With the proliferation of edge AI applications, satisfying user quality of experience (QoE) requirements, such as model inference latency, has become a first class objective, as these models operate in resource constrained settings and directly interact with users. Yet, modern AI models routinely exceed the resource capacity of individual devices, necessitating distributed execution across heterogeneous devices over variable and contention prone networks. Existing planners for hybrid (e.g., data and pipeline) parallelism largely optimize for throughput or device utilization, overlooking QoE, leading to severe resource inefficiency (e.g., unnecessary energy drain) or QoE violations under runtime dynamics.
We present Dora, a framework for QoE aware hybrid parallelism in distributed edge AI training and inference. Dora jointly optimizes heterogeneous computation, contention prone networks, and multi dimensional QoE objectives via three key mechanisms: (i) a heterogeneity aware model partitioner that determines and assigns model partitions across devices, forming a compact set of QoE compliant plans; (ii) a contention aware network scheduler that further refines these candidate plans by maximizing compute communication overlap; and (iii) a runtime adapter that adaptively composes multiple plans to maximize global efficiency while respecting overall QoEs. Across representative edge deployments, including smart homes, traffic analytics, and small edge clusters, Dora achieves 1.1--6.3 times faster execution and, alternatively, reduces energy consumption by 21--82 percent, all while maintaining QoE under runtime dynamics.
The proliferation of on-device AI applications-ranging from large language models (LLMs)-powered assistants [17, 28, 31] * Both authors contributed equally to this research. and smart robotics [4,27] to video surveillance [22] with multimodal LLMs-has brought Quality of Experience (QoE) to the forefront of edge AI tuning and inference. Unlike cloudbased deployments, where the system's primary objective is to maximize throughput [28,39] or resource efficiency [3] for aggregate performance across users, on-device AI often serves individual users, needing to satisfy per-user QoE requirements such as training or serving latency [6,10] and energy efficiency [28].
Aligning execution with these QoE targets not only ensures service quality but also improves system efficiency: exceeding QoE thresholds yields diminishing perceptual returns while wasting scarce resources. For example, in federated learning, clients only need to train quickly enough to avoid delaying the global aggregation round across hundreds of clients [12,14]; in continuous or personalized learning, training needs only keep pace with data generation (e.g., sensor events or app usage), thereby reducing interference with foreground tasks and conserving energy. On the inference side, users interacting with on-device LLMs expect token generation rates aligned with human reading or interaction speed [18,34], and edge cameras for traffic analytics need only track the natural rate of scene evolution [2,5].
However, meeting QoE requirements on a single edge device is increasingly untenable ( §2.1). Emerging applications depend on high-accuracy models that, while modest by cloud standards, saturate the compute, memory, and energy envelopes of edge devices. Running Qwen3-4B alone requires roughly 12 GB of memory, while iPhone 15 offers only 6GB of RAM. Worse, even a fully charged iPhone 15 can sustain less than an hour of operation when running assistive edge-AI agents (e.g., small multimodal LLMs for visually impaired individuals) [5,19]. Increasingly, edge environments have multiple compute-capable devices-smartphones, tablets, laptops in a home, or multiple AI cameras at an intersection-creating opportunities for QoE-aware, distributed model execution across edge devices. The goal is not merely to eliminate resource slack or maximize raw throughput, but to shape execution around user-driven QoE objectives while operating under the dynamism of real-world edge environments.
Enforcing QoE-aware hybrid parallelism, such as combining data and pipeline parallelism across edge devices, introduces unique challenges ( §2). Unlike controllable, homogeneous cloud settings with abundant and predictable network bandwidth, edge deployments consist of devices with heterogeneous compute and memory capabilities, and communication over contention-prone wireless channels (e.g., WiFi) or irregular wired structures (e.g., chains or rings). Even very recent edge AI advances for distributed model execution [30] have largely overlooked these network effects, leading to 4× efficiency degradation, as contention erases the benefits of model parallelism. Under dynamics, these systems frequently trigger heavy-weight replanning or model migration, stalling the service, while their emphasis on maximizing raw throughput can cascade into QoE violations such as rapid battery drain or thermal throttling.
This paper introduces Dora, a framework for distributed edge AI training and inference that generates parallelism plans explicitly to satisfy user-defined QoE objectives (e.g., execution latency, energy usage). By aligning applicationlevel performance needs with underlying model execution, Dora identifies the optimal balance between QoE and system efficiency, preventing unnecessary resource consumption while supporting existing edge AI software stacks with a few lines of code changes in APIs ( §3).
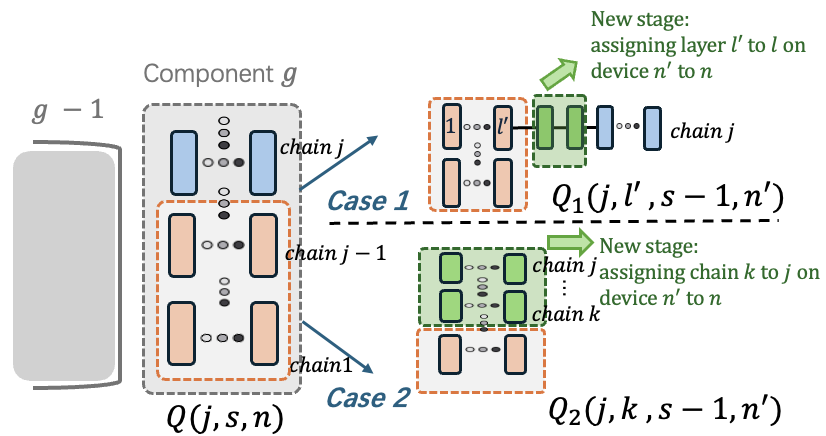
Overcoming the aforementioned challenges requires management over the interplay of heterogeneity, contention, and multi-objective requirements. Even without network effects or QoE constraints, identifying an optimal hybrid parallelism plan under heterogeneous compute resources is already NP-hard [26]. Network contention further exacerbates this challenge: computation dependencies that span shared links and irregular topologies can negate the gains of distributed computation, rendering compute-optimized plans ineffective. Dora tackles this interplay through: (i) a model partitioner that accounts for device heterogeneity to identify a compact set of QoE-compliant, compute-energy efficient candidate plans ( §4.1); and (ii) a contention-aware network scheduler that refines these candidates by adaptively allocating communication over networks to maximize computation-communication overlap, enabling Dora to select the plan that maximizes energy efficiency while satisfying user-specified QoE objectives ( §4.2).
Yet (offline) planning alone is insufficient, as edge environments are inherently dy
This content is AI-processed based on open access ArXiv data.