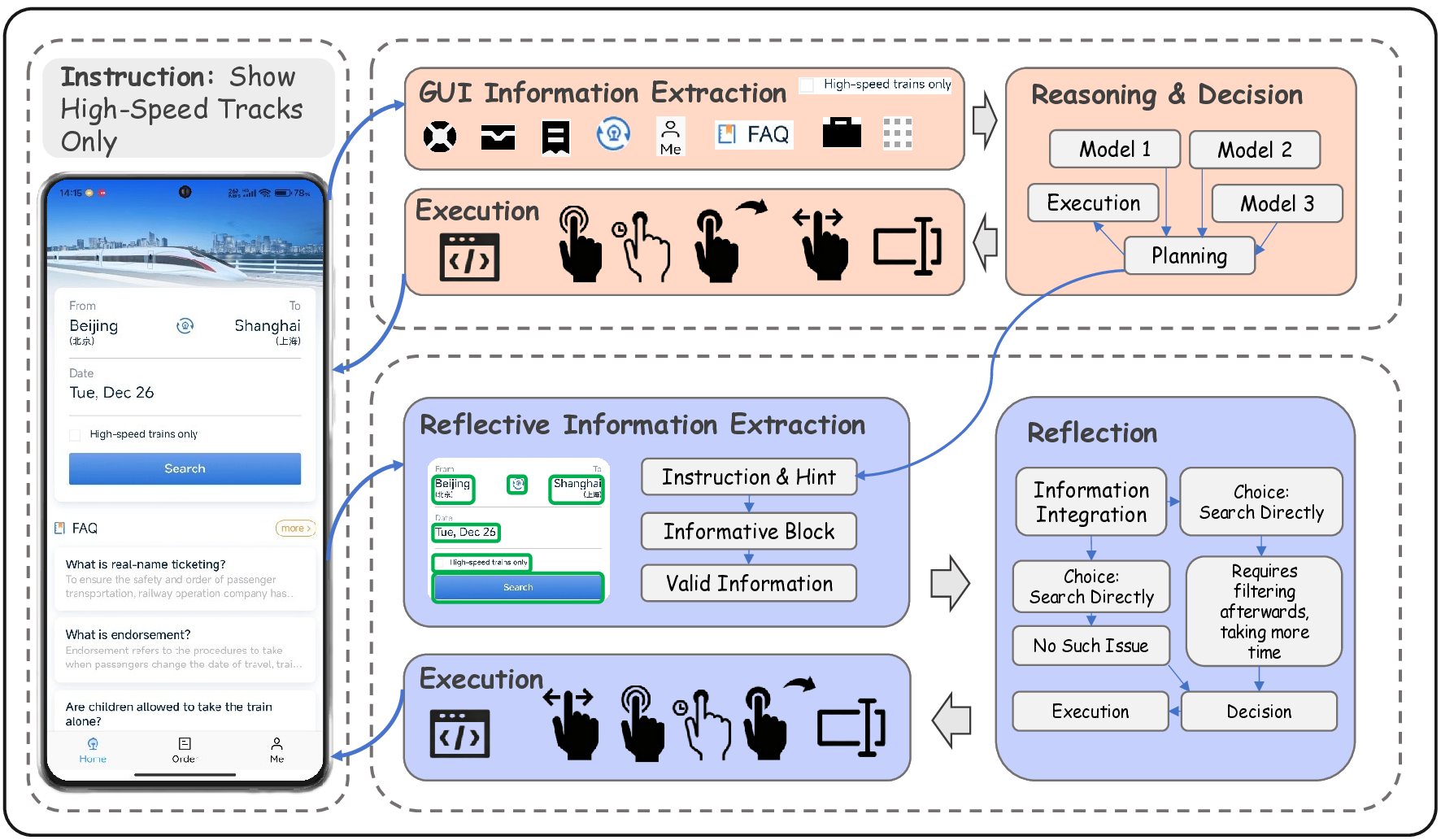
Building AI systems for GUI automation task has attracted remarkable research efforts, where MLLMs are leveraged for processing user requirements and give operations. However, GUI automation includes a wide range of tasks, from document processing to online shopping, from CAD to video editing. Diversity between particular tasks requires MLLMs for GUI automation to have heterogeneous capabilities and master multidimensional expertise, raising problems on constructing such a model. To address such challenge, we propose GAIR: GUI Automation via Information-Joint Reasoning and Group Reflection, a novel MLLM-based GUI automation agent framework designed for integrating knowledge and combining capabilities from heterogeneous models to build GUI automation agent systems with higher performance. Since different GUI-specific MLLMs are trained on different dataset and thus have different strengths, GAIR introduced a general-purpose MLLM for jointly processing the information from multiple GUI-specific models, further enhancing performance of the agent framework. The general-purpose MLLM also serves as decision maker, trying to execute a reasonable operation based on previously gathered information. When the general-purpose model thinks that there isn't sufficient information for a reasonable decision, GAIR would transit into group reflection status, where the general-purpose model would provide GUI-specific models with different instructions and hints based on their strengths and weaknesses, driving them to gather information with more significance and accuracy that can support deeper reasoning and decision. We evaluated the effectiveness and reliability of GAIR through extensive experiments on GUI benchmarks.
💡 Deep Analysis
📄 Full Content
GAIR : GUI AUTOMATION VIA INFORMATION-JOINT
REASONING AND GROUP REFLECTION
Zishu Wei1,‡, Qixiang Ma1,‡, Xavier Hu1, Yuhang Liu1, Hui Zang2, Yudong
Zhao2, Tao Wang2, Shengyu Zhang1,*, and Fei Wu1,*
1Zhejiang University
2Huawei Technologies Ltd.
ABSTRACT
Building AI systems for GUI automation task has attracted remarkable research
efforts, where MLLMs are leveraged for processing user requirements and give
operations.
However, GUI automation includes a wide range of tasks, from
document processing to online shopping, from CAD to video editing. Diver-
sity between particular tasks requires MLLMs for GUI automation to have het-
erogeneous capabilities and master multidimensional expertise, raising problems
on constructing such a model. To address such challenge, we propose GAIR :
GUI Automation via Information-Joint Reasoning and Group Reflection, a novel
MLLM-based GUI automation agent framework designed for integrating knowl-
edge and combining capabilities from heterogeneous models to build GUI au-
tomation agent systems with higher performance. Since different GUI-specific
MLLMs are trained on different dataset and thus have different strengths, GAIR
introduced a general-purpose MLLM for jointly processing the information from
multiple GUI-specific models, further enhancing performance of the agent frame-
work. The general-purpose MLLM also serves as decision maker, trying to exe-
cute a reasonable operation based on previously gathered information. When the
general-purpose model thinks that there isn’t sufficient information for a reason-
able decision, GAIR would transit into group reflection status, where the general-
purpose model would provide GUI-specific models with different instructions and
hints based on their strengths and weaknesses, driving them to gather information
with more significance and accuracy that can support deeper reasoning and de-
cision. We evaluated the effectiveness and reliability of GAIR through extensive
experiments on GUI benchmarks.
1
INTRODUCTION
GUI automation task, aiming at utilizing AI systems for automating GUI operations, would bring
further convenience for people’s daily work, thus becoming an attractive research field. With the
rapid development of Large Language Models (LLMs) and Multimodal Large Language Models
(MLLMs), the capabilities of AI models have reached the level of human intelligence, making it
possible to construct AI systems for GUI automation. Researchers have found that using MLLMs
for GUI automation task can economize computational cost (Xu et al., 2024), enhance generalization
(Liu et al., 2025b) and reduce model hallucination (Meng et al., 2024) and thus reaching better per-
formance (Kil et al., 2024). Therefore, the outstanding capabilities for processing complex semantic
information and contextual information and the architecture design that can simultaneously process
both textual and visual input have made MLLMs an appropriate choice for constructing AI systems
for GUI automation. However, GUI automation task is continually expanding, involving more and
more real-world scenarios, where applications, GUI pages and action spaces in each scenario can be
completely different, thus requiring different MLLMs to master such capabilities and achieve GUI
automation in each scenario and scope of task. For instance, general GUI automation models like
‡Equal Contribution, ∗Corresponding Author
1
arXiv:2512.09396v1 [cs.MA] 10 Dec 2025
Instruction: Show
High-Speed Tracks
Only
Resolve GUI Layout
Extract GUI Elements
12306 Homepage
Status Bar
Block functioning
searching for
particular trains,
results of which
used for booking
tickets.
Tabs
Block for
accessing
FAQ pages
Identify Significant Blocks and Elements
Decision and Operation Execution
Search
directly
Add query
condition
Searching
directly needs
filtering
afterwards,
taking more time
Click
on the
button
Instruction
corresponds with
searching, so
searching block
and elements are
significant
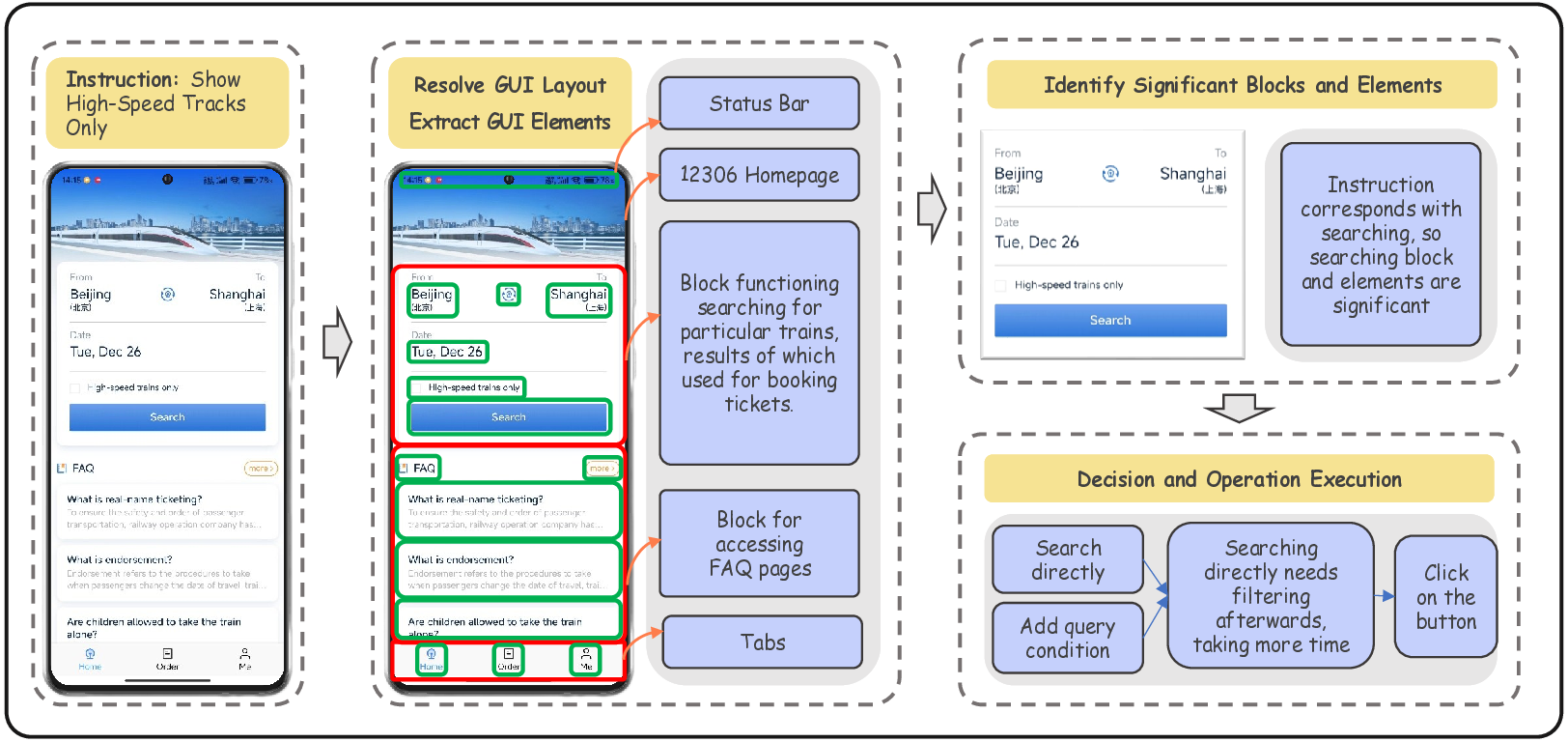
Figure 1: Demonstration of sub-tasks involved in the process of GUI automation task.
AGUVIS (Xu et al., 2024) and Ferret-UI (Li et al., 2025) does well on web and mobile applications
that are common in people’s daily life, but inefficient on various tasks in vertical fields; Assistant
systems designed for specific scenario or discipline such as CAD-Assistant (Mallis et al., 2024)
would be able to handle tasks within the designed scope but unable to process various tasks in peo-
ple’s daily life. In addition, as demonstrated in Fig. 1, the process of GUI automation tasks involves
multiple sub-tasks such as GUI page information extraction, information-processing-based decision
and precise operation generation, bringing higher complexity. Therefore, to build an efficient and
reliable agent system that is capable for most GUI automation tasks, multiple MLLMs need to be
leveraged. In this paper, we would explore the way to combine the capabilities of multiple GUI-
specific MLLMs to construct a G