Temporal-Spatial Tubelet Embedding for Cloud-Robust MSI Reconstruction using MSI-SAR Fusion: A Multi-Head Self-Attention Video Vision Transformer Approach
Reading time: 5 minute
...
📝 Original Info
Title: Temporal-Spatial Tubelet Embedding for Cloud-Robust MSI Reconstruction using MSI-SAR Fusion: A Multi-Head Self-Attention Video Vision Transformer Approach
ArXiv ID: 2512.09471
Date: 2025-12-10
Authors: Yiqun Wang, Lujun Li, Meiru Yue, Radu State
📝 Abstract
Cloud cover in multispectral imagery (MSI) significantly hinders early-season crop mapping by corrupting spectral information. Existing Vision Transformer(ViT)-based time-series reconstruction methods, like SMTS-ViT, often employ coarse temporal embeddings that aggregate entire sequences, causing substantial information loss and reducing reconstruction accuracy. To address these limitations, a Video Vision Transformer (ViViT)-based framework with temporal-spatial fusion embedding for MSI reconstruction in cloud-covered regions is proposed in this study. Non-overlapping tubelets are extracted via 3D convolution with constrained temporal span $(t=2)$, ensuring local temporal coherence while reducing cross-day information degradation. Both MSI-only and SAR-MSI fusion scenarios are considered during the experiments. Comprehensive experiments on 2020 Traill County data demonstrate notable performance improvements: MTS-ViViT achieves a 2.23\% reduction in MSE compared to the MTS-ViT baseline, while SMTS-ViViT achieves a 10.33\% improvement with SAR integration over the SMTS-ViT baseline. The proposed framework effectively enhances spectral reconstruction quality for robust agricultural monitoring.
💡 Deep Analysis
📄 Full Content
Temporal-Spatial Tubelet Embedding for Cloud-Robust MSI Reconstruction using MSI-SAR
Fusion: A Multi-Head Self-Attention Video Vision Transformer Approach
Yiqun WANG1, Lujun LI1, Meiru YUE1, Radu STATE1
1 University of Luxembourg, 1359 Kirchberg, Luxembourg
- (yiqun.wang, lujun.li, meiru.yue, radu.state)@uni.lu
Keywords: Cloud Removal, Video Vision Transformer, Temporal-Spatial Embedding, Time-series Image Reconstruction, MSI
Images, SAR Images.
Abstract
Cloud cover in multispectral imagery (MSI) significantly hinders early-season crop mapping by corrupting spectral information.
Existing Vision Transformer(ViT)-based time-series reconstruction methods, like SMTS-ViT, often employ coarse temporal embed-
dings that aggregate entire sequences, causing substantial information loss and reducing reconstruction accuracy. To address these
limitations, a Video Vision Transformer (ViViT)-based framework with temporal-spatial fusion embedding for MSI reconstruction
in cloud-covered regions is proposed in this study. Non-overlapping tubelets are extracted via 3D convolution with constrained
temporal span (t = 2), ensuring local temporal coherence while reducing cross-day information degradation. Both MSI-only and
SAR-MSI fusion scenarios are considered during the experiments. Comprehensive experiments on 2020 Traill County data demon-
strate notable performance improvements: MTS-ViViT achieves a 2.23% reduction in MSE compared to the MTS-ViT baseline,
while SMTS-ViViT achieves a 10.33% improvement with SAR integration over the SMTS-ViT baseline. The proposed framework
effectively enhances spectral reconstruction quality for robust agricultural monitoring.
1.
Introduction
Accurate early-season crop mapping is essential for agricultural
monitoring, food security assessment, and sustainable resource
management (Qader et al., 2021). Timely identification of crop
types and phenological stages enables precision farming, op-
timized resource allocation, and early detection of crop stress
conditions (Wang et al., 2023, Wang et al., 2024b, Wang et al.,
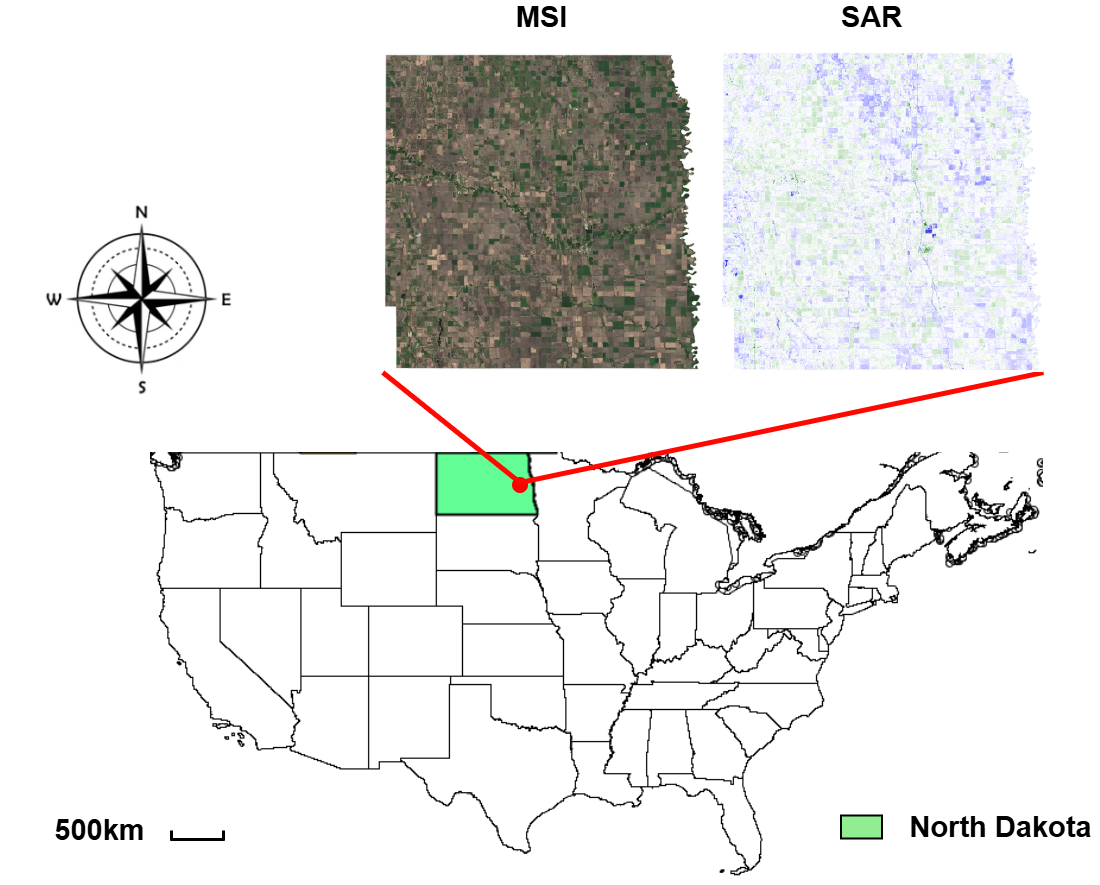
2024a). Multispectral imagery (MSI) from satellites such as
Sentinel-2 (Main-Knorn et al., 2017) provides rich spectral in-
formation spanning visible to shortwave infrared wavelengths,
enabling precise crop classification and continuous phenolo-
gical monitoring. However, MSI observations are inherently
vulnerable to cloud cover, which frequently obscures critical
observations during the early growing season. Cloud-induced
data gaps severely limit the ability to capture temporal crop
dynamics and make informed agricultural decisions, a prob-
lem particularly acute during early growth stages when phen-
ological changes are most indicative of crop variety and health
status.
Synthetic aperture radar (SAR) data from sensors such as Sentinel-
1 (Torres et al., 2012) provides a complementary solution, as
microwave signals penetrate cloud cover and deliver consistent
all-weather, day-and-night observations. However, SAR funda-
mentally lacks the spectral richness and spatial detail of MSI,
rendering it insufficient for precise discrimination between crop
types at the spatial and spectral granularity required for oper-
ational agricultural applications.
Existing approaches to ad-
dress cloud cover rely on simplistic techniques such as linear
temporal interpolation (Xia et al., 2012, Wang et al., 2024b,
Wang et al., 2024a), closest spectral fit (Eckardt et al., 2013),
or single-timeframe MSI-SAR fusion (Scarpa et al., 2018, Li et
al., 2019, Jing et al., 2023, Wang et al., 2024c, Tu et al., 2025),
which fail to capture the complex temporal-spectral patterns ne-
cessary for accurate reconstruction under severe and prolonged
cloud cover. A recent advanced multi-head self-attention Vis-
ion Transformer(ViT)-based model called SMTS-ViT (Li et al.,
2025) for time-series MSI reconstruction leverages integrated
MSI-SAR fusion to achieve superior results compared to single-
time frameworks. However, it employs temporal embeddings
that aggregate information uniformly across the entire sequence,
which can lead to significant information loss due to temporal
aliasing and ultimately degrade reconstruction quality.
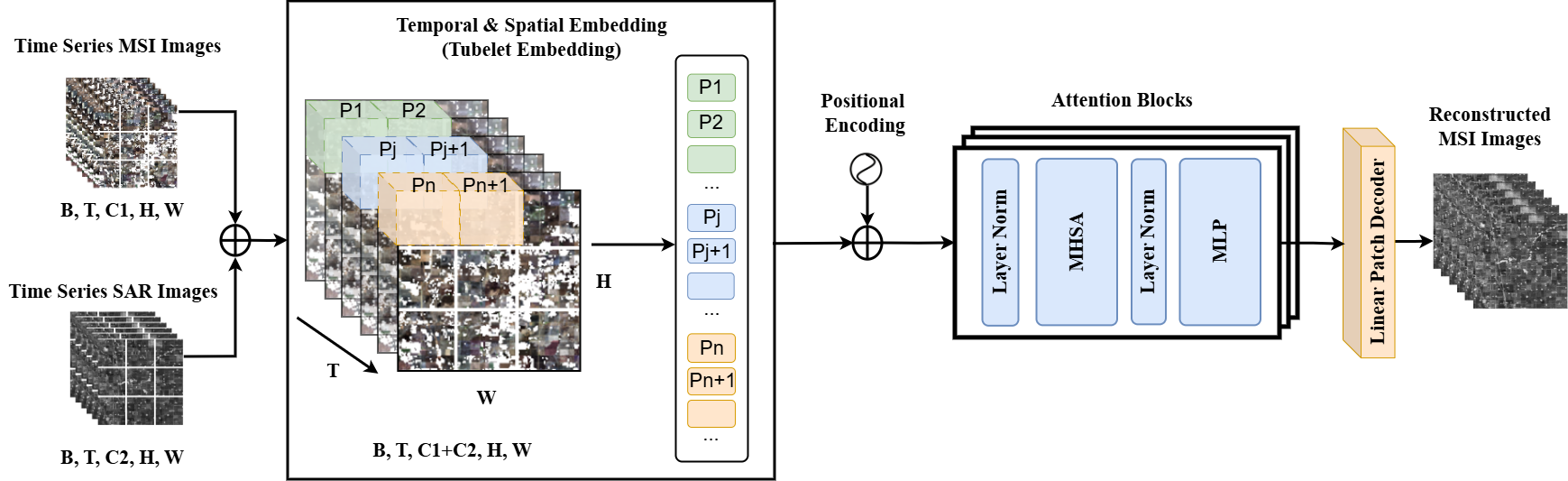
In this paper, a Video Vision Transformer (Arnab et al., 2021)
(ViViT)-based framework is proposed, which introduces temporal-
spatial fusion embedding via 3D convolutional tubelet projec-
tion with constrained temporal span, rather than aggregating in-
formation uniformly across the entire time series. This thereby
preserves local temporal coherence and reduces information loss
from excessive temporal aggregation. Theoretically, the ori-
ginal convolutional patch projection from (Li et al., 2025) can
be understood as a degenerate case of our time-spatial fusion
embedding where temporal span equals the full sequence length.
By limiting the temporal span, our approach reduces cross-day
information degradation and more effectively captures transi-
ent spectral patterns essential for accurate