Title: HLS4PC: A Parametrizable Framework For Accelerating Point-Based 3D Point Cloud Models on FPGA
ArXiv ID: 2512.22139
Date: 2025-12-11
Authors: Amur Saqib Pal, Muhammad Mohsin Ghaffar, Faisal Shafait, Christian Weis, Norbert Wehn
📝 Abstract
Point-based 3D point cloud models employ computation and memory intensive mapping functions alongside NN layers for classification/segmentation, and are executed on server-grade GPUs. The sparse, and unstructured nature of 3D point cloud data leads to high memory and computational demand, hindering real-time performance in safety critical applications due to GPU under-utilization. To address this challenge, we present HLS4PC, a parameterizable HLS framework for FPGA acceleration. Our approach leverages FPGA parallelization and algorithmic optimizations to enable efficient fixed-point implementations of both mapping and NN functions. We explore several hardware-aware compression techniques on a state-of-the-art PointMLP-Elite model, including replacing FPS with URS, parameter quantization, layer fusion, and input-points pruning, yielding PointMLP-Lite, a 4x less complex variant with only 2% accuracy drop on ModelNet40. Secondly, we demonstrate that the FPGA acceleration of the PointMLP-Lite results in 3.56x higher throughput than previous works. Furthermore, our implementation achieves 2.3x and 22x higher throughput compared to the GPU and CPU implementations, respectively.
💡 Deep Analysis
📄 Full Content
HLS4PC: A Parametrizable Framework For
Accelerating Point-Based 3D Point Cloud Models
on FPGA
Amur Saqib Pal1∗, Muhammad Mohsin Ghaffar2∗(B), Faisal Shafait1,
Christian Weis2, and Norbert Wehn2
1 National University of Sciences and Technology, 44000 Islamabad, Pakistan
{apal.bee19seecs,faisal.shafait}@seecs.edu.pk
2 Microelectronic Systems Design Research Group, RPTU Kaiserslautern-Landau,
67663 Kaiserslautern, Germany
{mohsin.ghaffar,christian.weis,norbert.wehn}@rptu.de
Abstract. Point-based 3D point cloud models employ computation and
memory intensive mapping functions alongside Neural Network (NN)
layers for classification/segmentation, and are executed on server-grade
Graphics Processing Units (GPUs). The sparse, and unstructured na-
ture of 3D point cloud data leads to high memory and computational
demand, hindering real-time performance in safety-critical applications
due to GPU under-utilization. To address this challenge, we present
HLS4PC, a parameterizable High Level Synthesis (HLS) framework for
Field-Programmable Gate Array (FPGA) acceleration. Our approach
leverages FPGA parallelization and algorithmic optimizations to enable
efficient fixed-point implementations of both mapping and NN functions.
We explore several hardware-aware compression techniques on a state-of-
the-art PointMLP-Elite model, including replacing Farthest Point Sam-
pling (FPS) with Uniform Random Sampling (URS), parameter quanti-
zation, layer fusion, and input-points pruning, yielding PointMLP-Lite,
a 4× less complex variant with only ∼2% accuracy drop on Model-
Net40. Secondly, we demonstrate that the FPGA acceleration of the
PointMLP-Lite results in 3.56× higher throughput than previous works.
Furthermore, our implementation achieves 2.3× and 22× higher through-
put compared to the GPU and Central Processing Unit (CPU) imple-
mentations, respectively. The code of the HLS4PC framework will be
available at: https://github.com/dll-ncai/HLS4PC.
Keywords: FPGA · Dataflow Architecture · Point Cloud Acceleration
1
Introduction
In recent years, 3D point cloud data from Light Detection and Ranging (Li-
DAR) or RGB-D sensors is increasingly used in applications such as autonomous
* These authors contributed equally to this work
The research reported in this work is partially supported by the Carl Zeiss Stiftung,
Germany, under the Sustainable Embedded AI project (P2021-02-009).
arXiv:2512.22139v1 [cs.DC] 11 Dec 2025
2
A. S. Pal & M. M. Ghaffar et al.
driving, robotics, drones, 3D reconstruction, Virtual Reality (VR)/Augmented
Reality (AR) head-sets and even the iPhone 16 Pro. Processing 3D point clouds
is challenging due to their sparsity, with unevenly distributed data points in
3D space. Since classification and segmentation are vital for safety-critical and
real-time applications, these models must meet strict throughput demands. For
instance, the throughput requirement for an end-to-end level-5 autonomous driv-
ing solution is estimated to be at 2,000 TOPS [7].
In the literature, researchers have proposed projection-based, volumetric-
based, mesh-based, and point-based methods for classification and segmentation
of 3D point cloud data [11]. The point-based approaches [10,6,8] dominate due
to the ability to operate directly on raw 3D data, achieving up to 5% higher
accuracy and lower complexity [5]. These models combine Deep Neural Network
(DNN) layers with mapping functions like Farthest Point Sampling (FPS) and
K-Nearest Neighbor (KNN) to extract features from unordered, sparse 3D data.
While Graphics Processing Units (GPUs) excel at dense matrix operations, they
struggle with irregular mapping functions due to data sparsity [10], leading to
resource under-utilization. A limited number of prior studies have explored the
use of Application-Specific Accelerators [5] to enhance the throughput of 3D
point cloud models. Although, these accelerators can deliver high throughput,
they inherently lack flexibility, making it challenging to deploy evolving and
mixed-precision models.
In contrast, Field-Programmable Gate Array (FPGA) allow precision to be
configured at compile-time, support mixed-precision acceleration without hard-
ware redesign. Additionally, new layers or functions can be added by updating
hardware libraries or reconfiguring logic blocks. These advantages make FPGAs
ideal for 3D point cloud processing, where models evolve rapidly. While vari-
ous FPGA-based DNN frameworks exist [2,13], they cannot accelerate 3D point
cloud models due to their lack of support for point cloud mapping functions. To
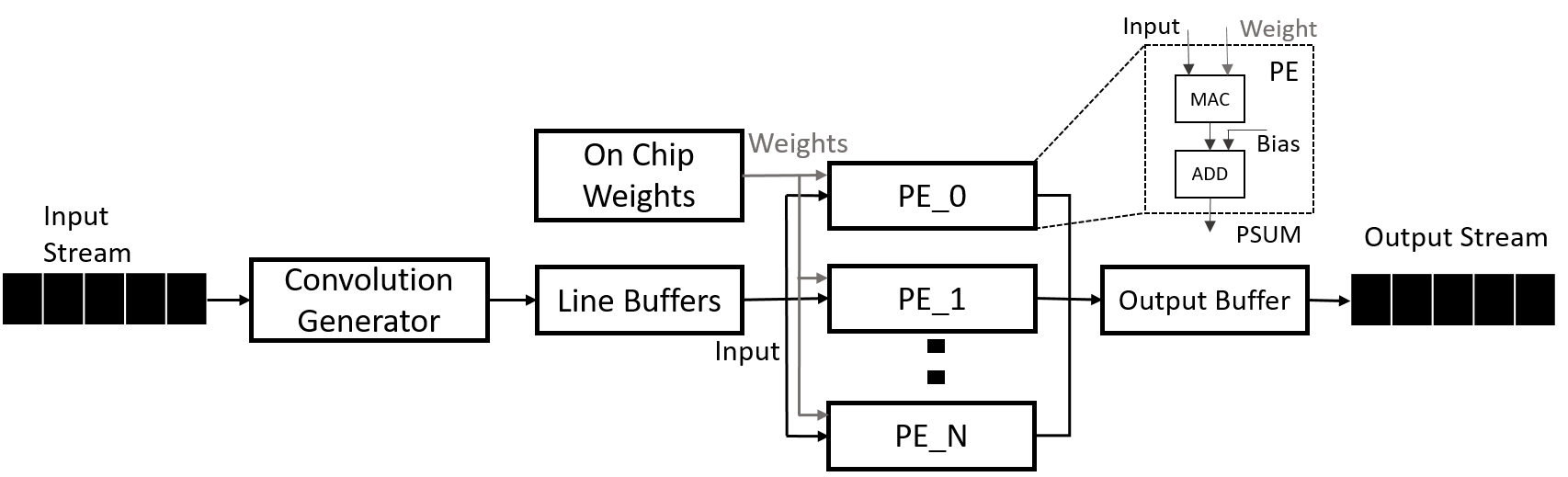
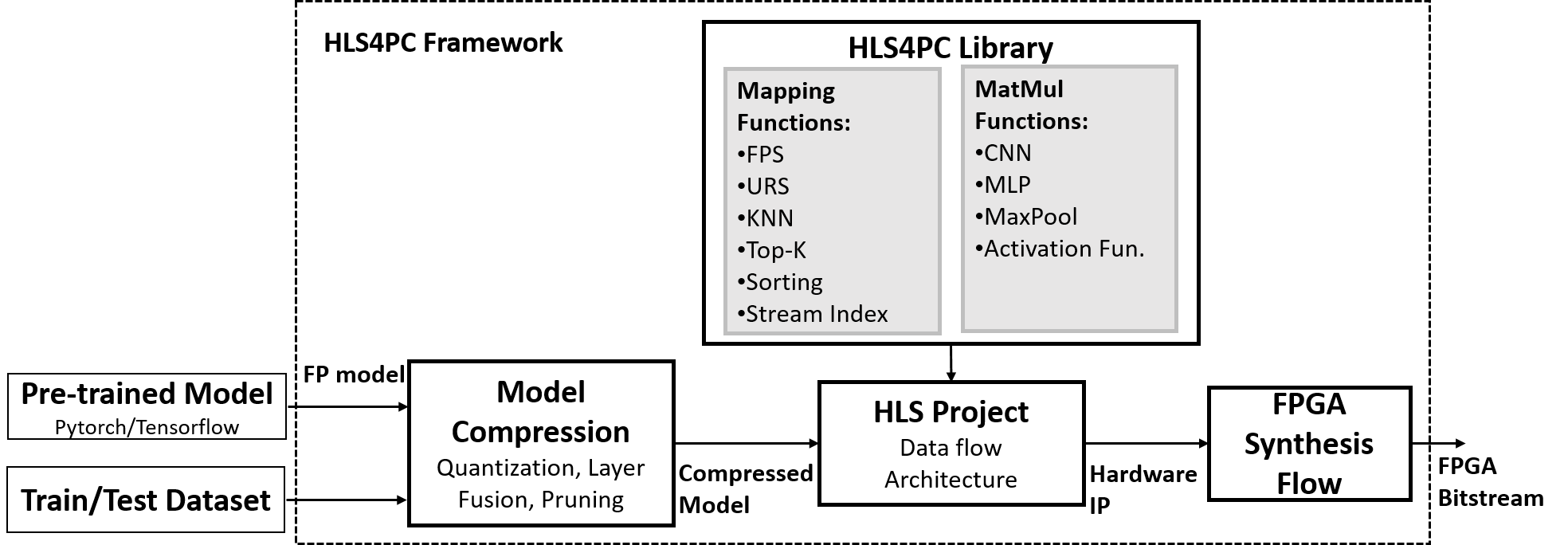
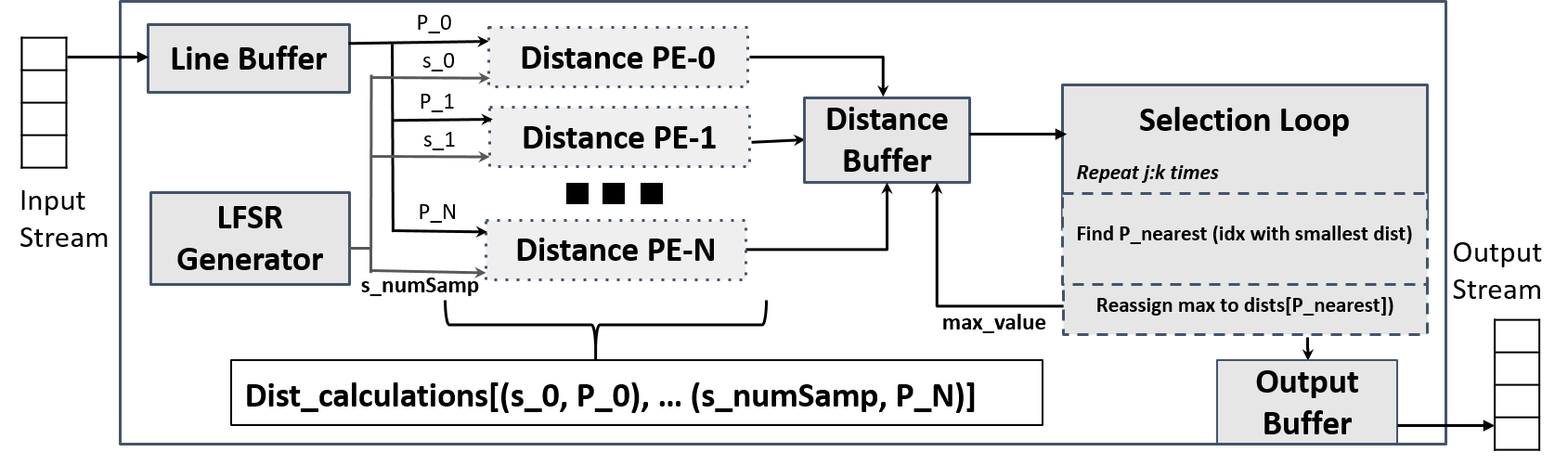
bridge this gap, we propose a parameterizable mixed-precision dataflow-based
streaming framework for acceleration of 3D point cloud models on FPGA pre-
sented as HLS4PC. We perform an in-depth investigation of the effects of com-
pression techniques such as input point pruning, quantization, and layer fusion
combined with hardware-aware mapping functions on model accuracy, utilizing
the ModelNet40 and ScanObjectNN as benchma