Zero-Touch Networks (ZTNs) represent a transformative paradigm toward fully automated and intelligent network management, providing the scalability and adaptability required for the complexity of sixth-generation (6G) networks. However, the distributed architecture, high openness, and deep heterogeneity of 6G networks expand the attack surface and pose unprecedented security challenges. To address this, security automation aims to enable intelligent security management across dynamic and complex environments, serving as a key capability for securing 6G ZTNs. Despite its promise, implementing security automation in 6G ZTNs presents two primary challenges: 1) automating the lifecycle from security strategy generation to validation and update under real-world, parallel, and adversarial conditions, and 2) adapting security strategies to evolving threats and dynamic environments. This motivates us to propose SecLoop and SA-GRPO. SecLoop constitutes the first fully automated framework that integrates large language models (LLMs) across the entire lifecycle of security strategy generation, orchestration, response, and feedback, enabling intelligent and adaptive defenses in dynamic network environments, thus tackling the first challenge. Furthermore, we propose SA-GRPO, a novel security-aware group relative policy optimization algorithm that iteratively refines security strategies by contrasting group feedback collected from parallel SecLoop executions, thereby addressing the second challenge. Extensive real-world experiments on five benchmarks, including 11 MITRE ATT&CK processes and over 20 types of attacks, demonstrate the superiority of the proposed SecLoop and SA-GRPO. We will release our platform to the community, facilitating the advancement of security automation towards next generation communications.
W ITH the commercialization of 5G, research efforts have rapidly shifted toward the exploration of 6G networks. According to the 6G vision recommendation [1] released by the ITU-R, security has been identified as one of the fundamental design principles of 6G networks, while the deep integration of artificial intelligence (AI) and communication [2]- [4] is considered among the six representative usage scenarios. Zero-touch networks [5]- [7] have emerged as a key solution for achieving fully automated network operations, offering essential capabilities such as self-configuration, self-monitoring, self-healing, and self-optimization. ZTNs are expected to play a pivotal role in 6G networks by addressing the growing demand for virtualized network functions [8] and aligning with the trend toward software-defined and automated architectures [9]. The primary objective of ZTNs is to execute various network management and control tasks autonomously, without the need for human intervention.
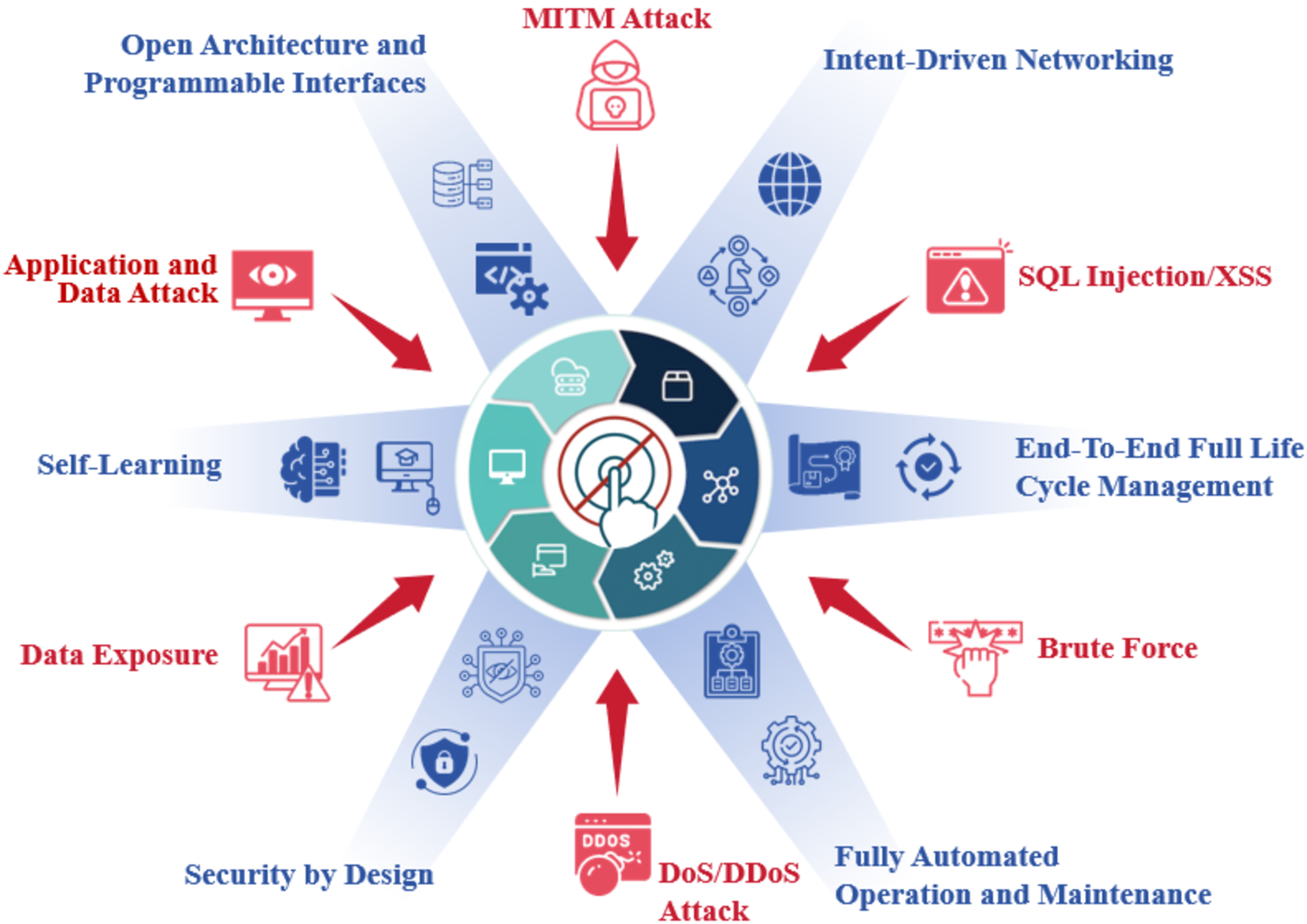
6G ZTNs, as illustrated in Figure 1, expand the attack surface due to the open architectures, distributed networks, and heterogeneous environments, thereby increasing the complexity of threat detection and mitigation [10], [11]. For instance, adversaries may launch distributed denial-of-service (DDoS) attacks to disrupt communication services, or SQL 1) Learnable: The system should possess the ability to continuously learn from diverse and evolving network conditions.
Adaptive: To ensure resilience in rapidly changing environments, the system must dynamically respond to diverse threat intelligence and adjust defensive strategies accordingly.
Practical: Generated strategies should be practical and tightly aligned with the execution capabilities of the underlying defense infrastructure. 4) Automatic: The system must support full automation across the security lifecycle, from threat simulation to strategy execution and feedback refinement, eliminating the need for manual intervention. 5) Efficient: To accelerate learning and improve responsiveness, the system should support parallel execution of candidate strategies in realistic environments, enabling fast validation and feedback cycles. 6) Pluggable: Given the heterogeneity of network infrastructures and evolving security tools, the system should maintain a modular architecture, allowing flexible integration and replacement of components.
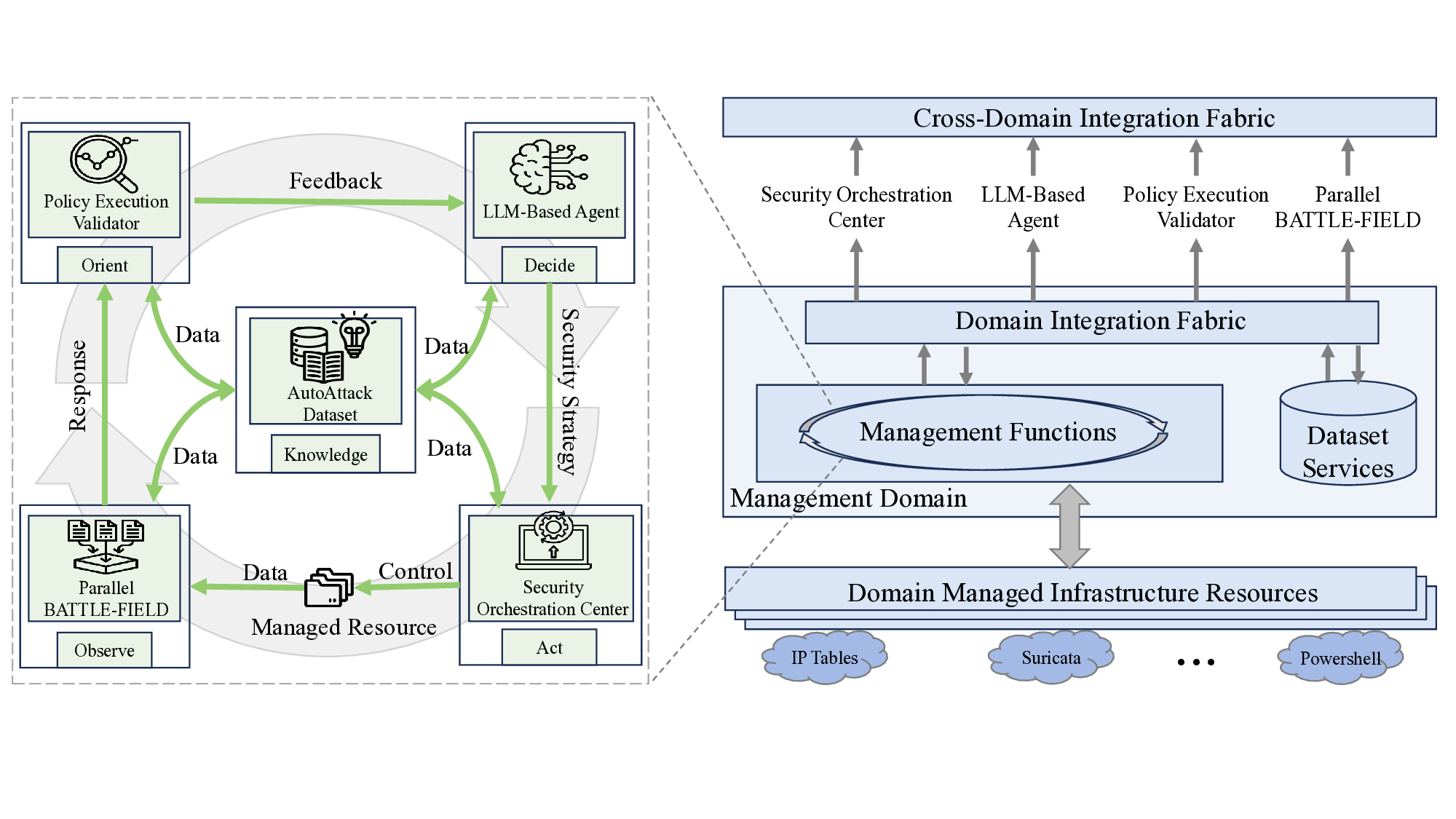
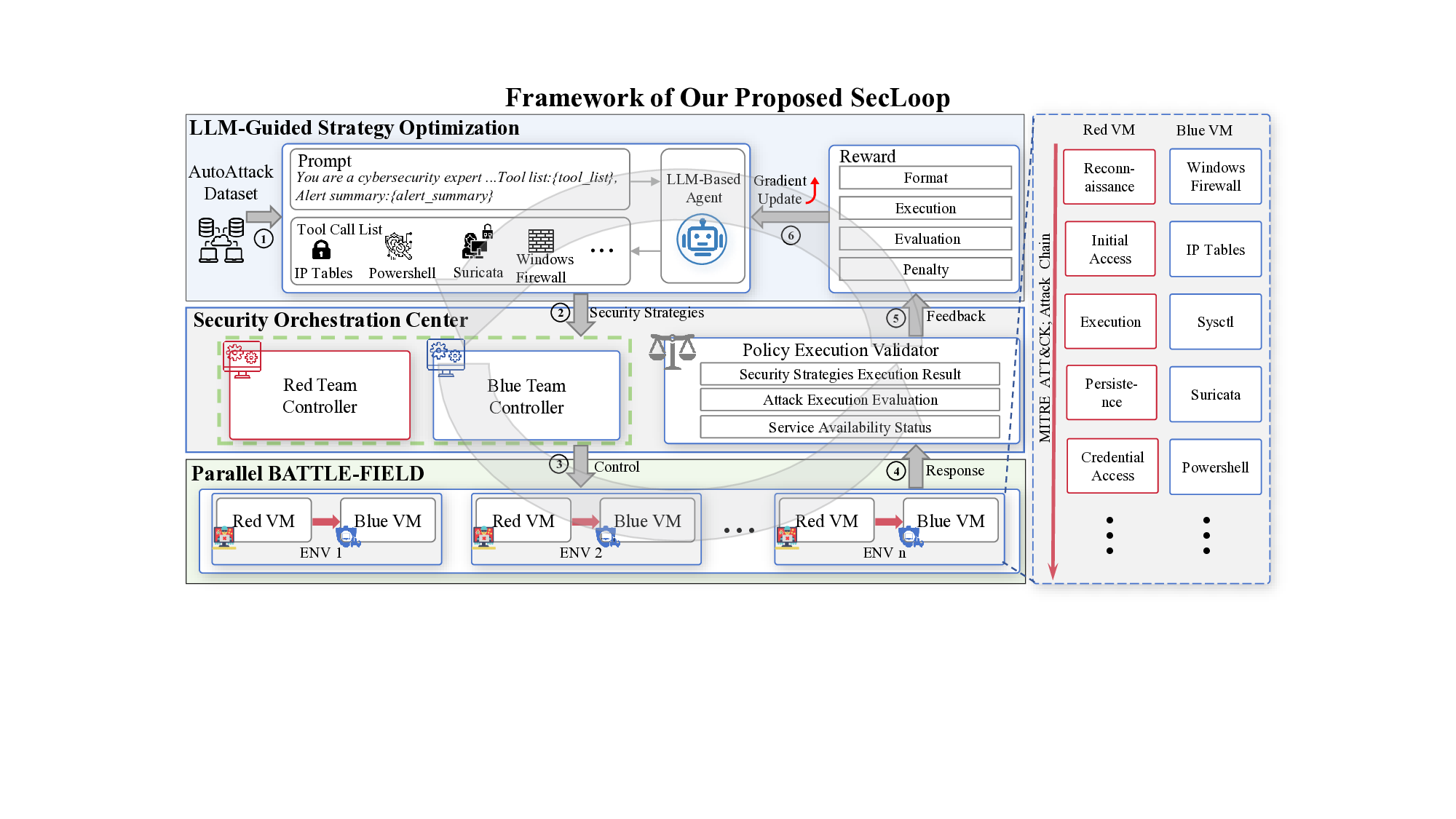
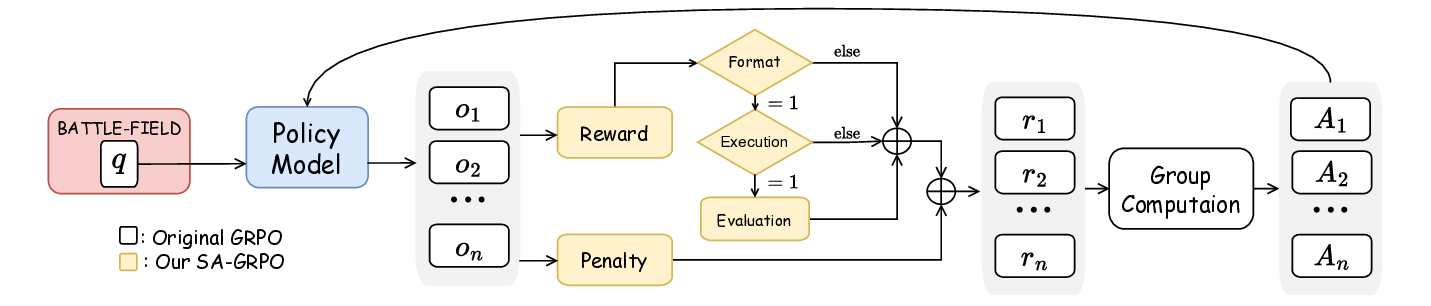
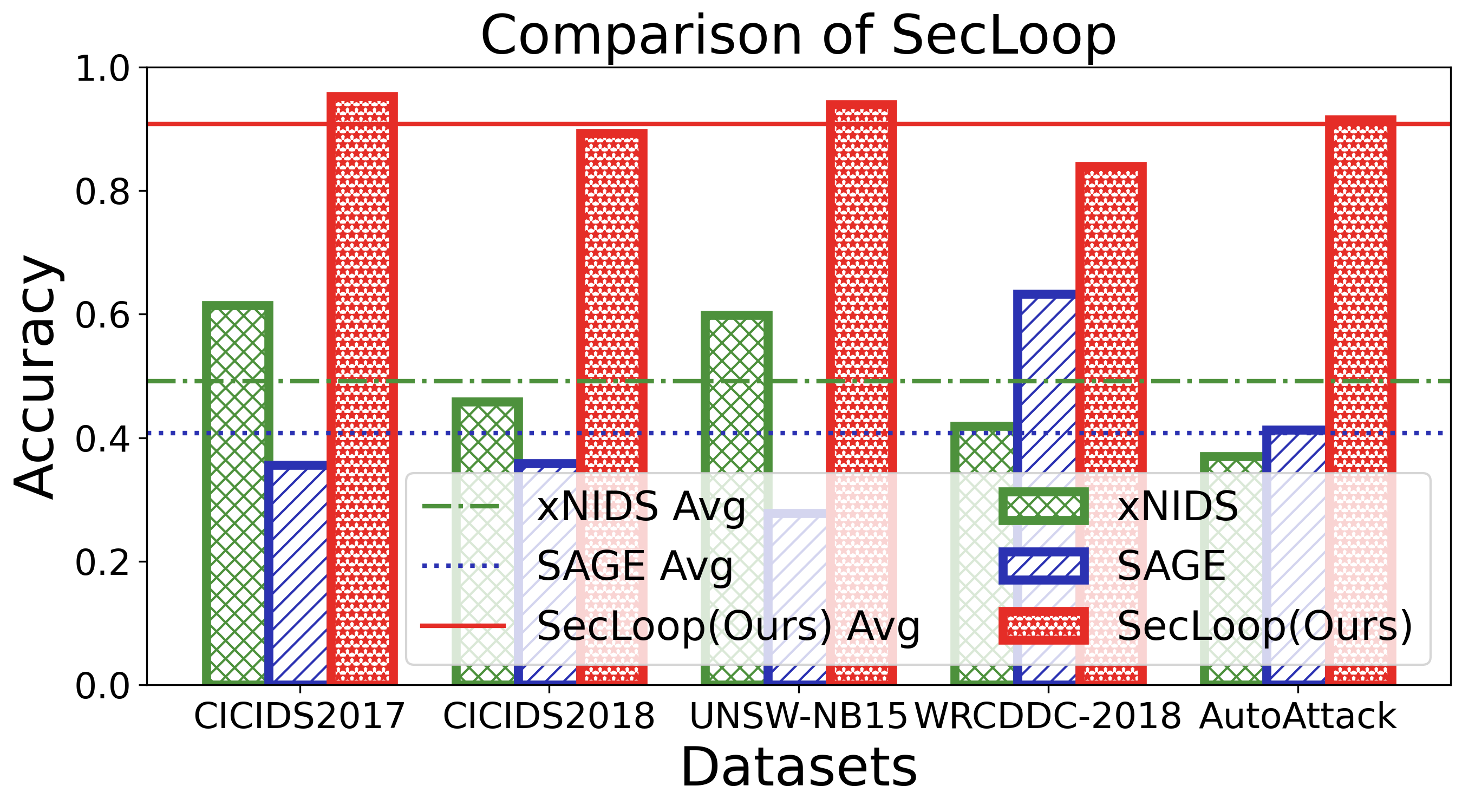
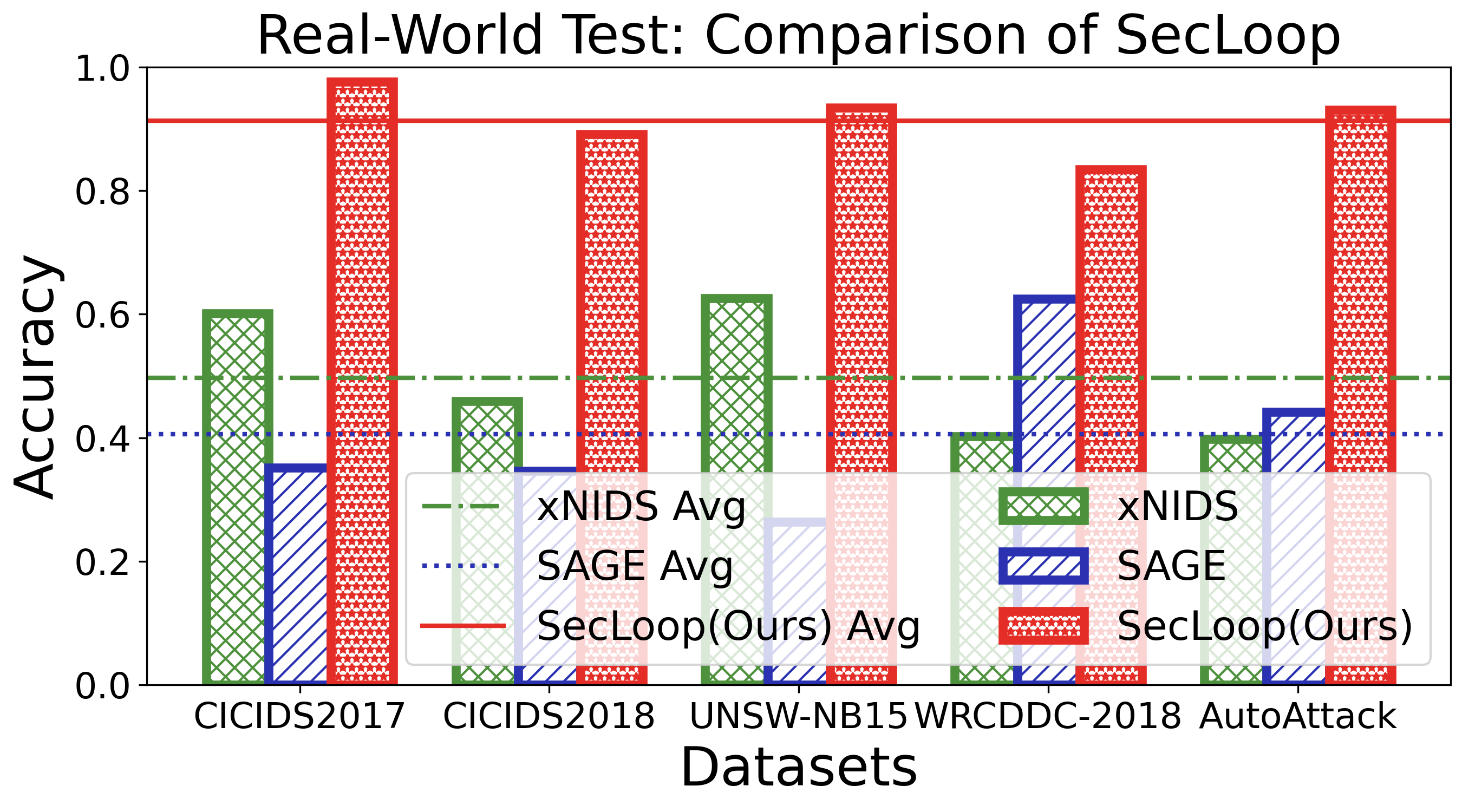
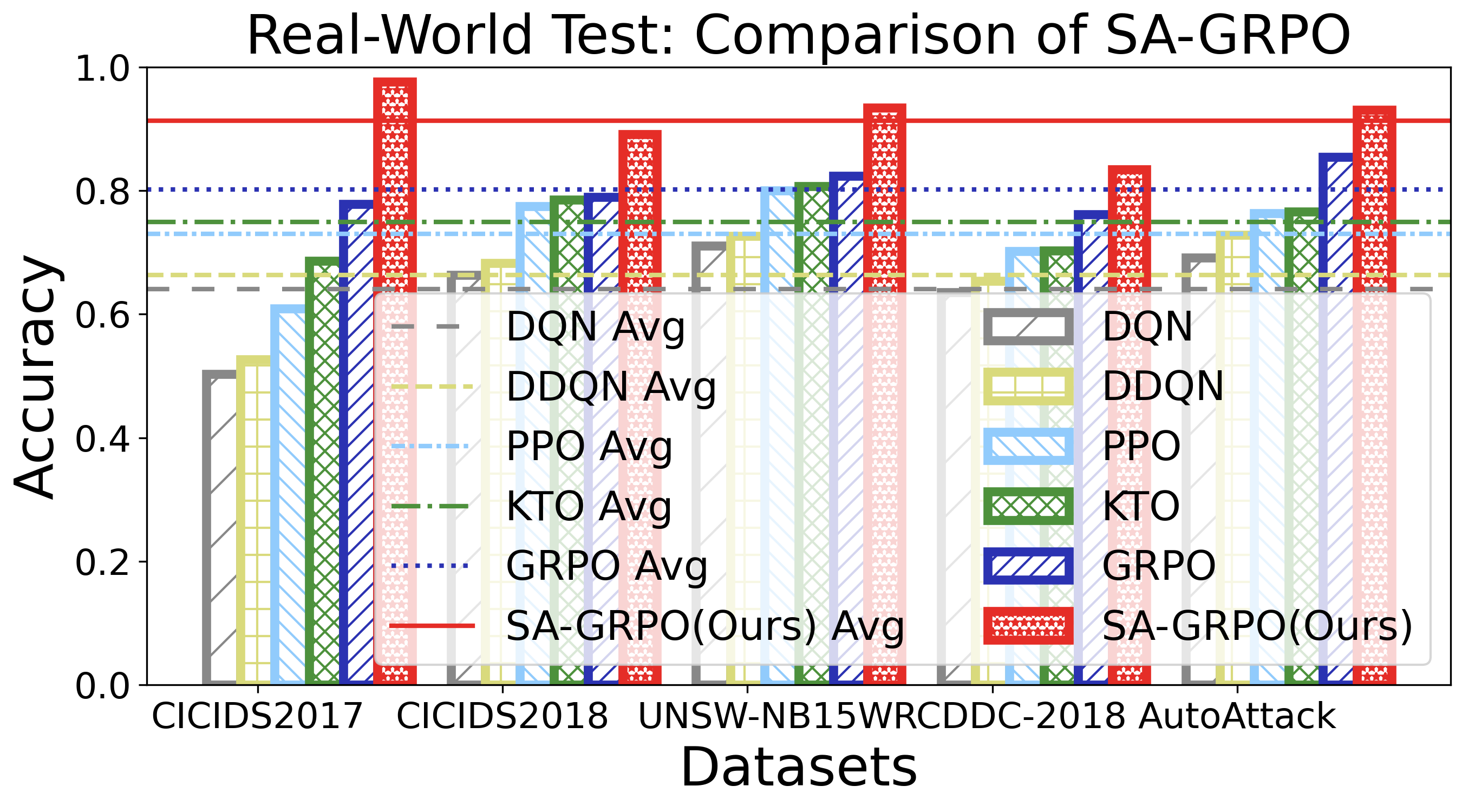
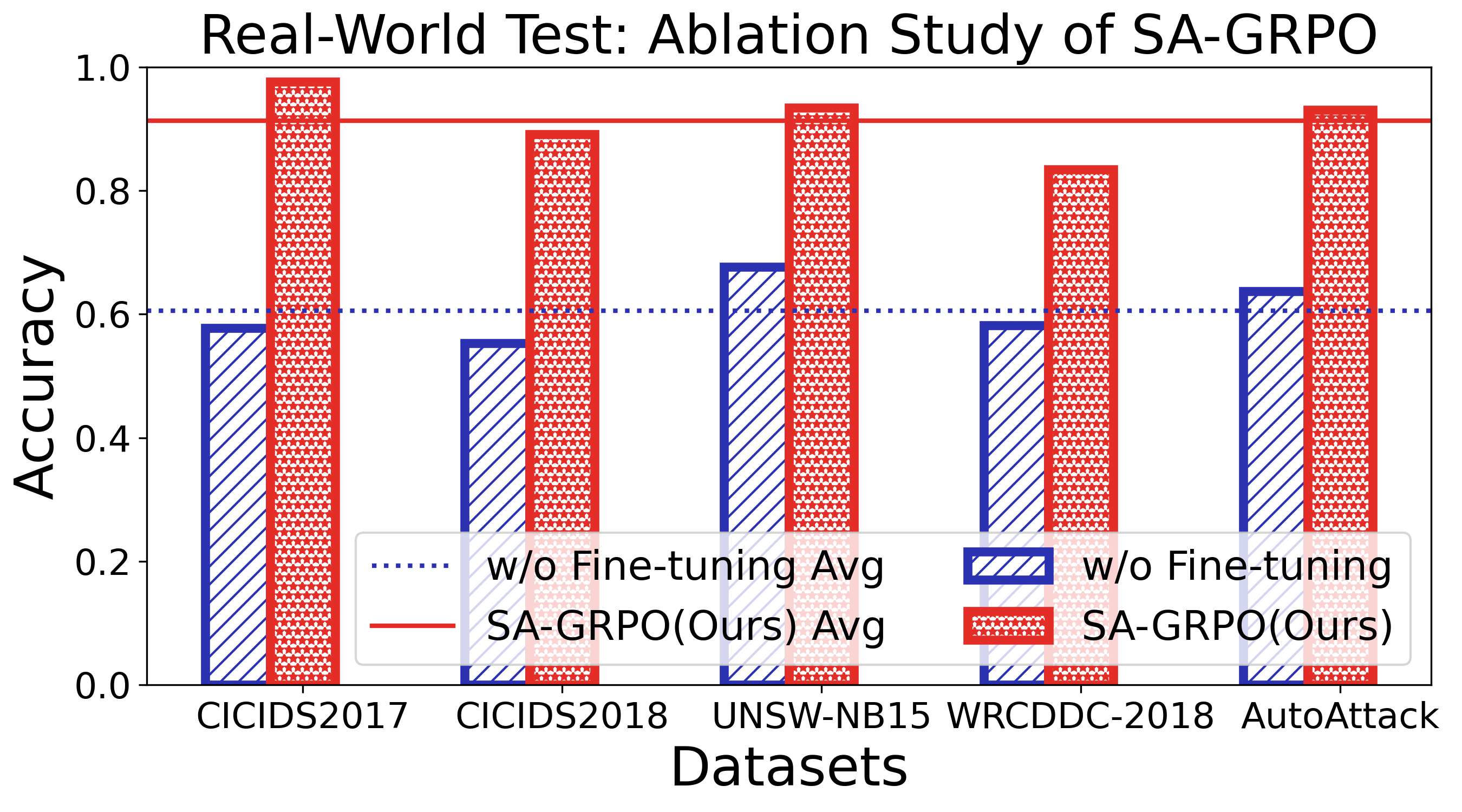
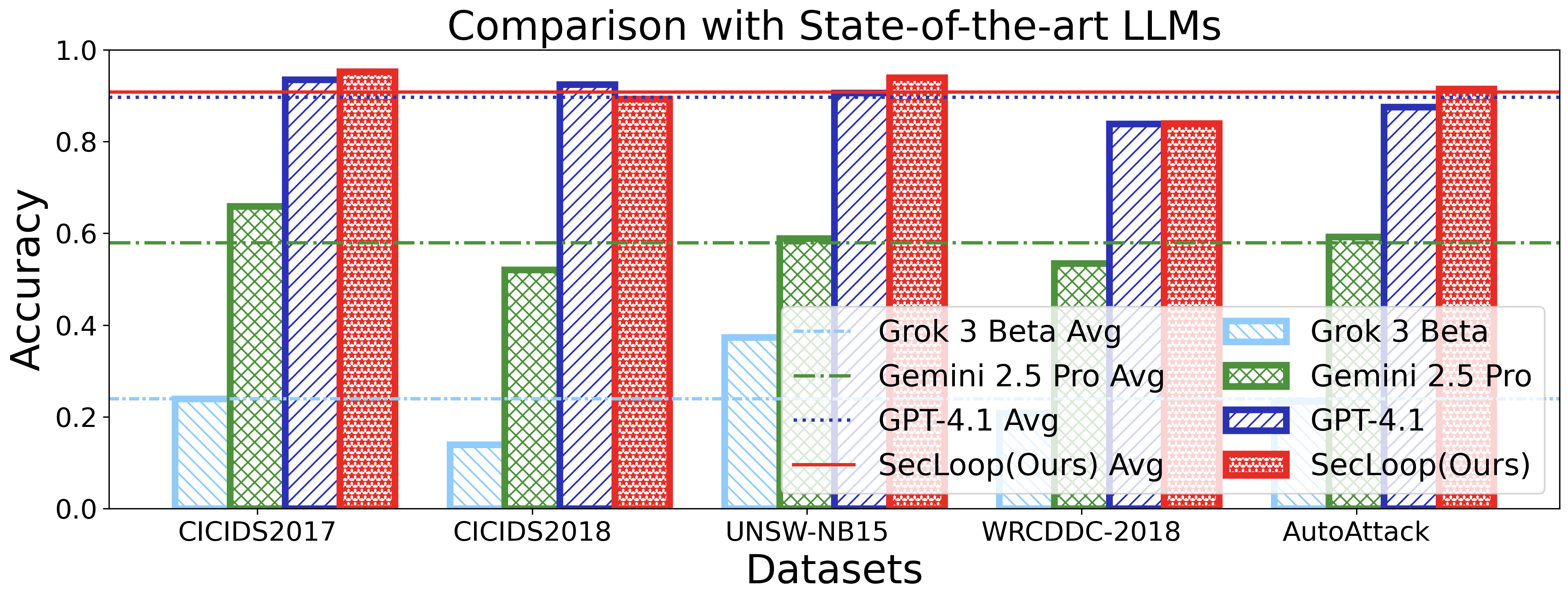
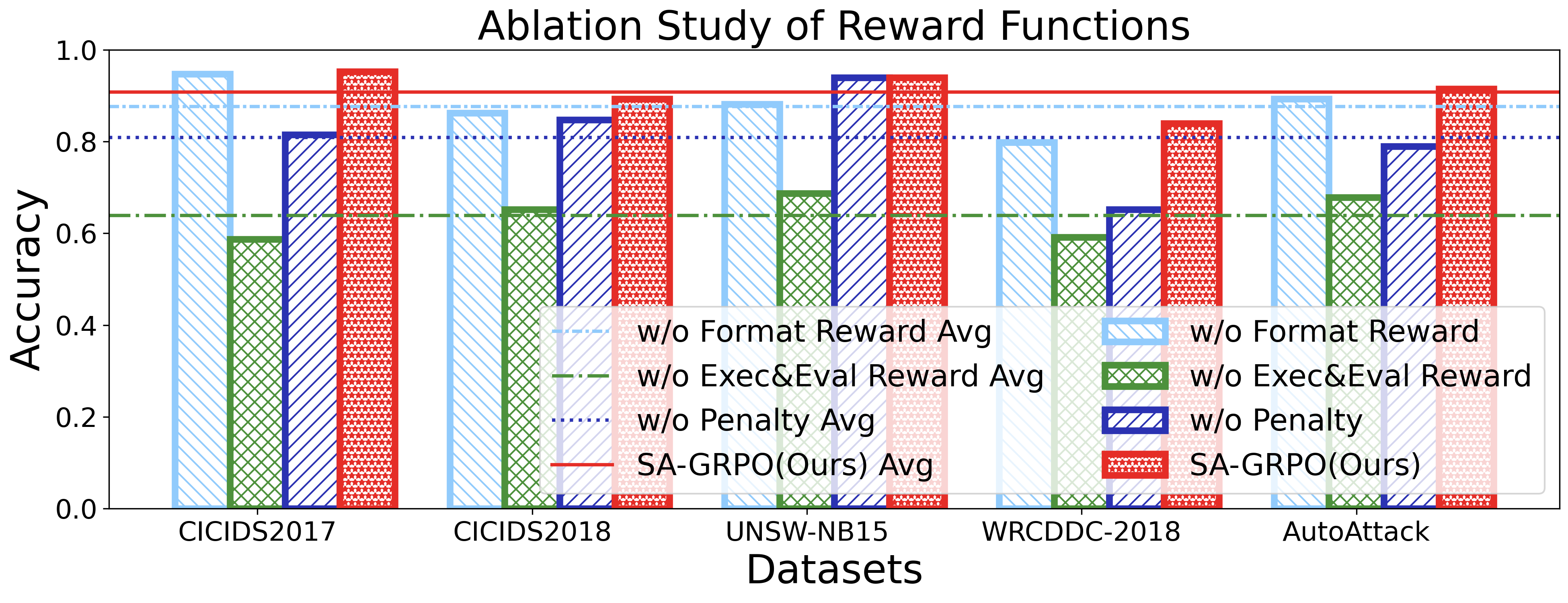
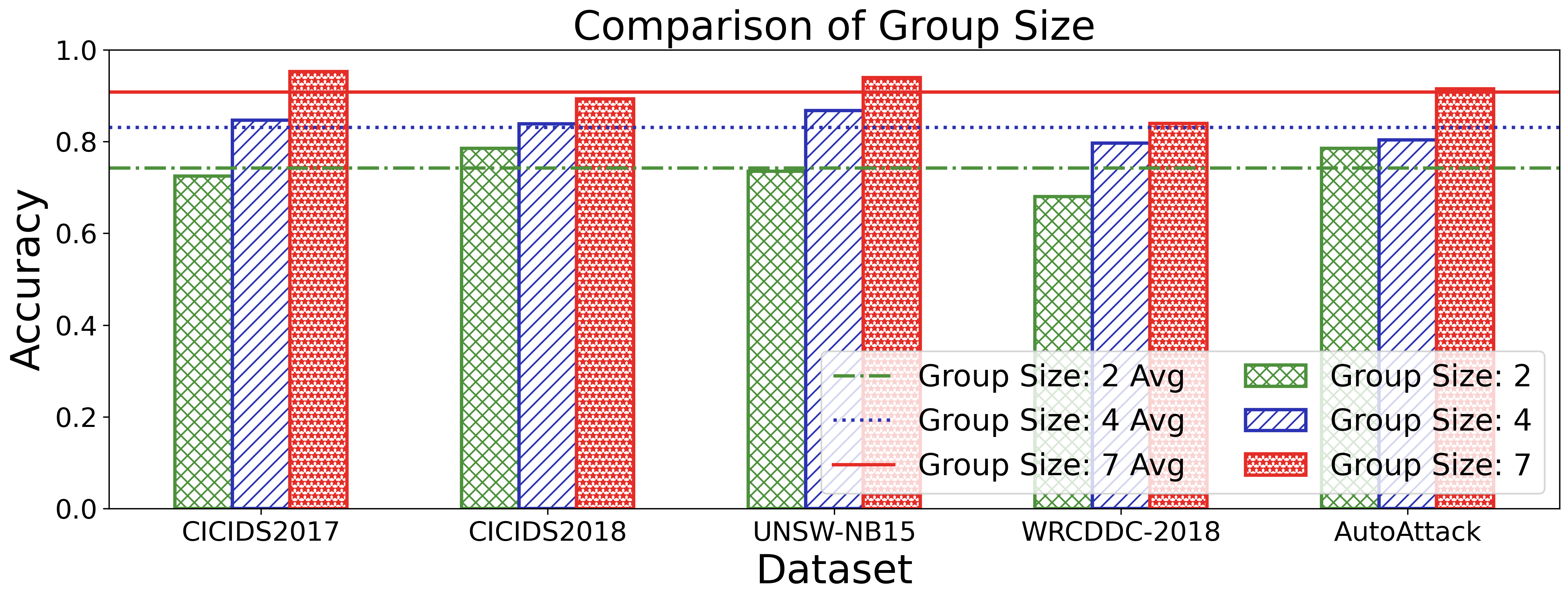
Keeping the above goals in mind, we design and implement SecLoop, an end-to-end security automation framework that enables strategy generation, execution, and feedback across real-world environments. SecLoop supports parallel deployment of diverse security strategies in isolated, virtualized environments and integrates LLMs as intelligent decision agents. These agents interact with streaming alerts from intrusion detection systems (IDS) and trigger responses through orchestrated security tools. To optimize decision-making under limited supervision, we further propose SA-GRPO, a securityaware group relative policy optimization algorithm. SA-GRPO generates a group of candidate strategies and deploys them concurrently in SecLoop environments. Feedback collected during execution is used to iteratively refine the policy through reinforcement learning. Through customized rewards, including format, execution, evaluation, and penalty, SA-GRPO can be tailored to security-specific scenarios. Extensive experiments on five benchmarks over 20 types of attack demonstrate the effectiveness of our proposed framework. Our code is publicly available 1 .
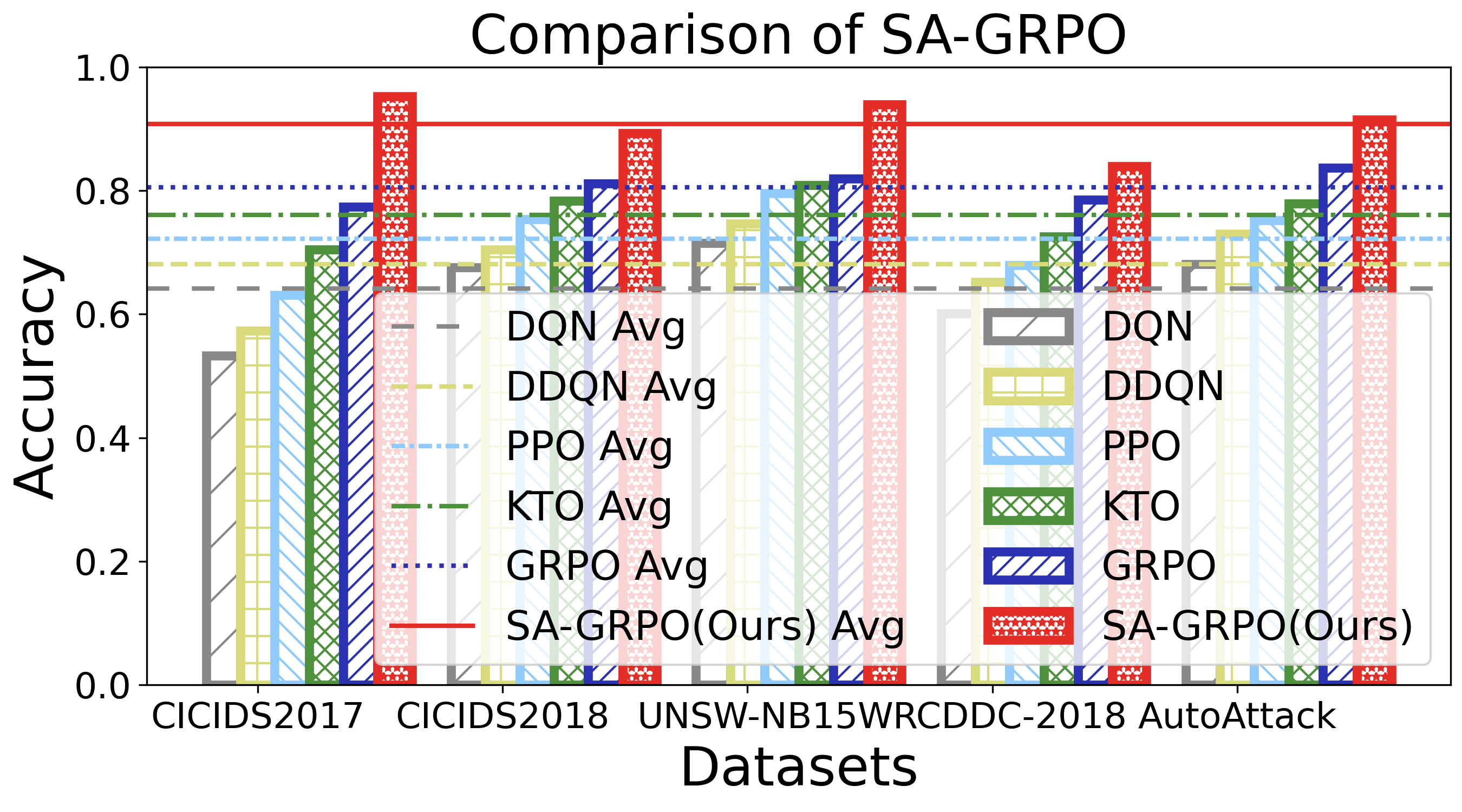
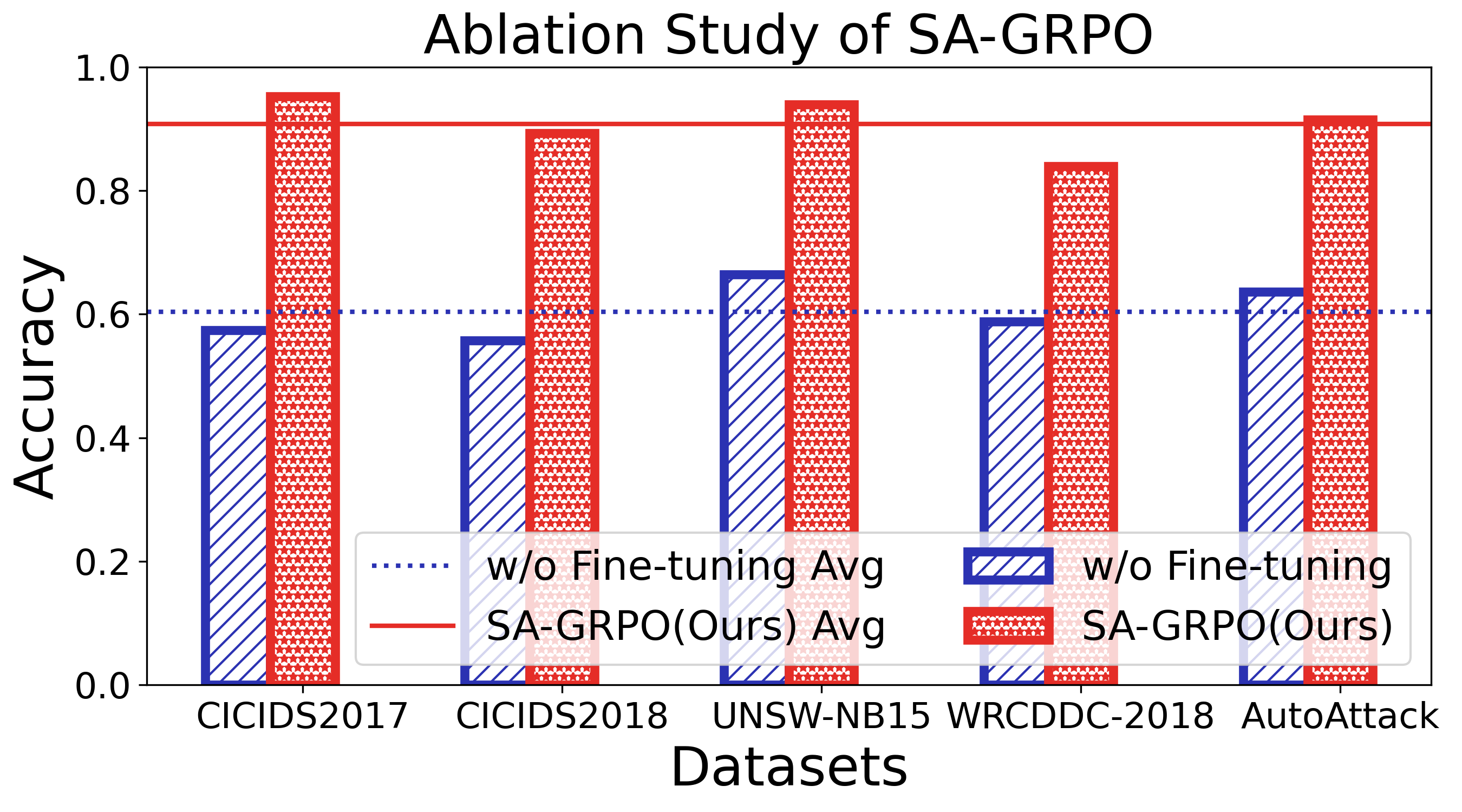
The main contributions of this paper are threefold: ❶ LLM Agent Empowered Security System: We design and implement SecLoop, the first end-to-end security strategy generation, orchestration, response, and feedback system, enabling adaptation of defensive strategies against evolving cyberthreats in 6G zero-touch networks. Integrated with native LLM and automated real-world BATTLE-FIELD (Blue And red Team Tactical Learning Environments For Intrusion, ExpLoitation, and Defense), SecLoop supports comprehensive attack simulation encompassing the ATT&CK process, provides a robust environment for fine-tuning LLMs and validating security algorithms under realistic adversarial conditions. ❷ Security-Aware GRPO: We propose SA-GRPO, a securityaware group relative policy optimization algorithm that refines security strategies through iterative feedback from parallel BATTLE-FIELD. SA-GRPO eliminates the need for highquality labeled data, adapting to the real world. To further tailor the optimization process to security-specific tasks, we design a customized reward function from four complementary perspectives, including format check, simulation execution, attack evaluation, and reasoning verification. ❸ Extensive Experiments: We conduct extensive experiments on four public benchmarks to show the effectiveness of the proposed SA-GRPO, yielding a state-of-the-art defense for the next generation networks. We also build a m
This content is AI-processed based on open access ArXiv data.