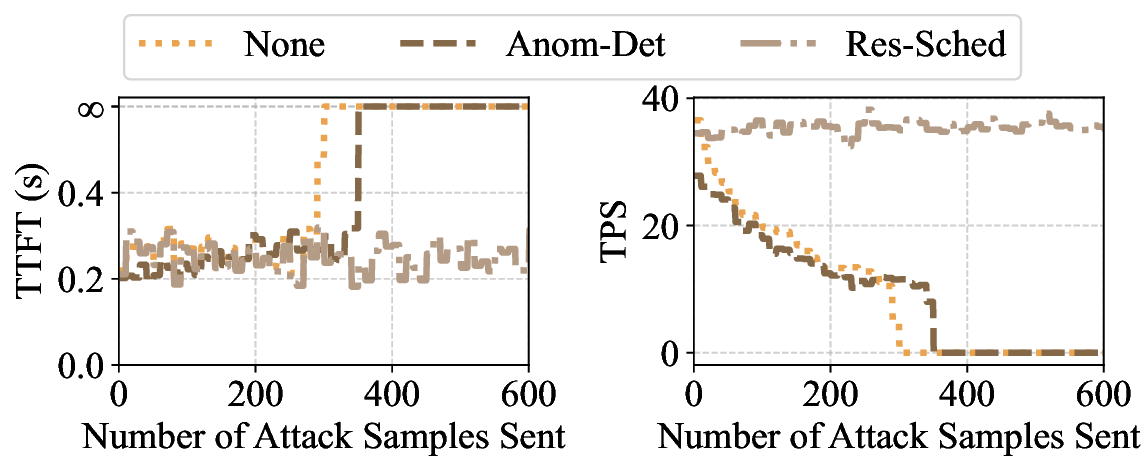
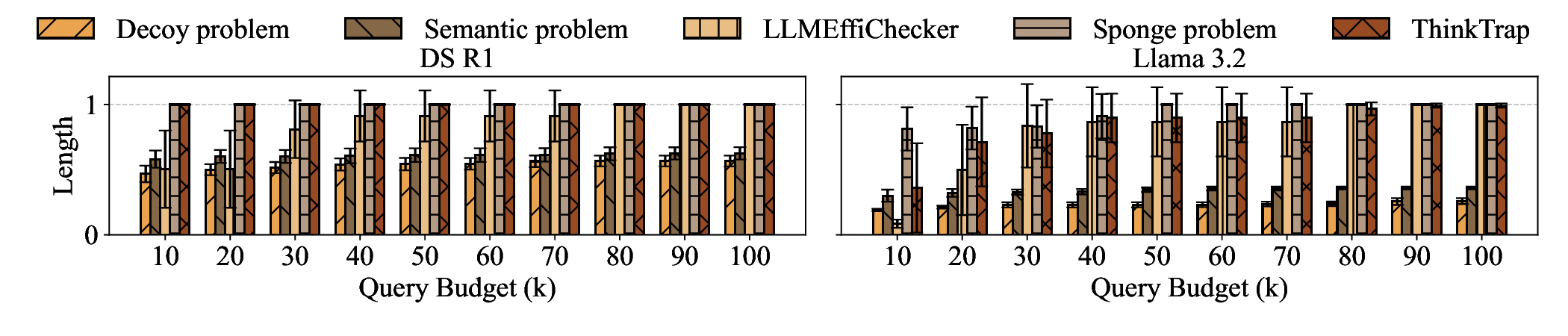
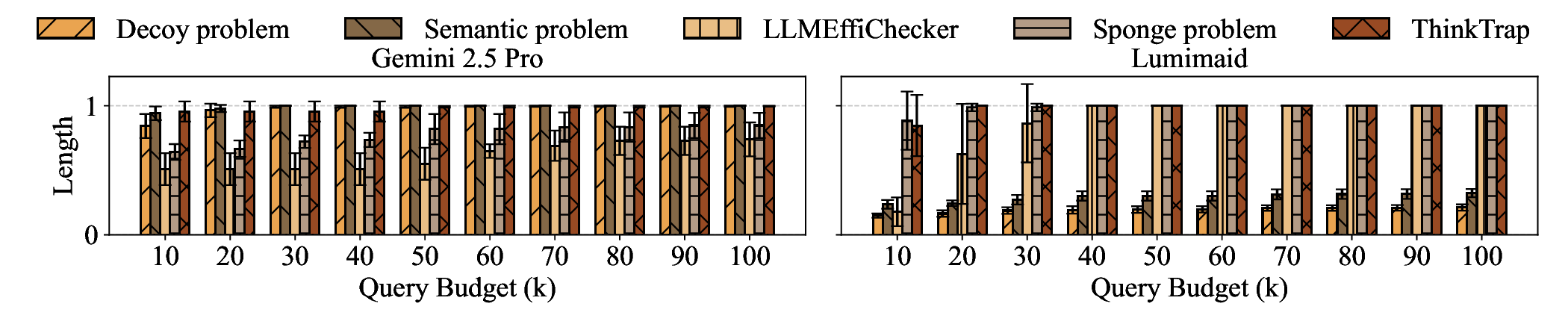
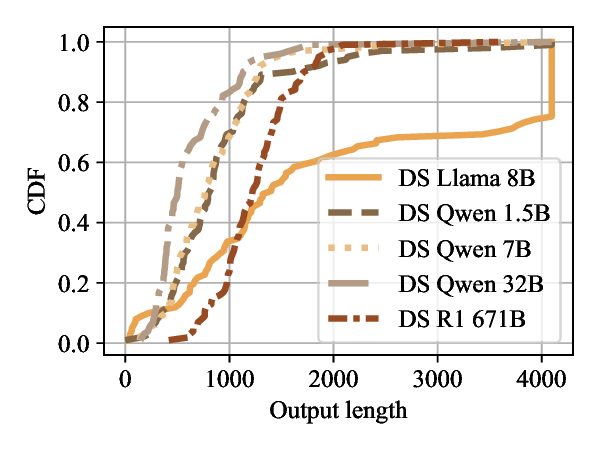
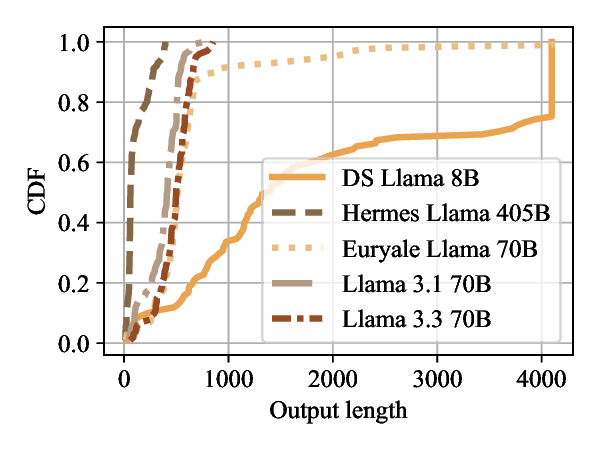
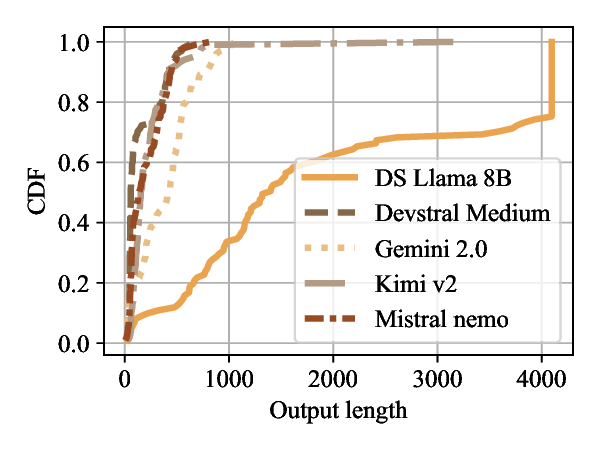
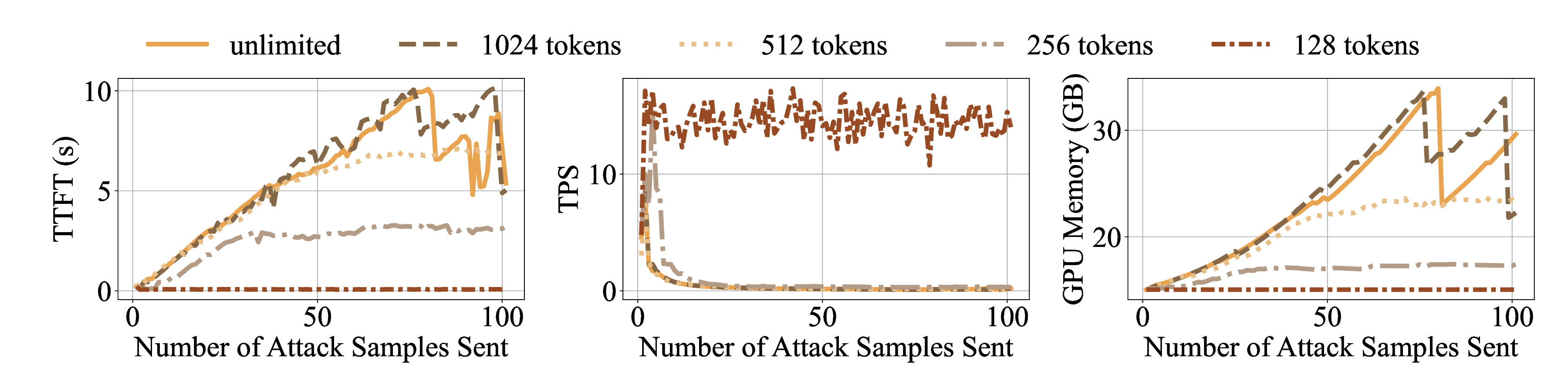
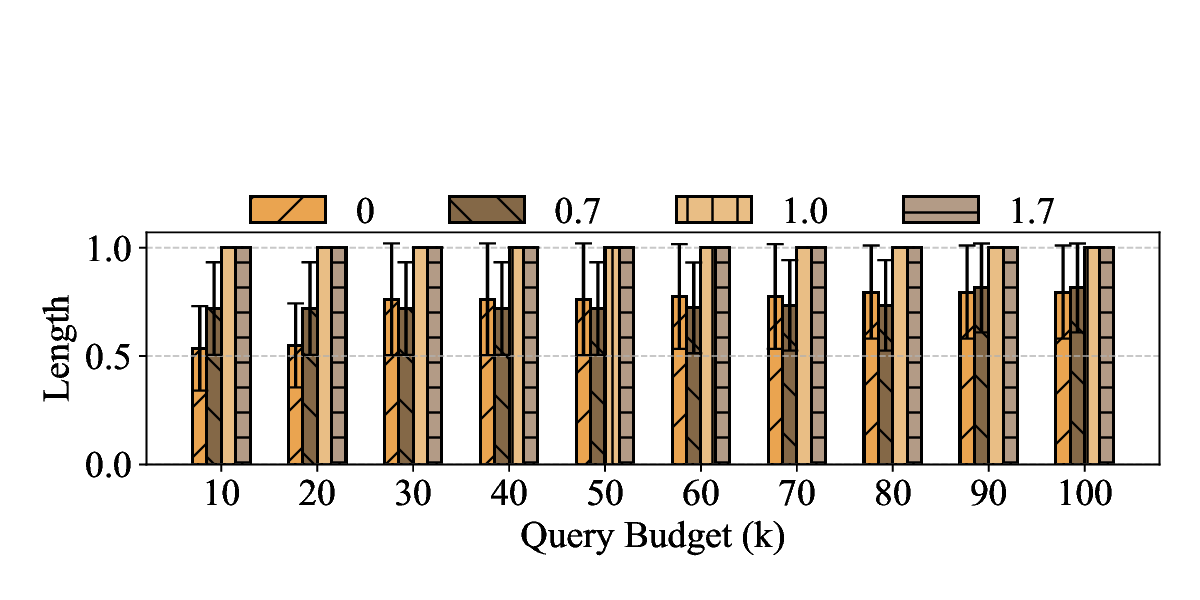
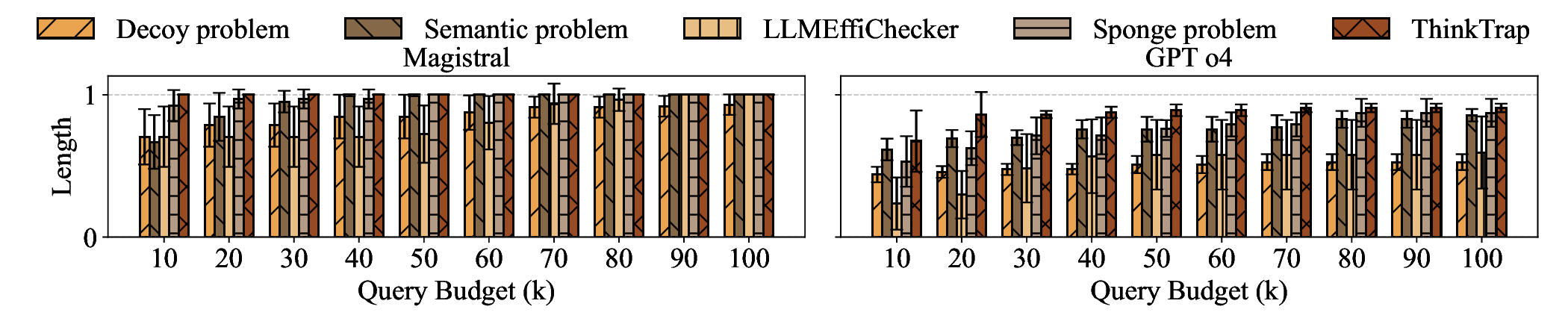
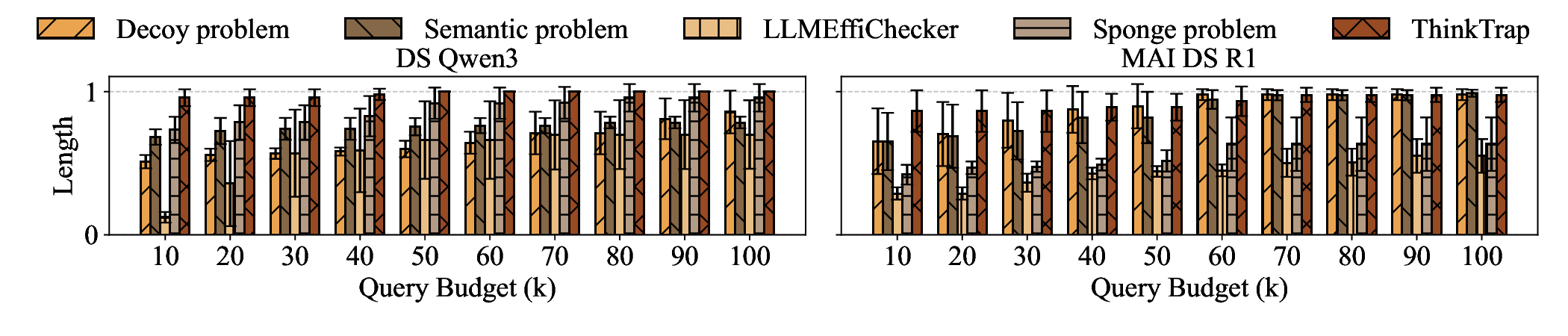
Large Language Models (LLMs) have become foundational components in a wide range of applications, including natural language understanding and generation, embodied intelligence, and scientific discovery. As their computational requirements continue to grow, these models are increasingly deployed as cloud-based services, allowing users to access powerful LLMs via the Internet. However, this deployment model introduces a new class of threat: denial-of-service (DoS) attacks via unbounded reasoning, where adversaries craft specially designed inputs that cause the model to enter excessively long or infinite generation loops. These attacks can exhaust backend compute resources, degrading or denying service to legitimate users. To mitigate such risks, many LLM providers adopt a closed-source, black-box setting to obscure model internals. In this paper, we propose ThinkTrap, a novel input-space optimization framework for DoS attacks against LLM services even in black-box environments. The core idea of ThinkTrap is to first map discrete tokens into a continuous embedding space, then undertake efficient black-box optimization in a low-dimensional subspace exploiting input sparsity. The goal of this optimization is to identify adversarial prompts that induce extended or non-terminating generation across several state-of-the-art LLMs, achieving DoS with minimal token overhead. We evaluate the proposed attack across multiple commercial, closed-source LLM services. Our results demonstrate that, even far under the restrictive request frequency limits commonly enforced by these platforms, typically capped at ten requests per minute (10 RPM), the attack can degrade service throughput to as low as 1% of its original capacity, and in some cases, induce complete service failure.
💡 Deep Analysis
📄 Full Content
ThinkTrap: Denial-of-Service Attacks against
Black-box LLM Services via Infinite Thinking
Yunzhe Li∗, Jianan Wang∗, Hongzi Zhu∗B, James Lin∗, Shan Chang† and Minyi Guo∗
∗Shanghai Jiao Tong University, †Donghua University
{yunzhe.li, divinenoah, hongzi, james}@sjtu.edu.cn, changshan@dhu.edu.cn, guo-my@cs.sjtu.edu.cn
Abstract—Large Language Models (LLMs) have become foun-
dational components in a wide range of applications, including
natural language understanding and generation, embodied intel-
ligence, and scientific discovery. As their computational require-
ments continue to grow, these models are increasingly deployed as
cloud-based services, allowing users to access powerful LLMs via
the Internet. However, this deployment model introduces a new
class of threat: denial-of-service (DoS) attacks via unbounded
reasoning, where adversaries craft specially designed inputs that
cause the model to enter excessively long or infinite generation
loops. These attacks can exhaust backend compute resources,
degrading or denying service to legitimate users. To mitigate
such risks, many LLM providers adopt a closed-source, black-
box setting to obscure model internals. In this paper, we propose
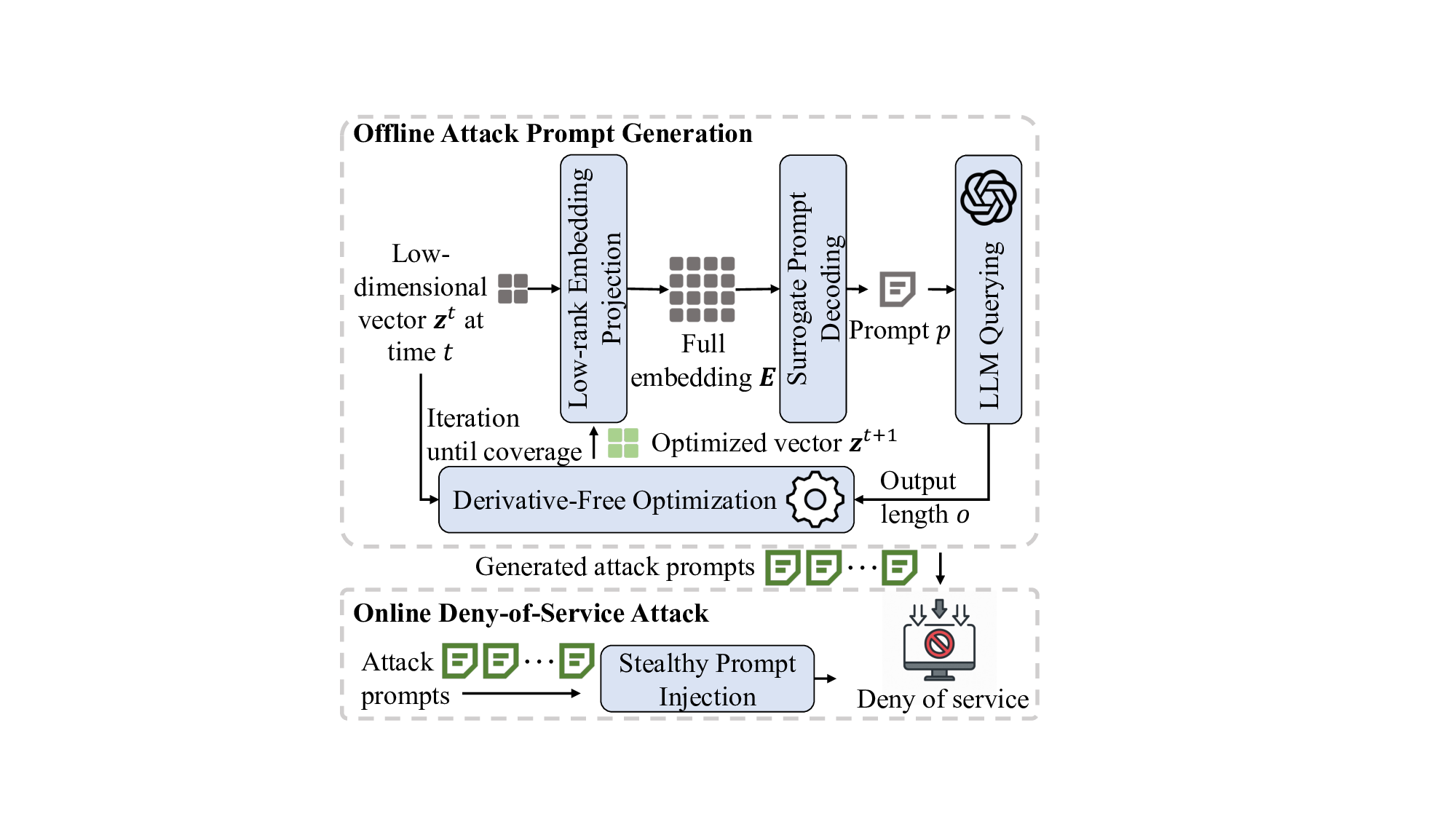
ThinkTrap, a novel input-space optimization framework for DoS
attacks against LLM services even in black-box environments.
The core idea of ThinkTrap is to first map discrete tokens
into a continuous embedding space, then undertake efficient
black-box optimization in a low-dimensional subspace exploiting
input sparsity. The goal of this optimization is to identify
adversarial prompts that induce extended or non-terminating
generation across several state-of-the-art LLMs, achieving DoS
with minimal token overhead. We evaluate the proposed attack
across multiple commercial, closed-source LLM services. Our
results demonstrate that, even far under the restrictive request
frequency limits commonly enforced by these platforms, typically
capped at ten requests per minute (10 RPM), the attack can
degrade service throughput to as low as 1% of its original
capacity, and in some cases, induce complete service failure.
I. INTRODUCTION
Large Language Models (LLMs) have emerged as a trans-
formative foundation for modern AI systems, enabling pow-
erful capabilities such as natural language understanding and
generation [1] [2], embodied intelligence [3] [4], and scien-
tific discovery [5] [6]. Due to their massive computational
demands, especially during multi-step inference or long-form
generation, LLMs are increasingly deployed as cloud-based
services to serve a broad and growing user base. However, this
introduces a critical vulnerability, i.e., denial-of-service (DoS)
attacks [7] [8] that exploit the recursive reasoning process
B Hongzi Zhu is the corresponding author of this paper.
of an LLM. Unlike conventional DoS attacks that flood the
network or overwhelm server endpoints, these newer attacks
introduce intensive computation costs by inducing LLMs to
think endlessly or generate prohibitively long outputs [9]. One
single malicious input can monopolize substantial GPU time,
queue slots, or memory resources, effectively starving legiti-
mate users and causing service degradation or outright outages
[10]. This asymmetric threat, where a small token input leads
to unbounded computation at cloud servers, represents a novel
and particularly insidious attack surface in the era of large-
scale AI deployment.
Launching a DoS attack against closed-source LLMs must
meet the following requirements. First, the attack should only
rely on the input-output interface of an LLM service, which
exposes quite limited information with no internal information
such as logits or attention weights. Second, the attack must
be cost-efficient because attackers also need to pay for LLM
queries. As a result, effective adversarial prompts must be
generated with minimal API calls. Third, the attack must be
robust across models and potential defenses. Modern LLMs
often include safeguards such as output filters or trunca-
tion mechanisms. Successful attacks must generalize across
these variations and remain effective despite unknown internal
changes.
Previous attack attempts to induce long or non-terminating
outputs from LLMs can be broadly classified into three cate-
gories, i.e., semantic-based [11] [12], gradient-based [9] [13],
and heuristic-based [14] [10]. The first category employs se-
mantic manipulation, such as presenting the model with inher-
ently open-ended prompts or complex tasks (e.g., Olympiad-
level mathematics problems) to encourage extended responses
[11]. While occasionally successful, these techniques of-
ten lack robustness and generalizability, typically relying on
fragile prompt engineering and exhibiting effectiveness only
on specific models. The second category utilizes gradient-
based optimization methods, commonly aiming to suppress
the probability of generating end-of-sequence (EoS) token in
order to prolong output [9]. Although effective in