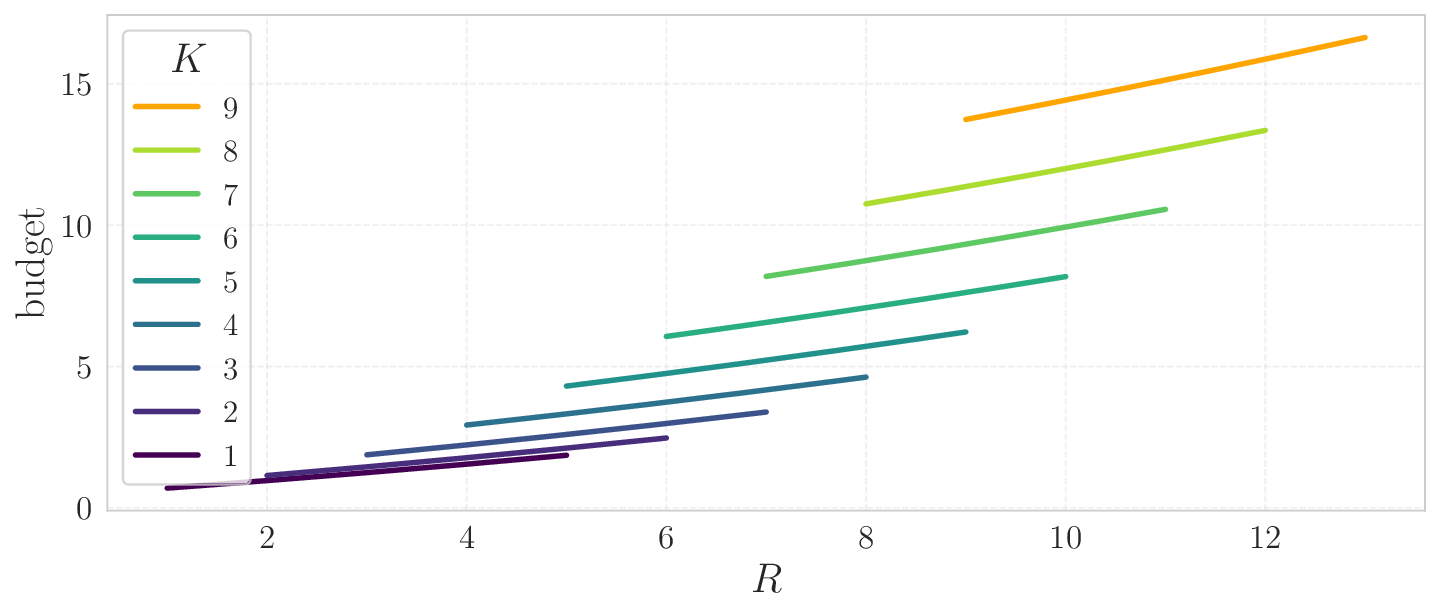Title: Dynamic one-time delivery of critical data by small and sparse UAV swarms: a model problem for MARL scaling studies
ArXiv ID: 2512.09682
Date: 2025-12-10
Authors: Mika Persson, Jonas Lidman, Jacob Ljungberg, Samuel Sandelius, Adam Andersson
📝 Abstract
This work presents a conceptual study on the application of Multi-Agent Reinforcement Learning (MARL) for decentralized control of unmanned aerial vehicles to relay a critical data package to a known position. For this purpose, a family of deterministic games is introduced, designed for scaling studies for MARL. A robust baseline policy is proposed, which is based on restricting agent motion envelopes and applying Dijkstra's algorithm. Experimental results show that two off-the-shelf MARL algorithms perform competitively with the baseline for a small number of agents, but scalability issues arise as the number of agents increase.
💡 Deep Analysis
📄 Full Content
Dynamic one-time delivery of critical data
by small and sparse UAV swarms: a model
problem for MARL scaling studies ‹
Mika Persson ˚,˚˚˚ Jonas Lidman ˚˚ Jacob Ljungberg ˚
Samuel Sandelius ˚ Adam Andersson ˚,˚˚˚
˚ Saab AB, 112 76, Gothenburg, Sweden (mikape@chalmers.se)
˚˚ Swedish Defence Research Agency (FOI), 164 90, Stockholm,
Sweden (jonas.lidman@foi.se)
˚˚˚ Chalmers University of Technology and the University of
Gothenburg, Department of Mathematical Sciences,
412 58, Gothenburg, Sweden (mikape@chalmers.se)
Abstract:
This work presents a conceptual study on the application of Multi-Agent Reinforcement
Learning (MARL) for decentralized control of unmanned aerial vehicles to relay a critical data
package to a known position. For this purpose, a family of deterministic games is introduced,
designed for scaling studies for MARL. A robust baseline policy is proposed, which is based
on restricting agent motion envelopes and applying Dijkstra’s algorithm. Experimental results
show that two off-the-shelf MARL algorithms perform competitively with the baseline for a
small number of agents, but scalability issues arise as the number of agents increase.
Keywords: Multi-agent systems, Reinforcement learning and deep learning in control, Learning
methods for control, Adaptive control of multi-agent systems, Markov decision process.
1. INTRODUCTION
Consider a search mission in which multiple Unmanned
Aerial Vehicles (UAVs) survey a designated area with the
goal of locating targets of interest and collecting associated
data. The mission involves dynamic UAVs, static base
stations, and entities that may interfere. After the search
concludes and a base station or UAV obtains critical
data, the scattered UAV swarm initiates a coordinated
task to swiftly deliver the data to a base station at a
known location. This return phase is the topic of the
current work. The UAVs can communicate and control
their motion. Moreover, the UAV swarm is sparse, meaning
that the UAVs cannot generally form a static connected
communication chain. Instead, they must physically move
to relay and deliver data, similarly to a rugby team.
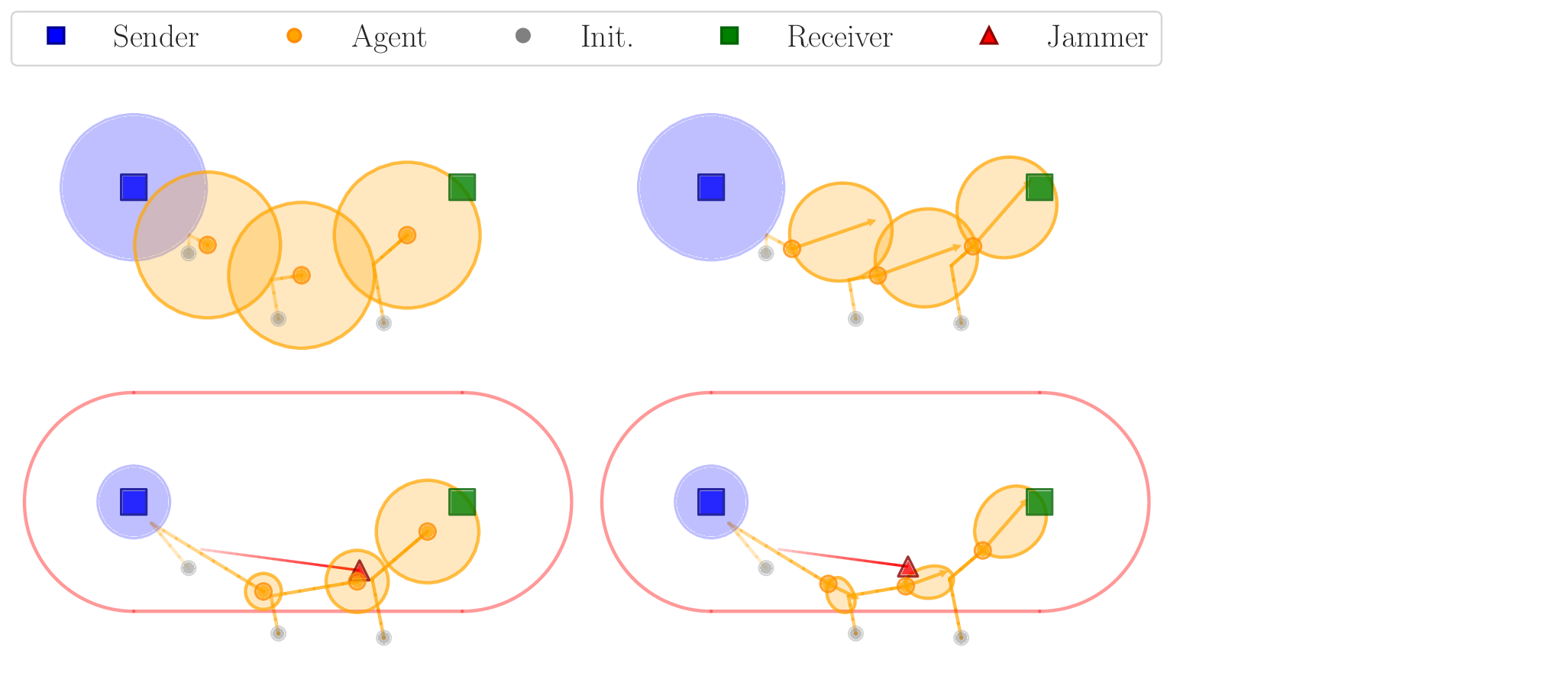
In this work, a family of deterministic games is introduced
that models the described problem and is suitable for
scalability studies in Multi-Agent Reinforcement Learn-
ing (MARL). The formulation captures key elements of
the real problem while introducing simplifications, most
notably the assumption of perfect information. A hand-
crafted, well-performing, and robust baseline policy is in-
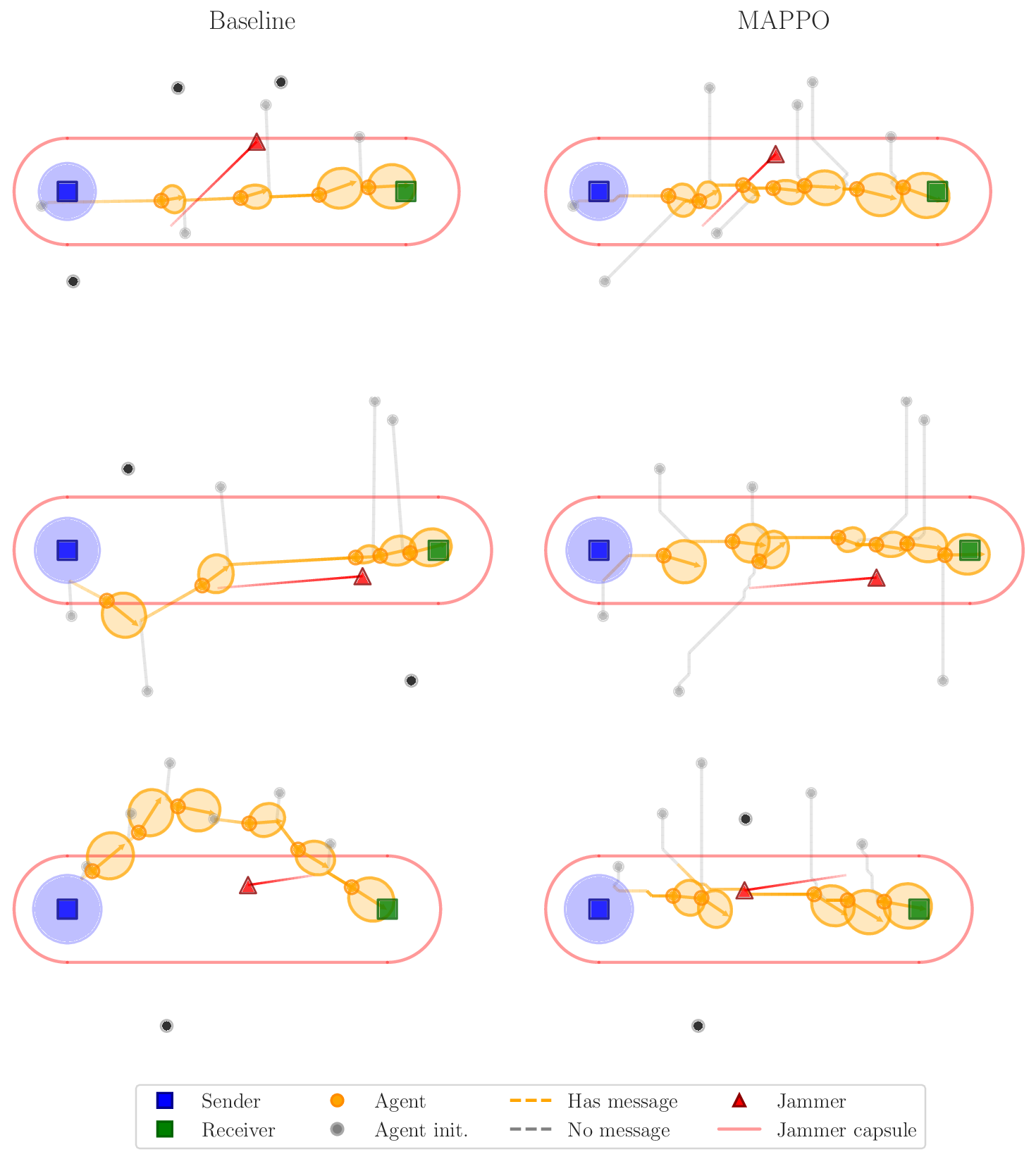
troduced, and two MARL methods from the literature
are trained and evaluated on scenarios involving up to
nine UAVs. The latter are Multi-Agent Proximal Policy
‹ The first author thanks the Wallenberg AI, Autonomous Systems
and Software Program (WASP) funded by the Knut and Alice Wal-
lenberg Foundation. Fredrik B˚aberg, Anders Israelsson and Johan
Markdahl at FOI are acknowledged for their great support and Axel
Ringh and Ann-Brith Str¨omberg at Chalmers for careful reading.
Optimization (MAPPO) (Yu et al., 2021) and Multi-Agent
Deep Deterministic Policy Gradient (MADDPG) (Lowe
et al., 2017). These algorithms have become popular in
the literature as building blocks for MARL solutions, due
to their good learning properties. Still, MARL is known for
having scaling problems in the number of agents, see, e.g.,
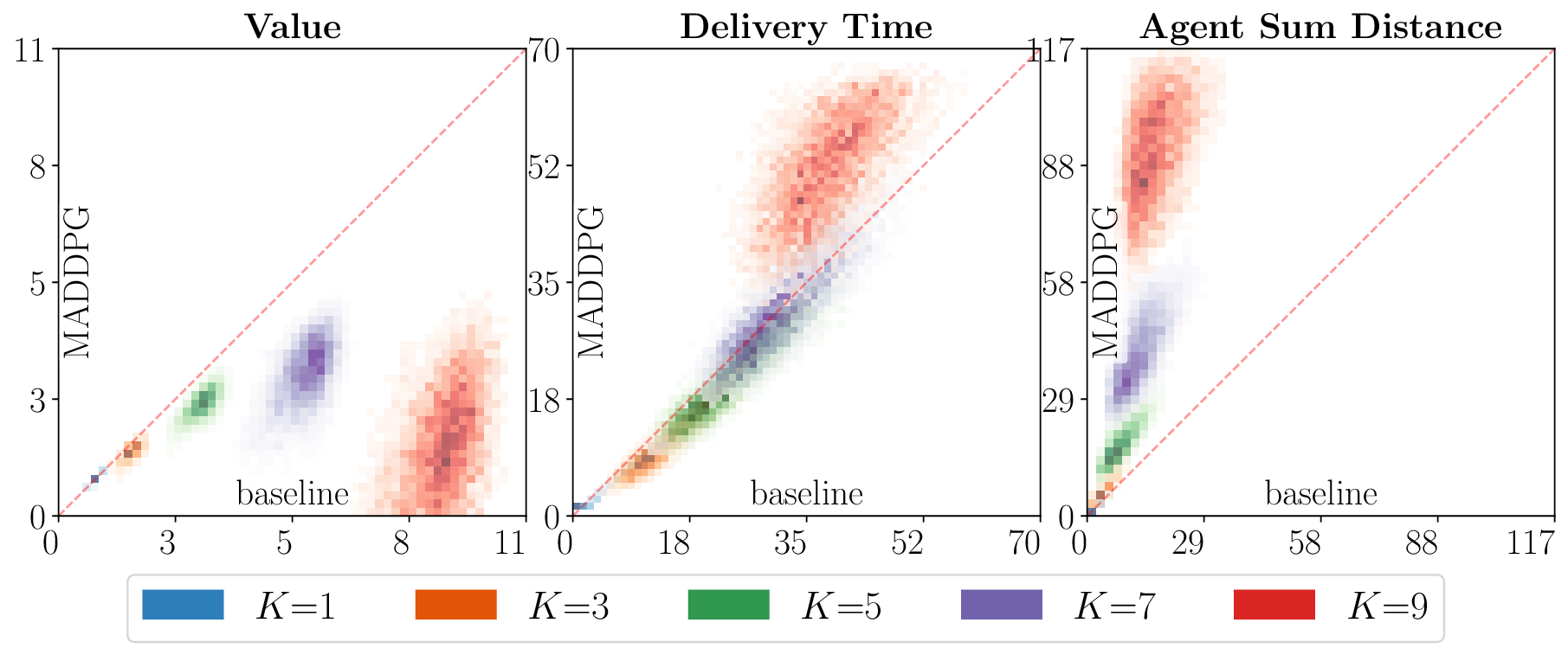
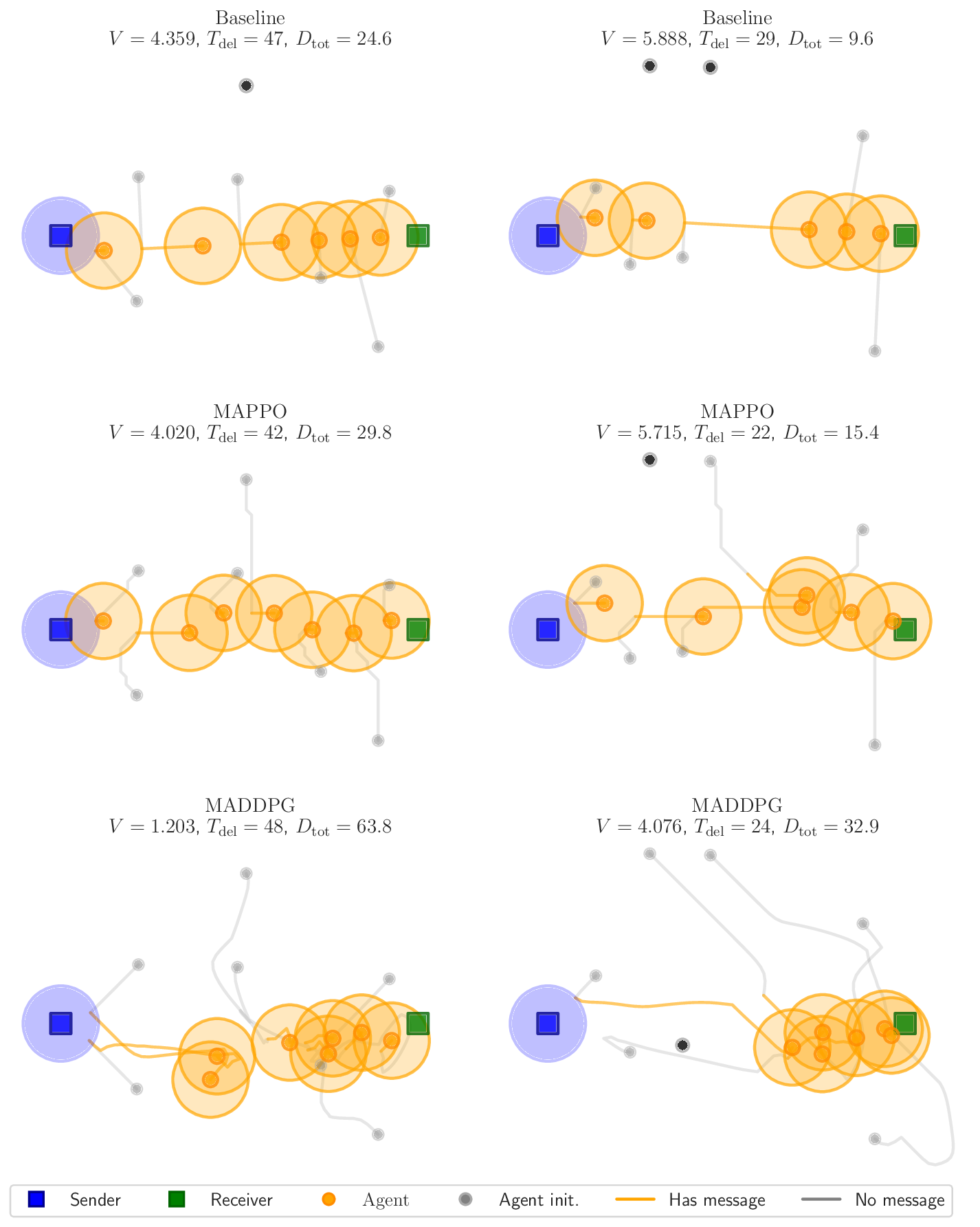
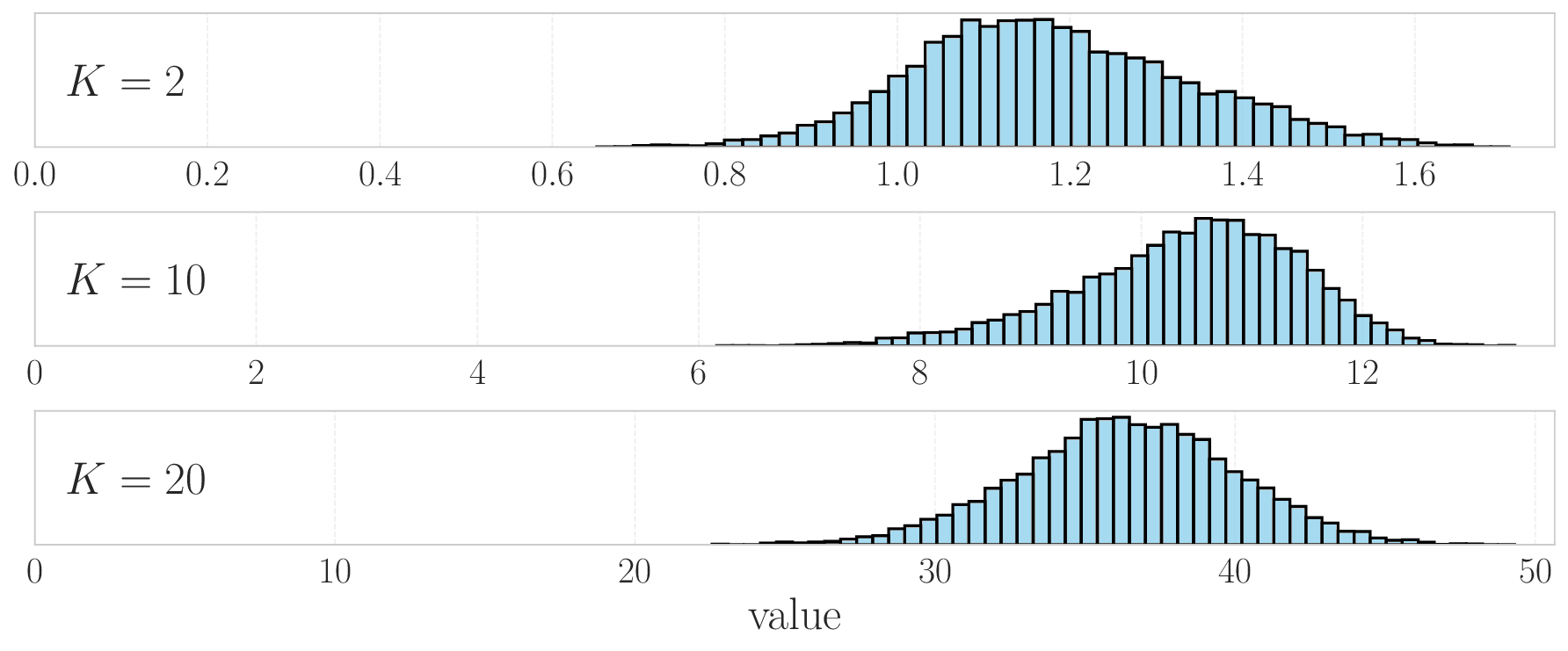
Gronauer and Diepold (2022). After training, MAPPO
remained competitive relative the baseline for up to seven
agents and MADDPG up to five agents. Beyond these
scales, both algorithms exhibited the expected degrada-
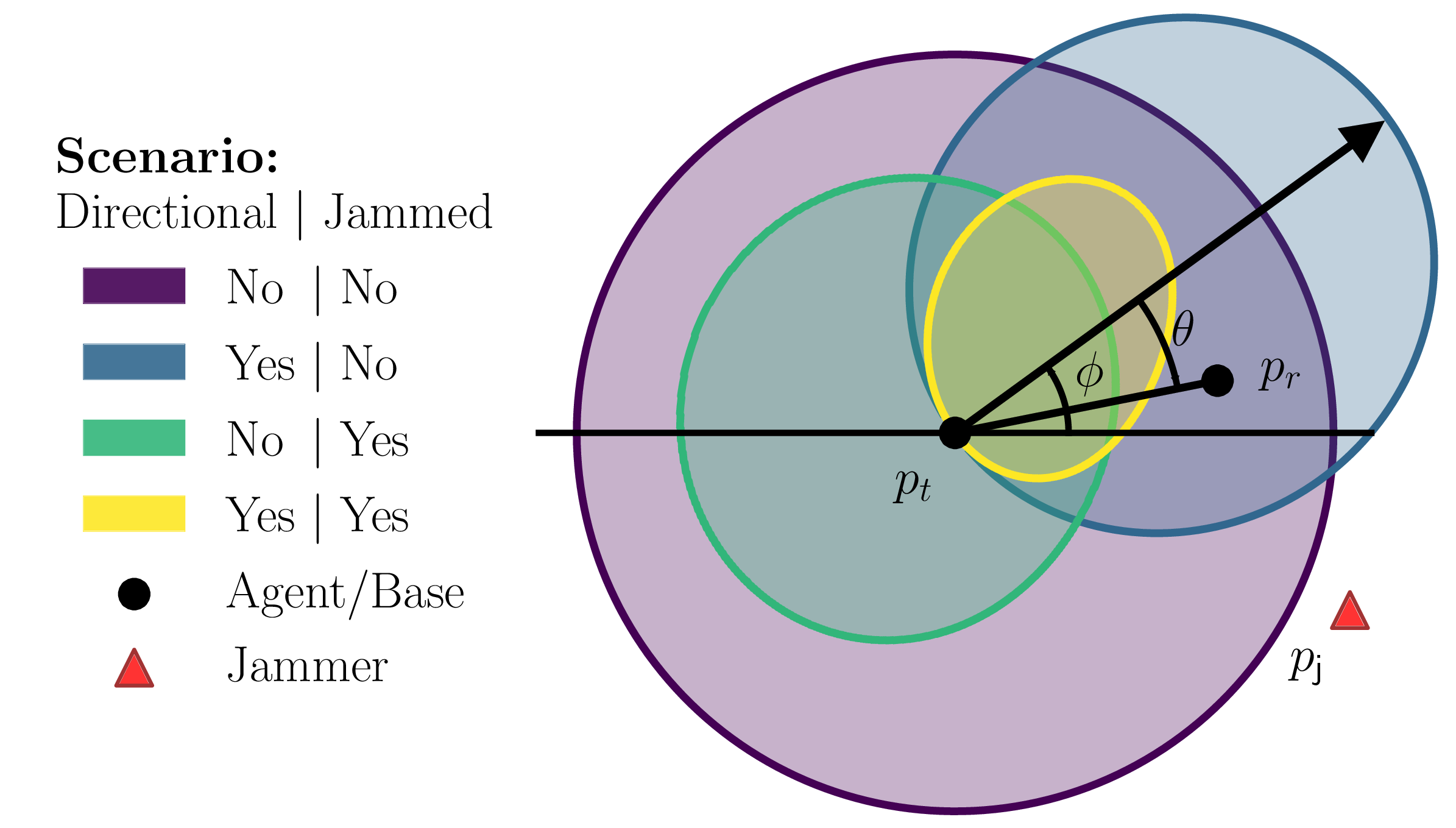
tion in performance. Four scenarios were evaluated, corre-
sponding to the combination of isotropic or directed data
links with the presence or absence of a jammer.
To the best of the authors’ knowledge, the problem of
delivering one single data package with UAVs has not been
previously reported in the literature. The use of UAVs to
maintain resilient data links through relay network is, how-
ever, well-studied in the literature; see (Bai et al., 2023). A
vast part of the literature consists of civilian applications
such as assisting systems of internet of things devices,
cellular networks, and mobile edge computing. Zhang et al.
(2020) investigate communication via relay UAVs under
presence of eavesdroppers. The proposed solution is to
deploy jammer UAVs that transmit interference toward
the eavesdroppers, thereby preventing interception. The
UAV policies are trained using MADDPG and an extended
variant, Continuous Action Attention MADDPG. The pa-
per demonstrates successful training of one transmitting
UAV together with two jammer UAVs. Similarly, Bai et al.
(2024), utilize relay UAVs to maintain a secure communi-
cation while avoiding eavesdropping by a hostile agent.
arXiv:2512.09682v1 [eess.SY] 10 Dec 2025
The UAVs control their transmission power and motion to
operate covertly. The proposed Covert-MAPPO algorithm
is successfully applied to a scenario with two relay UAVs.
A related problem concerning mo