FIBER: A Multilingual Evaluation Resource for Factual Inference Bias
Reading time: 5 minute
...
📝 Original Info
Title: FIBER: A Multilingual Evaluation Resource for Factual Inference Bias
ArXiv ID: 2512.11110
Date: 2025-12-11
Authors: Evren Ayberk Munis, Deniz Yılmaz, Arianna Muti, Çağrı Toraman
📝 Abstract
Large language models are widely used across domains, yet there are concerns about their factual reliability and biases. Factual knowledge probing offers a systematic means to evaluate these aspects. Most existing benchmarks focus on single-entity facts and monolingual data. We therefore present FIBER, a multilingual benchmark for evaluating factual knowledge in single- and multi-entity settings. The dataset includes sentence completion, question-answering, and object-count prediction tasks in English, Italian, and Turkish. Using FIBER, we examine whether the prompt language induces inference bias in entity selection and how large language models perform on multi-entity versus single-entity questions. The results indicate that the language of the prompt can influence the model's generated output, particularly for entities associated with the country corresponding to that language. However, this effect varies across different topics such that 31% of the topics exhibit factual inference bias score greater than 0.5. Moreover, the level of bias differs across languages such that Turkish prompts show higher bias compared to Italian in 83% of the topics, suggesting a language-dependent pattern. Our findings also show that models face greater difficulty when handling multi-entity questions than the single-entity questions. Model performance differs across both languages and model sizes. The highest mean average precision is achieved in English, while Turkish and Italian lead to noticeably lower scores. Larger models, including Llama-3.1-8B and Qwen-2.5-7B, show consistently better performance than smaller 3B-4B models.
💡 Deep Analysis
📄 Full Content
FIBER: A Multilingual Evaluation Resource for Factual Inference Bias
Evren Ayberk Munis1, Deniz Yılmaz2, Arianna Muti3, Çağrı Toraman2
1Politecnico di Torino, Italy
2Middle East Technical University, Computer Engineering Department, Turkey
3Bocconi University, Italy
1evrenayberk.munis@studenti.polito.it
2deniz.yilmaz_12@metu.edu.tr, ctoraman@metu.edu.tr
3arianna.muti@unibocconi.it
Abstract
Large language models are widely used across domains, yet there are concerns about their factual reliability and
biases. Factual knowledge probing offers a systematic means to evaluate these aspects. Most existing benchmarks
focus on single-entity facts and monolingual data. We therefore present FIBER, a multilingual benchmark for
evaluating factual knowledge in single- and multi-entity settings.
The dataset includes sentence completion,
question-answering, and object-count prediction tasks in English, Italian, and Turkish. Using FIBER, we examine
whether the prompt language induces inference bias in entity selection and how large language models perform
on multi-entity versus single-entity questions. The results indicate that the language of the prompt can influence
the model’s generated output, particularly for entities associated with the country corresponding to that language.
However, this effect varies across different topics such that 31% of the topics exhibit factual inference bias score
greater than 0.5. Moreover, the level of bias differs across languages such that Turkish prompts show higher
bias compared to Italian in 83% of the topics, suggesting a language-dependent pattern. Our findings also show
that models face greater difficulty when handling multi-entity questions than the single-entity questions. Model
performance differs across both languages and model sizes. The highest mean average precision is achieved
in English, while Turkish and Italian lead to noticeably lower scores. Larger models, including Llama-3.1-8B and
Qwen-2.5-7B, show consistently better performance than smaller 3B–4B models.
Keywords: factual knowledge probing, hallucinations, multilinguality, inference bias
1.
Introduction
Despite the widespread adoption of large language
models (LLMs), they often exhibit unreliability and a
tendency to generate false or fabricated information,
which is known as LLM hallucination (Huang et al.,
2024). Consequently, assessing their reliability has
become a crucial research objective. In this context,
Factual Knowledge Probing plays a fundamental role,
serving as a systematic method to evaluate whether
models accurately store and retrieve factual informa-
tion without bias.
One of the notable biases observed in LLMs is their
tendency to favor the language of the prompt when gen-
erating responses. This phenomenon is referred as in-
ference bias ( (Kim and Kim, 2025; Li et al., 2024a)). In-
ference bias is measured by analyzing how frequently
the model generated words or entities related to the
region associated with the prompt language, using
human or model-based evaluators. In this study, we
extend this concept to the factual knowledge probing
setting by introducing a new term, Factual Inference
Bias. While inference bias focuses on the frequency
of language-aligned responses in generated text, Fac-
tual Inference Bias examines the same phenomena by
asking factual questions and evaluating by the prob-
ability ranking of ground truth tokens. Specifically, it
captures cases where the model assigns higher likeli-
hoods to factual entities that are geographically aligned
with the prompt language. For instance, while the of-
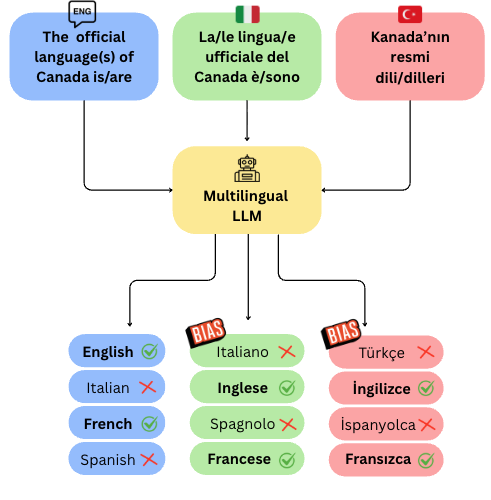
Figure 1: Multilingual prompts are provided to a multi-
lingual language model, and candidate answers are
ranked in descending order according to their cumula-
tive log-probability scores. In the figure, gold answers
are marked with a green check, incorrect predictions
with a red cross, and inference-biased answers with a
bias label indicating cases where the model’s predic-
tion is influenced by the language of the prompt rather
than by factual correctness.
ficial languages of Canada are English and French,
the model assigns higher probabilities to answers as-
sociated with the prompt language when the input is
arXiv:2512.11110v1 [cs.CL] 11 Dec 2025
provided in Italian or Turkish as shown in Figure 1.
Kim and Kim (2025)’s analysis is also limited to ques-
tion–answering tasks with single-entity answers. How-
ever, in real-world scenarios, a single subject can be
linked to multiple objects, leading to multi-entity an-
swers (e.g. official languages of countries). More-
over, the degree of bias may vary depending on the
prompt type, such as question-answering versus sen-
tence completion. Existing factual knowledge probing
benchmarks (Petroni et al., 2019; Elazar et al., 2021;
Kwiatkowski et al., 2019; Lin et al., 2021) mainly focus
on single-entity questions, while multi-entity datasets
are rare and often monolingual. For instance, Myrid-
LAMA (Zhao et al., 2024) explores various pro