracy. Our system demonstrates that intelligent memory disaggregation combined with speculative execution can effectively address the memory wall challenge in large-scale LLM serving. Our code implementation has been open-sourced at https://github.com/FastLM/CXL-SpecKV.
Large Language Models (LLMs) have emerged as the cornerstone of modern AI applications [7,33,46]. However, serving them efficiently faces significant challenges due to massive memory requirements of key-value (KV) caches. During inference, transformerbased LLMs store intermediate key and value tensors from all previous tokens. For a typical LLaMA-2 70B model serving 2048 tokens with batch size 32, the KV-cache alone consumes 640GB-far exceeding GPU capacity [19].
Traditional approaches include memory offloading [41], KVcache compression [16], and speculative decoding [20], but suffer from limited bandwidth, accuracy degradation, or persistent memory constraints.
Recent advances in Compute Express Link (CXL) [11] and FPGA architectures [12] present new opportunities. CXL provides highbandwidth, low-latency cache-coherent memory sharing, while FPGAs offer customizable acceleration.
We propose CXL-SpecKV, combining CXL memory disaggregation with FPGA-accelerated speculative execution. By predicting and preloading KV-cache entries through CXL, we overcome GPU memory limits while maintaining low latency.
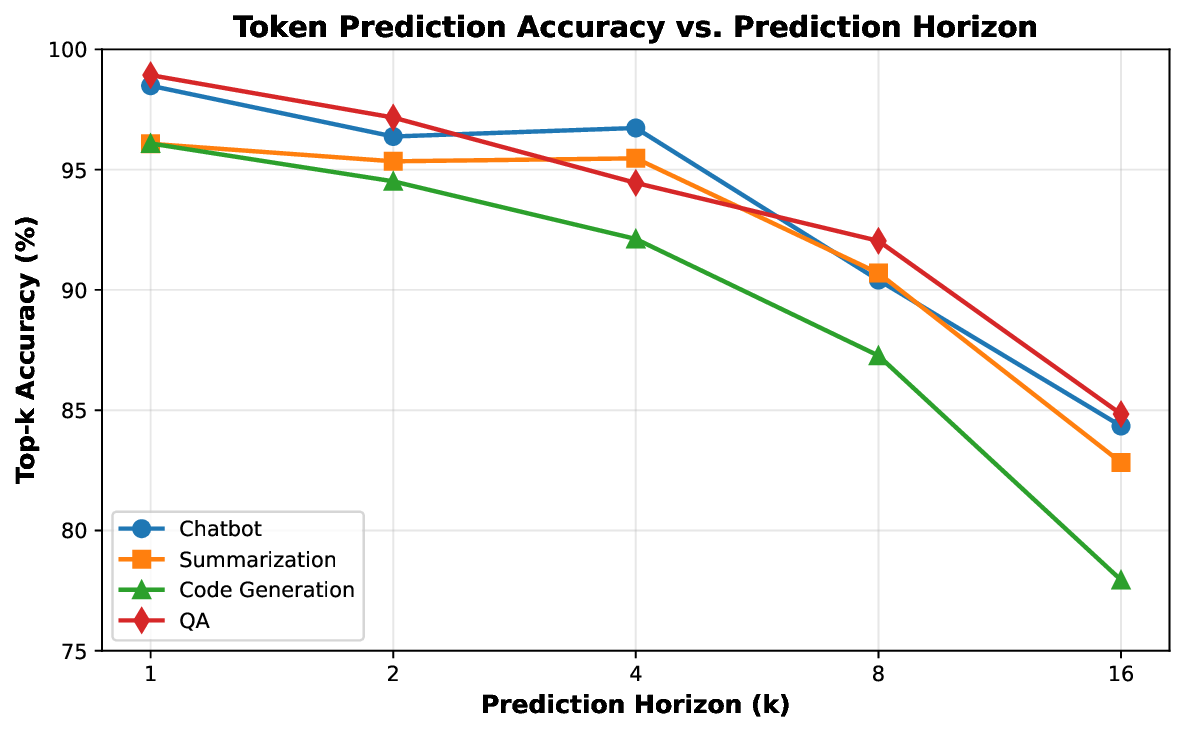
CXL-SpecKV features: (i) transparent KV-cache offloading to CXL memory (4-8× capacity expansion), (ii) speculative prefetching with 95% accuracy reducing access latency, (iii) FPGA-accelerated compression (3-4× ratio) and address translation, and (iv) seamless integration with existing frameworks.
The architecture consists of three components: the CXL Memory Manager for allocation and migration, the Speculative Prefetcher using lightweight models for prediction, and the FPGA Cache Engine implementing compression/decompression pipelines at >800MHz.
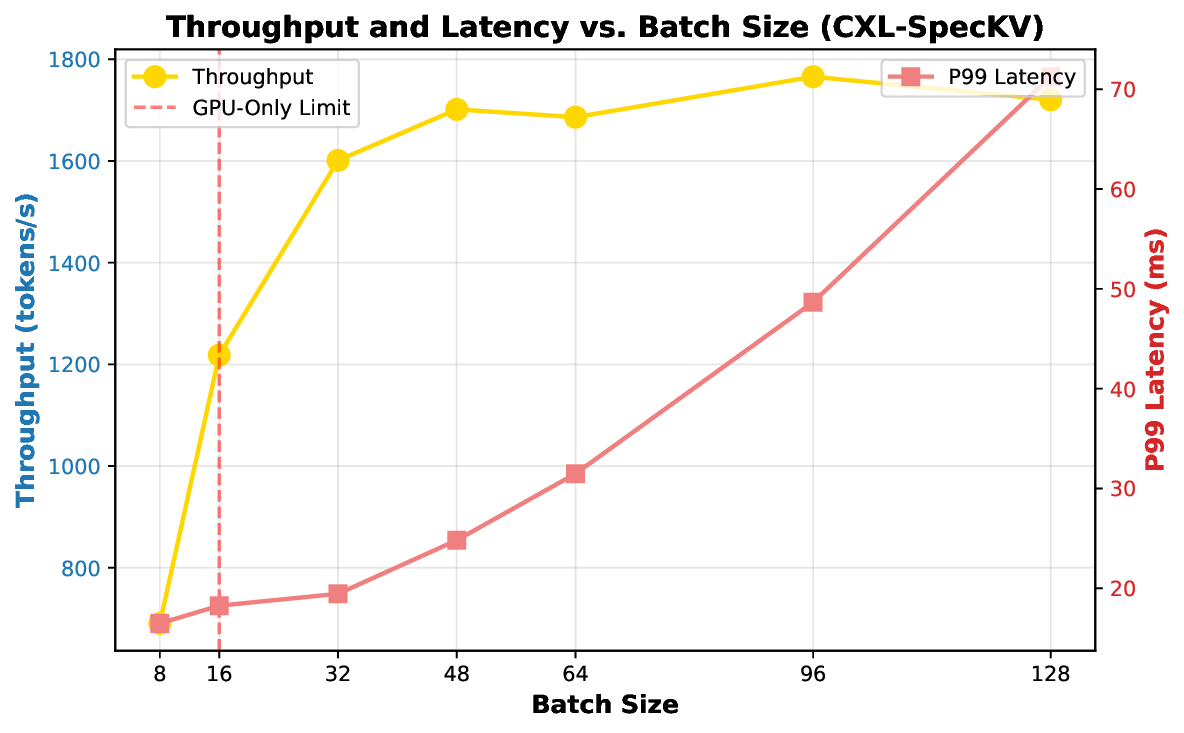
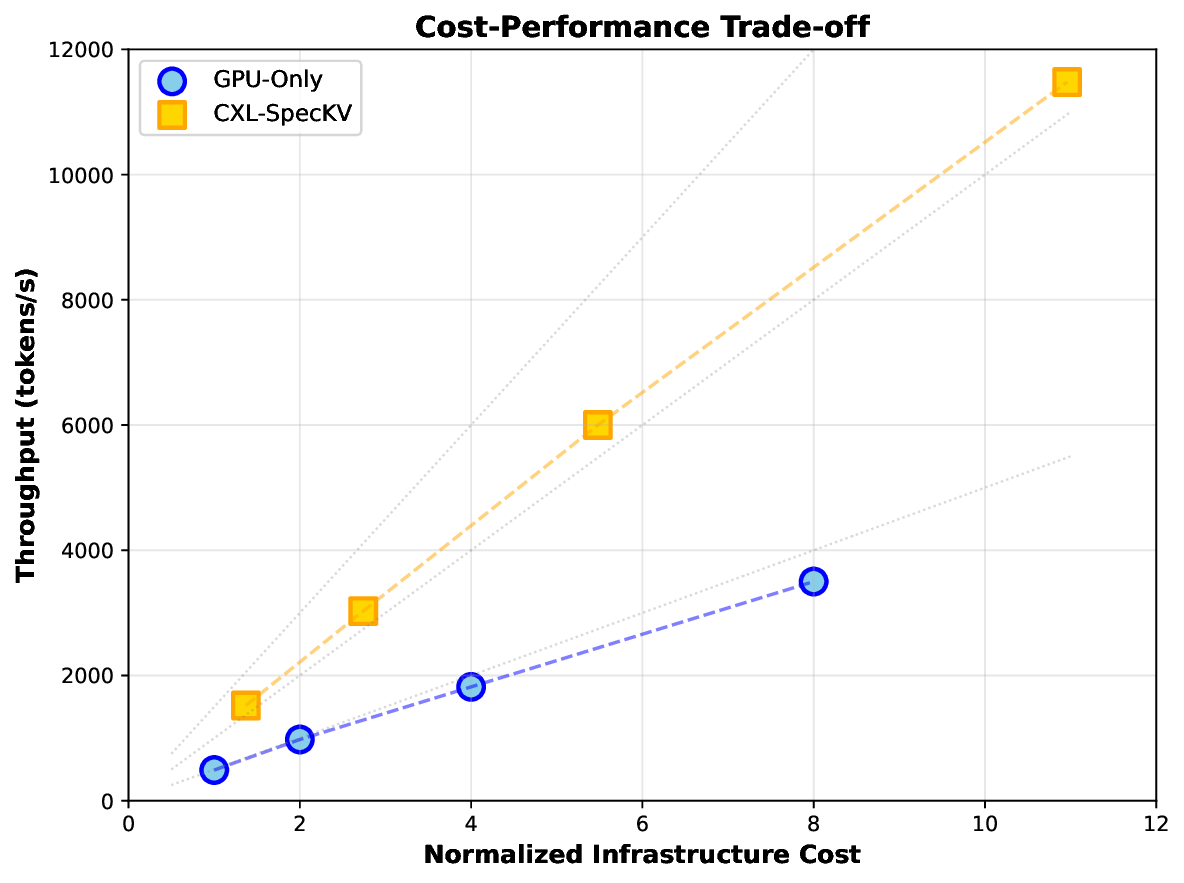
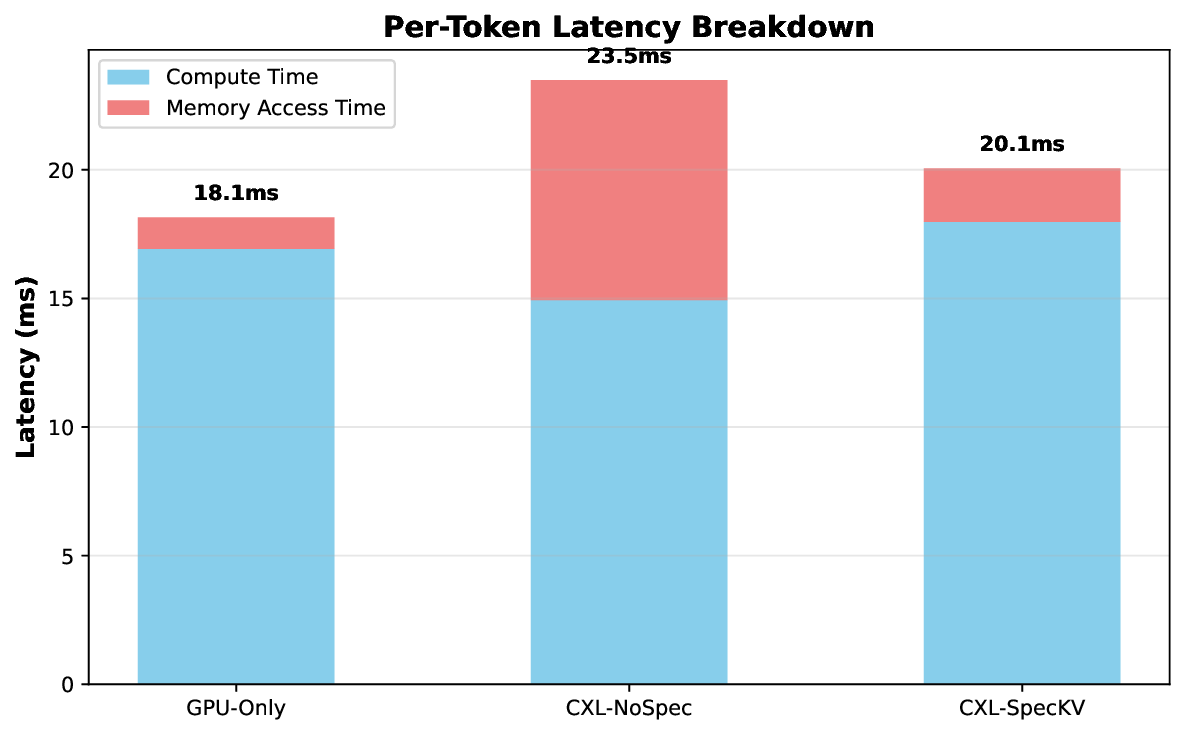
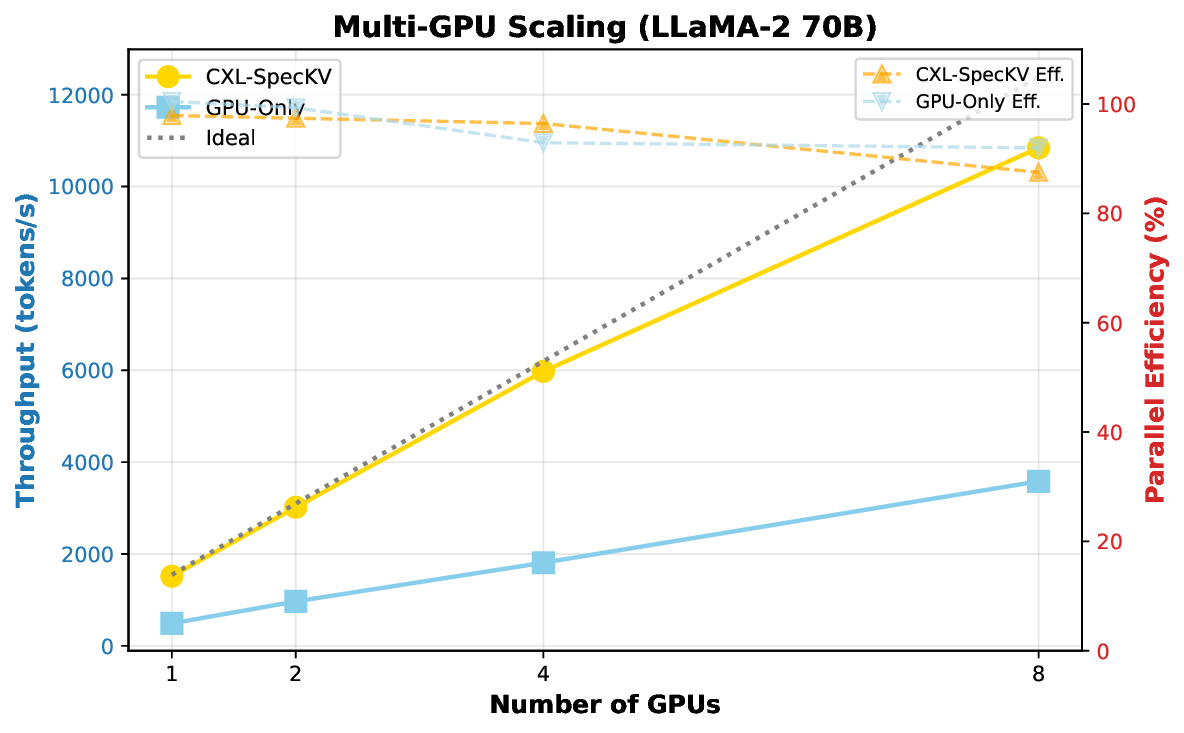
Our evaluations on LLM workloads (7B-70B parameters) show: 3.2× higher throughput enabling 4-8× larger batches, 8% per-token latency overhead, 2.8× memory cost reduction, 99.5% accuracy preservation, and 87% parallel efficiency at 8 GPUs. The approach potentially reduces infrastructure costs by 30-40% for memorybound workloads.
The contributions of this work are summarized as follows:
• We propose the first CXL-based disaggregated memory architecture specifically designed for LLM KV-cache management, demonstrating the viability and benefits of memory pooling for inference workloads. • We introduce novel speculative prefetching algorithms that exploit the predictable patterns in autoregressive token generation, achieving high prediction accuracy while maintaining low computational overhead. • We design and implement efficient FPGA accelerators for KVcache compression, decompression, and management, with detailed architectural descriptions and resource utilization analysis. • We develop a complete system prototype integrated with popular LLM serving frameworks (vLLM, TensorRT-LLM), demonstrating practical deployment feasibility and real-world performance benefits. • We conduct extensive evaluations across multiple LLM models and workload patterns, providing insights into the performance characteristics, bottlenecks, and optimization opportunities of disaggregated memory architectures for LLM serving.
The remainder of this paper is organized as follows. Section 2 reviews related work in LLM serving optimization, memory disaggregation, and FPGA acceleration. Section 3 presents the detailed architecture of CXL-SpecKV, including the memory management framework, speculative prefetching mechanisms, and FPGA cache engine design. Section 4 describes our experimental methodology and presents comprehensive performance evaluations. Finally, Section 5 concludes with a discussion of future research directions and broader implications for datacenter AI infrastructure.
Our work builds upon and extends research in several key areas: LLM serving optimization, memory disaggregation technologies, FPGA-based acceleration, and speculative execution techniques. We discuss the most relevant prior work and highlight how CXL-SpecKV differs from and improves upon existing approaches.
The challenge of efficiently serving large language models has received significant attention from both industry and academia. vLLM [19] introduces PagedAttention, which organizes KV-caches in paged memory blocks to reduce fragmentation and improve memory utilization. However, vLLM is fundamentally limited by GPU memory capacity and does not address the bandwidth bottlenecks of memory disaggregation. FlexGen [41] explores offloading strategies between GPU, CPU, and disk storage, but suffers from the high latency of PCIe transfers (typically 8-12GB/s) compared to GPU HBM bandwidth (>2TB/s). Our CXL-based approach achieves significantly lower latency and higher bandwidth than PCIe-based offloading.
DeepSpeed-Inference [4] and FasterTransformer [32] provide optimized inference kernels and tensor parallelism strategies, but do not fundamentally address memory capacity constraints. Orca [50] introduces iteration-level scheduling to maximize batch size and throughput, yet remains constrained by available GPU me
This content is AI-processed based on open access ArXiv data.