Title: PACIFIC: a framework for generating benchmarks to check Precise Automatically Checked Instruction Following In Code
ArXiv ID: 2512.10713
Date: 2025-12-11
Authors: Itay Dreyfuss, Antonio Abu Nassar, Samuel Ackerman, Axel Ben David, Eitan Farchi, Rami Katan, Orna Raz, Marcel Zalmanovici
📝 Abstract
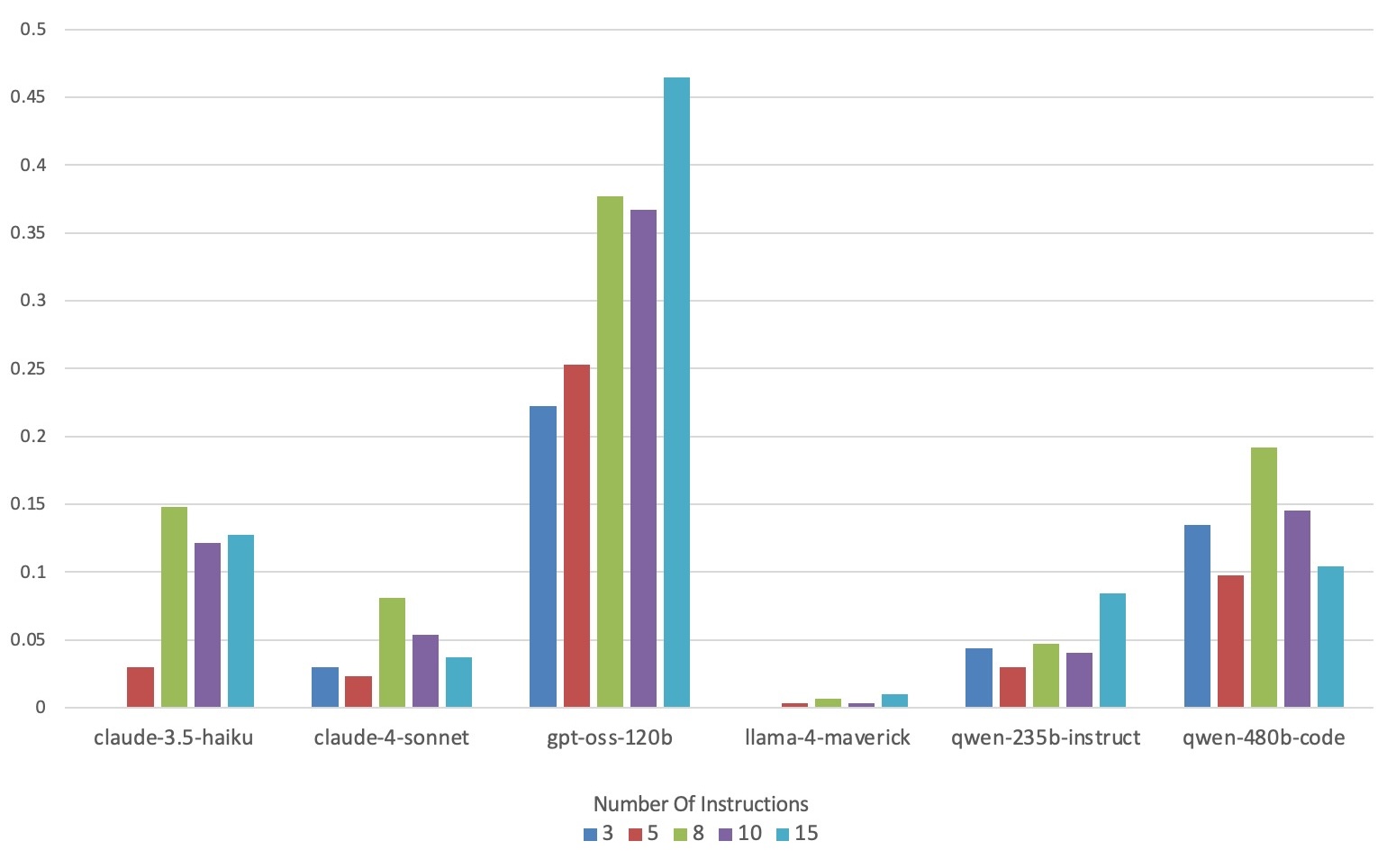
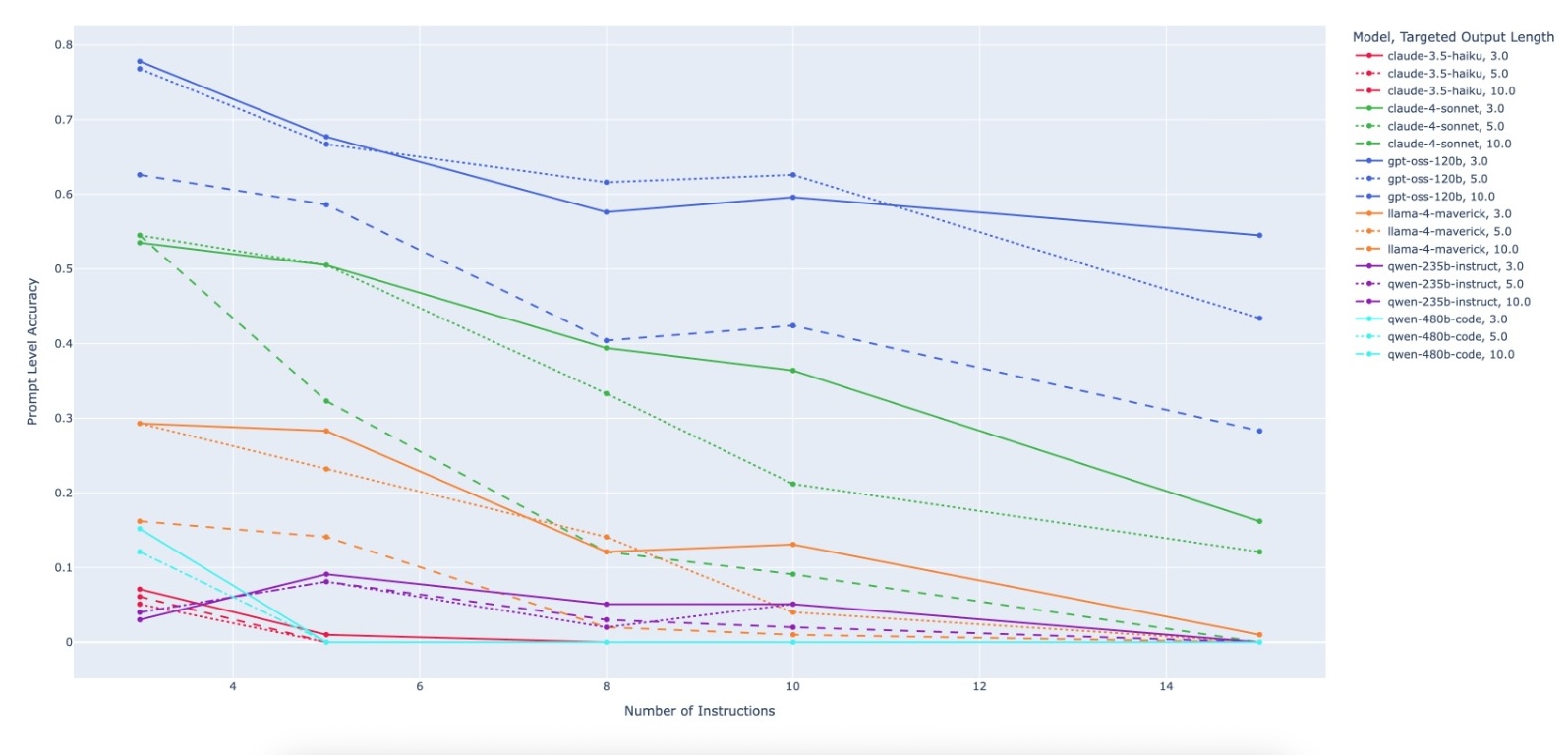
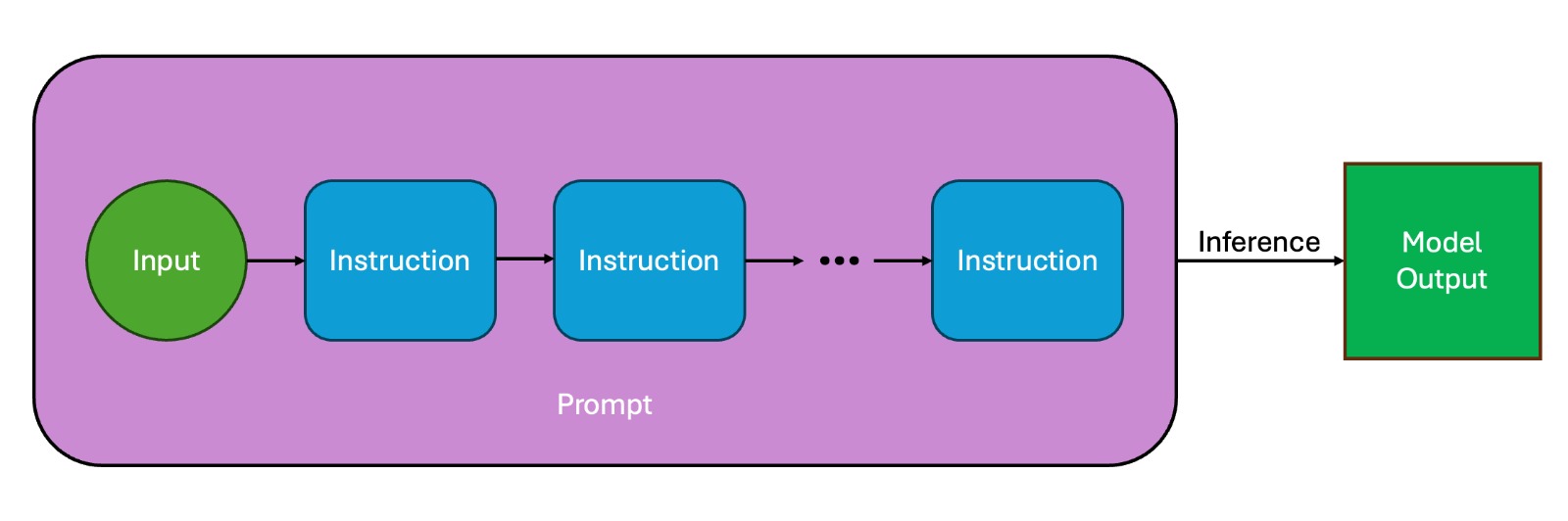
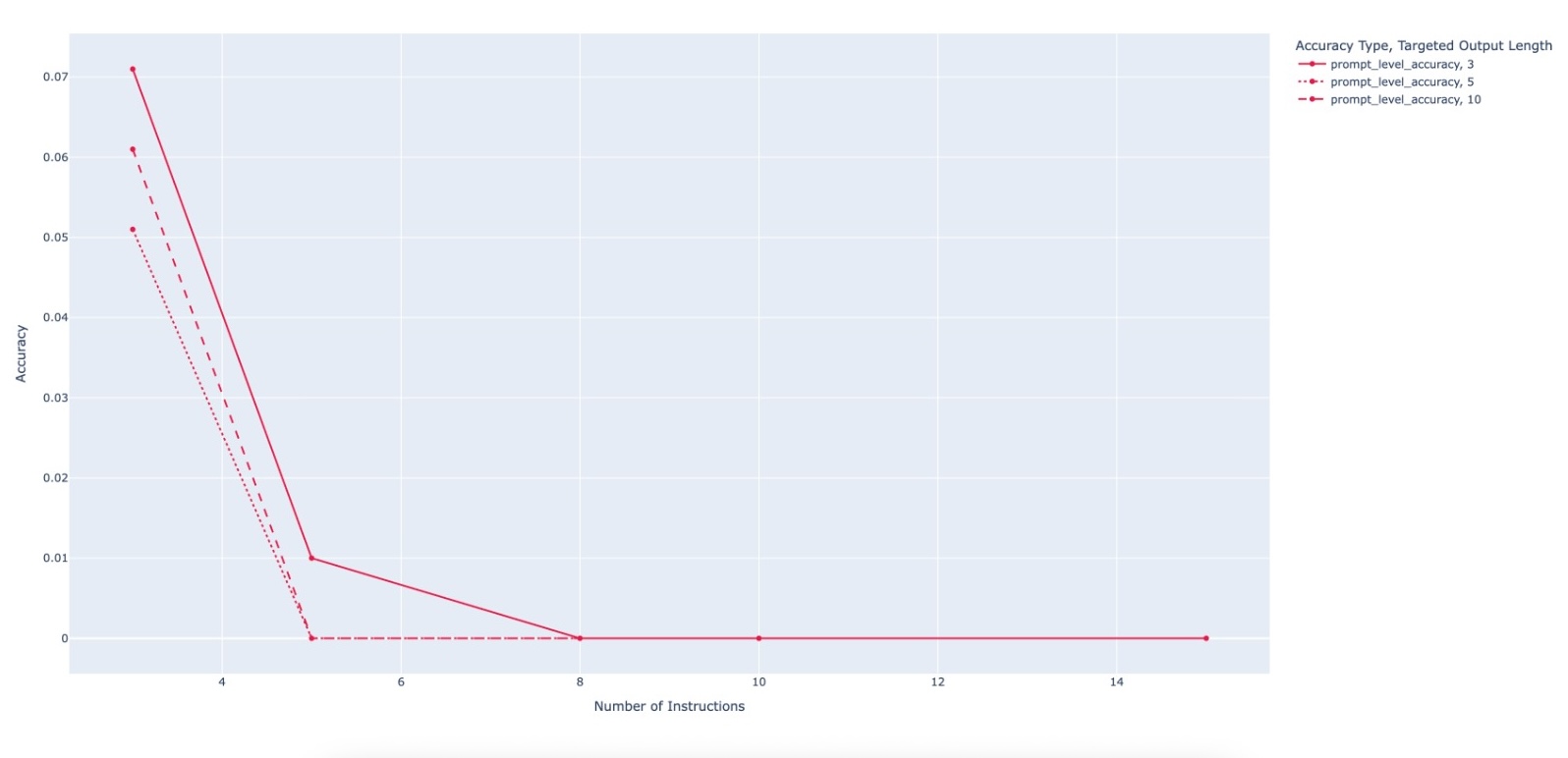
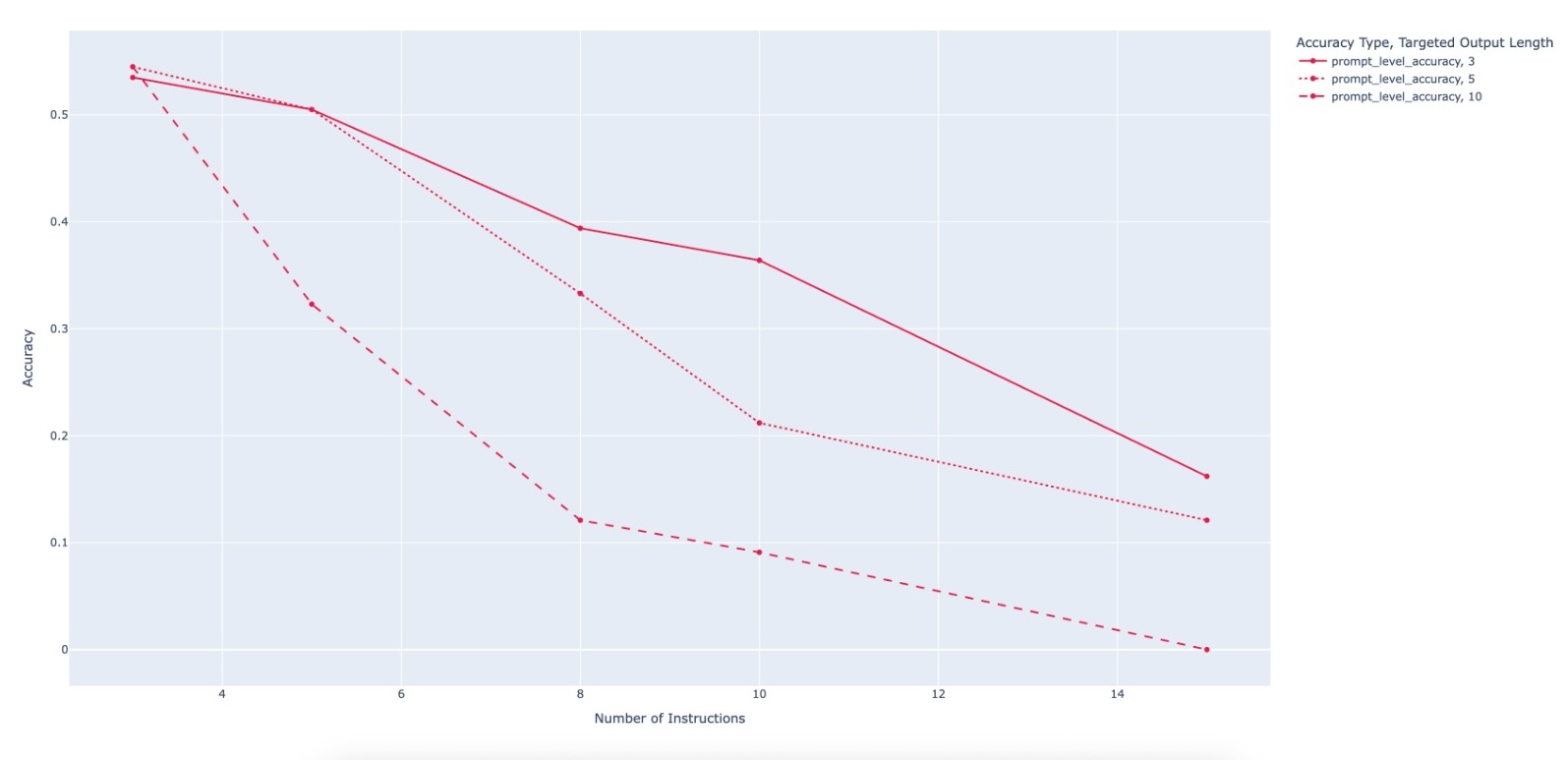
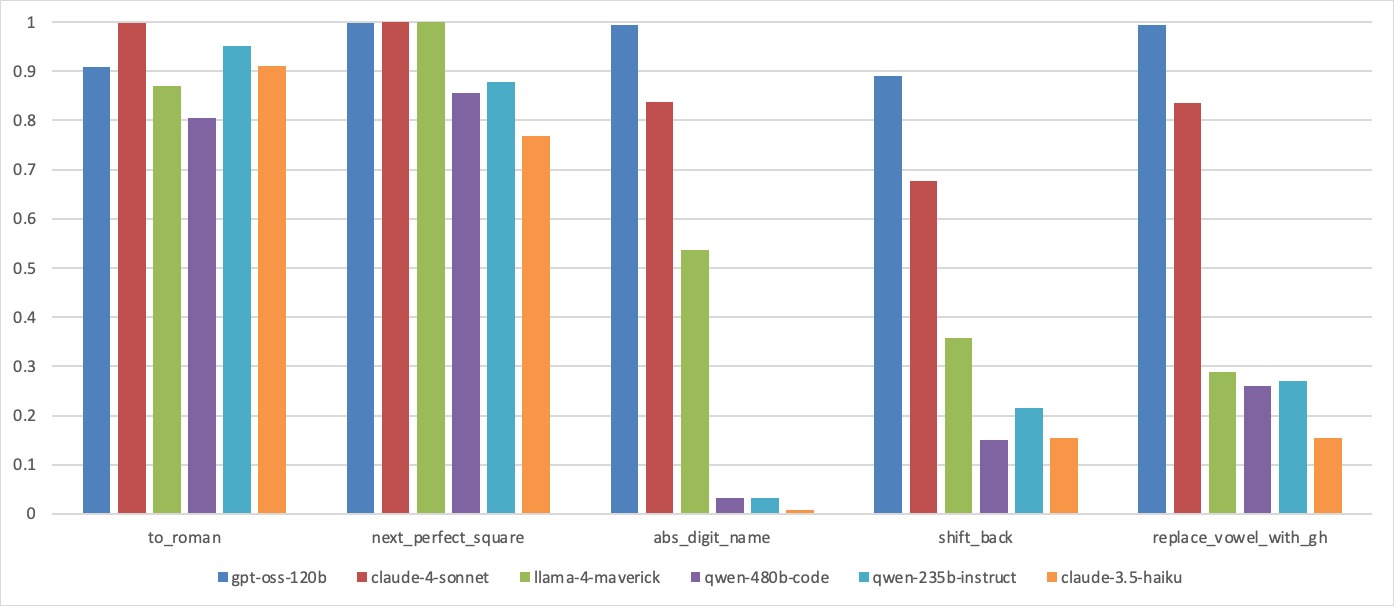
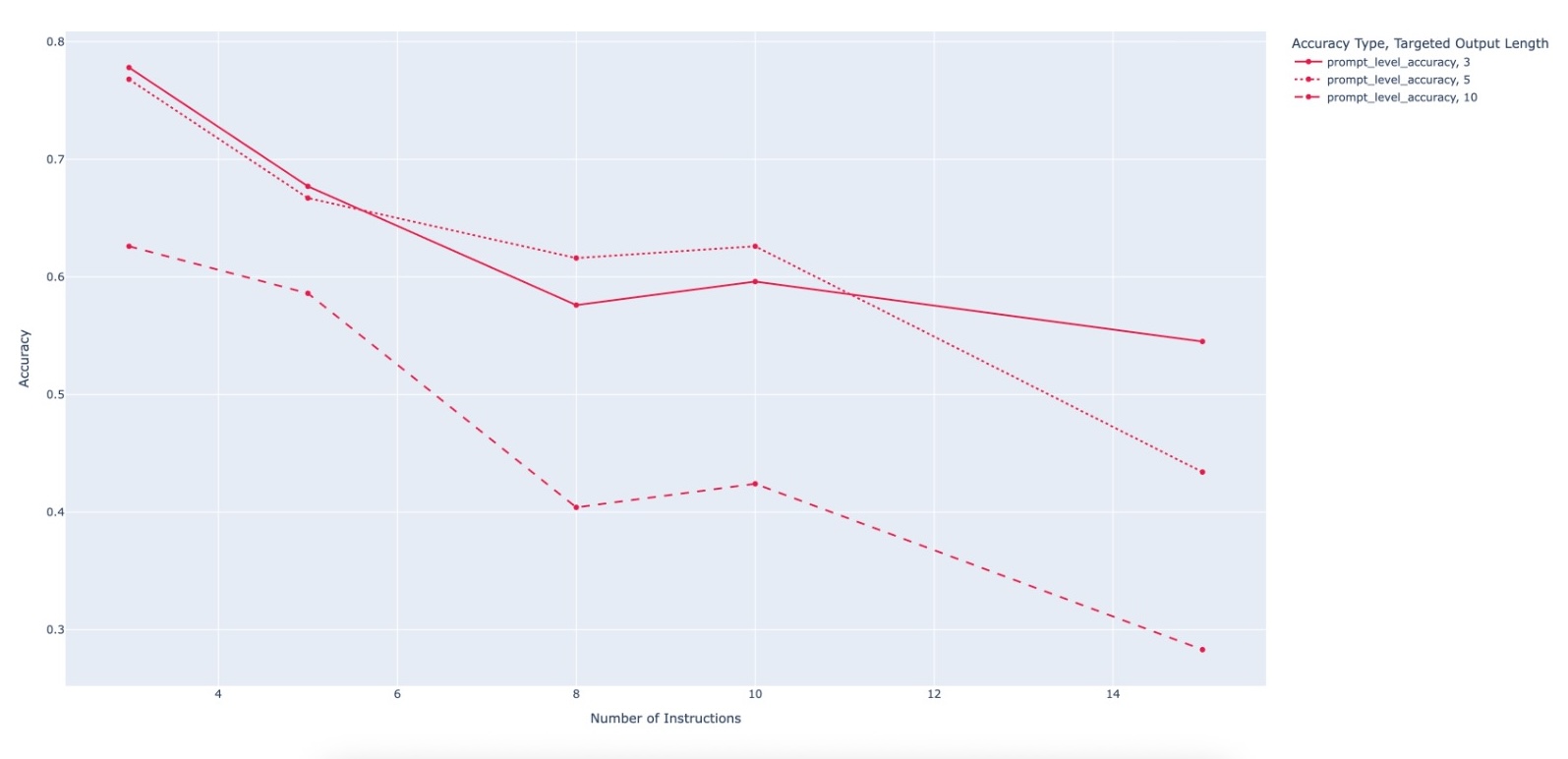
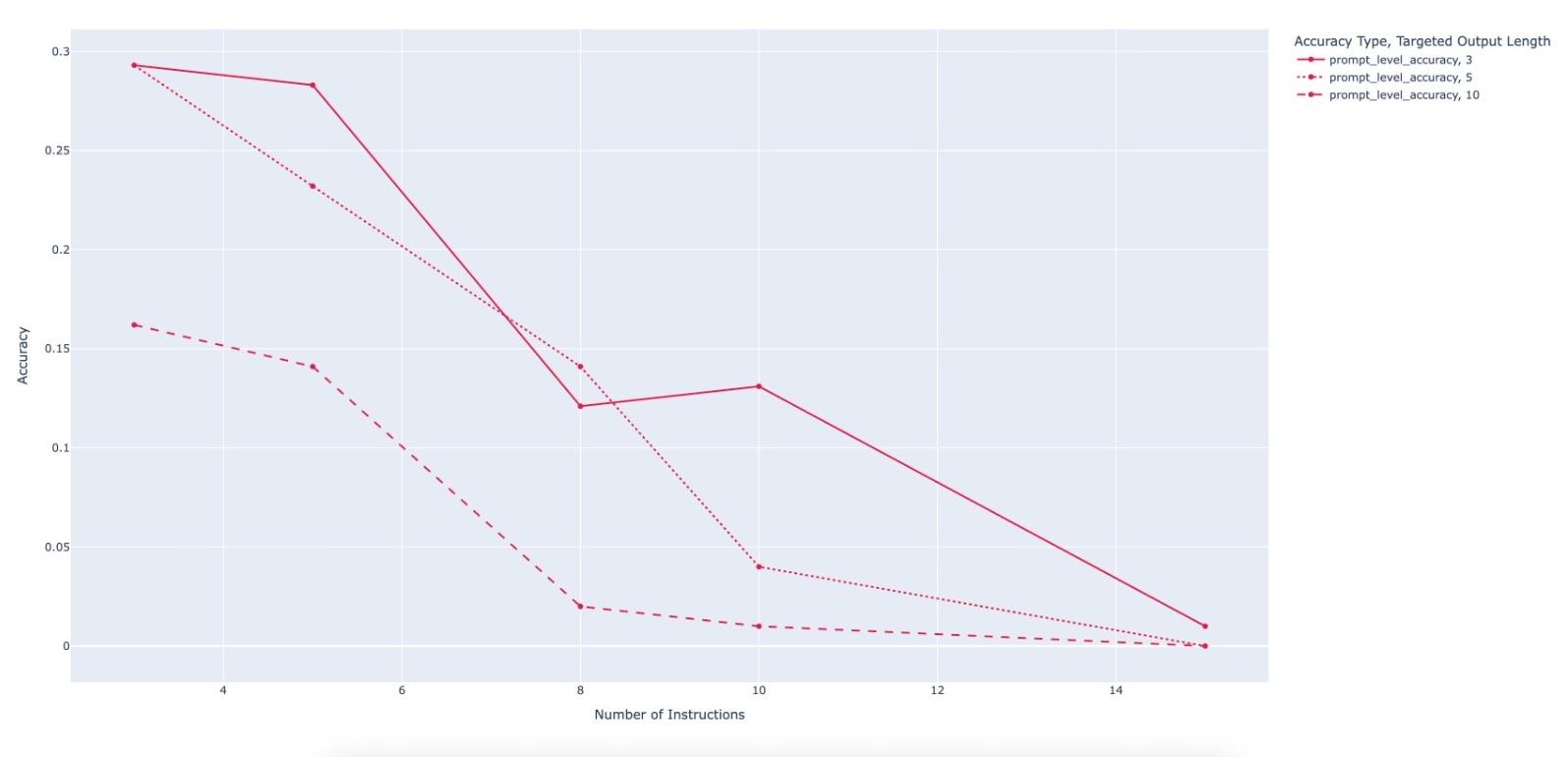
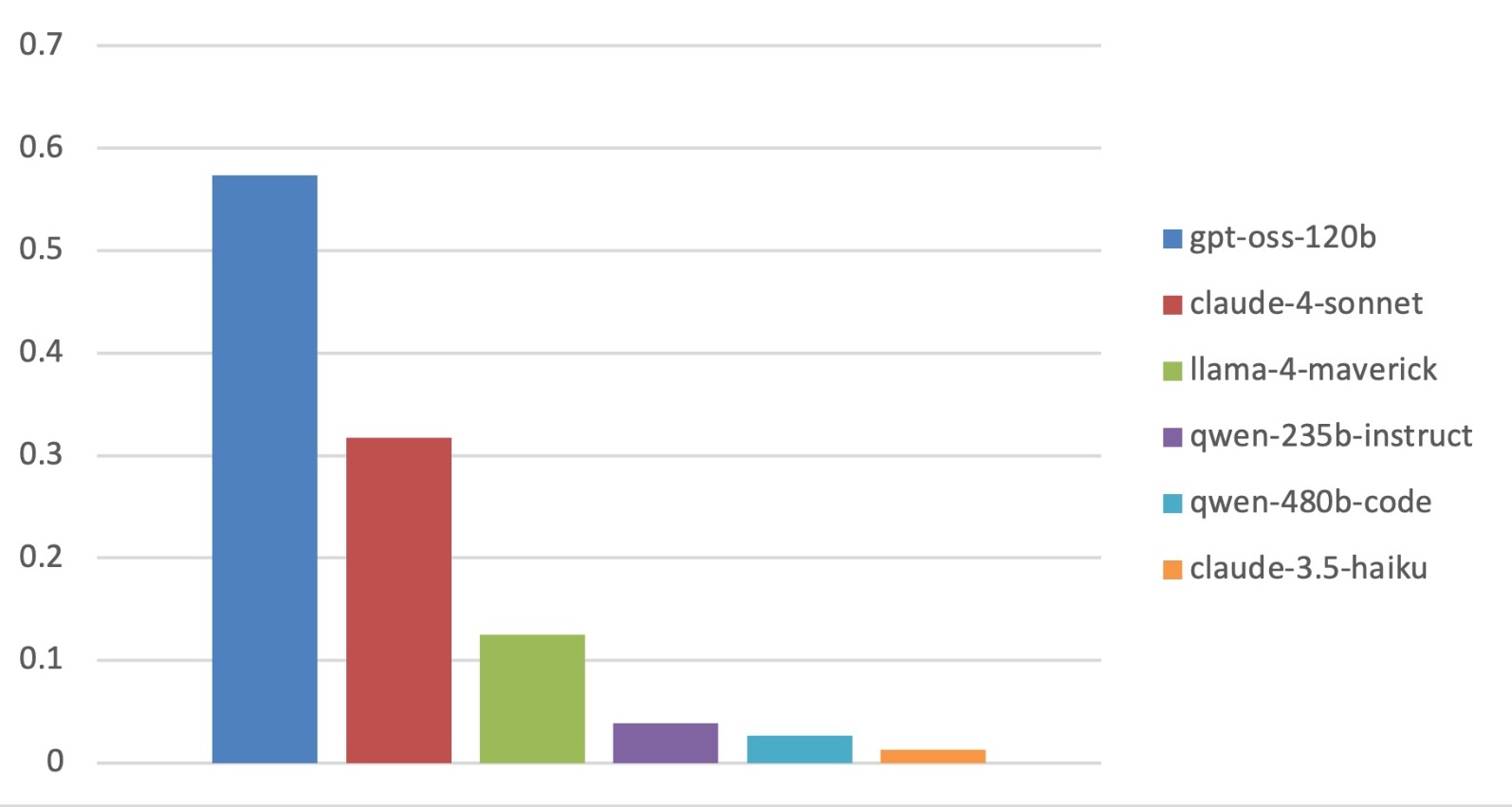
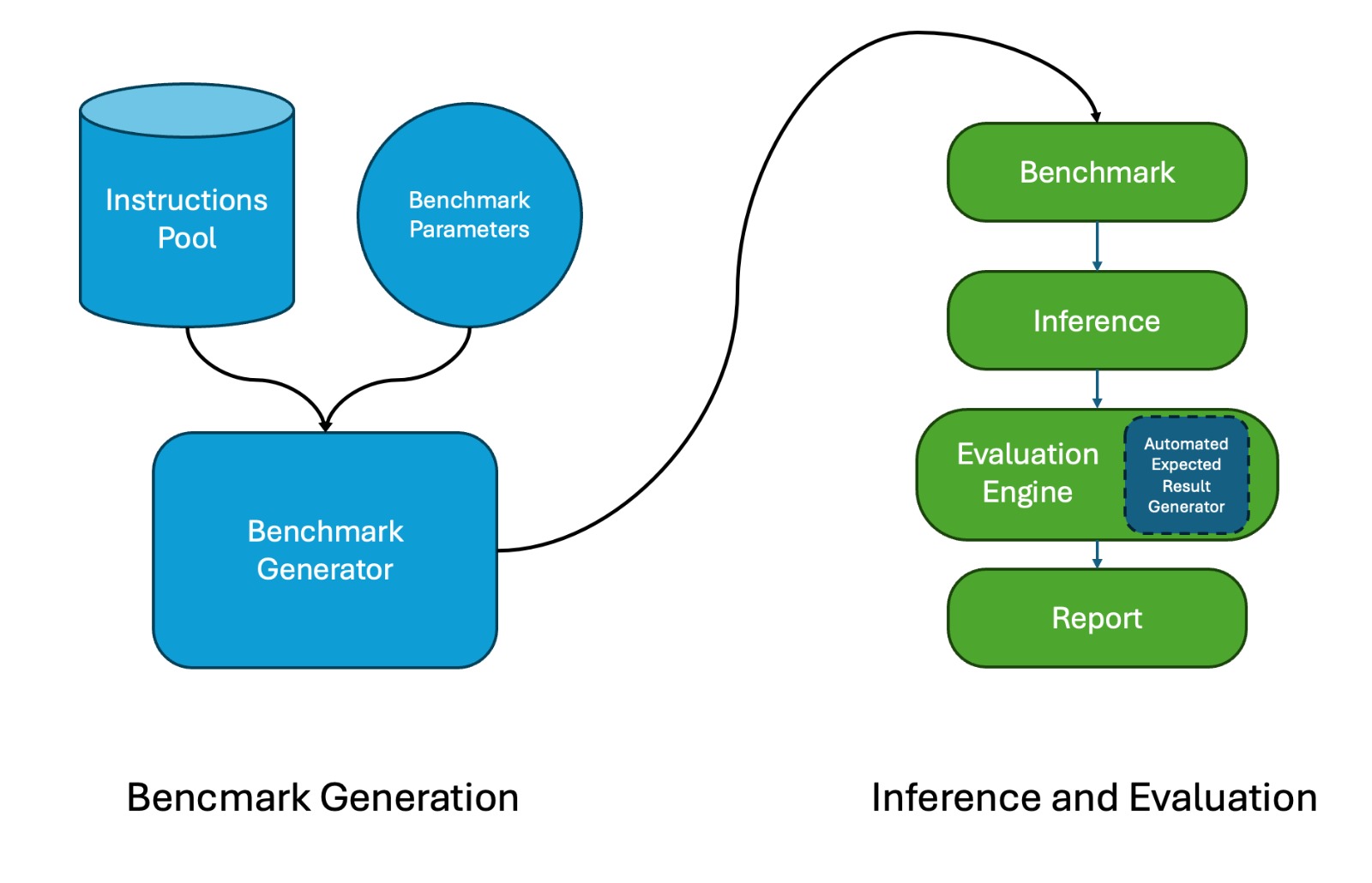
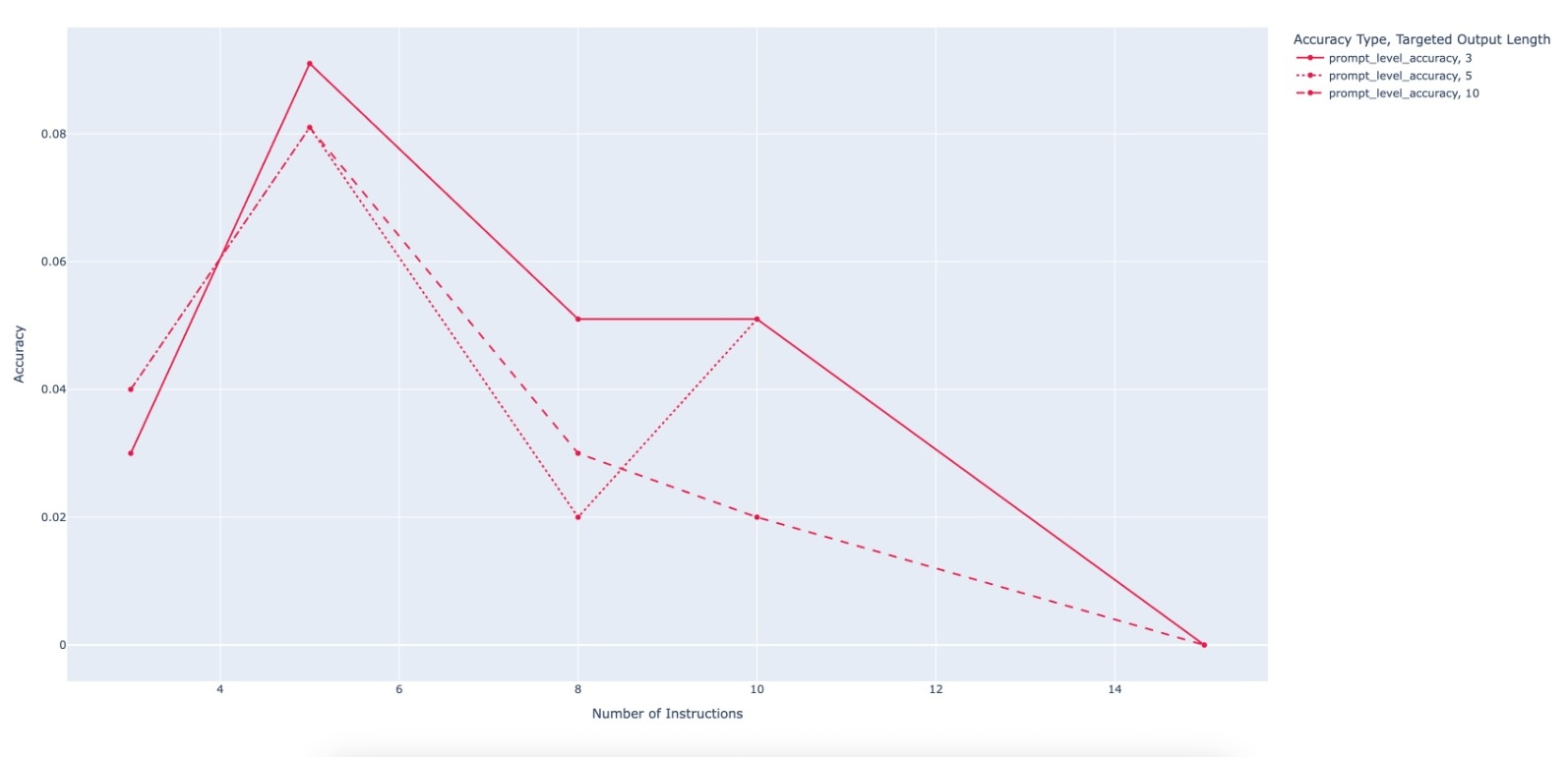
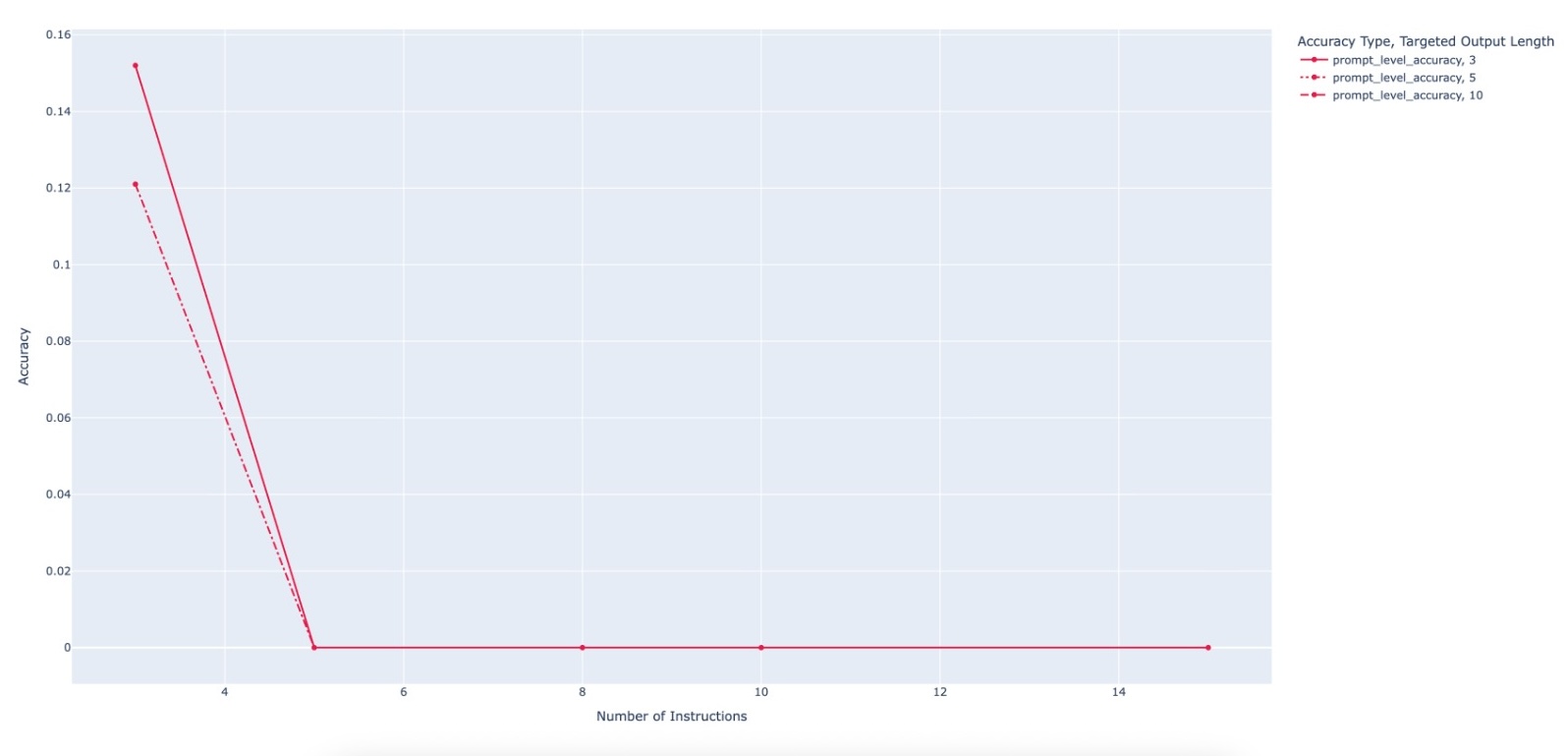
Large Language Model (LLM)-based code assistants have emerged as a powerful application of generative AI, demonstrating impressive capabilities in code generation and comprehension. A key requirement for these systems is their ability to accurately follow user instructions. We present Precise Automatically Checked Instruction Following In Code (PACIFIC), a novel framework designed to automatically generate benchmarks that rigorously assess sequential instruction-following and code dry-running capabilities in LLMs, while allowing control over benchmark difficulty. PACIFIC produces benchmark variants with clearly defined expected outputs, enabling straightforward and reliable evaluation through simple output comparisons. In contrast to existing approaches that often rely on tool usage or agentic behavior, our work isolates and evaluates the LLM's intrinsic ability to reason through code behavior step-by-step without execution (dry running) and to follow instructions. Furthermore, our framework mitigates training data contamination by facilitating effortless generation of novel benchmark variations. We validate our framework by generating a suite of benchmarks spanning a range of difficulty levels and evaluating multiple state-of-the-art LLMs. Our results demonstrate that PACIFIC can produce increasingly challenging benchmarks that effectively differentiate instruction-following and dry running capabilities, even among advanced models. Overall, our framework offers a scalable, contamination-resilient methodology for assessing core competencies of LLMs in code-related tasks.