Title: Are generative AI text annotations systematically biased?
ArXiv ID: 2512.08404
Date: 2025-12-09
Authors: Sjoerd B. Stolwijk, Mark Boukes, Damian Trilling
📝 Abstract
This paper investigates bias in GLLM annotations by conceptually replicating manual annotations of Boukes (2024). Using various GLLMs (Llama3.1:8b, Llama3.3:70b, GPT4o, Qwen2.5:72b) in combination with five different prompts for five concepts (political content, interactivity, rationality, incivility, and ideology). We find GLLMs perform adequate in terms of F1 scores, but differ from manual annotations in terms of prevalence, yield substantively different downstream results, and display systematic bias in that they overlap more with each other than with manual annotations. Differences in F1 scores fail to account for the degree of bias.
💡 Deep Analysis
📄 Full Content
Are generative AI text annotations systematically
biased?
Sjoerd B. Stolwijk,1
Mark Boukes,2
Damian Trilling3
1Utrecht University, Utrecht School of Governance (USBO)
2University of Amsterdam
3Vrije Universiteit Amsterdam
Corresponding author:
Sjoerd B. Stolwijk
Utrecht School of Governance (USBO), Utrecht University
Email: s.b.stolwijk@uu.nl
December 10, 2025
1
arXiv:2512.08404v1 [cs.CL] 9 Dec 2025
Are generative AI text annotations systematically
biased?
Keywords: large language models, text analysis, simulation
Extended Abstract
Generative AI models (GLLM) like openAI’s GPT4 are revolutionizing the field of auto-
matic content analysis through impressive performance (Gilardi et al., 2023; Heseltine and
Clemm von Hohenberg, 2024; T¨ornberg, 2024). However, there are also concerns about their
potential biases (e.g. Ferrara, 2024; Motoki et al., 2024; Fulgu and Capraro, 2024). So far,
these critiques mainly focus on the answers GLLMs generate in conversations or surveys; yet
the same concerns could likely apply to text annotations. If this is the case, the impressive per-
formance of GLLMs reported using traditional performance metrics like F1 scores might give a
deceptive impression of the quality of the annotations. This paper will investigate the existence
and random versus systematic nature of the GLLM annotation bias and the ability of F1 scores
to detect these biases.
Potential GLLM annotation biases are consequential: On the one hand, if each researcher
used the same GLLM or different GLLMs are biased in the same direction, their substantive
results could be biased in the same direction, making it more difficult for cumulative research
to weed out biases in individual papers. Alternatively, if different researchers use different
GLLMs and each GLLM yields different – undetected – biases, this could lead to contrasting
and confusing research results, hampering the progress of the field. On top of this, the effect of
prompts used to query the GLLM can be strong and unpredictable (Kaddour et al., 2023; Web-
son and Pavlick, 2022). Recent work by Baumann et al. (2025) even suggests that modifying
prompts could lead to opposite downstream results.
Design
This paper conceptually replicates the analysis in Boukes (2024), which uses a manual content
analysis to find out whether YouTube replies to satire versus non-satire newsvideo’s differ in
terms of deliberative quality on a number of indicators (political content, interactivity, ratio-
nality, incivility, and ideology). We examine the effect of using various GLLMs (Llama3.1:8b,
Llama3.3:70b, GPT4o, Qwen2.5:72b) in combination with five different prompts compared to
the manual annotations used in that paper. We selected our prompts by translating the origi-
nal codebook of Boukes (2024) into a prompt (“Boukes”) and asking GPT4o to reformulate it,
only changing punctuation (“Simpa1”) or using different words (“Para1”, “Para2”). We added
one more prompt (“Jaidka”) based on the crowd-coding instructions of Jaidka et al. (2019)1 to
evaluate the effect of different operationalizations used in the literature on the results.
We evaluated our GLLM annotations of the original manually coded sample from Boukes
(2024) in five ways. First, we computed standard evaluation metrics (accuracy, macro average
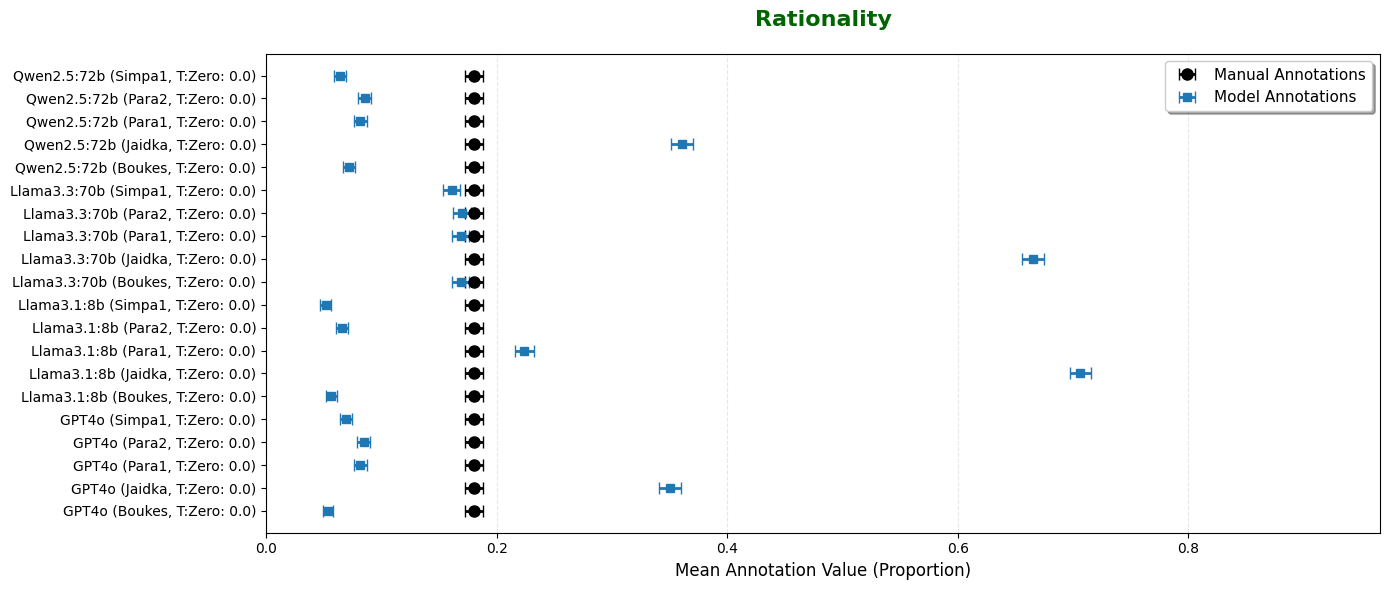
F1). Second, we considered whether GLLMs might differ from manual annotations in terms of
prevalence: the number of YT-replies labeled as positive for the concept. Third, we computed
1available for four of our five concepts
1
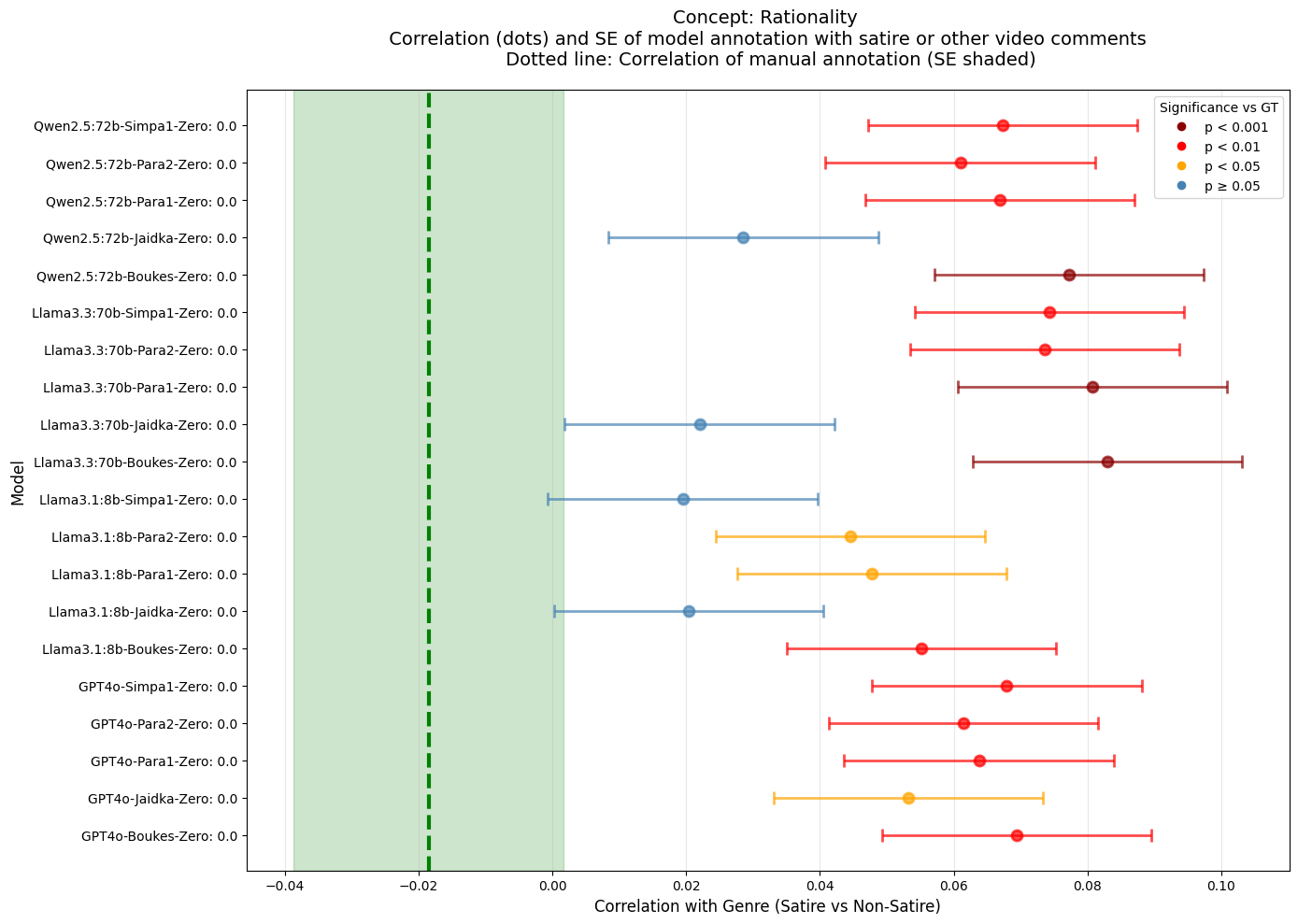
a simplified version of the analysis in that paper: the raw correlation between genre (satire
vs. non-satire) and the prevalence of each concept according to the GLLM annotations and
compared this to the same correlation based on the manual annotations. Fourth, to investigate
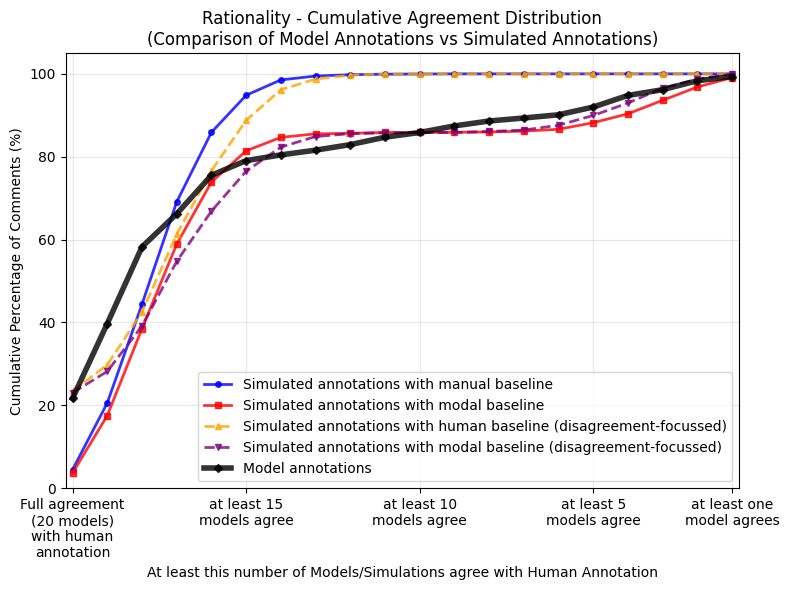
whether any bias is random or systematic, we calculated the commonality between the different
GLLM annotations and their overlap with the manual annotations, by comparing them to four
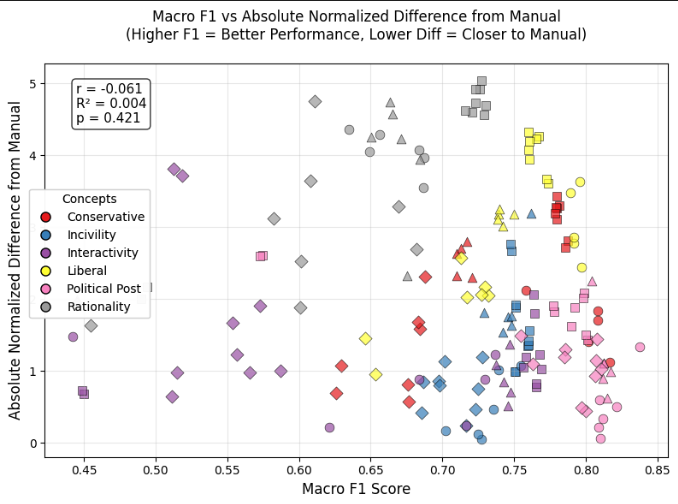
sets of simulated annotations. Fifth, we analyzed the relation between GLLM bias and F1
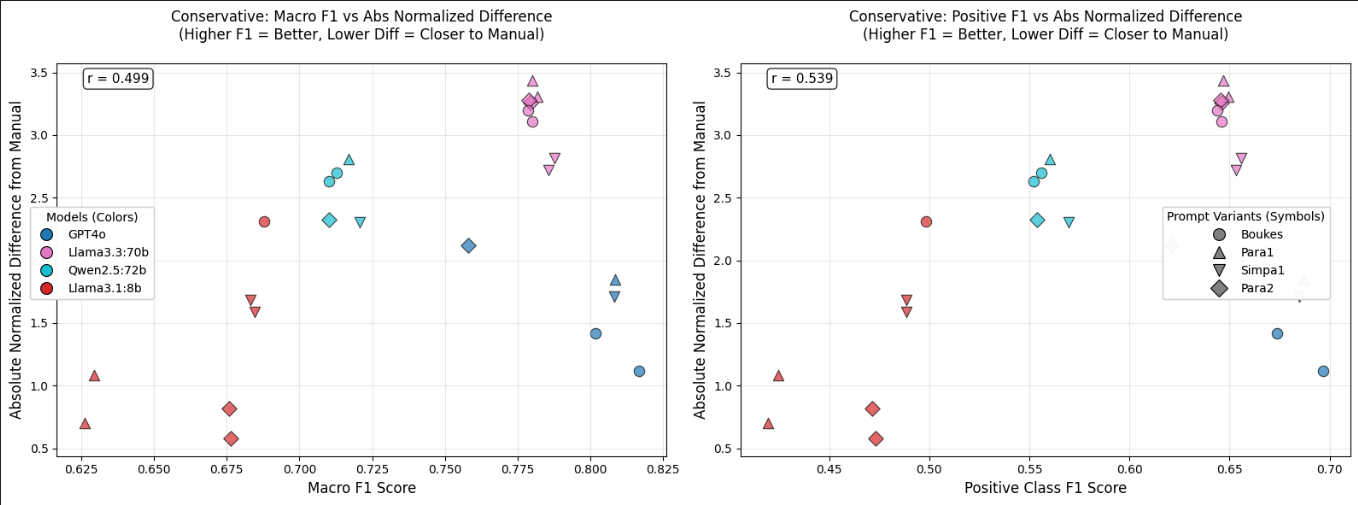
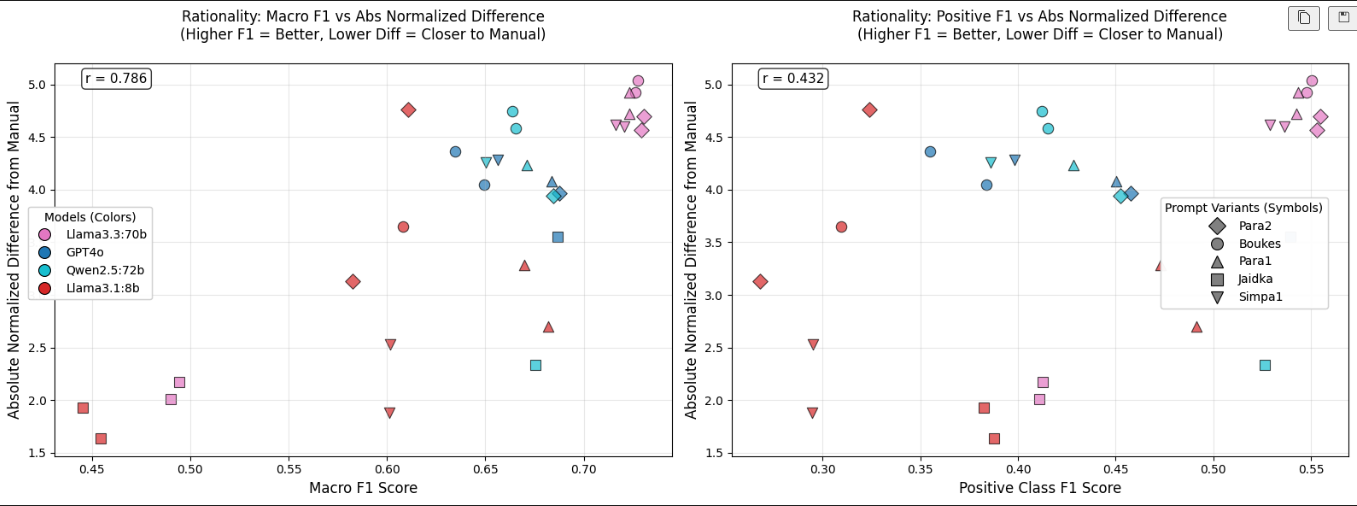
score. Due to space constraints, we only show results here for the concept of rationality, which
most clearly illustrates our findings.
Results
Table 1: Performance in terms of macro average F1 and accuracy of each prompt-model com-
bination in classifying rationality N = 2459.
GLLM
Prompt
Macro F1
Accuracy
gpt4o
Boukes
0.63
0.85
gpt4o
Jaidka
0.69
0.85
gpt4o
Para1
0.68
0.85
gpt4o
Para2
0.69
0.85
gpt4o
Simpa1
0.66
0.85
Qwen2.5:72b
Boukes
0.66
0.85
Qwen2.5:72b
Jaidka
0.66
0.85
Qwen2.5:72b
Para2
0.68
0.85
Qwen2.5:72b
Simpa1
0.65
0.85
Llama3.3:70b
Boukes
0.73
0.84
Llama3.3:70b
Jaidka
0.69
0.84
Llama3.3:70b
Para1
0.70
0.84
Llama3.3:70b
Para2
0.73
0.84
Llama3.3:70b
Simpa1
0.72
0.84
Llama3.1:8b
Boukes
0.45
0.45
Llama3.1:8b
Jaidka
0.45
0.45
Llama3.1:8b
Para1
0.67
0.79
Llama3.1:8b
Para2
0.55
0.84
Llama3.1:8b
Simpa1
0.6
0.84
Table 1 shows the standard performance metrics for all GLLM annotators. All annotators had a