Title: Hands-on Evaluation of Visual Transformers for Object Recognition and Detection
ArXiv ID: 2512.09579
Date: 2025-12-10
Authors: ** - Dimitrios N. Vlachogiannis (Dept. of Computer Engineering and Informatics, University of Patras, Greece) - Dimitrios A. Koutsomitropoulos (Dept. of Computer Engineering and Informatics, University of Patras, Greece) **
📝 Abstract
Convolutional Neural Networks (CNNs) for computer vision sometimes struggle with understanding images in a global context, as they mainly focus on local patterns. On the other hand, Vision Transformers (ViTs), inspired by models originally created for language processing, use self-attention mechanisms, which allow them to understand relationships across the entire image. In this paper, we compare different types of ViTs (pure, hierarchical, and hybrid) against traditional CNN models across various tasks, including object recognition, detection, and medical image classification. We conduct thorough tests on standard datasets like ImageNet for image classification and COCO for object detection. Additionally, we apply these models to medical imaging using the ChestX-ray14 dataset. We find that hybrid and hierarchical transformers, especially Swin and CvT, offer a strong balance between accuracy and computational resources. Furthermore, by experimenting with data augmentation techniques on medical images, we discover significant performance improvements, particularly with the Swin Transformer model. Overall, our results indicate that Vision Transformers are competitive and, in many cases, outperform traditional CNNs, especially in scenarios requiring the understanding of global visual contexts like medical imaging.
💡 Deep Analysis
📄 Full Content
Hands-on Evaluation of Visual Transformers for
Object Recognition and Detection
Dimitrios N. Vlachogiannis
Dept. of Computer Engineering and Informatics
University of Patras
Patras, Greece
st1067371@ceid.upatras.gr
Dimitrios A. Koutsomitropoulos
Dept. of Computer Engineering and Informatics
University of Patras
Patras, Greece
koutsomi@ceid.upatras.gr
Abstract—Convolutional Neural Networks (CNNs) for com-
puter vision sometimes struggle with understanding images in
a global context, as they mainly focus on local patterns. On
the other hand, Vision Transformers (ViTs), inspired by models
originally created for language processing, use self-attention
mechanisms, which allow them to understand relationships across
the entire image. In this paper, we compare different types of ViTs
(pure, hierarchical, and hybrid) against traditional CNN models
across various tasks, including object recognition, detection,
and medical image classification. We conduct thorough tests
on standard datasets like ImageNet for image classification and
COCO for object detection. Additionally, we apply these models
to medical imaging using the ChestX-ray14 dataset. We find that
hybrid and hierarchical transformers, especially Swin and CvT,
offer a strong balance between accuracy and computational re-
sources. Furthermore, by experimenting with data augmentation
techniques on medical images, we discover significant perfor-
mance improvements, particularly with the Swin Transformer
model. Overall, our results indicate that Vision Transformers are
competitive and, in many cases, outperform traditional CNNs,
especially in scenarios requiring the understanding of global
visual contexts like medical imaging.
Index Terms—Visual Transformers,Object Recognition, Object
Detection, Medical Imaging, Data Augmentation, Swin, ChestX-
ray14
I. INTRODUCTION
The rapid development of deep learning and artificial intel-
ligence over the last decade has transformed computer vision,
enabling machines to interpret and understand images and
videos with greater accuracy than ever before. Convolutional
Neural Networks (CNNs) have been the default approach to
visual recognition tasks for over a decade, doing both image
classification and object detection due to their ability to learn
local spatial hierarchies through convolutional operations. Ar-
chitectures such as AlexNet [1], VGGNet [2], ResNet [3] for
object recognition and Faster R-CNN [4], Yolo [5] for object
detection have established CNNs as the dominant architecture
in computer vision. However, CNNs often face limitations
related to capturing global context effectively, which is crucial
for a more in-depth insight into visual scenes and robust
performance, especially in challenging conditions [6], [24].
The Transformer model, as presented by Vaswani et al. [8],
has revolutionized the domain of natural language process-
ing (NLP) by effectively capturing long-range dependencies
through the self-attention mechanism, thus enabling models
like BERT [7] and GPT [10] to achieve state-of-the-art results.
Inspired by these successes, the Vision Transformer (ViT) [9]
was devised, adapting Transformer models to vision tasks by
framing images as sequences of image patches processed via
self-attention. Unlike CNNs, ViTs inherently capture global
image features and significantly improve their capacity to
identify spatial relationships present across the entire image.
Furthermore, the robustness and application of Vision Trans-
formers in specialized domains, notably medical imaging, have
become important topics. Transformers have demonstrated
enhanced resilience against adversarial perturbations compared
to CNNs [21], [24], [25], attributed to their global context
capabilities. Additionally, in medical imaging scenarios, ViTs
have showcased superior performance, reduced sensitivity to
hidden stratification, and improved generalization across di-
verse datasets [23], [28], [29].
Motivated by these latest developments, this paper presents
a comprehensive hands-on evaluation of various Vision Trans-
former architectures for object recognition, detection, and
medical image analysis tasks.The main contributions of this
work are the following:
• Comprehensive Comparative Evaluation: We present an
extensive experimental evaluation and comparative analy-
sis of Transformer-based architecture (pure, hierarchical,
and hybrid ViT models) against established CNN bench-
marks on both image classification (ImageNet-1K) and
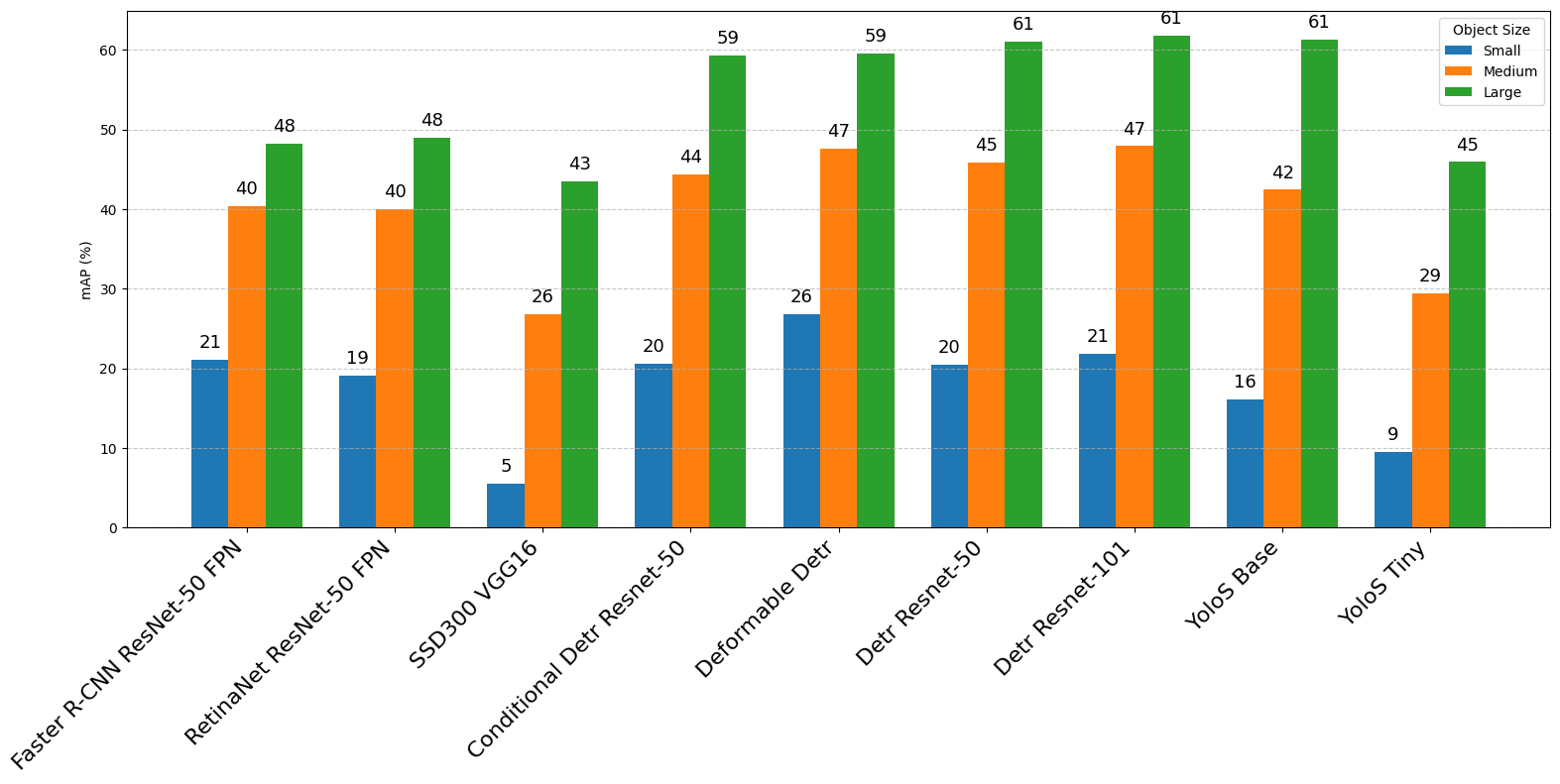
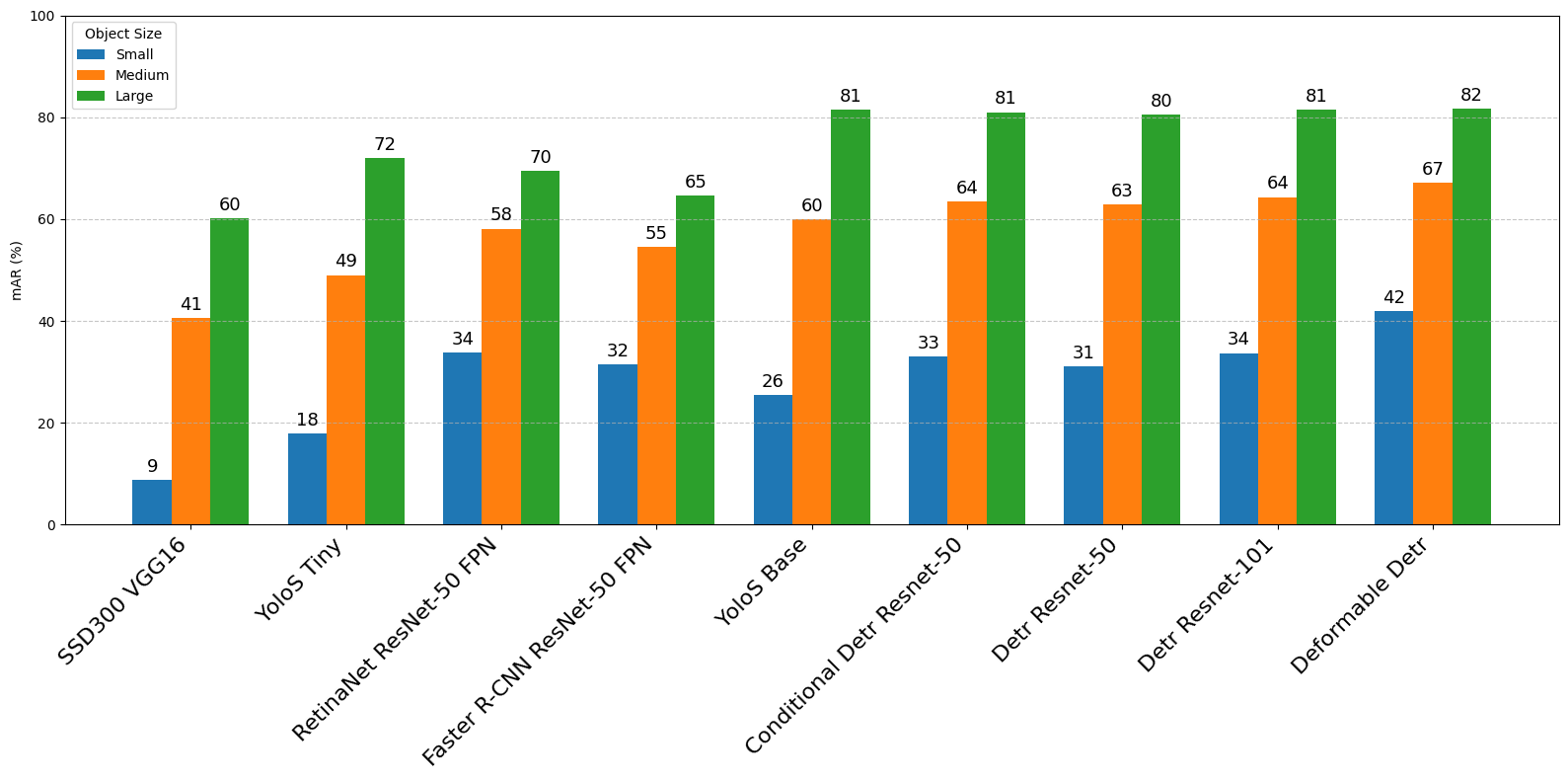
object detection (COCO) datasets.
• We extend our evaluation to medical image classification,
utilizing the ChestX-ray14 dataset. We demonstrate the
effectiveness of Vision Transformers, particularly that of
hybrid and hierarchical ViTs.
• We
investigate
specific
data
augmentation
techniques (CutMix, MixUp, Random Augmentations)
arXiv:2512.09579v1 [cs.CV] 10 Dec 2025
and observe their impact on the hierarchical model
(Swin).
Notably,
these
techniques
have
not
been
previously applied to the pure Swin model on t