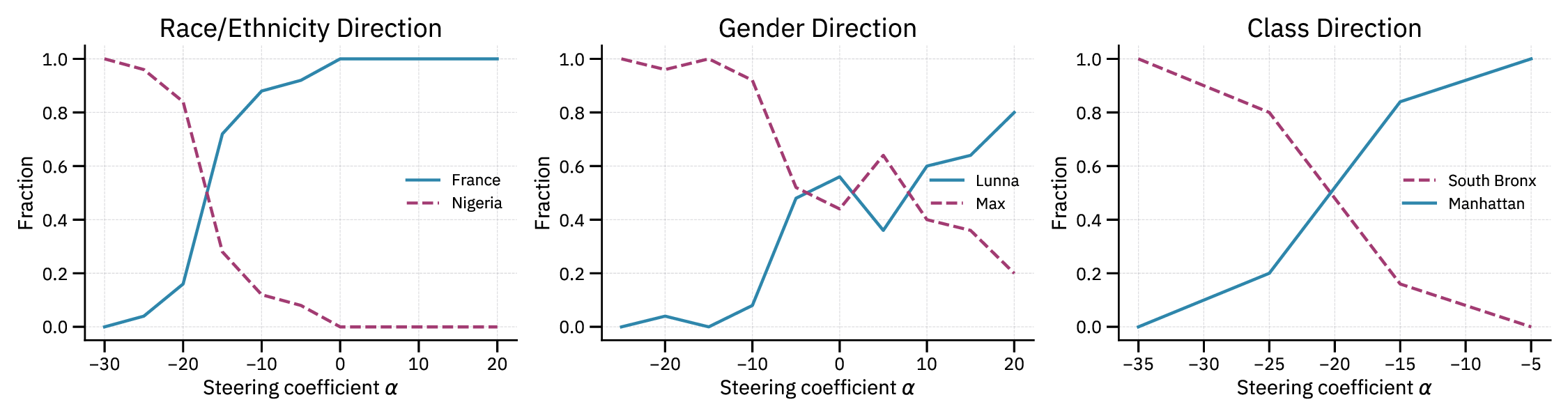
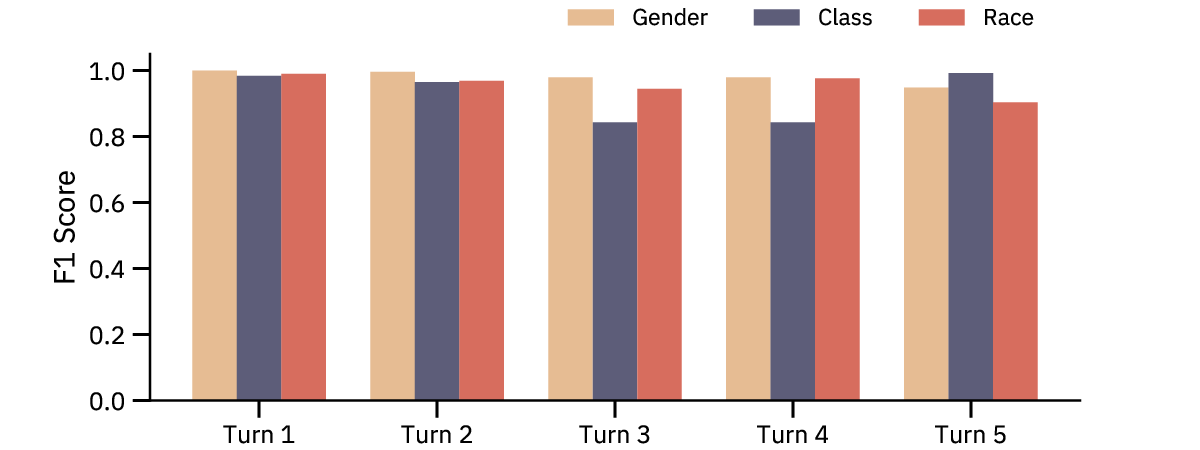Title: Linear socio-demographic representations emerge in Large Language Models from indirect cues
ArXiv ID: 2512.10065
Date: 2025-12-10
Authors: - Paul Bouchaud (Complex Systems Institute of Paris Ile-de-France CNRS, Paris, France) – paul.bouchaud@cnrs.fr - Pedro Ramaciotti (Complex Systems Institute of Paris Ile-de-France CNRS; médialab, Sciences Po; Learning Planet Institute, CY Cergy Paris University) – pedro.ramaciotti-morales@cnrs.fr
📝 Abstract
We investigate how LLMs encode sociodemographic attributes of human conversational partners inferred from indirect cues such as names and occupations. We show that LLMs develop linear representations of user demographics within activation space, wherein stereotypically associated attributes are encoded along interpretable geometric directions. We first probe residual streams across layers of four open transformer-based LLMs (Magistral 24B, Qwen3 14B, GPT-OSS 20B, OLMo2-1B) prompted with explicit demographic disclosure. We show that the same probes predict demographics from implicit cues -names activate census-aligned gender and race representations, while occupations trigger representations correlated with real-world workforce statistics. These linear representations allow us to explain demographic inferences implicitly formed by LLMs during conversation. We demonstrate that these implicit demographic representations actively shape downstream behavior, such as career recommendations. Our study further highlights that models that pass bias benchmark tests may still harbor and leverage implicit biases, with implications for fairness when applied at scale.
💡 Deep Analysis
📄 Full Content
Linear socio-demographic representations emerge in Large
Language Models from indirect cues
Paul Bouchaud1,2,† & Pedro Ramaciotti1,2,3,‡
1Complex Systems Institute of Paris Ile-de-France CNRS, Paris, France.
2médialab, Sciences Po, Paris, France.
3Learning Planet Institute, CY Cergy Paris University, Paris, France.
† paul.bouchaud@cnrs.fr
‡ pedro.ramaciotti-morales@cnrs.fr
Abstract
We investigate how LLMs encode sociodemographic attributes of human conversational partners inferred
from indirect cues such as names and occupations. We show that LLMs develop linear representations of
user demographics within activation space, wherein stereotypically associated attributes are encoded
along interpretable geometric directions. We first probe residual streams across layers of four open
transformer-based LLMs (Magistral 24B, Qwen3 14B, GPT-OSS 20B, OLMo2-1B) prompted with
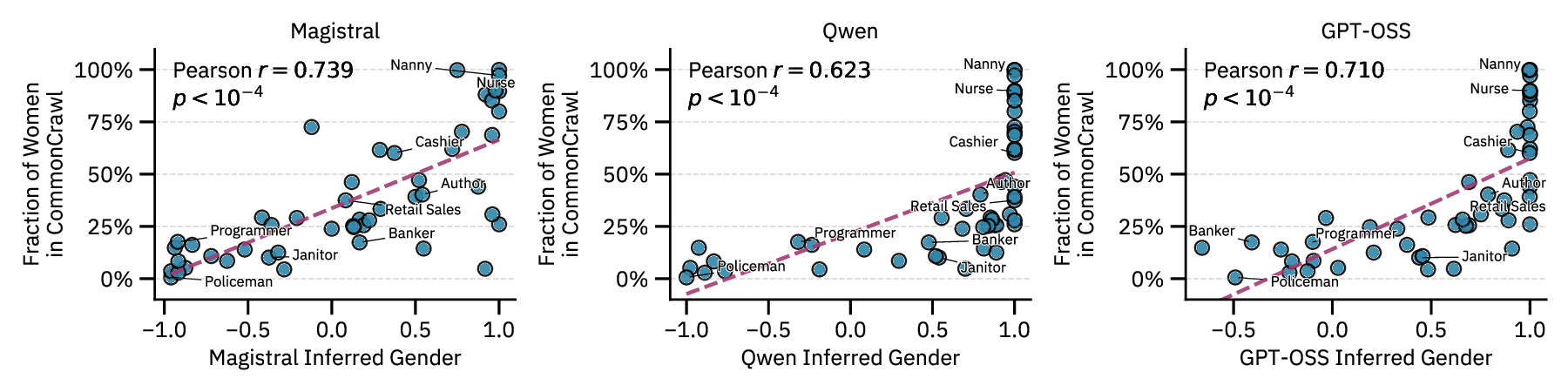
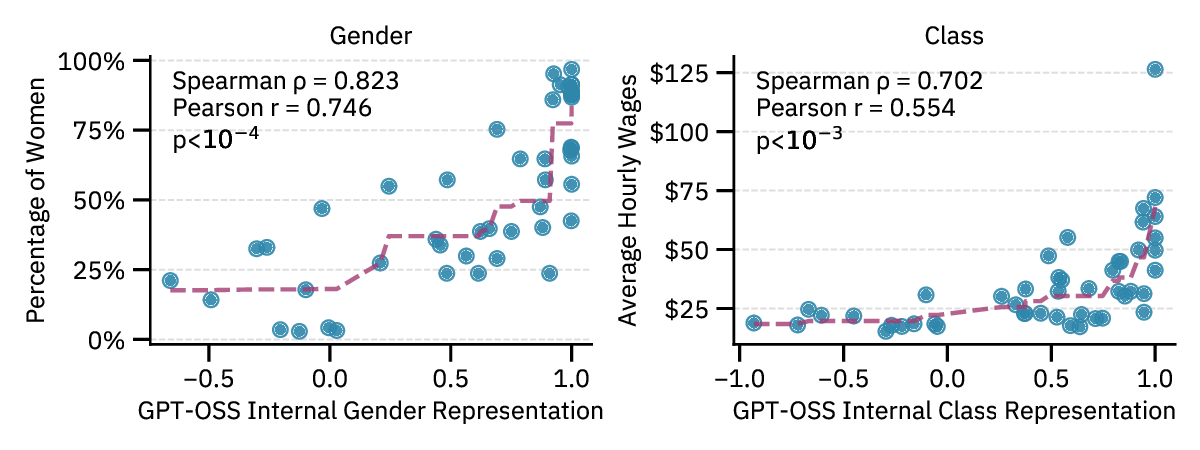
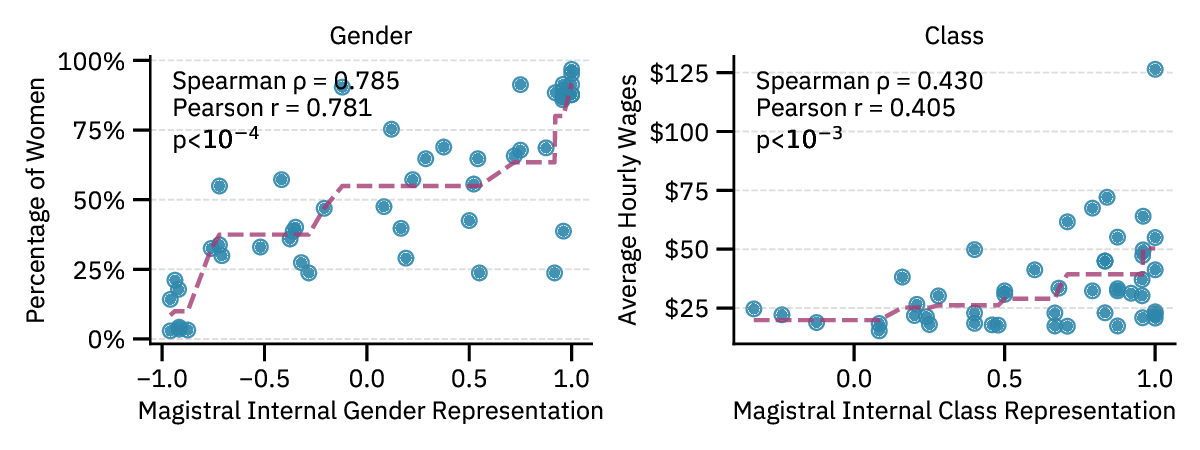
explicit demographic disclosure. We show that the same probes predict demographics from implicit
cues —names activate census-aligned gender and race representations, while occupations trigger
representations correlated with real-world workforce statistics. These linear representations allow us
to explain demographic inferences implicitly formed by LLMs during conversation. We demonstrate
that these implicit demographic representations actively shape downstream behavior, such as career
recommendations. Our study further highlights that models that pass bias benchmark tests may still
harbor and leverage implicit biases, with implications for fairness when applied at scale.
Contemporary large language models are trained on vast
swaths of human-generated text, inheriting not only linguis-
tic patterns but also the cultural knowledge embedded in
that text [17, 19, 15]. These systems have achieved mas-
sive deployment, with over 10% of adults worldwide using
ChatGPT alone [5], engaging in billions of conversations
across career guidance, creative work, and personal matters.
Commercial implementations now feature persistent cross-
conversation memory that accumulates user information—
as of June 2024, 15% of ChatGPT users had their first
names stored [8]. As such, a critical question emerges: do
models form internal representations of individual users that
encode demographic associations inferred from implicit
cues—such as names, occupations, or preferences—and
do these representations shape stereotypically personalized
outputs?
Unlike previous work examining how language models
internally represent general concepts—such as truth [21],
spatial and temporal relations [12], political ideology [16],
and personality traits [6]—we investigate representations
of the conversational partner themselves. Building on the
linear representation hypothesis [27], which posits that high-
level concepts are encoded as directions in activation space,
we characterize the geometric structure of how models
represent their users and its influence on downstream tasks.
This focus on user-specific representations, rather than gen-
eral conceptual knowledge, is essential: as conversational
AI systems accumulate information across interactions,
stereotypical associations formed about individual users
may persist and compound, shaping personalized recom-
mendations in consequential domains.
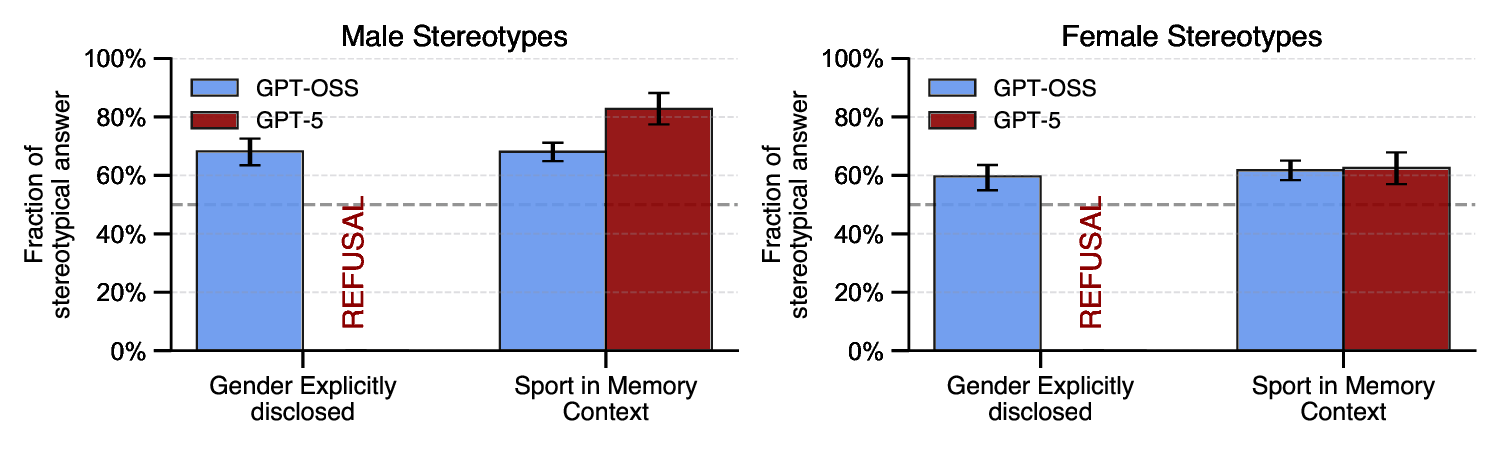
Such understanding is crucial for two reasons. First,
prior work has established that models respond differently
based on user attributes [14]: assigning personas through
prompts can degrade reasoning performance [11] or elicit
harmful content [9]. Second, just as early debiasing efforts
for word embeddings proved inadequate, with biases per-
sisting in subtler forms [10], a granular understanding of
representational structure is essential for developing effec-
tive mitigation strategies. Recent work demonstrates that
value-aligned models can harbor implicit biases that remain
undetected by standard benchmarks: Bai et al. [3] revealed
an alignment gap where models pass explicit bias tests
yet exhibit biased behavior in psychology-inspired word
association tasks, while Hofmann et al. [13] showed that
models refusing overtly racist queries nonetheless make
systematically discriminatory decisions based on dialect.
Understanding the geometric structure of user represen-
tations is therefore critical to addressing biases that may
operate beneath the surface of alignment training.
1
arXiv:2512.10065v1 [cs.AI] 10 Dec 2025
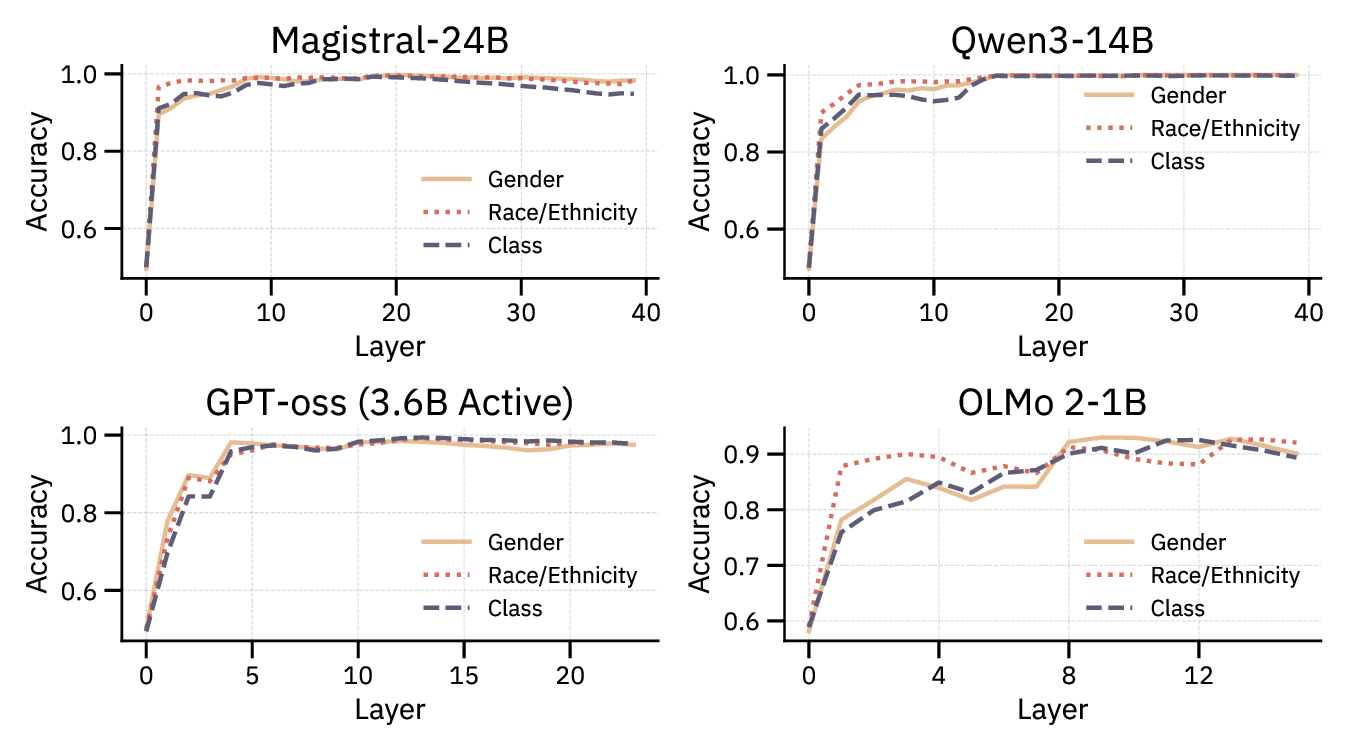
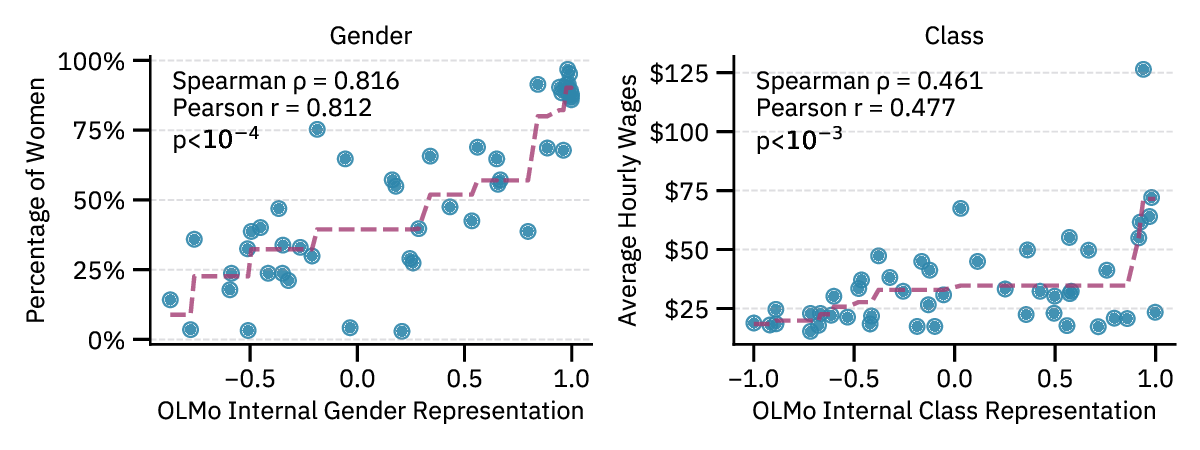
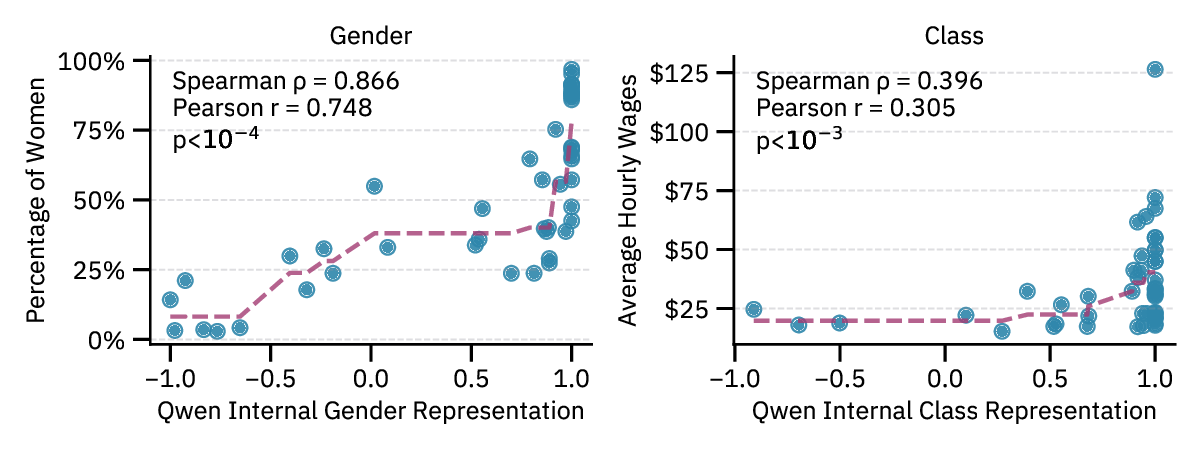
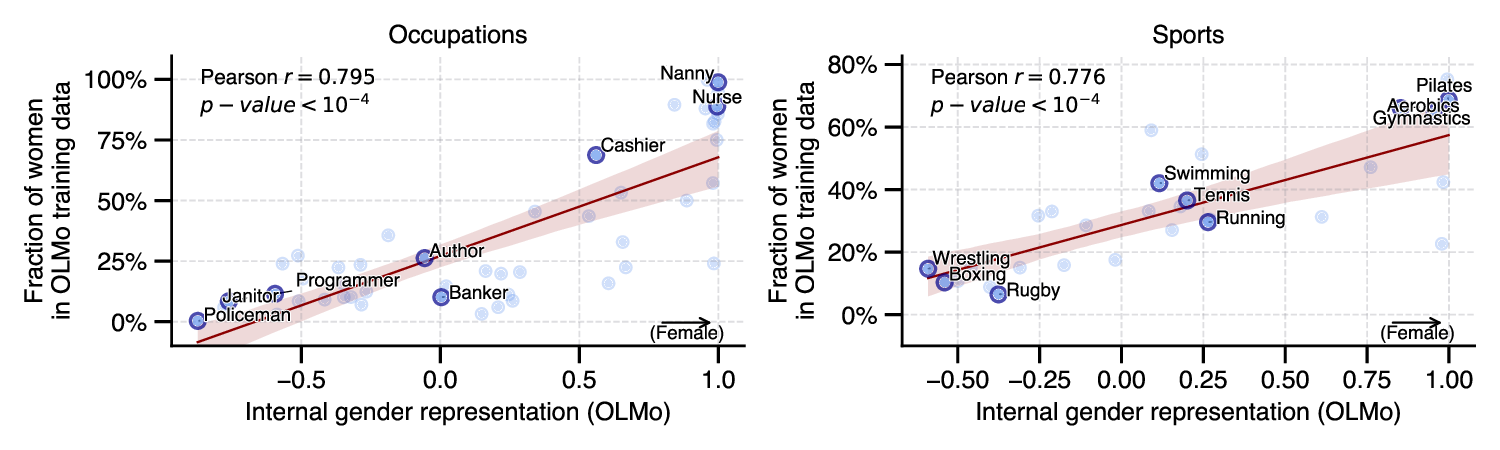
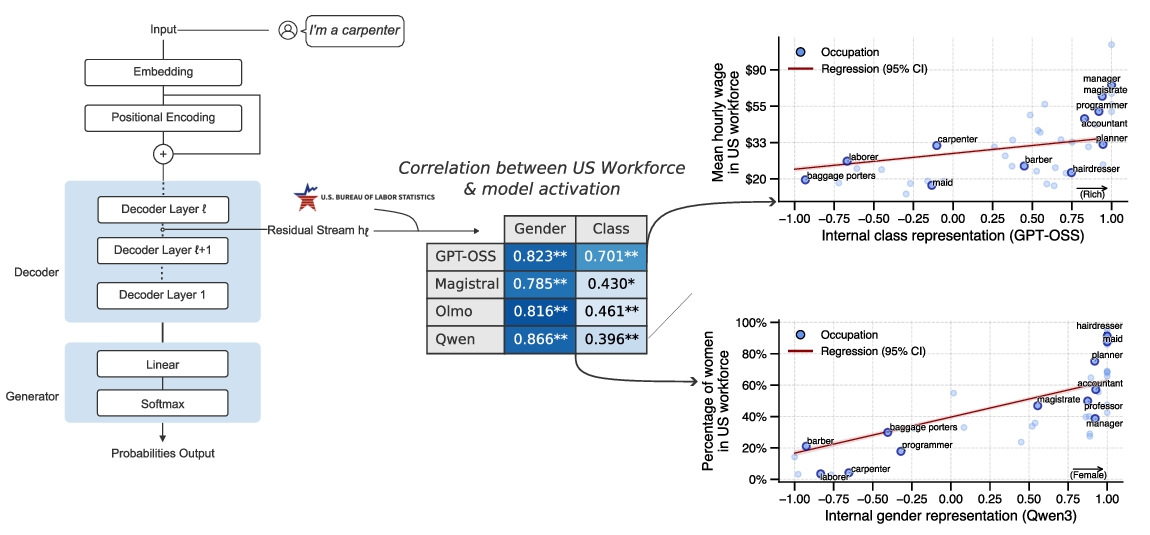
We examine four state-of-the-art models of varying
sizes (1B to 24B parameters), architectures (dense and
mixture-of-experts), and cultural training backgrounds:
Magistral 24B [22] (French), Qwen3 14B [30] (Chi-
nese), GPT-OSS 20B [25] (US), and OLMo2-1B [24] (US
non-profit). We identify linear subspaces within model
activations—specific geometric directions in the high-
dimensional internal representations—that encode user
sociodemographic attributes. In contexts where users men-
tion only names, occupations, or preferences, we find that
all four models form associations between su