Title: Auto-BenchmarkCard: Automated Synthesis of Benchmark Documentation
ArXiv ID: 2512.09577
Date: 2025-12-10
Authors: Aris Hofmann, Inge Vejsbjerg, Dhaval Salwala, Elizabeth M. Daly
📝 Abstract
We present Auto-BenchmarkCard, a workflow for generating validated descriptions of AI benchmarks. Benchmark documentation is often incomplete or inconsistent, making it difficult to interpret and compare benchmarks across tasks or domains. Auto-BenchmarkCard addresses this gap by combining multi-agent data extraction from heterogeneous sources (e.g., Hugging Face, Unitxt, academic papers) with LLM-driven synthesis. A validation phase evaluates factual accuracy through atomic entailment scoring using the FactReasoner tool. This workflow has the potential to promote transparency, comparability, and reusability in AI benchmark reporting, enabling researchers and practitioners to better navigate and evaluate benchmark choices.
💡 Deep Analysis
📄 Full Content
Benchmarks are vital in AI for standardizing tasks, enabling model evaluation, tracking progress, and setting baseline expectations (Reuel et al. 2024). Appropriate benchmarks systematically detect, assess, and mitigate risks (Sokol et al. 2024). Unsuitable benchmarks may risk leaving failure modes undetected, leading to deployment with unverified, poorly understood behaviors. Choosing appropriate benchmarks ensures models are evaluated on relevant tasks, avoiding inaccurate assessments and missed risks.
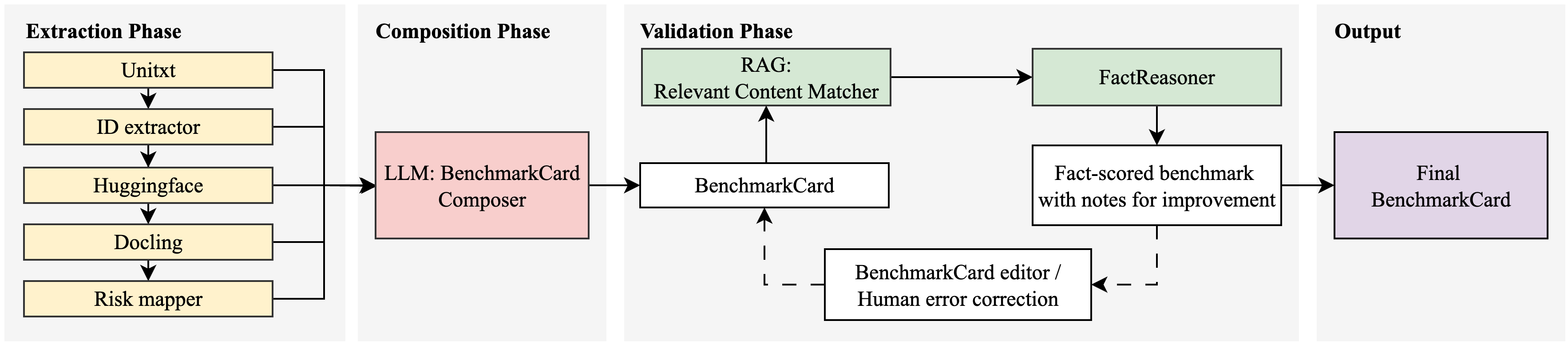
The workflow has three phases: Extraction, Composition, and Validation, illustrated in Figure 1. Access is provided via a Python CLI, and the system1 is available in open source.
Extraction Phase: This phase collects structured benchmark data from multiple sources using modular custom agent tools. The implementation currently supports Unitxt but can be adapted for other standards like lm-eval-harness. Users begin by specifying a benchmark identifier for the Unitxt Tool, built upon the Unitxt library (Bandel et al. 2024), which searches its catalog and retrieves the corresponding UnitxtCard. The retrieved card is then parsed to identify cited materials (e.g., metrics, templates) and retrieve related supplementary cards, with the result returned in JSON format. Next, the Extractor Tool extracts identifiers from the JSON such as the Hugging Face repository ID and the publication URL for subsequent processing. The Hugging Face Tool then extracts metadata from the benchmark’s repository. Finally, the Docling Tool (Livathinos et al. 2025) processes the benchmark’s associated research publication, converting it into machine-readable markdown format.
Composition Phase: The extracted data is passed to a large language model (LLM), which generates a complete BenchmarkCard by filling predefined sections such as purpose, methodology, and limitations. Once the initial card is generated, the system passes it to the Risk Atlas Nexus framework (Bagehorn et al. 2025). The risk identifier component flags potential risks based on a structured risk taxon- Validation Phase: Validation plays a critical role by introducing a structured approach to verifying the factual accuracy of the initial BenchmarkCard. To address consistency challenges, especially conflicting details, we use FactReasoner, a probabilistic framework for assessing factual consistency via natural language inference (Marinescu et al. 2025). We extend the package with custom components for atomization and context retrieval, specifically adapted to the BenchmarkCard format. The validation process begins by breaking down the BenchmarkCard into atomic statements: small, self-contained units of meaning that can each be checked for accuracy. This step is performed using an LLM with a prompt tailored to the structure and content of Bench-markCards. In contrast to generic atomization, this approach ensures that the resulting statements are not only minimal but also and explicitly designed to be fact-checkable.
To assess each statement’s validity, we reference content from the Extraction Phase. The extracted metadata can be extensive, so evaluation by comparing each atomic statement against the full knowledge base is inefficient. To