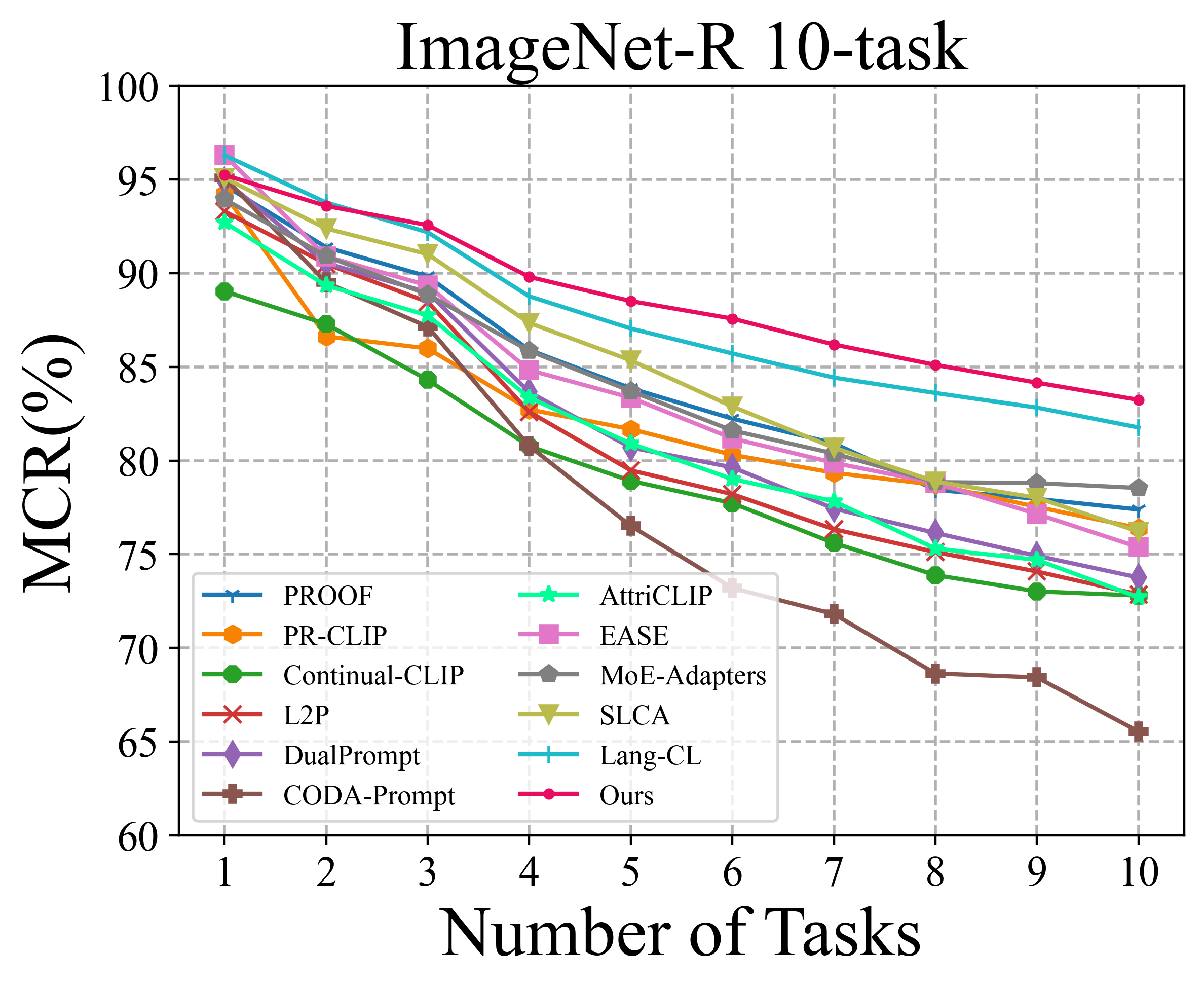
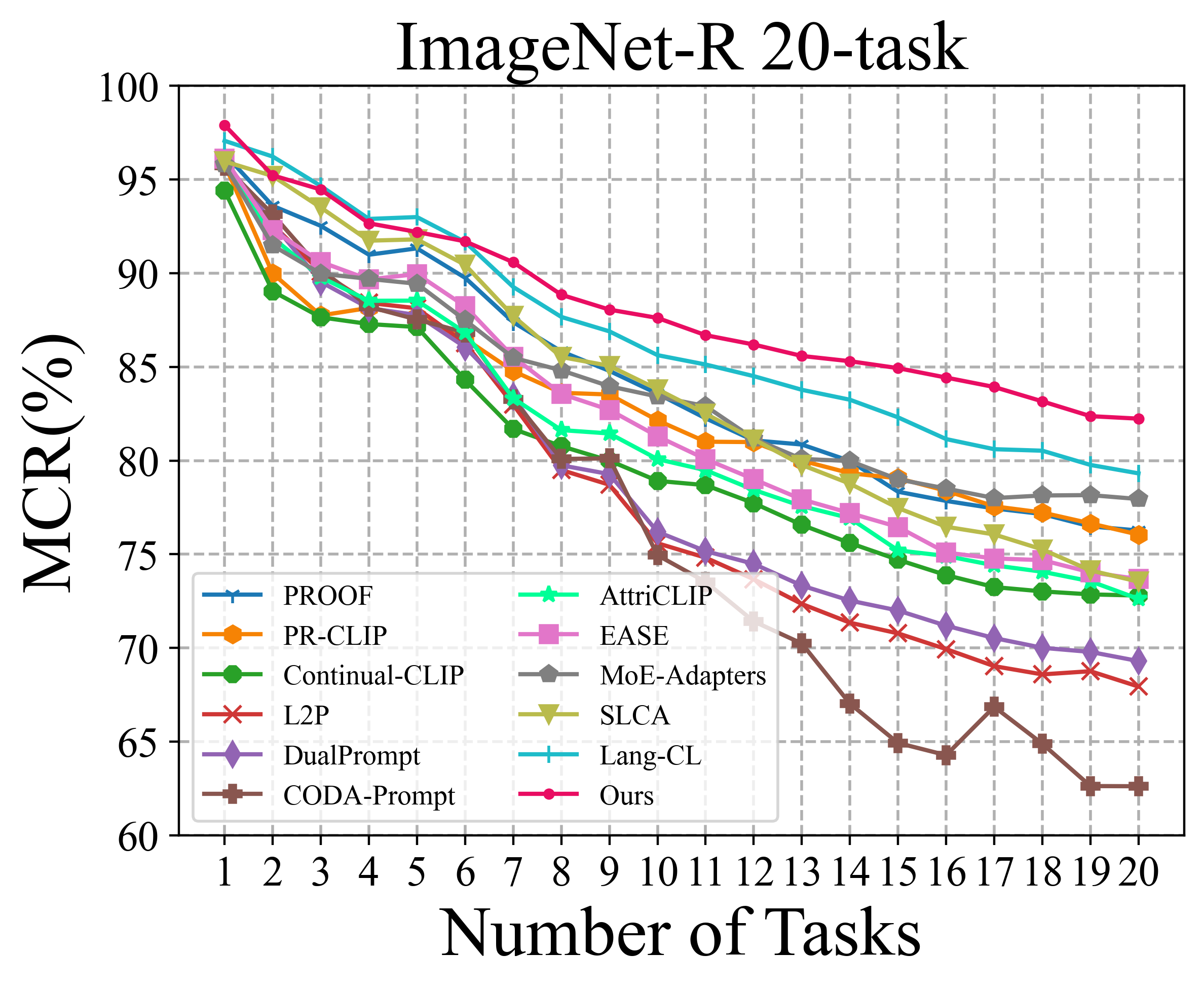
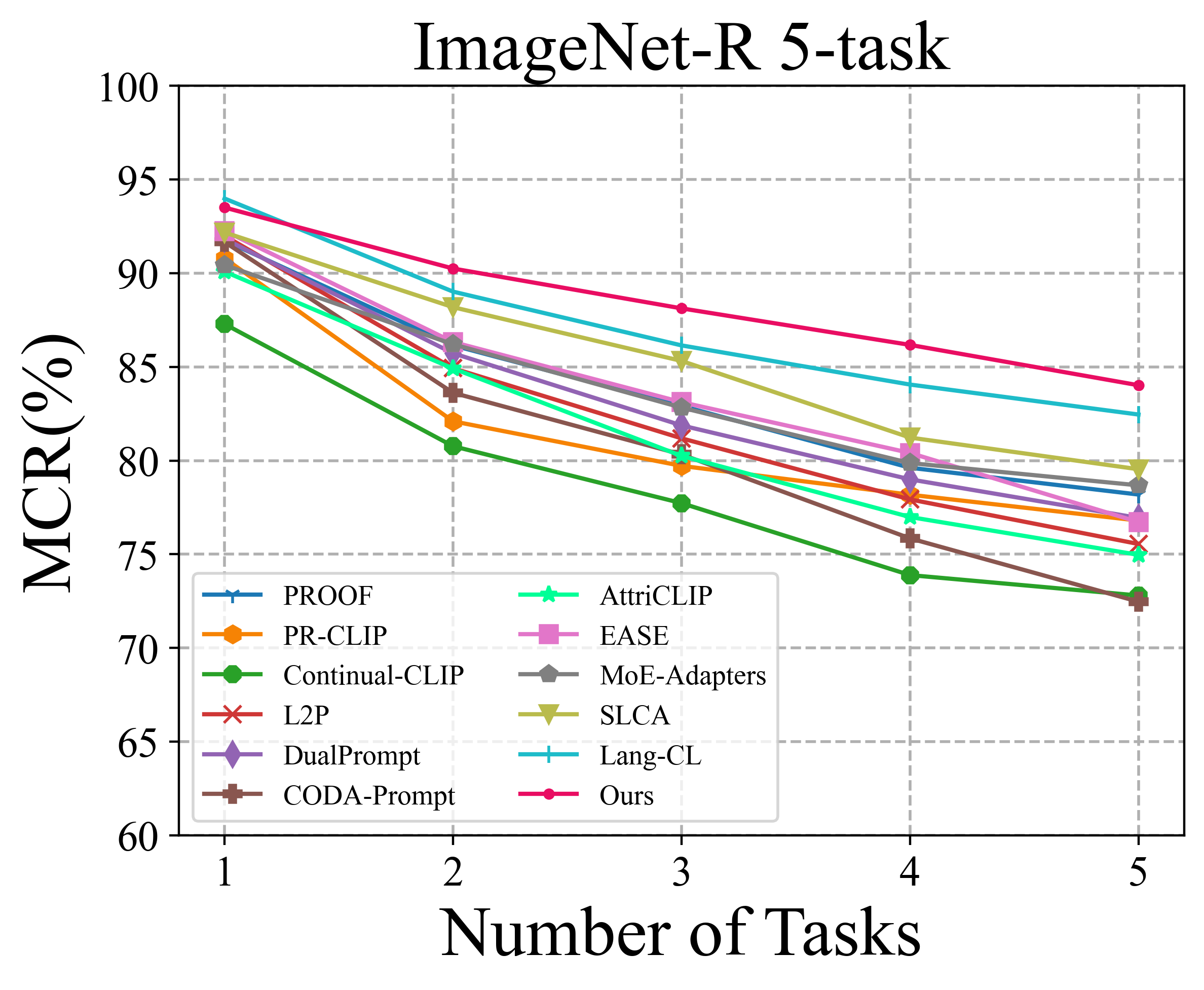
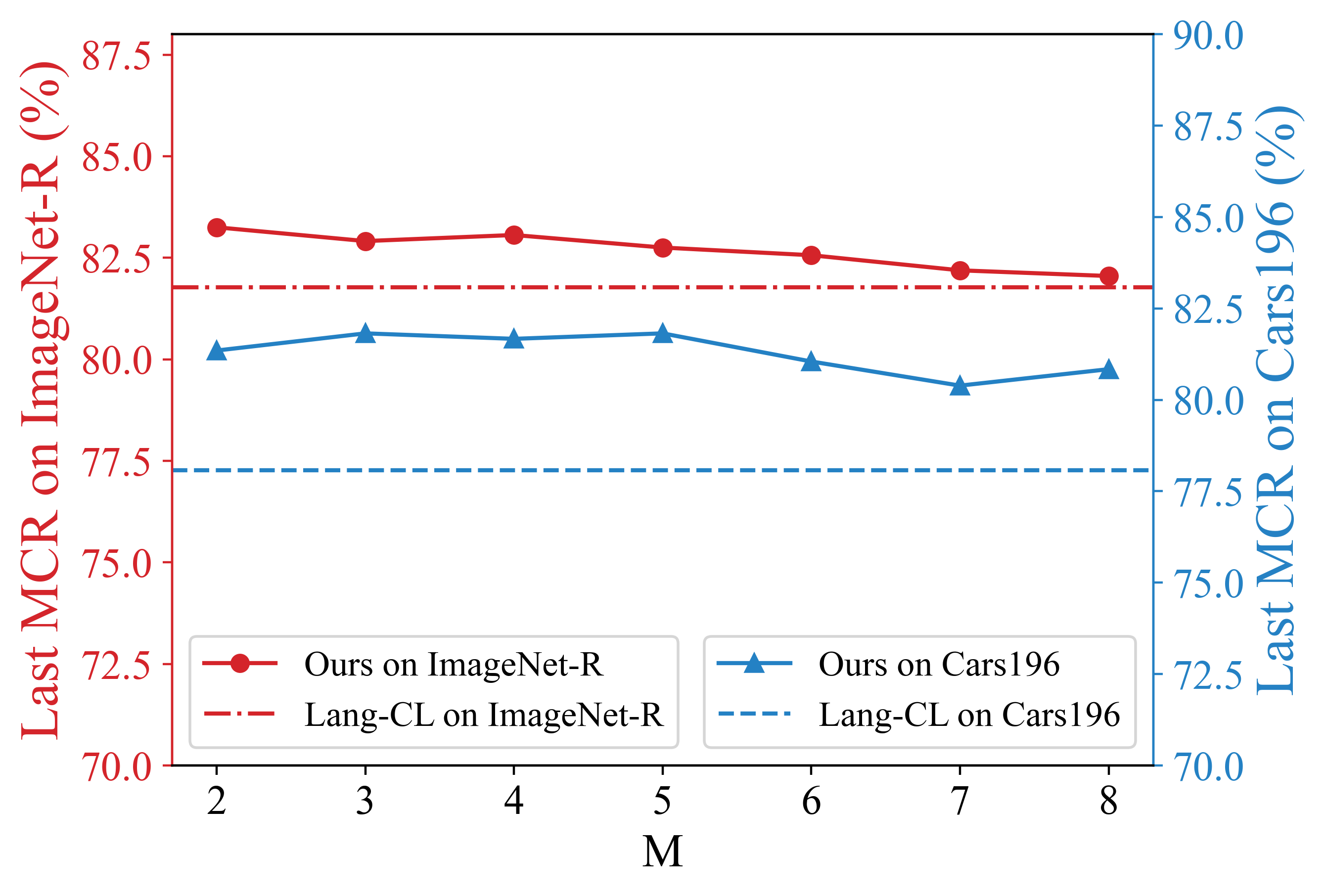
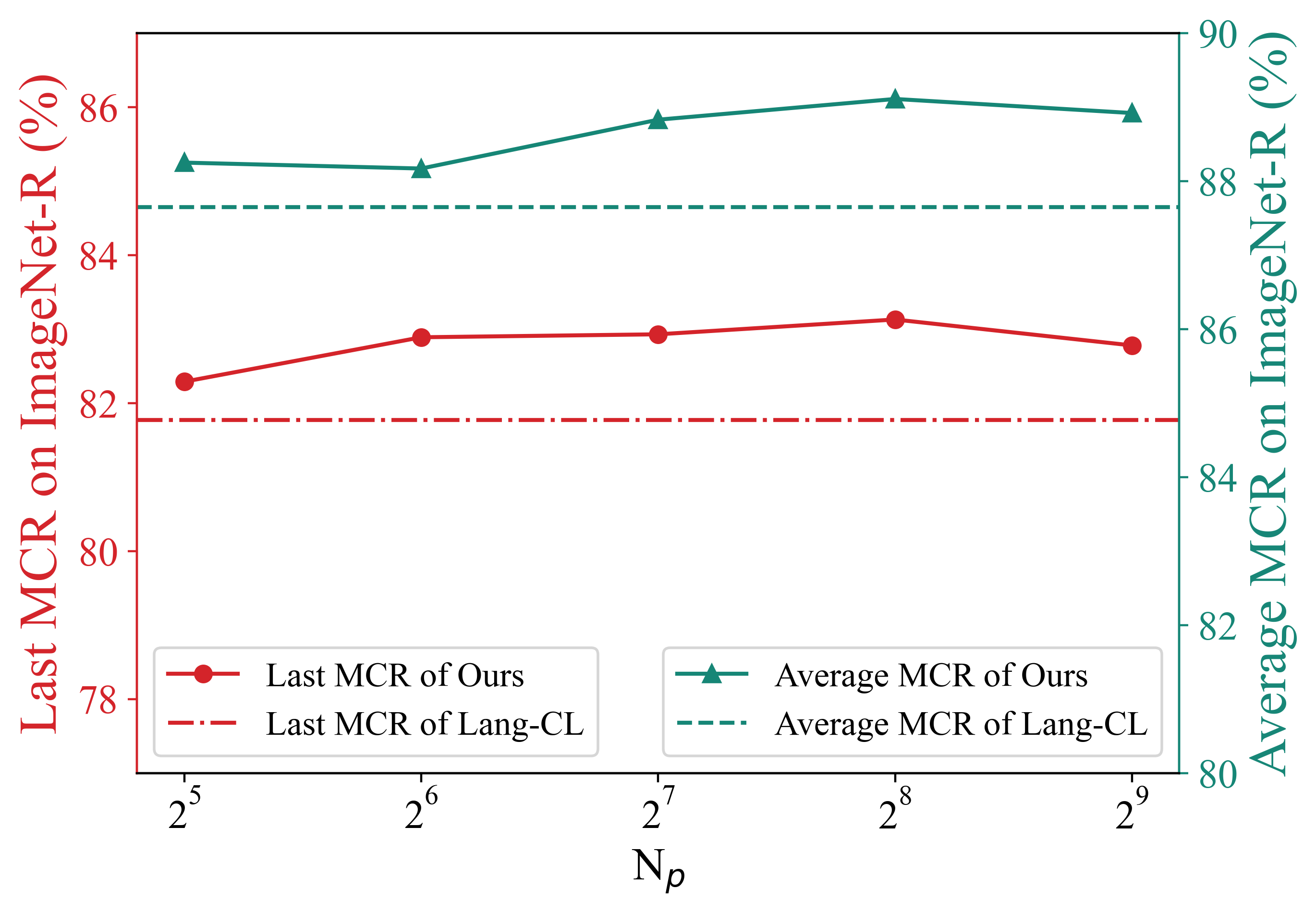
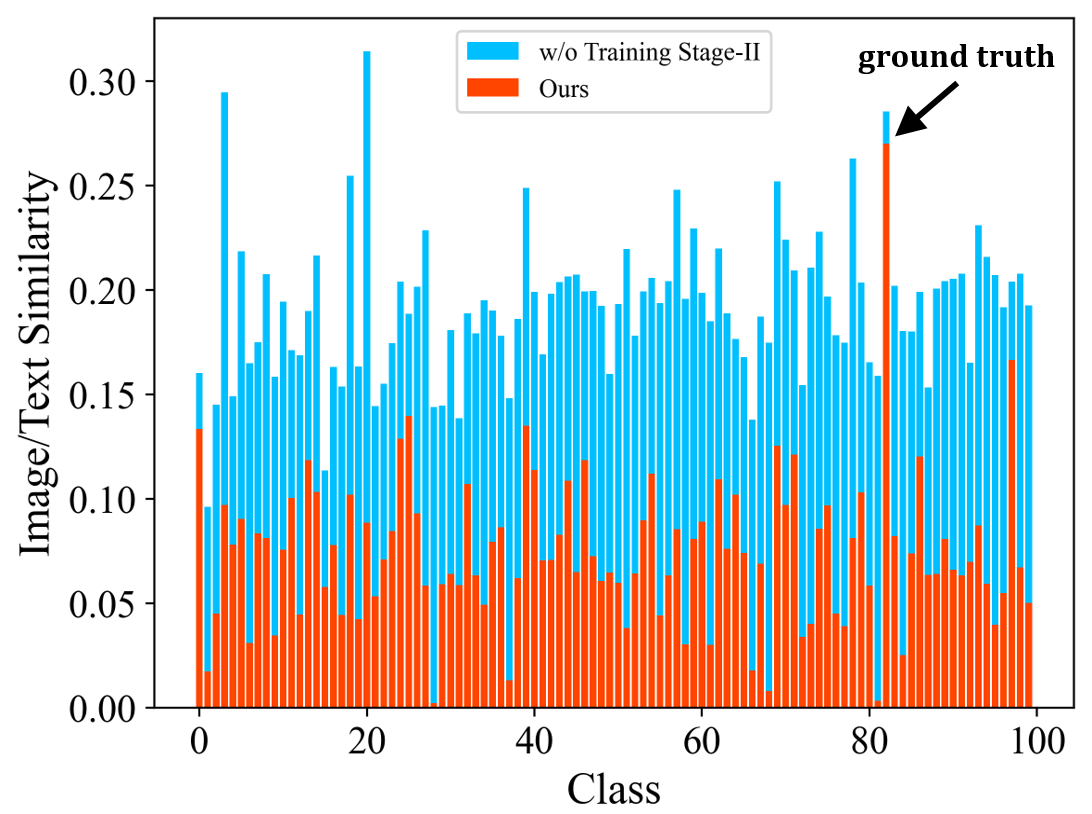
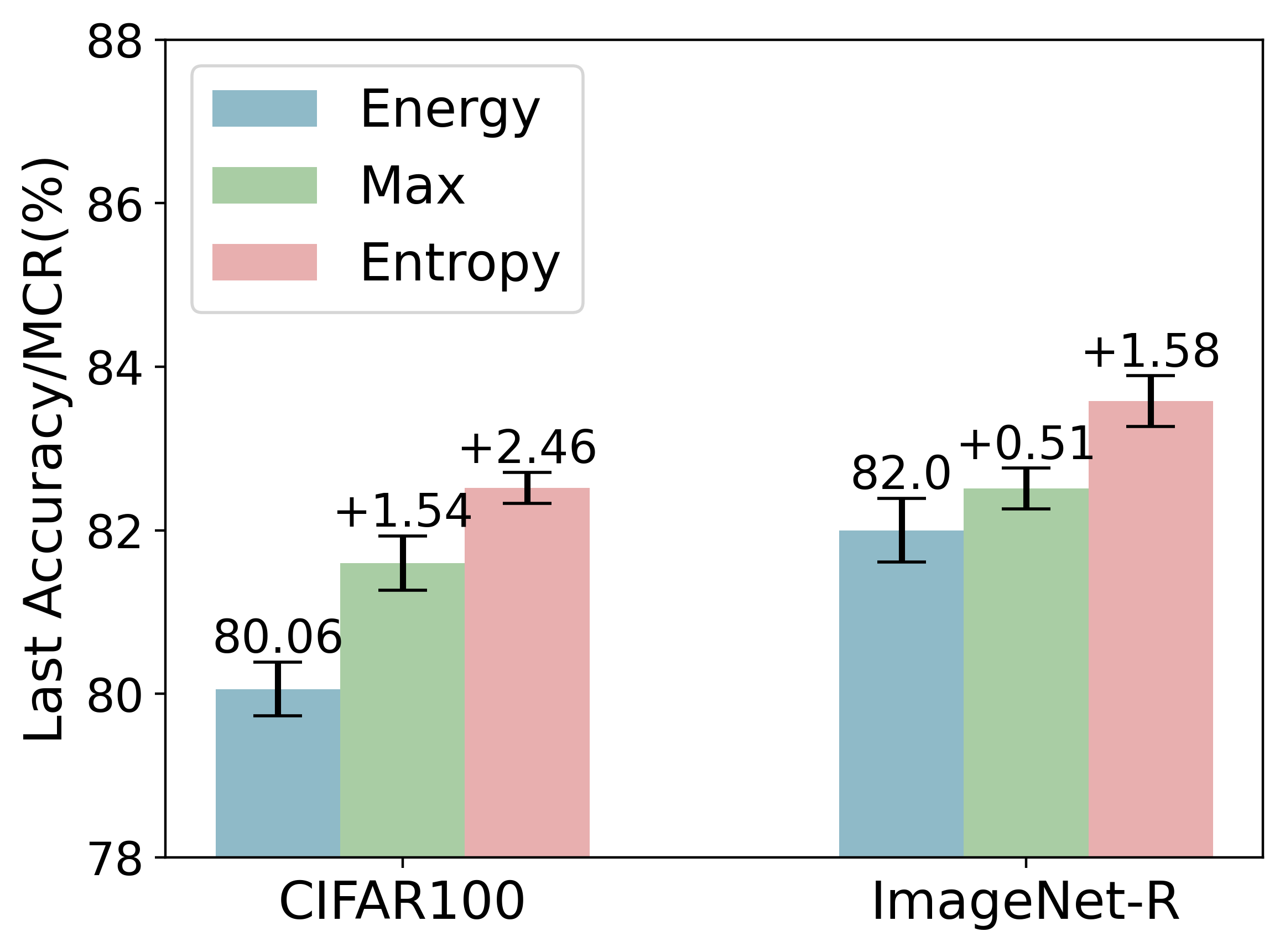
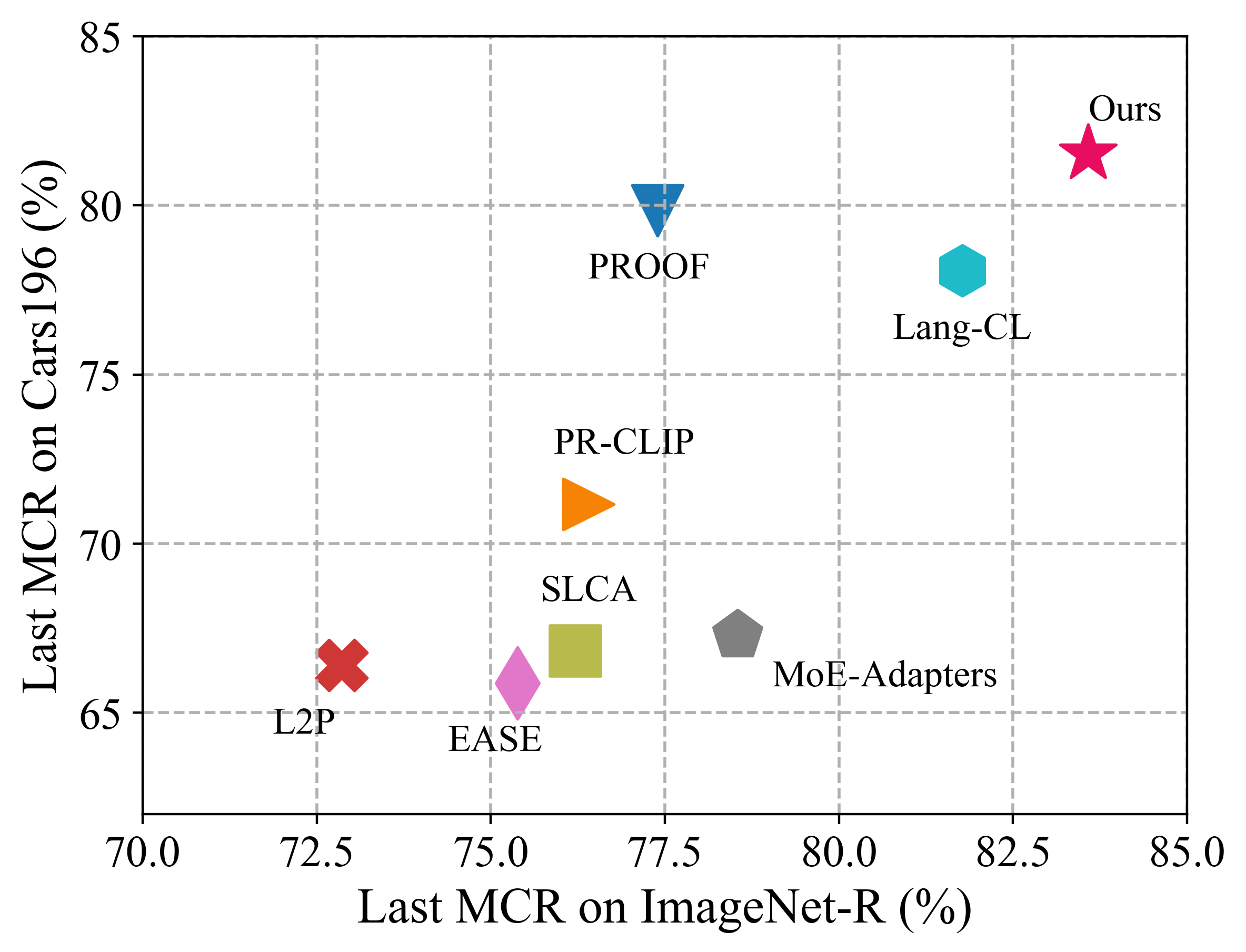
Class-incremental learning requires a learning system to continually learn knowledge of new classes and meanwhile try to preserve previously learned knowledge of old classes. As current state-of-the-art methods based on Vision-Language Models (VLMs) still suffer from the issue of differentiating classes across learning tasks. Here a novel VLM-based continual learning framework for image classification is proposed. In this framework, task-specific adapters are added to the pre-trained and frozen image encoder to learn new knowledge, and a novel cross-task representation calibration strategy based on a mixture of light-weight projectors is used to help better separate all learned classes in a unified feature space, alleviating class confusion across tasks. In addition, a novel inference strategy guided by prediction uncertainty is developed to more accurately select the most appropriate image feature for class prediction. Extensive experiments on multiple datasets under various settings demonstrate the superior performance of our method compared to existing ones.
The rapid development of deep learning has led to impressive breakthroughs in various domains [1]- [3]. However, unlike humans who can continually learn new knowledge from their experiences and adapt to new information over time, current deep learning systems typically rely on static datasets, and would catastrophically forget previously learned knowledge when they are learning new data [4].
Existing studies have been performed to empower deep learning models with the continual learning (CL) ability. Early CL studies often assume the models are initially trained from scratch and then continually updated with a sequence of CL tasks [5]. Considering the strong generalization ability of pretrained models, researchers started to build CL systems on pre-trained vision or vision-language models (VLMs) [6]. In particular, the integration of pre-trained textual information from VLM as supervision input significantly enhances the generalization capabilities of trained image features, increasing resilience to catastrophic forgetting. Several CL methods based on pre-trained VLM (e.g., CLIP [2]) have shown superior performance [7], [8]. In VLM-based CL methods, while efficient fine-tuning of VLMs with task-shared light modules has shown promising performance [9], [10], they have been outperformed by the recently proposed task-wise fine-tuning approach [8], [11], where each CL task is associated with a task-specific learnable light module. The main challenge in the task-wise fine-tuning approach is correct selection or appropriate fusion of task-specific modules or features.
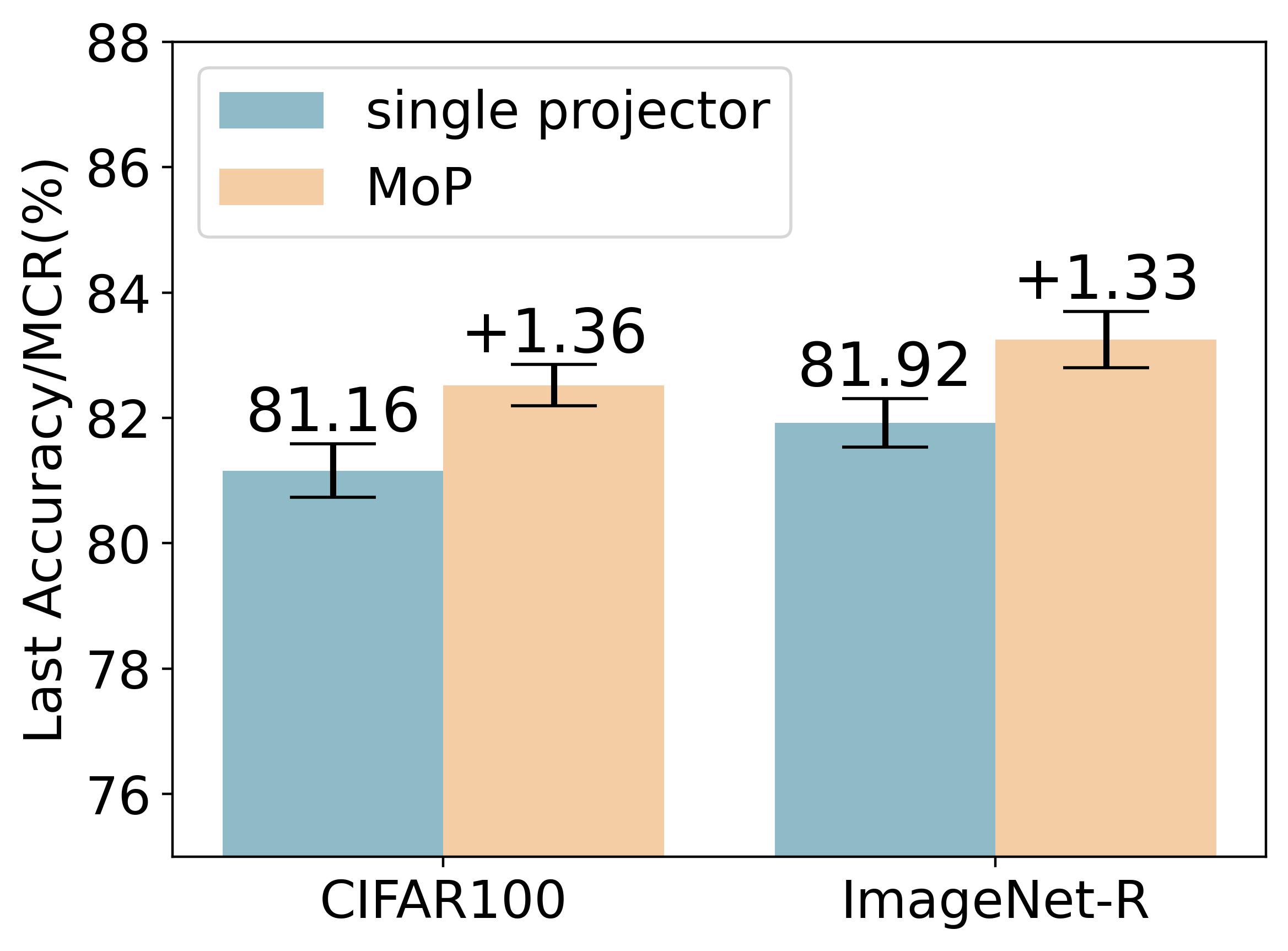
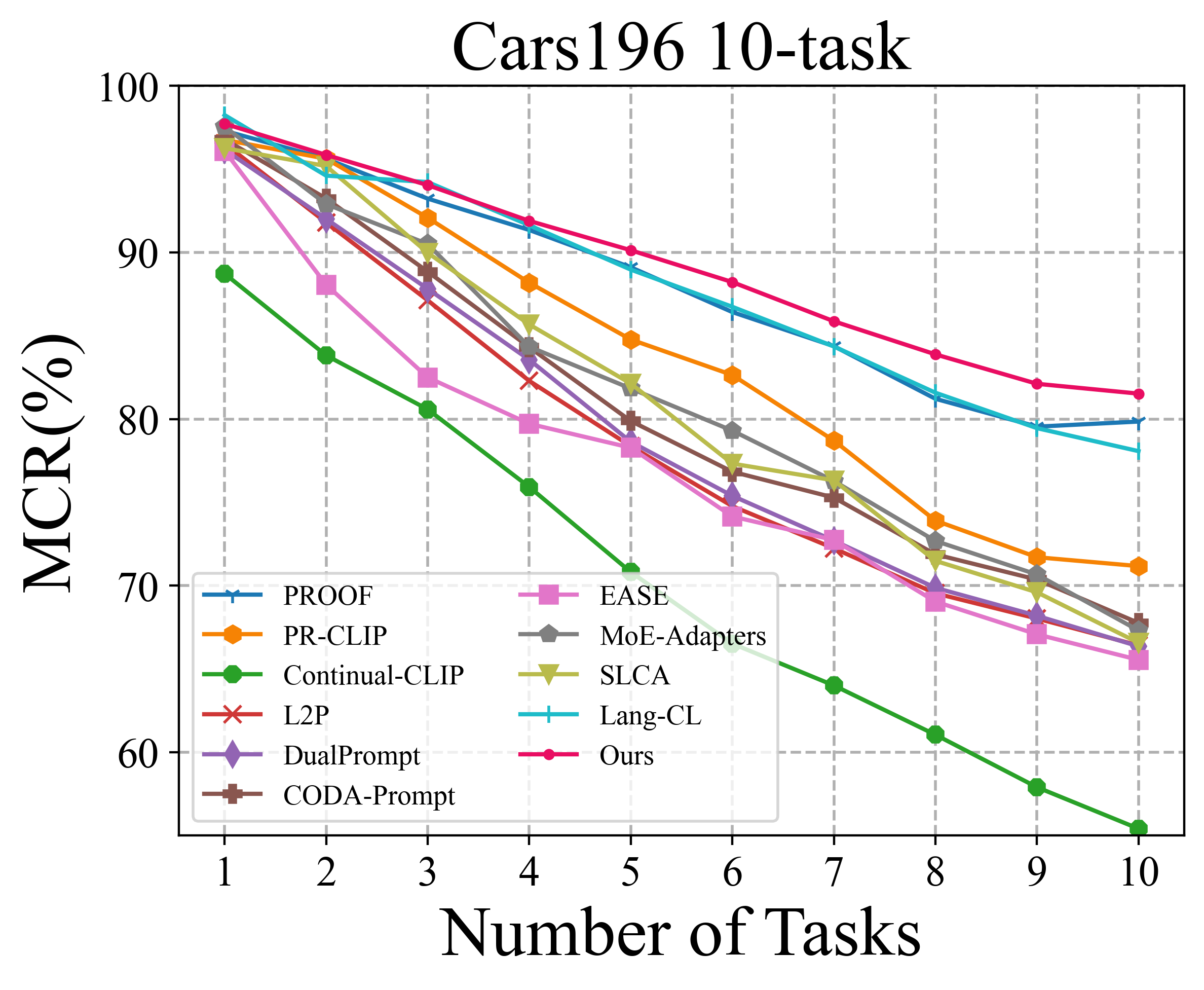
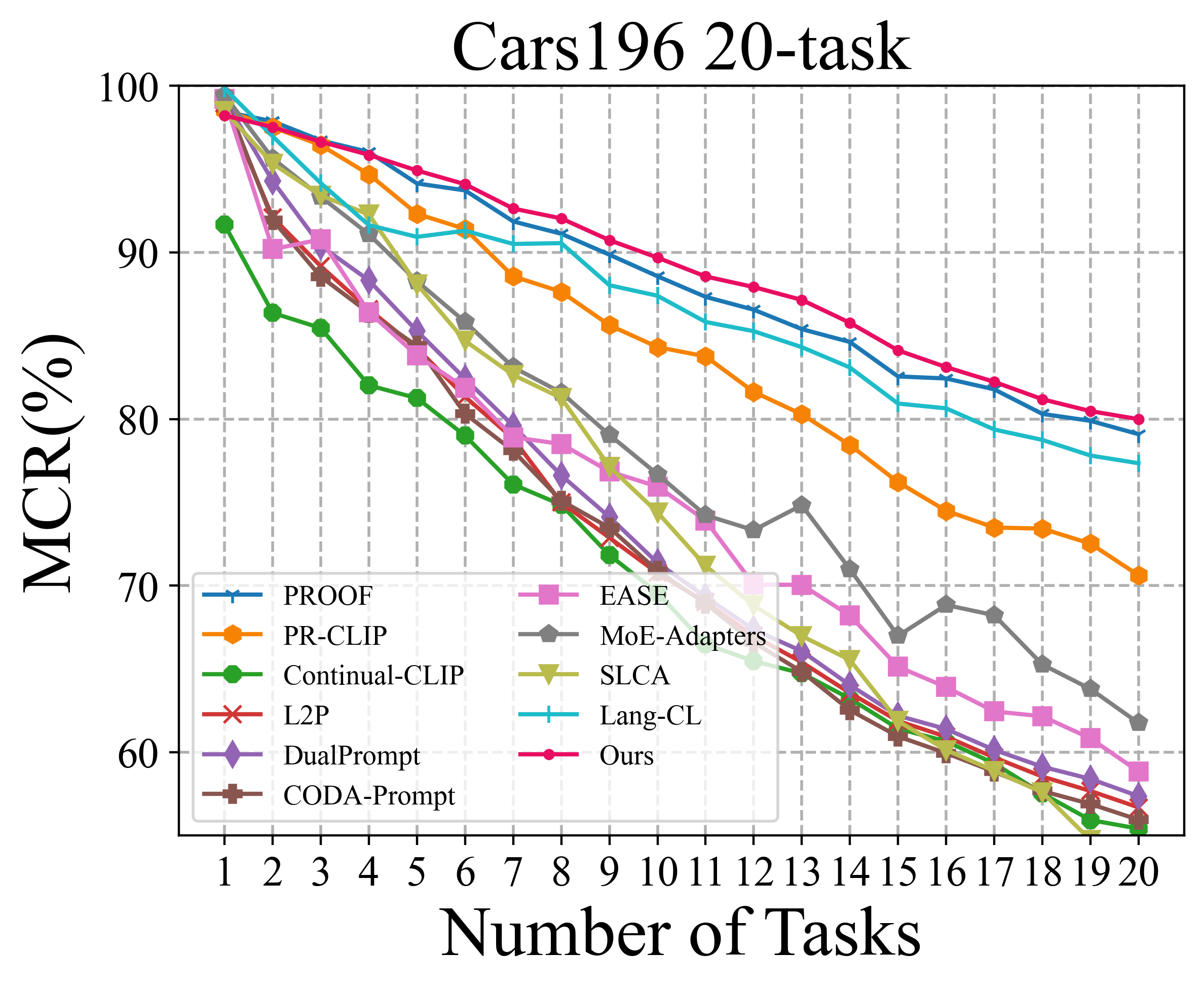
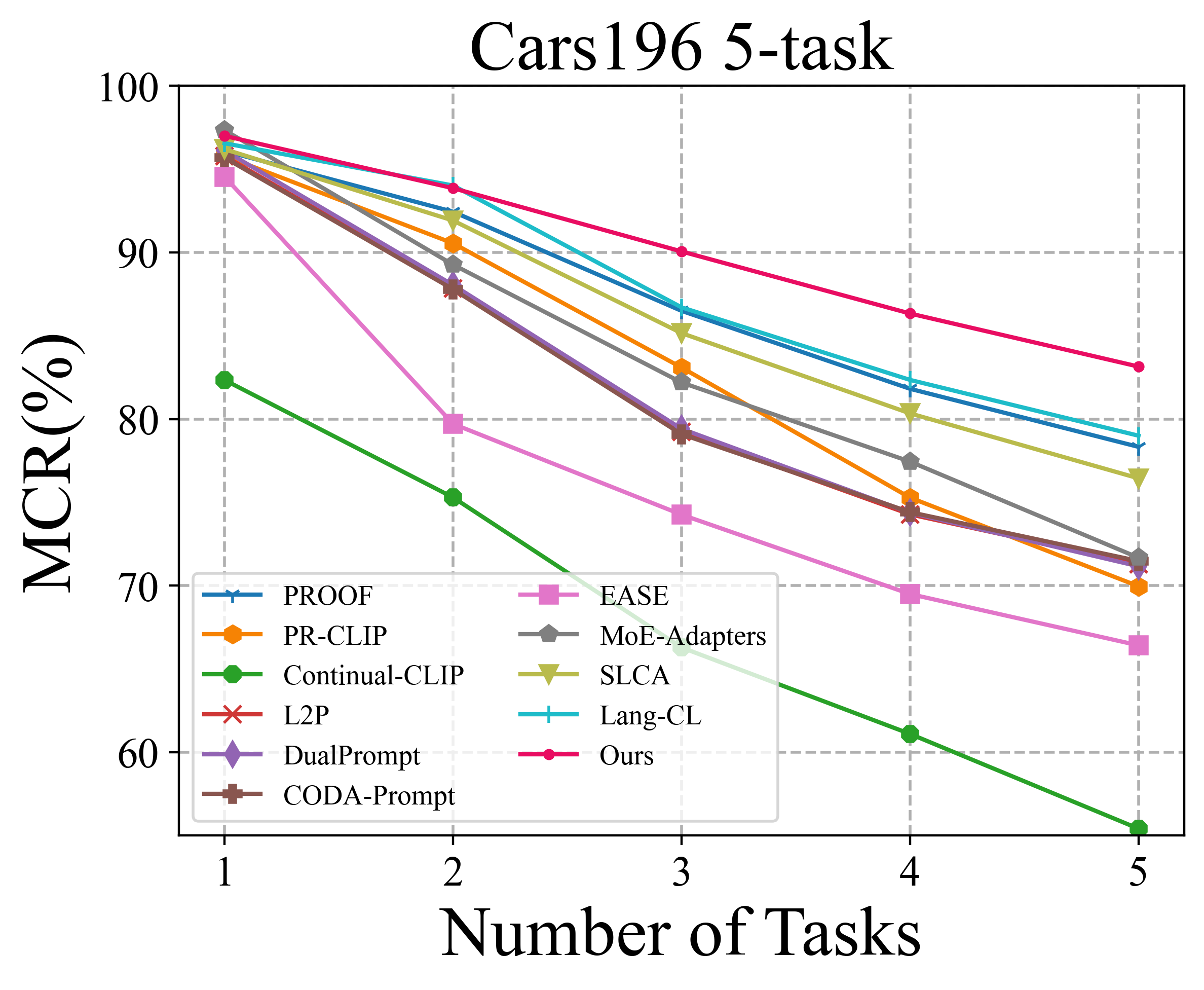
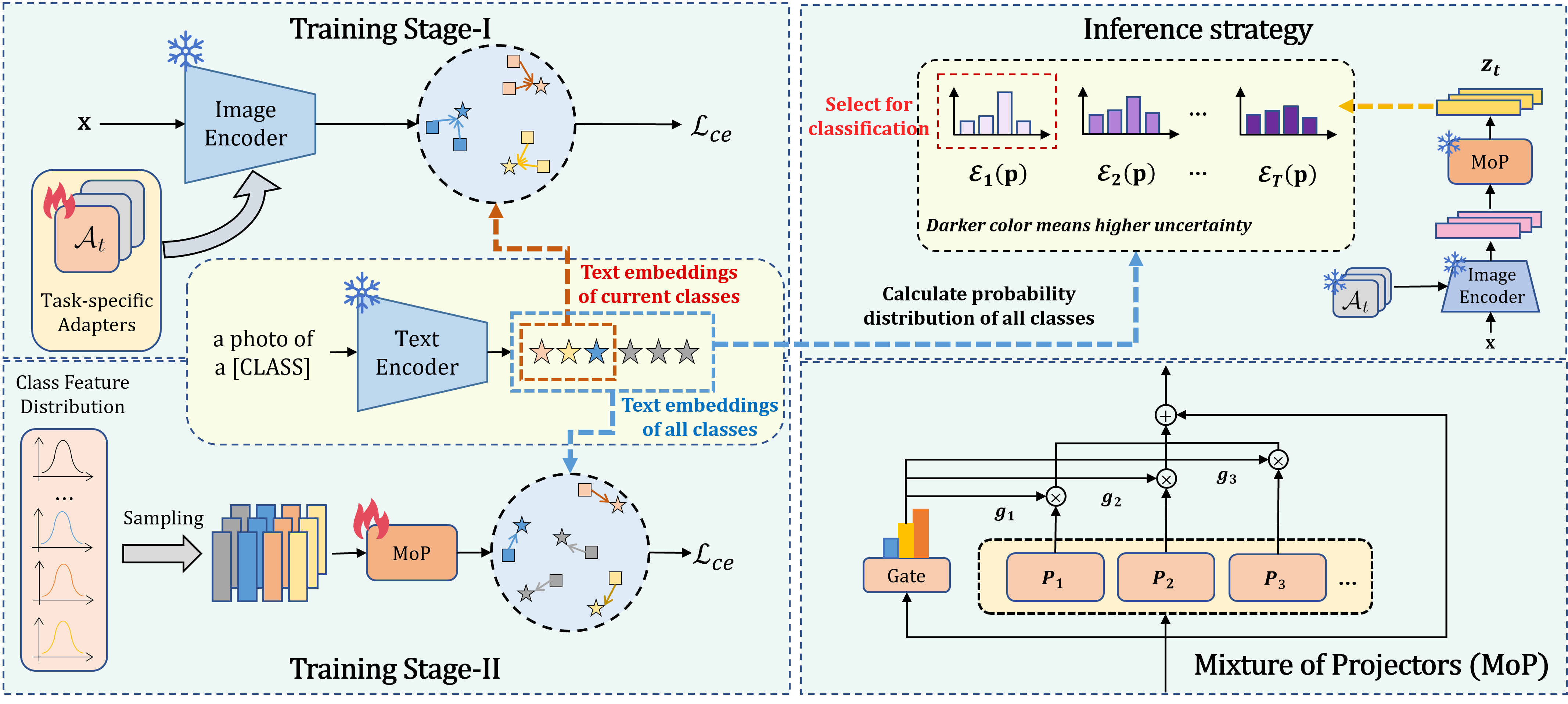
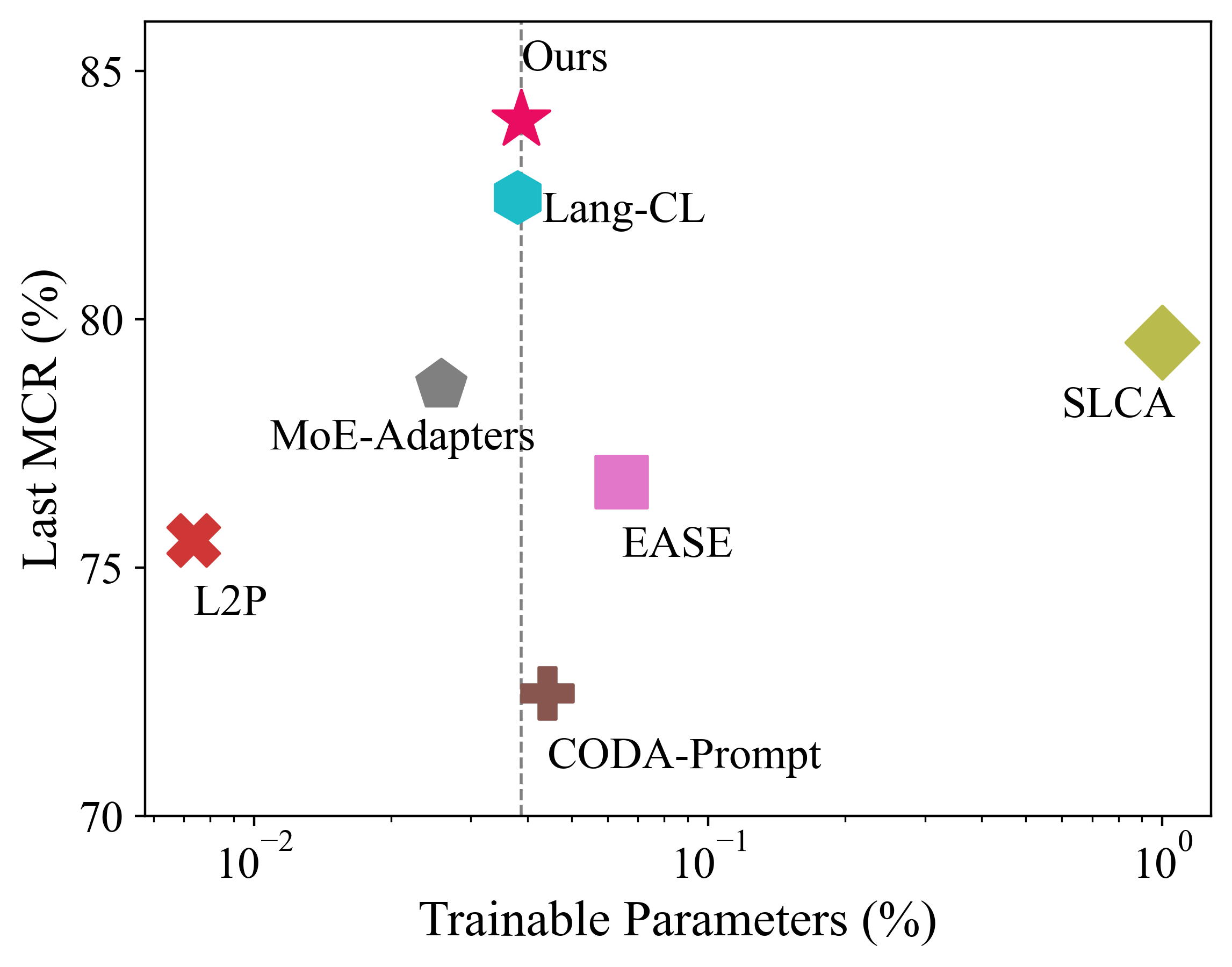
To solve the above challenge, a novel VLM-based framework for continual learning of image classes is proposed in this paper. The framework contains two novel designs. First, after learning a new task, a cross-task feature calibration strategy is introduced to help align independent task-specific feature spaces into a unified task-shared feature space, enhancing class separation across tasks. This is realized by training a novel mapping module called Mixture of Projectors (MoP) on top of the task-specific adapted VLM’s image encoder. Second, a novel prediction uncertainty-guided inference strategy is utilized to select the most appropriate calibrated feature in task-shared space. This strategy is designed based on the prediction uncertainty that, if the task-specific image feature is extracted from the adapted image encoder of the task that test image belongs to, the prediction uncertainty of its corresponding calibrated feature transformed by MoP will be lower. Extensive empirical evaluations on multiple image classification benchmarks with various imaging domains and settings consistently support that the proposed CL framework is superior to existing approaches. The main contributions of arXiv:2512.09441v1 [cs.CV] 10 Dec 2025 this study are summarized below. [18] usually maintain a memory buffer to store a small subset of old data for experience replay. Different from above approaches, structure-based approaches [8], [19], [20] usually add new modules to help learn knowledge of new classes, avoiding parameter overwriting and interference across tasks. Since this approach eliminates the need to address forgetting (stability), it primarily focuses on learning new data (plasticity) and selecting or merging parameters during inference. CIL on Vision-Language Models: Vision-Language Models (VLMs) can leverage knowledge from text modality to support CIL of image classes, and therefore recent studies have started to focus on CIL with VLMs (especially with CLIP). These studies can be broadly divided into two types. One type involves fine-tuning the pre-trained image encoder [20]- [22], usually adopting PEFT techniques. These methods still face the challenges of parameter overwriting or prompt selection. The other type involves freezing pre-trained CLIP image encoder and using outputs of the pre-trained image encoder for further learning. These methods typically enhance the image representations with trainable modules following the image encoder [7], [23]- [25]. But such frozen image features constrain learning performance on downstream CIL tasks especially when there is a large domain gap between downstream and pre-training data. This work addresses above issues by finetuning the encoder with task-specific parameters and proposes a better inference strategy.
This study focuses on class-incremental learning (CIL). In CIL, a model continually learns new knowledge from a sequence of T tasks, and each task contains a unique set of new classes. When the model is trained with the data of the tth task (t ≤ T ), it often assumes training data of all previously learned (old) classes from task 1 to task t -1 are largely or totally unavailable. Here the challenging exemplar-free setting is adopted, i.e., no data of old classes are available when the model learns new knowledge from the current t-th task.
Task-specific adapters for CIL (Training Stage-I): When the
This content is AI-processed based on open access ArXiv data.