Sensitive information leakage in code repositories has emerged as a critical security challenge. Traditional detection methods that rely on regular expressions, fingerprint features, and high-entropy calculations often suffer from high false-positive rates. This not only reduces detection efficiency but also significantly increases the manual screening burden on developers. Recent advances in large language models (LLMs) and multi-agent collaborative architectures have demonstrated remarkable potential for tackling complex tasks, offering a novel technological perspective for sensitive information detection. In response to these challenges, we propose Argus, a multi-agent collaborative framework for detecting sensitive information. Argus employs a three-tier detection mechanism that integrates key content, file context, and project reference relationships to effectively reduce false positives and enhance overall detection accuracy. To comprehensively evaluate Argus in real-world repository environments, we developed two new benchmarks, one to assess genuine leak detection capabilities and another to evaluate false-positive filtering performance. Experimental results show that Argus achieves up to 94.86% accuracy in leak detection, with a precision of 96.36%, recall of 94.64%, and an F1 score of 0.955. Moreover, the analysis of 97 real repositories incurred a total cost of only 2.2$. All code implementations and related datasets are publicly available at https://github.com/TheBinKing/Argus-Guard for further research and application.
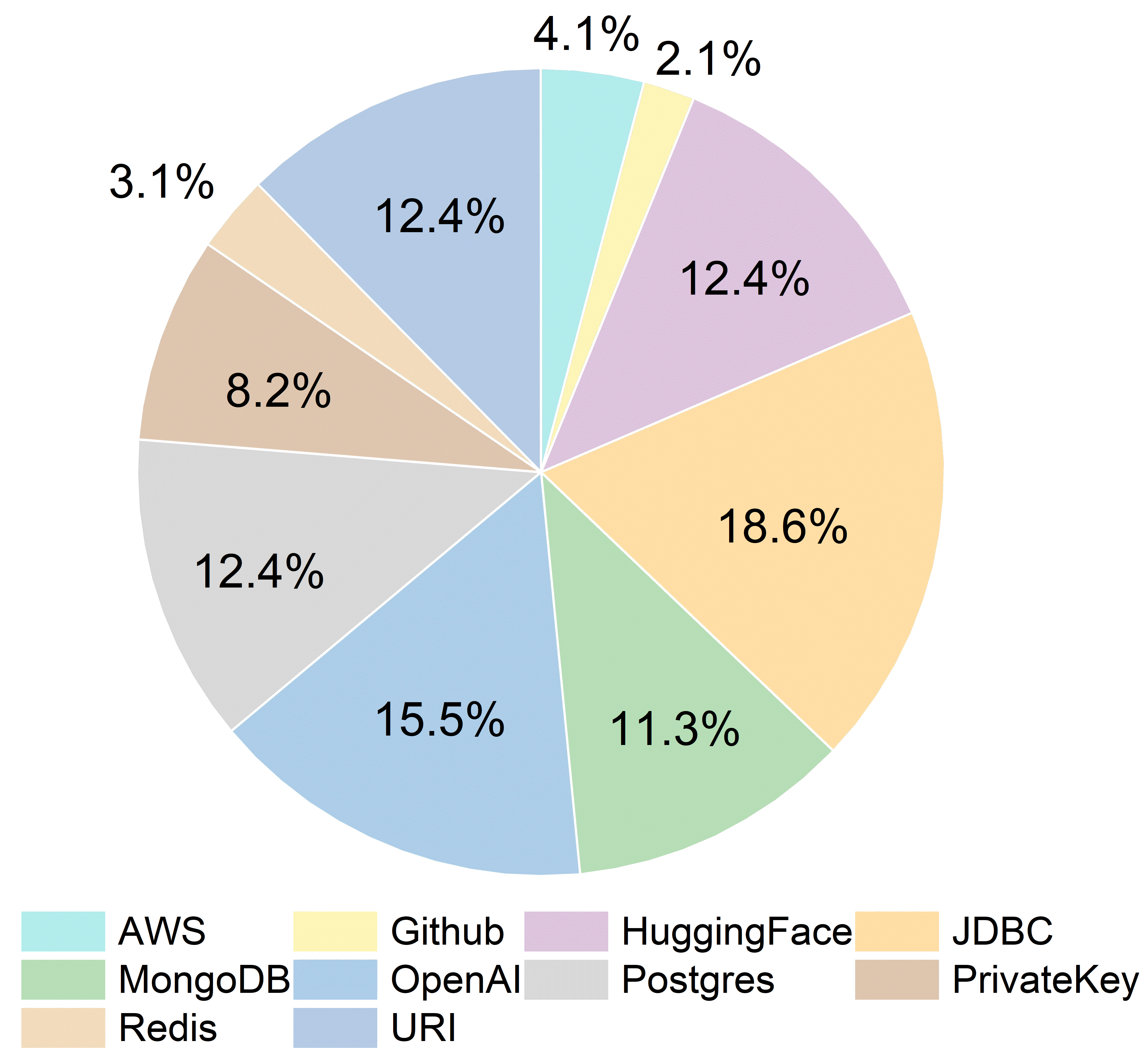
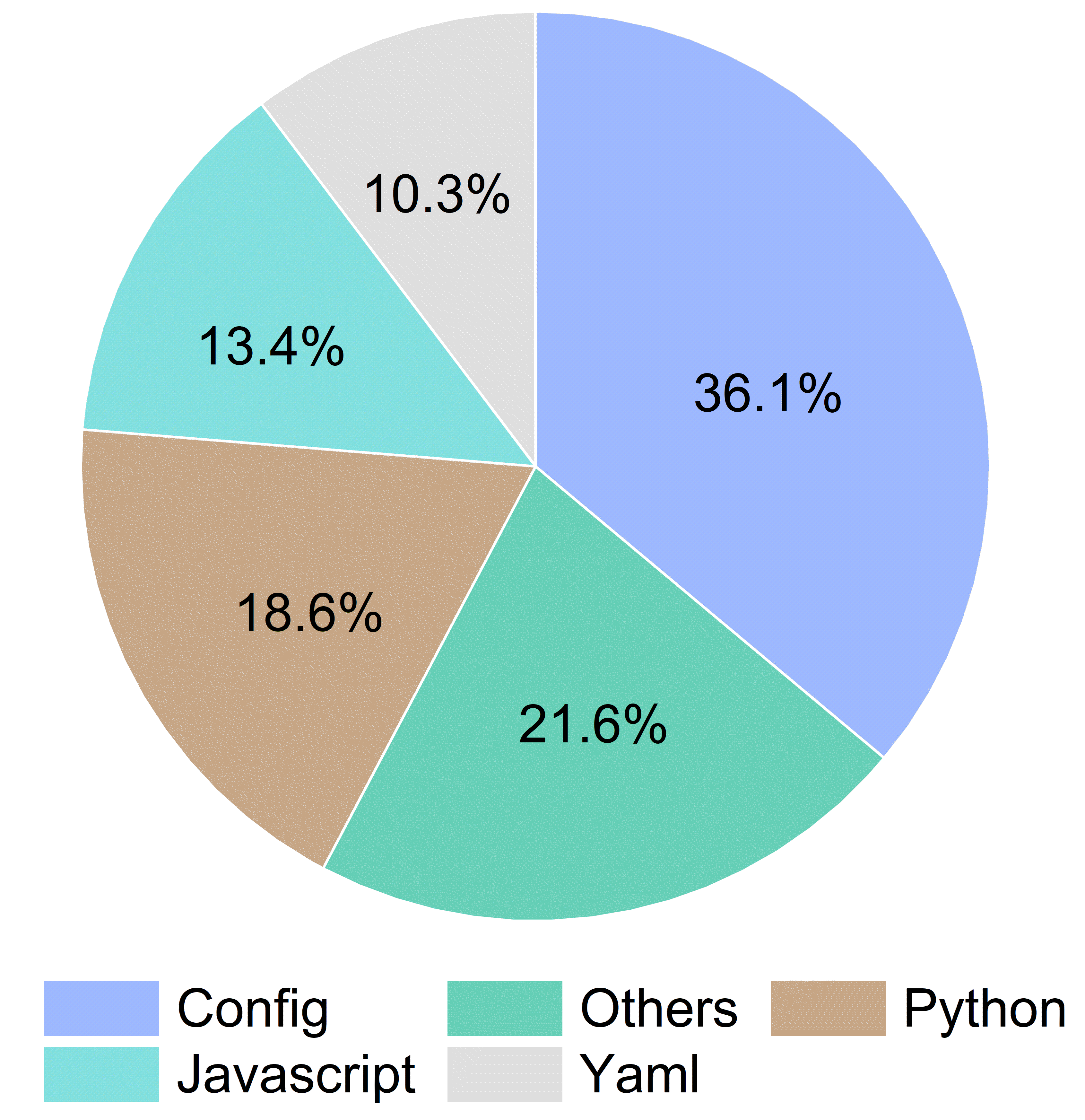
Public code repositories, such as GitHub, have become central platforms for developer collaboration and version control in modern software development. These platforms enable developers to efficiently share code, track issues, and manage versions rigorously, thereby significantly enhancing both development efficiency and code quality. However, their open nature also introduces new security challenges, particularly regarding the management and protection of sensitive information [23]. According to monitoring data from GitGuardian [9], sensitive information leakage incidents on GitHub reached 12.8 million in 2023-a 28% increase over 2022-with the trend continuing upward. These leaks primarily involve API keys, database credentials, private keys, and other critical data, posing serious risks not only to individual privacy but also to enterprises by exposing them to severe security vulnerabilities and potential economic losses [46].The paper How Bad Can It Git? Characterizing Secret Leakage in Public GitHub Repositories [28] discusses the prevalence of secret leakage in open-source Git repositories, highlighting the urgency of addressing this issue.
Current approaches to detecting sensitive information leaks can be broadly classified into two categories. The first comprises rulebased detection tools (e.g., Gitleaks and TruffleHog) that rely on regular expressions and entropy calculations [38]. The second involves machine learning methods designed to reduce false positives through model training. However, both approaches have inherent limitations. While rule-based tools offer extensive coverage, some tools have a false positive rate of over 80% [2], which substantially undermines their utility. As Chess and McGraw [4] have noted, “an excessively high false positive rate ultimately leads to 100% of leaks being overlooked because users will eventually disregard the detection results.” Conversely, machine learning methods [32], though effective in reducing false positives, lack a deep understanding of code semantics, rendering them less effective in managing complex contextual relationships.
In recent years, the advent of LLMs has opened a new technical pathway for sensitive information detection [12]. Compared to traditional methods, LLMs offer superior text comprehension, enabling them to deeply analyze code context and identify potential sensitive information. However, relying solely on LLMs presents challenges: they may struggle to precisely verify key formats and identify placeholders, and their output stability can diminish when processing lengthy texts. To overcome these limitations, the concept of “AI-empowered software engineering” has emerged. This approach leverages multiple AI agents working in collaboration to address complex tasks. The principle of “collaborative AI for SE” involves the coordinated operation of several AI agents, each compensating for the limitations of a single agent when tackling intricate problems. For instance, in tasks such as code review and generation, multi-agent systems have demonstrated significant advantages-such as reducing security vulnerabilities by 13% [29] when an LLM responsible for code generation collaborates with agents for static analysis and fuzz testing-while ensuring functional correctness. These findings underscore the potential of a collaborative multi-agent strategy in handling the diverse and highly accurate detection requirements of source code sensitive information.
Motivated by these insights, we propose a multi-agent sensitive information detection framework named Argus. This framework employs a three-tier detection mechanism that integrates key content, file context, and project reference relationships, effectively compensating for the limitations of a single LLM. Each agent focuses on a specific detection task, and through their coordinated efforts, the system achieves stable and precise detection outcomes. Additionally, we have developed a comprehensive evaluation dataset that encompasses common sensitive information scenarios found in open-source projects. Experimental results demonstrate that Argus attains a detection accuracy of 94.86% on this dataset, significantly outperforming existing methods.
The main contributions of this paper are as follows:
(1) We propose a novel three level detection mechanism that offers a comprehensive analysis of sensitive information, providing a fresh perspective on applying LLMs in the field of security detection. (2) We construct two benchmark datasets based on real-world code repository scenarios, covering a wide range of sensitive information types and usage scenarios, thereby establishing a unified standard for evaluating detection tools. In addition, we verify the validity of the secrets in each repository to mitigate potential security risks. (3) We design and implement a multi-agent sensitive information detection framework named Argus, which achieves a precision of 96.36% and a recall of 94.64% on the
This content is AI-processed based on open access ArXiv data.