https://refkxh.github.io/BiCo_Webpage A butterfly flapping its wings softly on a vibrant yellow flower, surrounded by a vibrant Minecraft landscape featuring a dynamic volcano which erupts, spewing vibrant red lava and creating a dramatic ash cloud against a serene blue sky, with molten lava pooling on the black rocks below. A beautiful butterfly rests on a vibrant yellow flower, flapping its wings softly against a backdrop of lush green leaves.
💡 Deep Analysis
📄 Full Content
Composing Concepts from Images and Videos via Concept-prompt Binding
Xianghao Kong1 , Zeyu Zhang1 , Yuwei Guo2 , Zhuoran Zhao1,3 , Songchun Zhang1 , Anyi Rao1
1 HKUST 2 CUHK 3 HKUST(GZ)
https://refkxh.github.io/BiCo_Webpage
A butterfly flapping its wings softly on a vibrant yellow flower, surrounded by a vibrant Minecraft landscape featuring a dynamic volcano which
erupts, spewing vibrant red lava and creating a dramatic ash cloud against a serene blue sky, with molten lava pooling on the black rocks below.
A beautiful butterfly rests on a vibrant yellow flower, flapping
its wings softly against a backdrop of lush green leaves.
A vibrant Minecraft landscape
featuring a flowing river, lush
trees, a cascading waterfall…
A dynamic volcano erupts,
spewing vibrant red lava and
creating a dramatic ash cloud…
A beagle dog wearing a collar mixes a drink vigorously using a shaker with its dog's paws at a bar, surrounded by a cityscape visible through a large window.
A beagle dog wearing a collar stands on a
pathway surrounded by grass and grassland.
A bartender in a black shirt skillfully mixes a drink in a shaker at a bar, surrounded by a cityscape visible
through a large window.
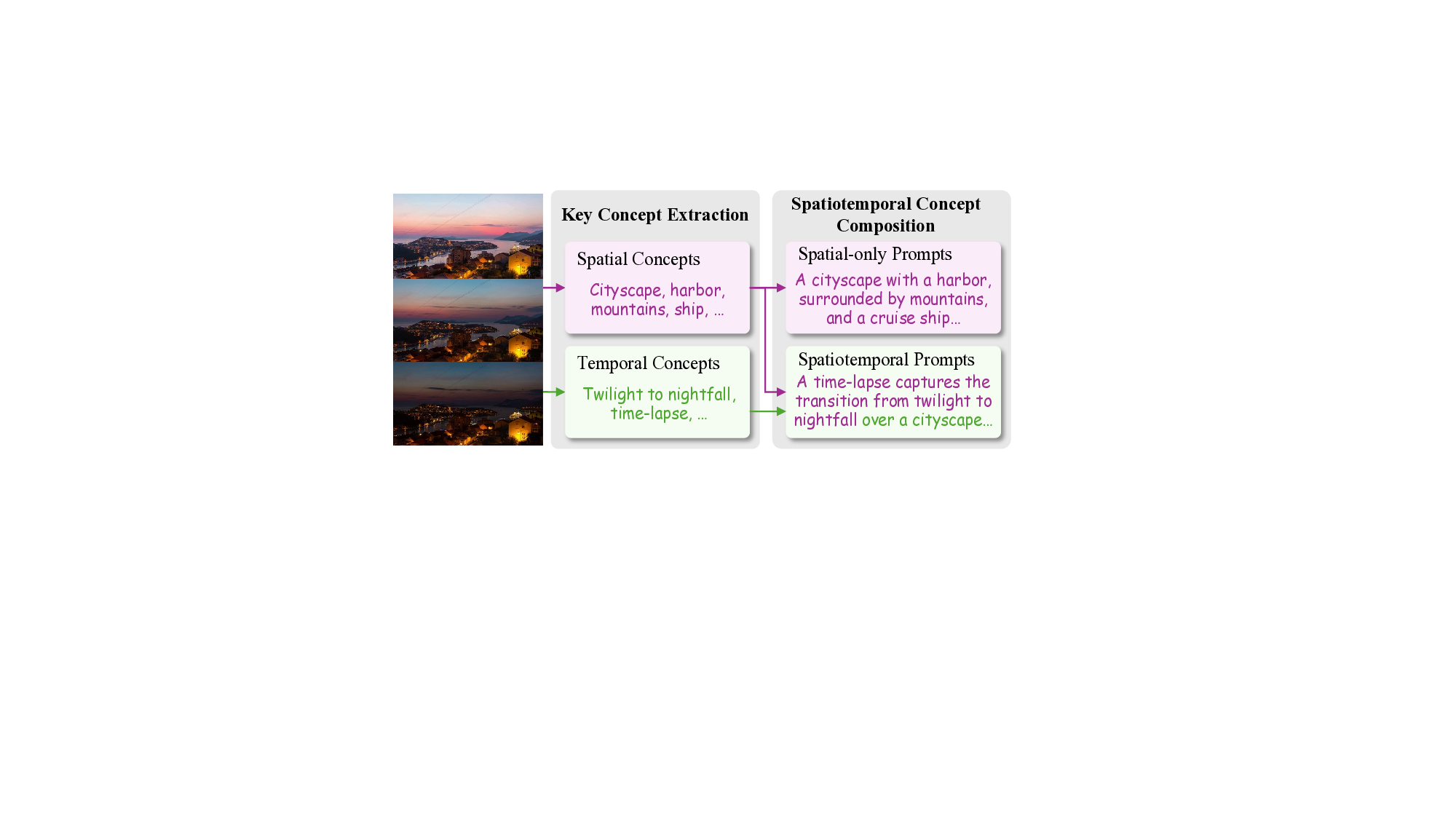
Figure 1. Illustration of BiCo, a one-shot method that enables flexible visual concept composition by binding visual concepts with the
corresponding prompt tokens and composing the target prompt with bound tokens from various sources (§1).
Abstract
Visual concept composition, which aims to integrate differ-
ent elements from images and videos into a single, coher-
ent visual output, still falls short in accurately extracting
complex concepts from visual inputs and flexibly combining
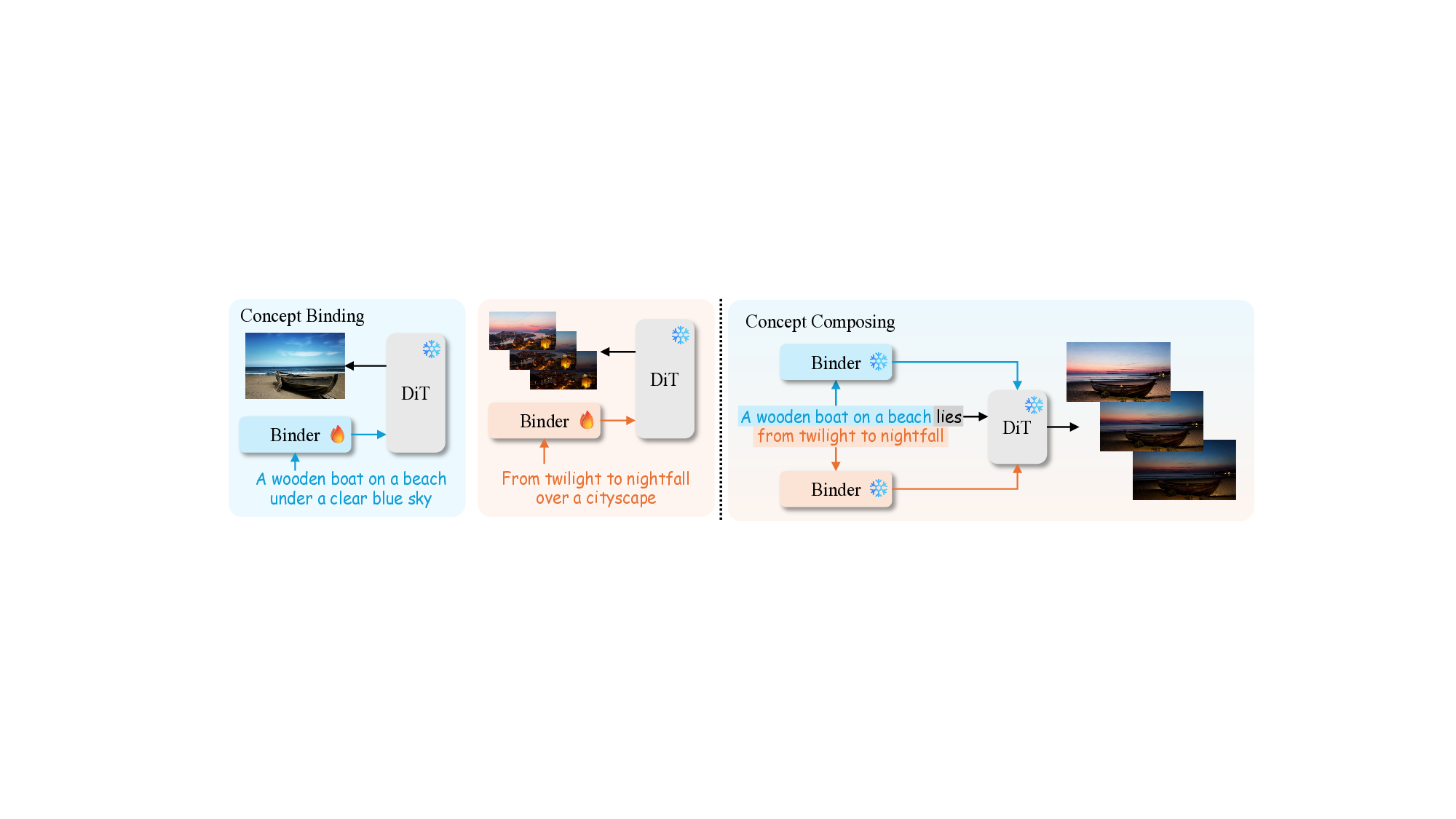
concepts from both images and videos. We introduce Bind
& Compose, a one-shot method that enables flexible visual
concept composition by binding visual concepts with corre-
sponding prompt tokens and composing the target prompt
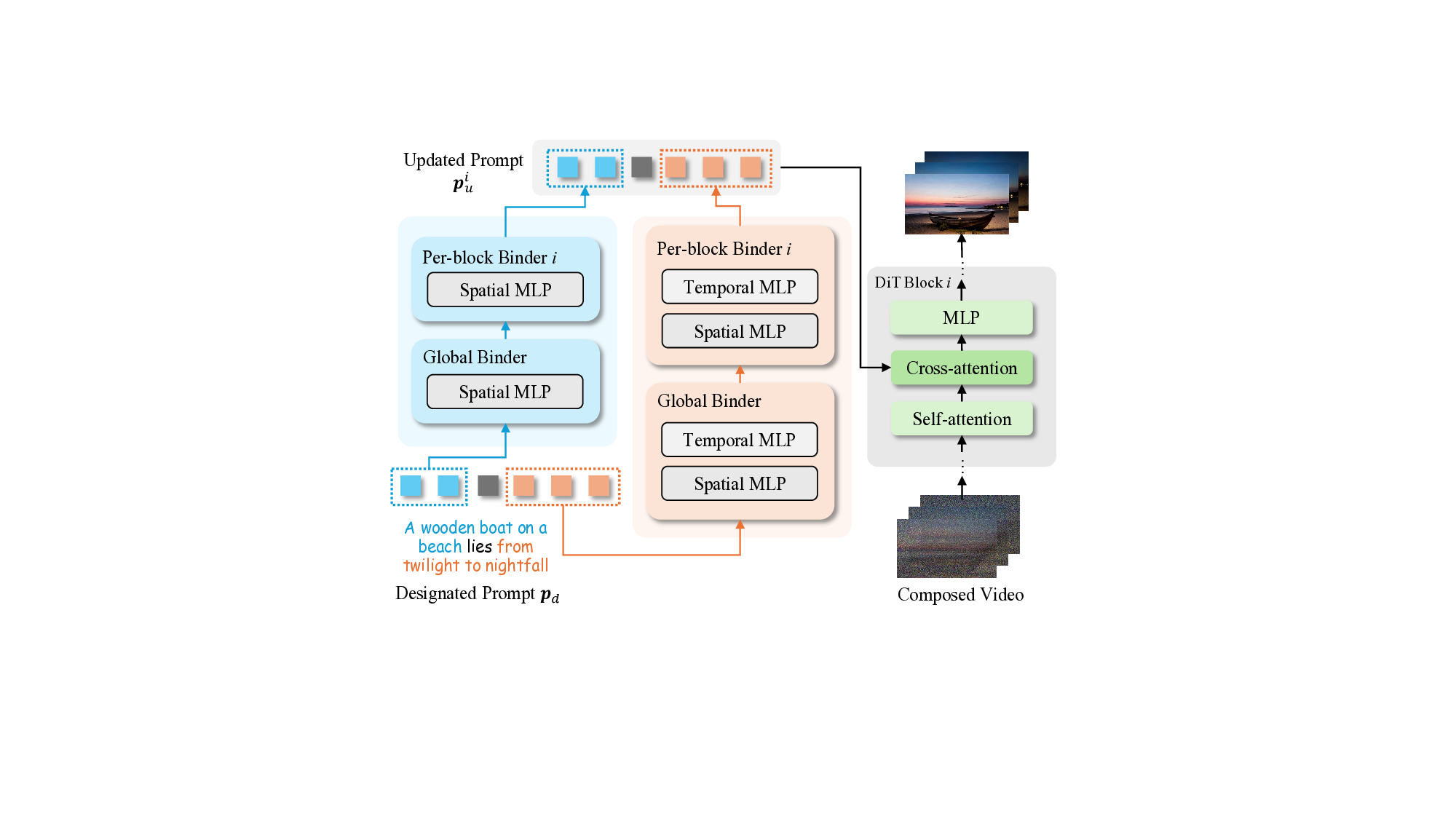
with bound tokens from various sources. It adopts a hier-
archical binder structure for cross-attention conditioning in
Diffusion Transformers to encode visual concepts into cor-
responding prompt tokens for accurate decomposition of
complex visual concepts. To improve concept-token bind-
ing accuracy, we design a Diversify-and-Absorb Mecha-
nism that uses an extra absorbent token to eliminate the im-
pact of concept-irrelevant details when training with diver-
sified prompts. To enhance the compatibility between image
and video concepts, we present a Temporal Disentangle-
ment Strategy that decouples the training process of video
concepts into two stages with a dual-branch binder struc-
ture for temporal modeling. Evaluations demonstrate that
our method achieves superior concept consistency, prompt
fidelity, and motion quality over existing approaches, open-
ing up new possibilities for visual creativity.
1
arXiv:2512.09824v1 [cs.CV] 10 Dec 2025
1. Introduction
Visual concept composition aims to integrate different ele-
ments from images and videos into a single, coherent visual
output. This process is a reflection of human artists’ cre-
ation: combining ingredients from various inspirations to
form a brand new masterpiece [15]. Consequently, it plays
a fundamental role in visual creativity and filmmaking [62].
With the rapid advancement of diffusion-based visual con-
tent generation models [16, 20, 29–31, 35, 40, 42, 54, 58,
61, 63], an increasing number of works [1, 3, 11, 14, 18,
26, 32–34, 55, 56] have been exploring the field of visual
concept composition by exploiting the generative models’
strong capability of concept grounding and customization.
Despite considerable efforts devoted to this field, chal-
lenges still remain in accurately extracting complex con-
cepts from visual inputs and flexibly combining concepts
from both images and videos. First, the capability to pre-
cisely extract specific concepts from various sources is of
great significance for visual content creators. Nevertheless,
existing mainstream methods [1, 3, 14, 26, 32, 34, 55, 56]
use either adapters like LoRA [25] or learnable embeddings
with explicit or implicit masks to realize concept selection,
which fall short in decoupling complex concepts with oc-
clusions and temporal alterations, and extracting non-object
concepts such as styles. Second, it is a common practice
to integrate different visual elements from both images and
videos in the visual content creation process [62]. How-
ever, previous works are confined to animating designated
subjects from images with motion from videos [26, 55, 56],
without further exploration of flexibly combining various
attributes (e.g., visual styles and lighting variations) from
both images and videos. Although there has been recent
effort on flexible concept composition [18] in the image do-
main, achieving universal visual concept composition for
both images and videos remains an underexplored problem.
To this end, we introduce Bind & Compose (BiCo), a
one-shot method that enables flexible visual concept com