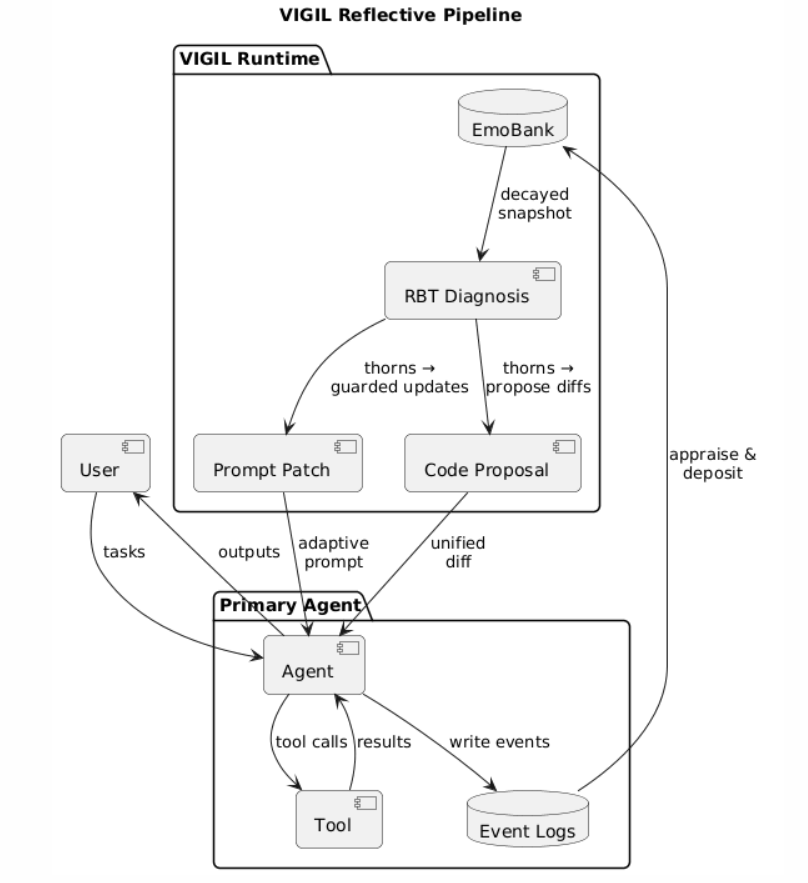
Agentic LLM frameworks promise autonomous behavior via task decomposition, tool use, and iterative planning, but most deployed systems remain brittle. They lack runtime introspection, cannot diagnose their own failure modes, and do not improve over time without human intervention. In practice, many agent stacks degrade into decorated chains of LLM calls with no structural mechanisms for reliability. We present VIGIL (Verifiable Inspection and Guarded Iterative Learning), a reflective runtime that supervises a sibling agent and performs autonomous maintenance rather than task execution. VIGIL ingests behavioral logs, appraises each event into a structured emotional representation, maintains a persistent EmoBank with decay and contextual policies, and derives an RBT diagnosis that sorts recent behavior into strengths, opportunities, and failures. From this analysis, VIGIL generates both guarded prompt updates that preserve core identity semantics and read only code proposals produced by a strategy engine that operates on log evidence and code hotspots. VIGIL functions as a state gated pipeline. Illegal transitions produce explicit errors rather than allowing the LLM to improvise. In a reminder latency case study, VIGIL identified elevated lag, proposed prompt and code repairs, and when its own diagnostic tool failed due to a schema conflict, it surfaced the internal error, produced a fallback diagnosis, and emitted a repair plan. This demonstrates meta level self repair in a deployed agent runtime.
• Adaptation Layer -generates prompt updates and code patch proposals grounded in diagnostic evidence.
• Orchestration Layer -enforces a gated execution model where each stage must complete before the next begins.
Together, these layers form a closed-loop system for introspection and selfmaintenance. VIGIL does not operate autonomously in the task space-it operates autonomously in the maintenance space, producing interpretable, recoverable, and reproducible artifacts with each cycle.
Agentic LLMs increasingly operate in environments that demand robustness, reliability, and continuity across tasks. However, most agent stacks lack the structural machinery to observe their own failures or adapt based on evidence. Prompt chains retry failures without diagnosis. Tool wrappers crash silently. “Improvement” often means a developer hand-edits YAML or prompt templates based on intuition.
VIGIL is designed to change that. Its premise is simple: if an agent can observe its own behavior, summarize its outcomes, and reflect on failure modes using structured memory, it can generate better adaptations. VIGIL makes this reflective capacity explicit and repeatable.
A full VIGIL run operates over a single pass through recent logs (typically 12-24 hours of events). The lifecycle proceeds as follows:
Ingest Events. Behavioral logs from the target agent are parsed and windowed by timestamp.
Appraise Emotions. Each event is transformed into an affective representation using deterministic heuristics (e.g., success → relief, delay → anxiety).
Deposit into EmoBank. Emotions are persisted with contextual metadata (valence, intensity, timestamp, cause).
Diagnose RBT. The recent emotional state and events are analyzed to extract Roses (successes to preserve), Buds (latent opportunities), and Thorns (failures to repair).
Generate Adaptations. Based on the diagnosis, VIGIL proposes changes to the agent’s prompt and codebase:
• Prompt updates are written into a dedicated adaptive section.
• Code suggestions are emitted as unified diffs with human-readable PR notes.
- Log and Emit. All artifacts (summaries, diffs, emotions, and patch proposals) are persisted under versioned paths for auditability.
VIGIL is not continuous-it is episodic. Each run processes a bounded window of experience, emits adaptations, and exits cleanly. This enables human review and integration into CI/CD pipelines, multi-agent swarms, or persistent agents with upgrade cycles.
Rather than binding directly to the agent’s internal loop, VIGIL operates externally via:
• Log Surveillance -passively reads JSONL event logs without modifying execution.
• Prompt Diffing -proposes updated prompt files but never alters the core-identity block.
• Code Review Proxy -scans the agent repo and produces patch proposals without file mutation.
This isolation ensures that VIGIL does not interfere with production systems and can be run safely as a background process, scheduler task, or reflection daemon.
Figure 1 illustrates the architecture of VIGIL and its interaction with the target agent (Robin-A). The system is composed of three major modules: the reflective runtime (yellow), the target agent (blue), and the file-based input/output layer (gray).
VIGIL operates entirely on structured event logs produced by the target agent. Each event is written as a line in a JSONL file with the following schema:
“ts”: “2025-10-31T23:59:59Z”, “kind”: “reminder.toast”, “status”: “delay”, “payload”: { “delayed_by_sec”: 97, “scheduled_utc”: “…” } } The system reads up to 500 recent events within a configurable window (typically 24 hours), filtering by timestamp. This provides VIGIL with a bounded slice of recent agent behavior.
Each event is transformed into an affective state via the appraise event() function. This process uses deterministic heuristics (not an LLM) to compute:
• emotion: a discrete label (e.g., frustration, pride, relief, curiosity)
• valence: an integer in {-1, 0, 1} representing emotional direction
• intensity: a float [0, 1] scaled by payload features (e.g., delay magnitude)
• cause: a human-readable string such as reminder.toast:delay For example, an event with status=“fail” and a delay of 180 seconds might map to frustration with valence -1 and intensity 0.9.
VIGIL maintains a lightweight affective memory called EmoBank, which stores structured appraisals of agent events over time. Each entry represents a discrete emotional evaluation-such as frustration over a failed tool call-with associated metadata including valence, intensity, and cause. These appraisals are appended to a persistent JSONL log and accessed via a virtual decay mechanism to enable time-sensitive summarization.
Data Model. Each appraisal entry is stored as: {“ts”: “…Z”, “emotion”: “frustration”, “intensity”: 0.7, “valence”: -0.6, “cause”: “reminder.toast:delay”, “episode”: “…”} The episode field is a stable hash derived from the cause string, grouping related en
This content is AI-processed based on open access ArXiv data.