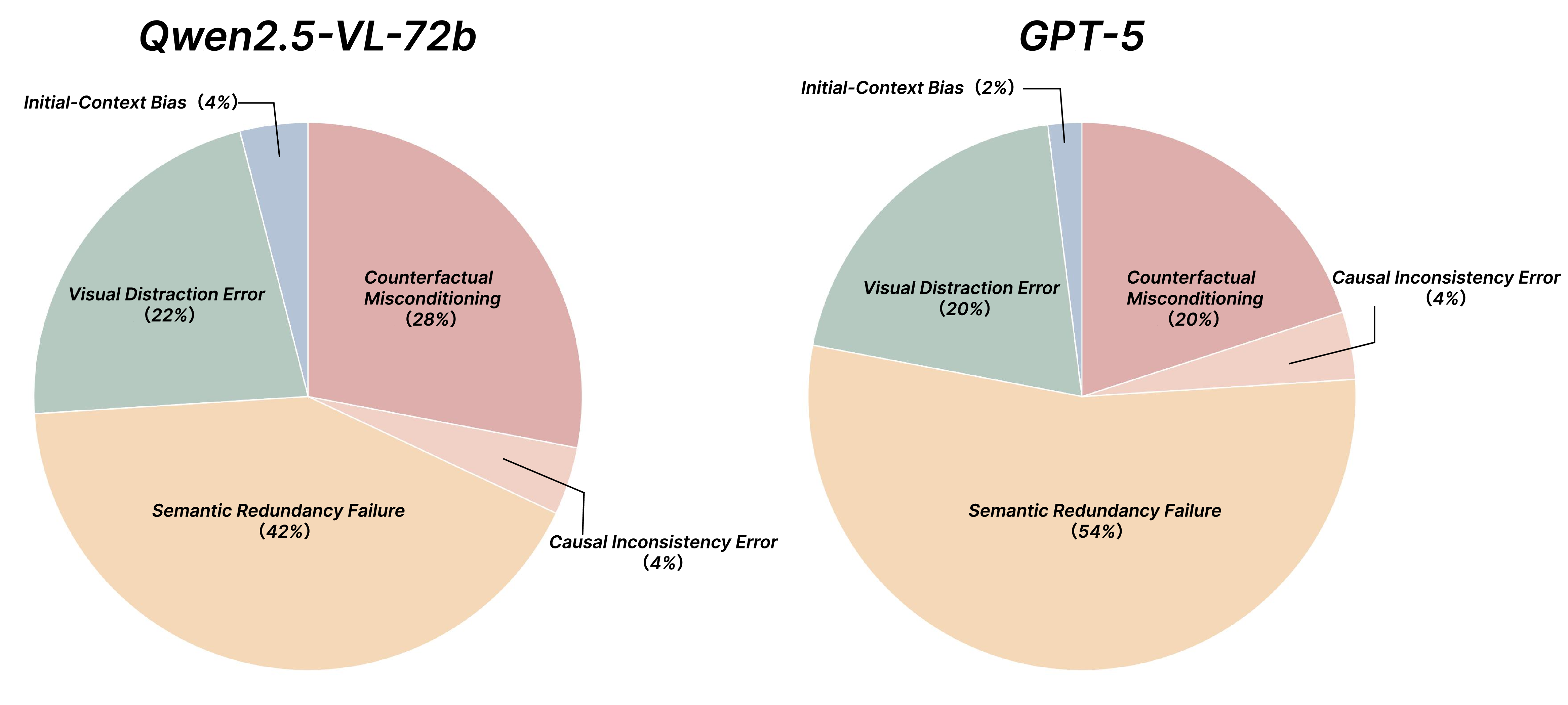
The ability to perform Chain-of-Thought (CoT) reasoning marks a major milestone for multimodal models (MMs), enabling them to solve complex visual reasoning problems. Yet a critical question remains: is such reasoning genuinely grounded in visual evidence and logically coherent? Existing benchmarks emphasize generation but neglect verification, i.e., the capacity to assess whether a reasoning chain is both visually consistent and logically valid. To fill this gap, we introduce MM-CoT, a diagnostic benchmark specifically designed to probe the visual grounding and logical coherence of CoT reasoning in MMs. Instead of generating freeform explanations, models must select the sole event chain that satisfies two orthogonal constraints: (i) visual consistency, ensuring all steps are anchored in observable evidence, and (ii) logical coherence, ensuring causal and commonsense validity. Adversarial distractors are engineered to violate one of these constraints, exposing distinct reasoning failures. We evaluate leading vision-language models on MM-CoT and find that even the most advanced systems struggle, i.e., revealing a sharp discrepancy between generative fluency and true reasoning fidelity. MM-CoT shows low correlation with existing benchmarks, confirming that it measures a unique combination of visual grounding and logical reasoning. This benchmark provides a foundation for developing future models that reason not just plausibly, but faithfully and coherently within the visual world.
💡 Deep Analysis
📄 Full Content
MM-CoT: A Benchmark for Probing Visual Chain-of-Thought Reasoning in
Multimodal Models
Jusheng Zhang1
Kaitong Cai1
Xiaoyang Guo1
Sidi Liu1
Qinhan Lv1
Ruiqi Chen1
Jing Yang1
Yijia Fan1
Xiaofei Sun2
Jian Wang3
Ziliang Chen1
Liang Lin1
Keze Wang1
1Sun Yat-sen University
2Alibaba Group
3Snap Inc.
Abstract
The ability to perform Chain-of-Thought (CoT) reasoning
marks a major milestone for multimodal models (MMs), en-
abling them to solve complex visual reasoning problems.
Yet a critical question remains: is such reasoning genuinely
grounded in visual evidence and logically coherent? Exist-
ing benchmarks emphasize generation but neglect verifica-
tion, i.e., the capacity to assess whether a reasoning chain is
both visually consistent and logically valid. To fill this gap,
we introduce MM-CoT, a diagnostic benchmark specifically
designed to probe the visual grounding and logical coher-
ence of CoT reasoning in MMs. Instead of generating free-
form explanations, models must select the sole event chain
that satisfies two orthogonal constraints: (i) visual consis-
tency, ensuring all steps are anchored in observable evi-
dence, and (ii) logical coherence, ensuring causal and com-
monsense validity. Adversarial distractors are engineered
to violate one of these constraints, exposing distinct reason-
ing failures. We evaluate leading vision–language models
on MM-CoT and find that even the most advanced systems
struggle, i.e., revealing a sharp discrepancy between gen-
erative fluency and true reasoning fidelity. MM-CoT shows
low correlation with existing benchmarks, confirming that
it measures a unique combination of visual grounding and
logical reasoning. This benchmark provides a foundation
for developing future models that reason not just plausibly,
but faithfully and coherently within the visual world.
1. Introduction
Large-scale Multimodal Models (MMs), especially Vision–
Language Models (VLMs) [1–3, 16, 25, 30, 42, 50, 57]
equipped with Chain-of-Thought (CoT) prompting [7, 22,
45, 48, 49], now generate remarkably detailed multi-step
explanations for visual tasks. Yet this apparent sophisti-
cation often masks a critical weakness: models can repli-
cate familiar reasoning templates without genuinely un-
derstanding the causal or visual structure underlying the
scene [30, 47, 51]. This gap between fluent narration and
true inferential depth raises a central question: are multi-
modal CoT explanations truly grounded in visual evidence,
and do they follow coherent, causally valid progressions?
Despite rapid progress, existing multimodal bench-
marks [4, 6, 11, 29, 31, 53, 55] overwhelmingly emphasize
generation. They reward models for producing plausible
answers or fluent rationales, but largely overlook verifica-
tion, i.e., the ability to assess whether a reasoning chain
is visually faithful and logically sound. This omission be-
comes evident when models produce narratives that refer-
ence nonexistent objects, misinterpret key visual cues, or
violate causal order [24, 33, 44]. Such failures indicate that
current multimodal CoT behaviors remain predominantly
pattern-driven rather than evidence-driven, implying that
correctness-based evaluations provide an incomplete, and
at times misleading, picture of visual reasoning ability.
To address this limitation, we introduce MM-CoT, a di-
agnostic benchmark that reframes multimodal CoT reason-
ing as a discriminative verification task rather than open-
ended generation. As illustrated in Fig. 1, the model is given
an image or video and must select the unique valid event
chain from a set of carefully constructed candidates. Each
chain follows a triadic structure A→B→C: an initiating
condition (A), a visually grounded mediating step (B), and
a logically entailed outcome (C). Distractors are adversari-
ally designed to violate exactly one of two orthogonal con-
straints: (i) visual consistency. Each step must be anchored
in observable evidence, and (ii) logical coherence. Causal
and temporal transitions must be physically and common-
sensically valid. Distractors are intentionally written to be
linguistically plausible, preventing models from exploiting
textual shortcuts and forcing genuine visual-and-causal ver-
ification. [20, 28, 39, 47, 57]
MM-CoT consists of 5616 image-based and 2,100
video-based reasoning instances. Each item includes a sin-
gle valid chain and K distractors (K=3 for images, K=4
for videos), enabling controlled evaluation of both percep-
tual grounding and multi-step causal reasoning across in-
creasing difficulty tiers. This design separates visual plau-
arXiv:2512.08228v1 [cs.CV] 9 Dec 2025
Image
Video
Firefighters may
cut water output
temporarily or
pause flow to
"stabilize the hose"
and reduce
vibration, then
continue spraying.
The dog stops in time
and avoids falling into
the water.
The dog stops in time
and avoids falling into
the water.
The nozzle of the fire
hose
slightly
loosen and shake
begins to
due
to high water pressure