Title: Robustness of Probabilistic Models to Low-Quality Data: A Multi-Perspective Analysis
ArXiv ID: 2512.11912
Date: 2025-12-11
Authors: Liu Peng, Yaochu Jin
📝 Abstract
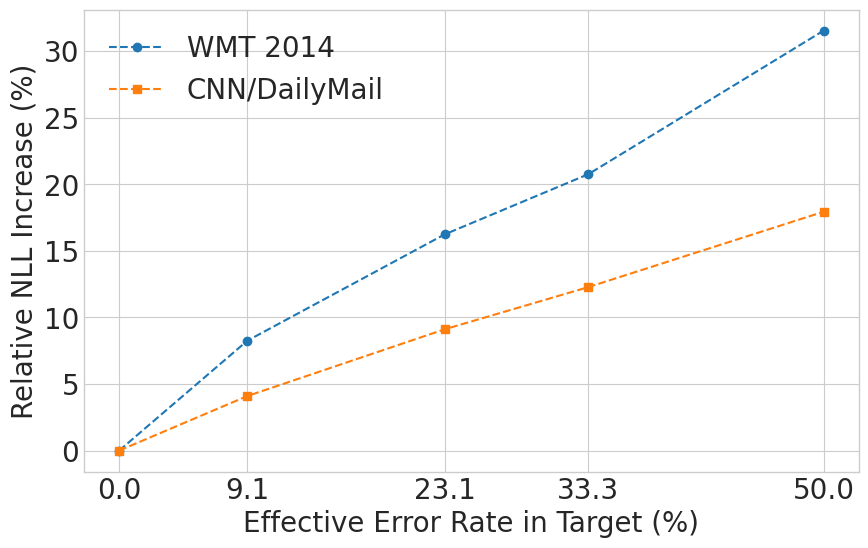
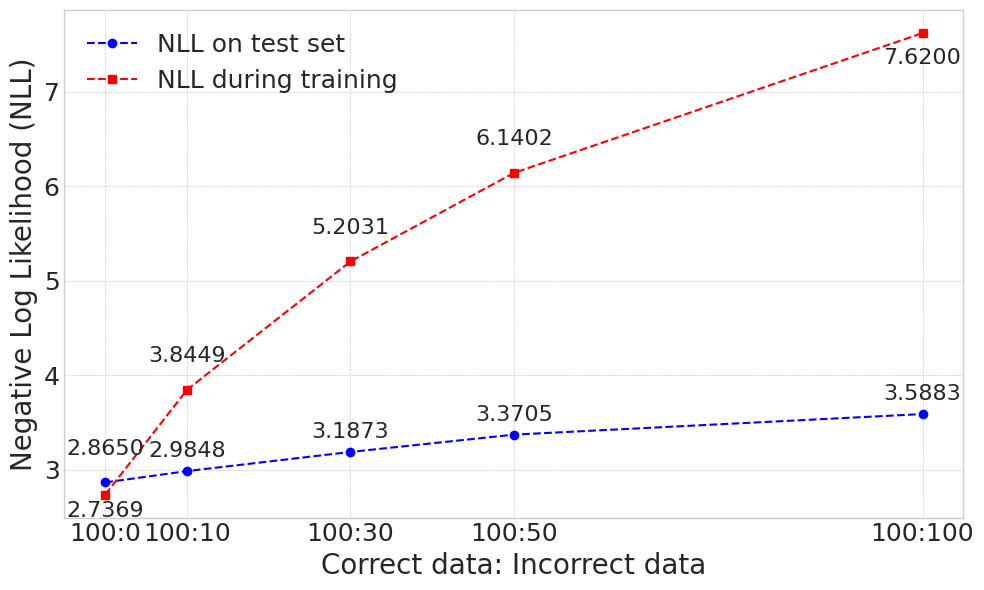
A systematic, comparative investigation into the effects of low-quality data reveals a stark spectrum of robustness across modern probabilistic models. We find that autoregressive language models, from token prediction to sequence-to-sequence tasks, are remarkably resilient (for GPT-2, test NLL increases modestly from 2.87 to 3.59 despite 50% token corruption). By contrast, under the same levels of data corruption, class-conditional diffusion models degrade catastrophically (image-label consistency plummets by 56.81% relative to baseline), while classifiers show a moderate impact that diminishes with dataset scale. To explain these discrepancies, we analyze the results through a multi-perspective lens, integrating information theory, PAC learning, and gradient dynamics. These analyses suggest that robustness is heavily influenced by two key principles: the richness of conditioning information, which constrains the learning problem, and the absolute information content of the training data, which allows the signal from correct information to dominate statistical noise.
💡 Deep Analysis
📄 Full Content
Preprint
ROBUSTNESS OF PROBABILISTIC MODELS TO LOW-
QUALITY DATA: A MULTI-PERSPECTIVE ANALYSIS
Liu Peng
Trustworthy and General AI Lab
Westlake University
Hangzhou, China
LiuPeng_NGP@outlook.com
Yaochu Jin∗
Department of Artificial Intelligence
Westlake University
Hangzhou, China
jinyaochu@westlake.edu.cn
ABSTRACT
A systematic, comparative investigation into the effects of low-quality data re-
veals a stark spectrum of robustness across modern probabilistic models. We
find that autoregressive language models, from token prediction to sequence-to-
sequence tasks, are remarkably resilient (for GPT-2, test NLL increases modestly
from 2.87 to 3.59 despite 50% token corruption). By contrast, under the same lev-
els of data corruption, class-conditional diffusion models degrade catastrophically
(image-label consistency plummets by 56.81% relative to baseline), while classi-
fiers show a moderate impact that diminishes with dataset scale. To explain these
discrepancies, we analyze the results through a multi-perspective lens, integrating
information theory, PAC learning, and gradient dynamics. These analyses suggest
that robustness is heavily influenced by two key principles: the richness of con-
ditioning information, which constrains the learning problem, and the absolute
information content of the training data, which allows the signal from correct
information to dominate statistical noise.
1
INTRODUCTION
Contemporary deep learning models are trained on increasingly vast datasets where the presence of
low-quality data is inevitable (Radford et al., 2018; 2019; Brown et al., 2020; Podell et al., 2023b;
Li et al., 2024). How models contend with such data, however, is far from uniform. Our systematic
investigation reveals a stark divergence in robustness across modern probabilistic models: while
autoregressive language models and large-scale classifiers are remarkably resilient to high levels of
data corruption, class-conditional diffusion models exhibit catastrophic degradation under the same
conditions.
This dramatic disparity, which synthesizes observations from prior work on discriminative model
robustness (Rolnick et al., 2018) and generative model fragility (Na et al., 2023), motivates the
central goal of this paper: to move beyond model-specific observations and uncover the fundamental
principles governing this behavior. Why do some of the most powerful models in AI occupy opposite
ends of the robustness spectrum?
To systematically probe this disparity, we conduct a suite of controlled experiments across these
three representative model families. Our methodology involves dynamically introducing quantifi-
able, random errors into the training data, allowing us to precisely control the level of corruption.
This paradigm lets us study the effects of what we term low-quality data, which we define func-
tionally as samples where the relationship between inputs, conditions, and target outputs has been
corrupted in a way that is detrimental to the specific learning task.
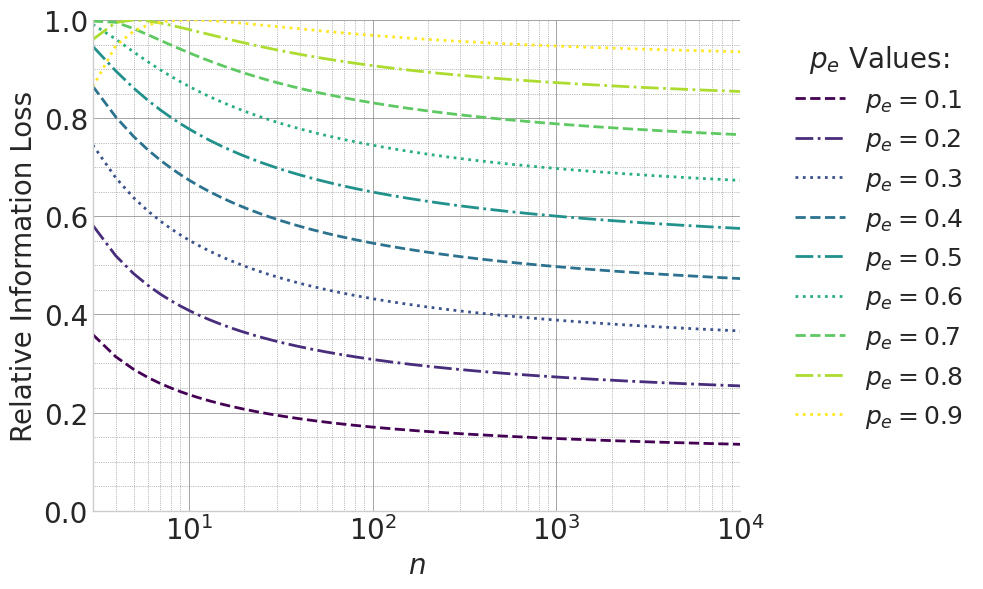
To answer this question, we adopt a multi-perspective analytical approach, integrating insights from
information theory, PAC learning, and gradient dynamics. We hypothesize that the observed dis-
parities can be explained by a coherent set of underlying factors. By integrating empirical findings
with these theoretical viewpoints, we aim to provide foundational insights for understanding and
predicting model robustness in real-world, noisy environments.
∗Corresponding Author
1
arXiv:2512.11912v1 [cs.AI] 11 Dec 2025
Preprint
The key contributions of this work are as follows:
• We conduct a systematic empirical investigation that validates and quantifies a stark di-
vergence in robustness across autoregressive language models, class-conditional diffusion
models, and image classifiers, providing controlled evidence for this critical phenomenon.
• We propose and apply a multi-perspective analytical framework that uses information the-
ory, PAC learning, and gradient dynamics to explain what informational properties drive
robustness, why they are formally required for generalization, and how the optimization
process mechanistically achieves this resilience.
• Through this integrated approach, we identify two fundamental factors that govern model
robustness: (1) the richness of conditioning information available to the model, and (2)
the absolute information content of the training data.
2
RELATED WORK
The challenge of training on imperfect data is a central theme in machine learning, giving rise to
a rich literature on noise robustness. For discriminative models, this is a well-established field;
the surprising resilience of deep classifiers to label noise is well-documented (Rolnick et al., 2018;
ZhangChiyuan et al., 2021), leading to an ecosystem of solutions, from noise-robust loss functions
(Menon et al., 2019; Chen et al., 2020) to techniques for noise correction (Yi & Wu, 2019). More
recently, attention has turned to the fragility of modern generative models.