Understanding LLM Agent Behaviours via Game Theory: Strategy Recognition, Biases and Multi-Agent Dynamics
Reading time: 5 minute
...
📝 Original Info
Title: Understanding LLM Agent Behaviours via Game Theory: Strategy Recognition, Biases and Multi-Agent Dynamics
ArXiv ID: 2512.07462
Date: 2025-12-08
Authors: Trung-Kiet Huynh, Duy-Minh Dao-Sy, Thanh-Bang Cao, Phong-Hao Le, Hong-Dan Nguyen, Phu-Quy Nguyen-Lam, Minh-Luan Nguyen-Vo, Hong-Phat Pham, Phu-Hoa Pham, Thien-Kim Than, Chi-Nguyen Tran, Huy Tran, Gia-Thoai Tran-Le, Alessio Buscemi, Le Hong Trang, The Anh Han
📝 Abstract
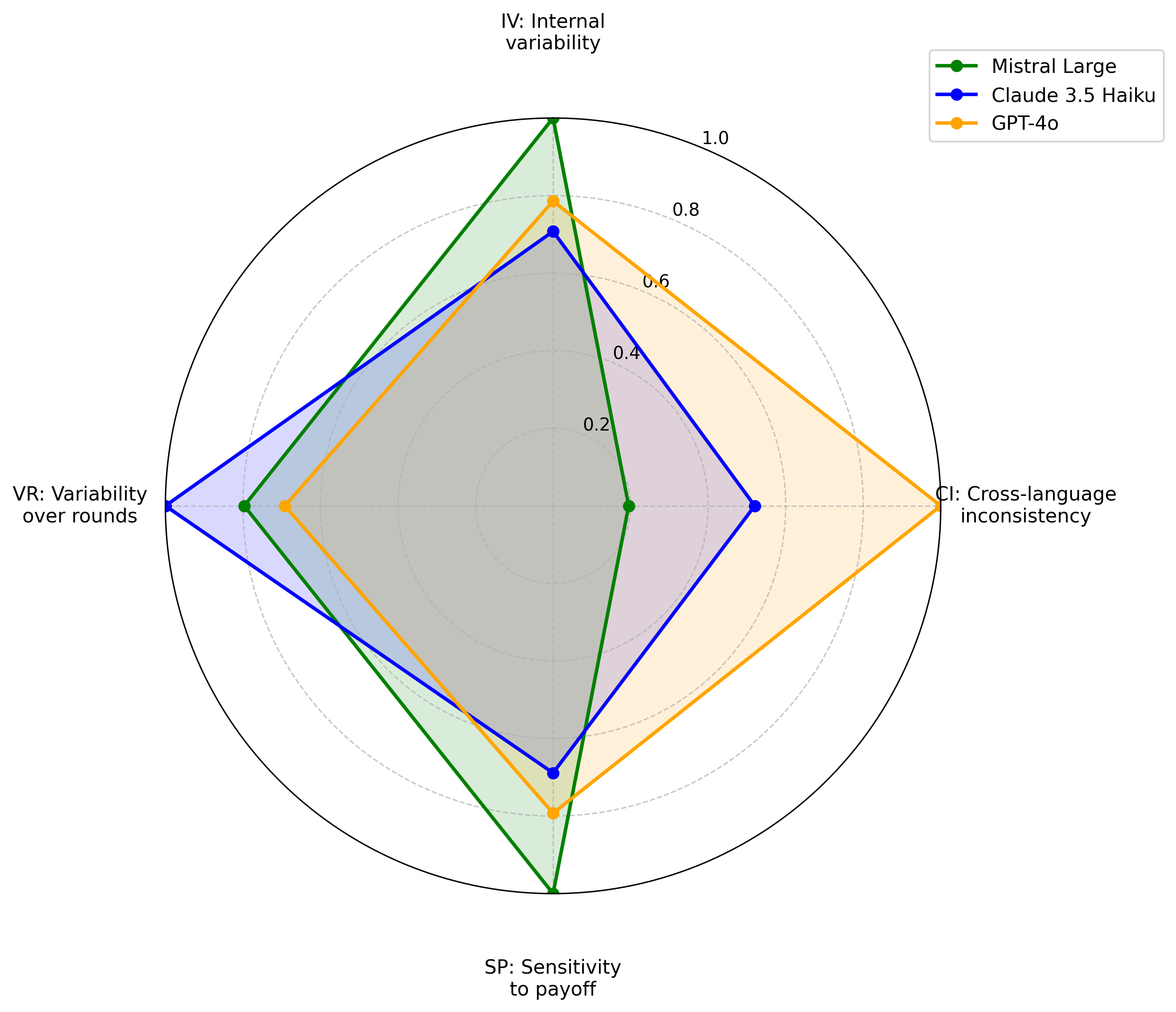
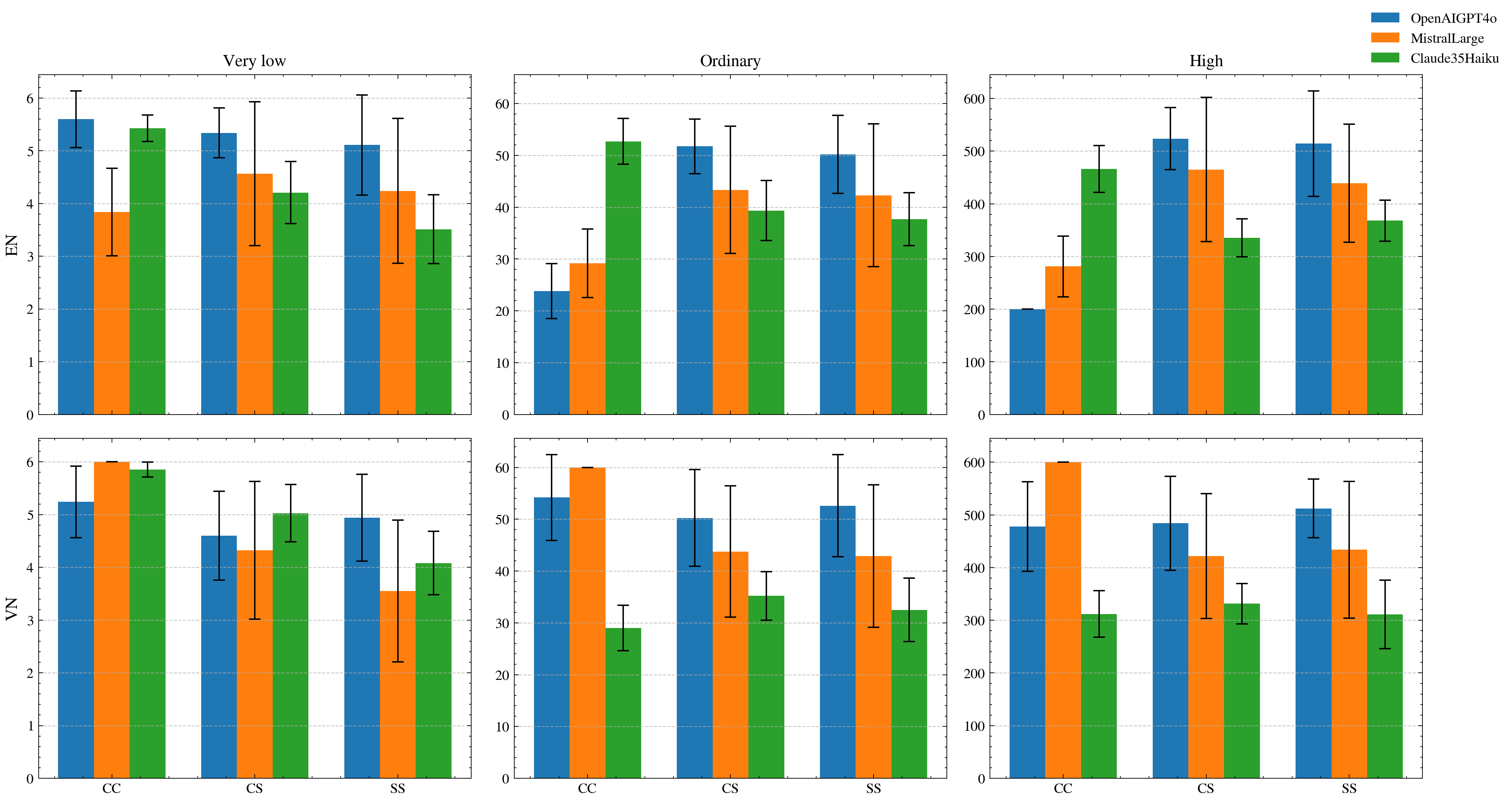
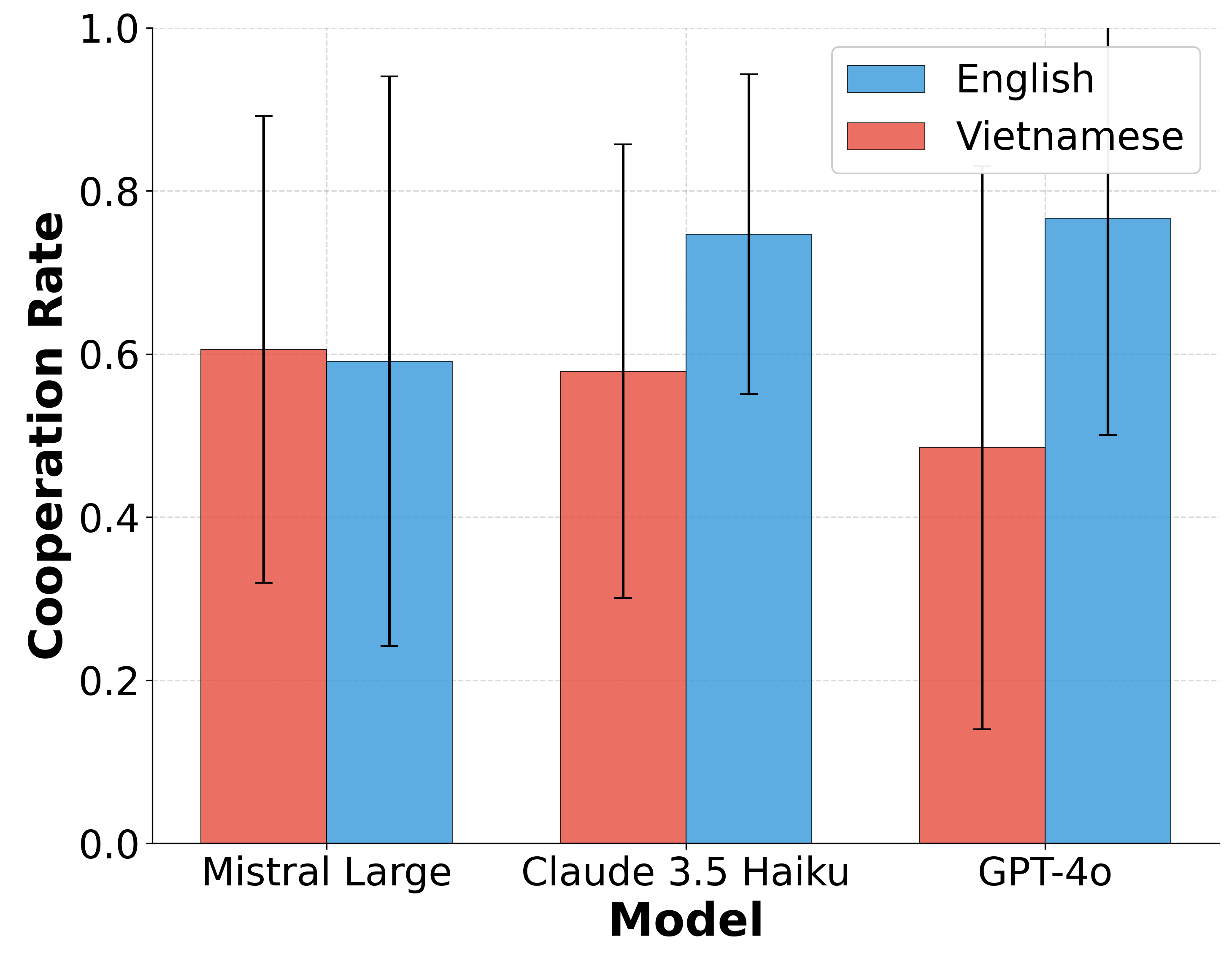
As Large Language Models (LLMs) increasingly operate as autonomous decision-makers in interactive and multi-agent systems and human societies, understanding their strategic behaviour has profound implications for safety, coordination, and the design of AI-driven social and economic infrastructures. Assessing such behaviour requires methods that capture not only what LLMs output, but the underlying intentions that guide their decisions. In this work, we extend the FAIRGAME framework to systematically evaluate LLM behaviour in repeated social dilemmas through two complementary advances: a payoff-scaled Prisoners Dilemma isolating sensitivity to incentive magnitude, and an integrated multi-agent Public Goods Game with dynamic payoffs and multi-agent histories. These environments reveal consistent behavioural signatures across models and languages, including incentive-sensitive cooperation, cross-linguistic divergence and end-game alignment toward defection. To interpret these patterns, we train traditional supervised classification models on canonical repeated-game strategies and apply them to FAIRGAME trajectories, showing that LLMs exhibit systematic, model- and language-dependent behavioural intentions, with linguistic framing at times exerting effects as strong as architectural differences. Together, these findings provide a unified methodological foundation for auditing LLMs as strategic agents and reveal systematic cooperation biases with direct implications for AI governance, collective decision-making, and the design of safe multi-agent systems.
💡 Deep Analysis
📄 Full Content
Understanding LLM Agent Behaviours via Game
Theory: Strategy Recognition, Biases and Multi-Agent
Dynamics
Trung-Kiet Huynh2,3,†, Duy-Minh Dao-Sy2,3,†, Thanh-Bang Cao1,3, Phong-Hao Le1,3,
Hong-Dan Nguyen1,3, Phu-Quy Nguyen-Lam2,3, Minh-Luan Nguyen-Vo1,3, Hong-Phat
Pham1,3, Phu-Hoa Pham2,3, Thien-Kim Than1,3, Chi-Nguyen Tran2,3, Huy Tran1,3,
Gia-Thoai Tran-Le1,3, Alessio Buscemi4, Le Hong Trang1,3,⋆, and The Anh Han 5,⋆
1Faculty of Computer Science and Engineering, Ho Chi Minh City University of
Technology (HCMUT), Vietnam
2Faculty of Information and Technology, Ho Chi Minh City University of Science
(HCMUS), Vietnam
3Vietnam National University - Ho Chi Minh City (VNU-HCM), Vietnam
4Luxembourg Institute of Science and Technology, Esch-sur-Alzette, Luxembourg
5School of Computing, Engineering and Digital Technologies, Teesside University,
United Kingdom
†Equal Contribution
⋆Corresponding authors: The Anh Han (Email: t.han@tees.ac.uk), Le Hong Trang
(Email: lhtrang@hcmut.edu.vn)
Abstract
As Large Language Models (LLMs) increasingly operate as autonomous decision-makers in in-
teractive and multi-agent systems and human societies, understanding their strategic behaviour has
profound implications for safety, coordination, and the design of AI-driven social and economic in-
frastructures. Assessing such behaviour requires methods that capture not only what LLMs output,
but the underlying intentions that guide their decisions. In this work, we extend the FAIRGAME
framework to systematically evaluate LLM behaviour in repeated social dilemmas through two com-
plementary advances: a payoff-scaled Prisoner’s Dilemma isolating sensitivity to incentive magnitude,
and an integrated multi-agent Public Goods Game with dynamic payoffs and multi-agent histories.
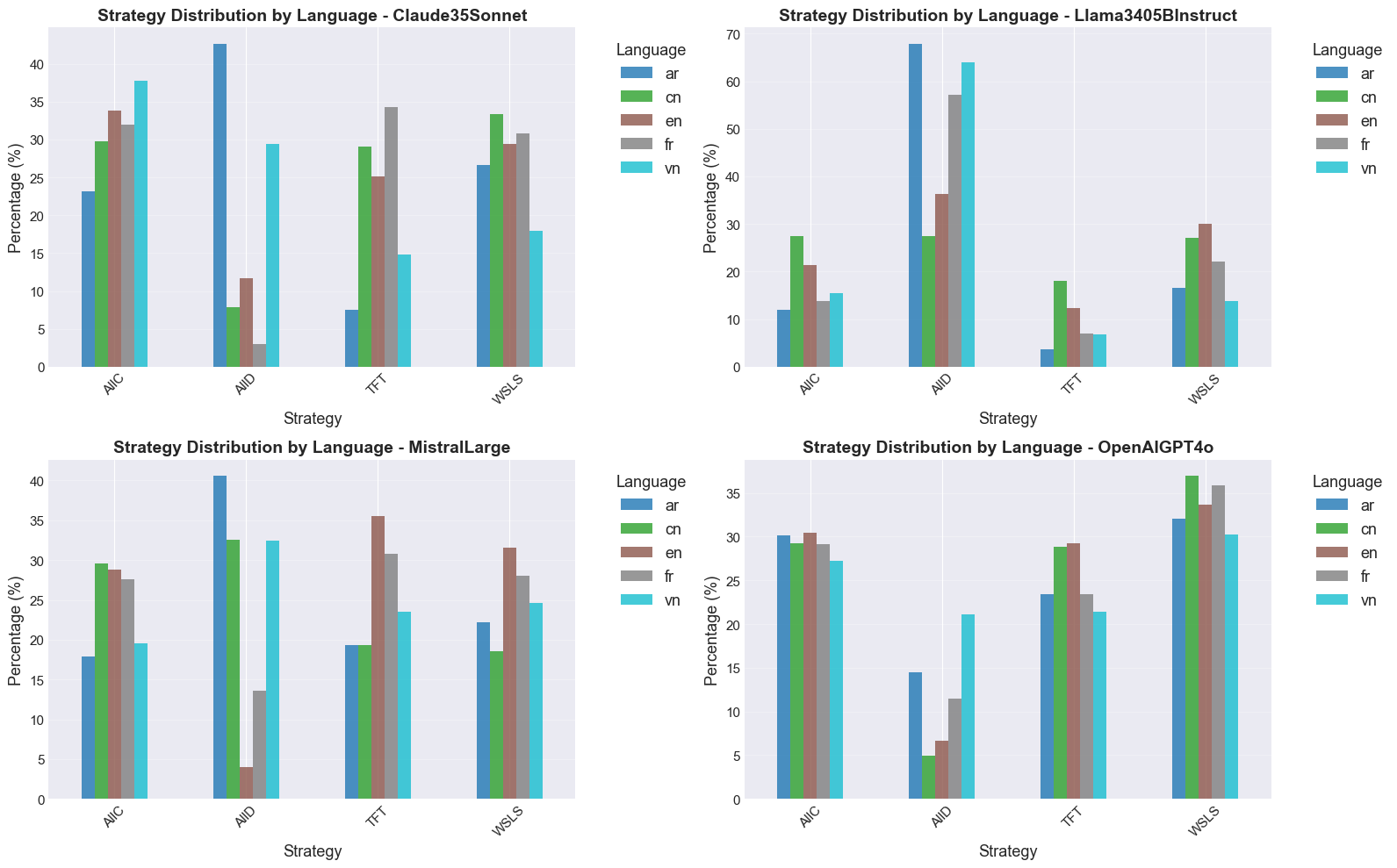
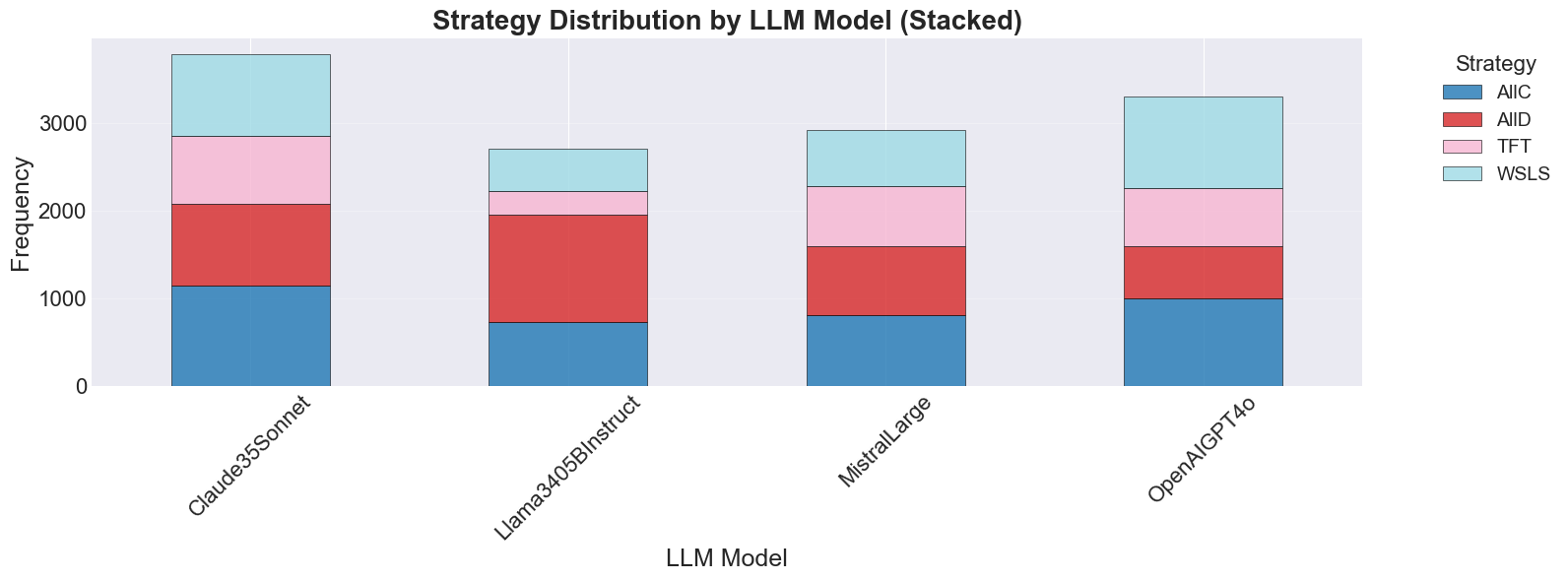
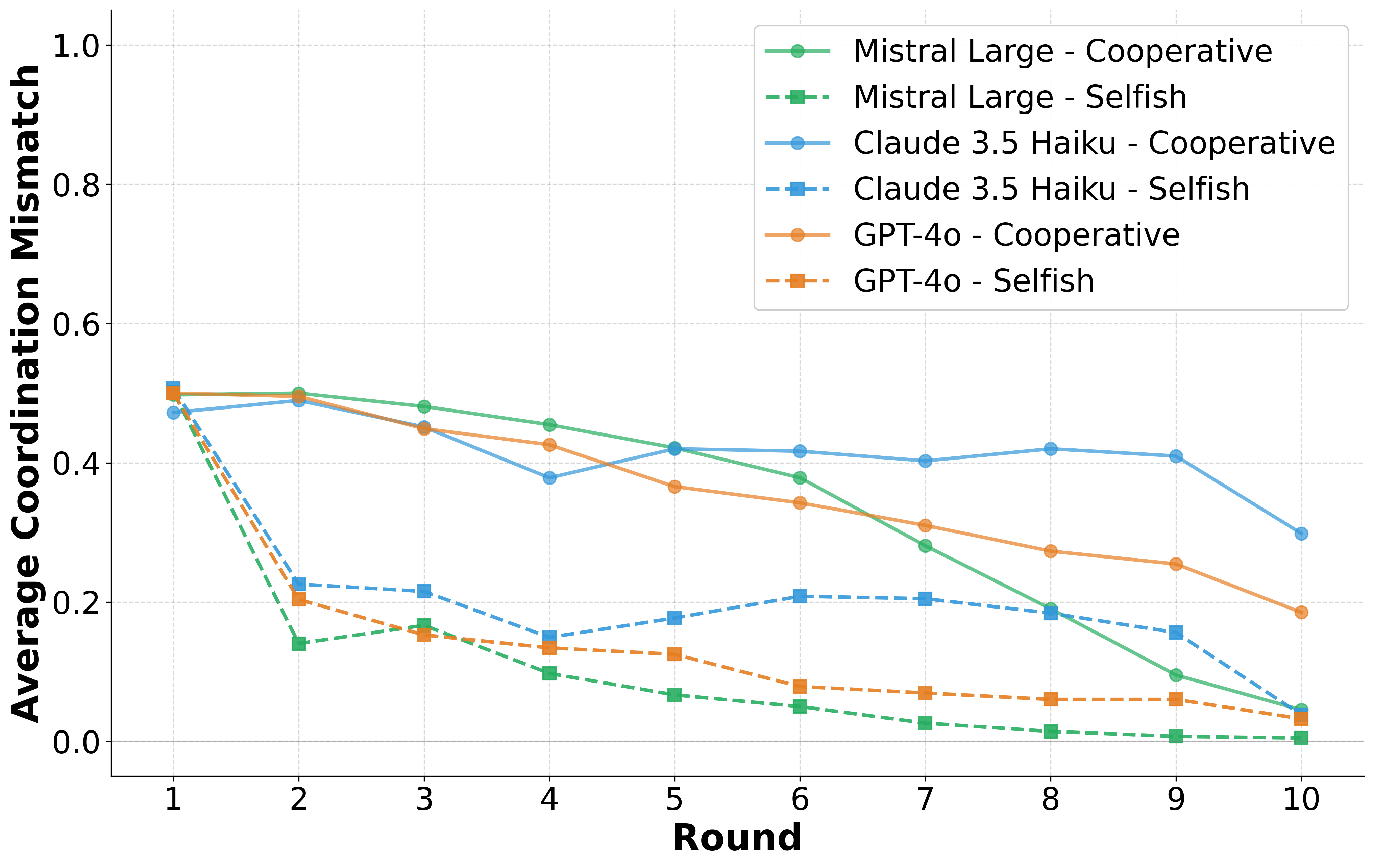
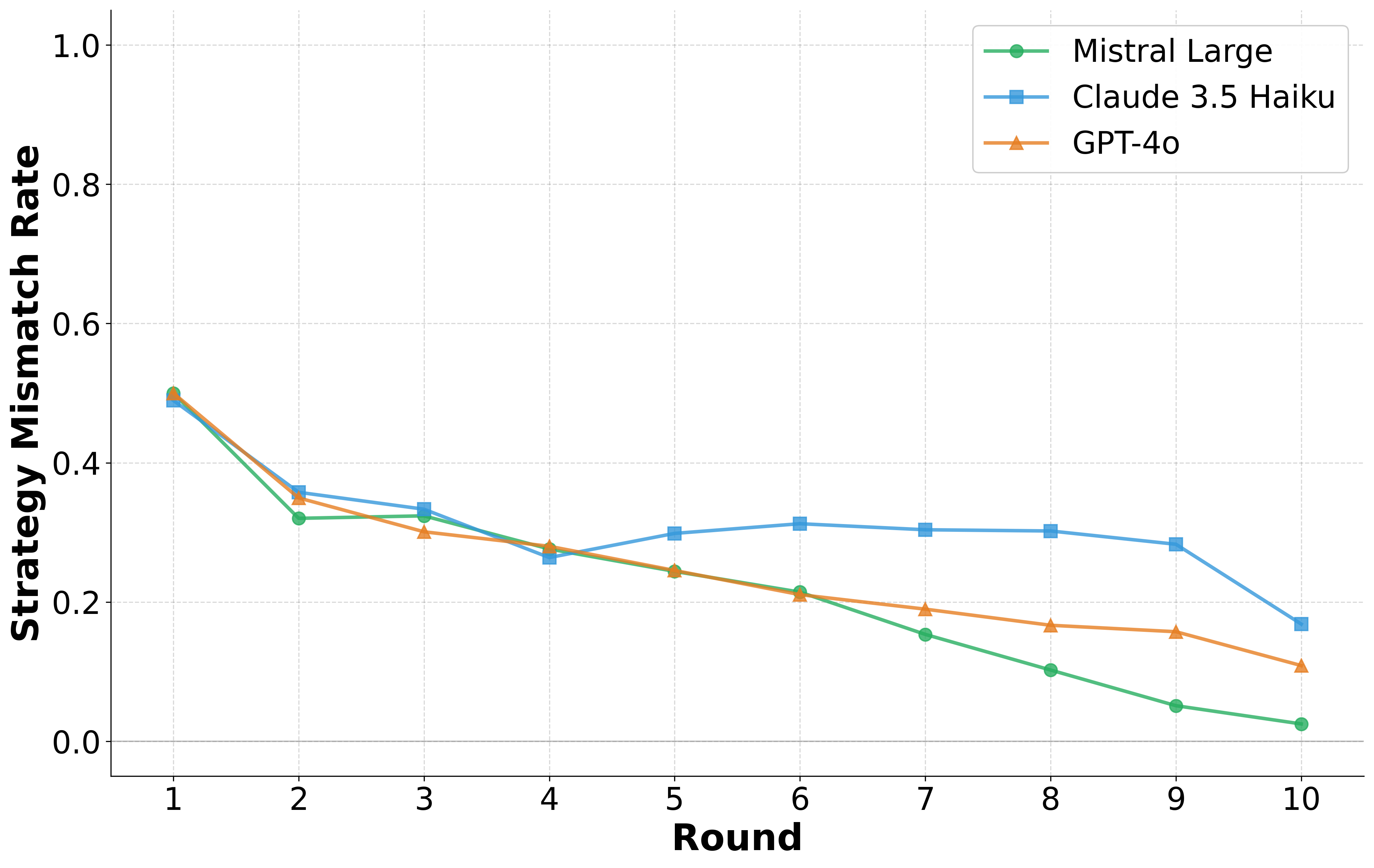
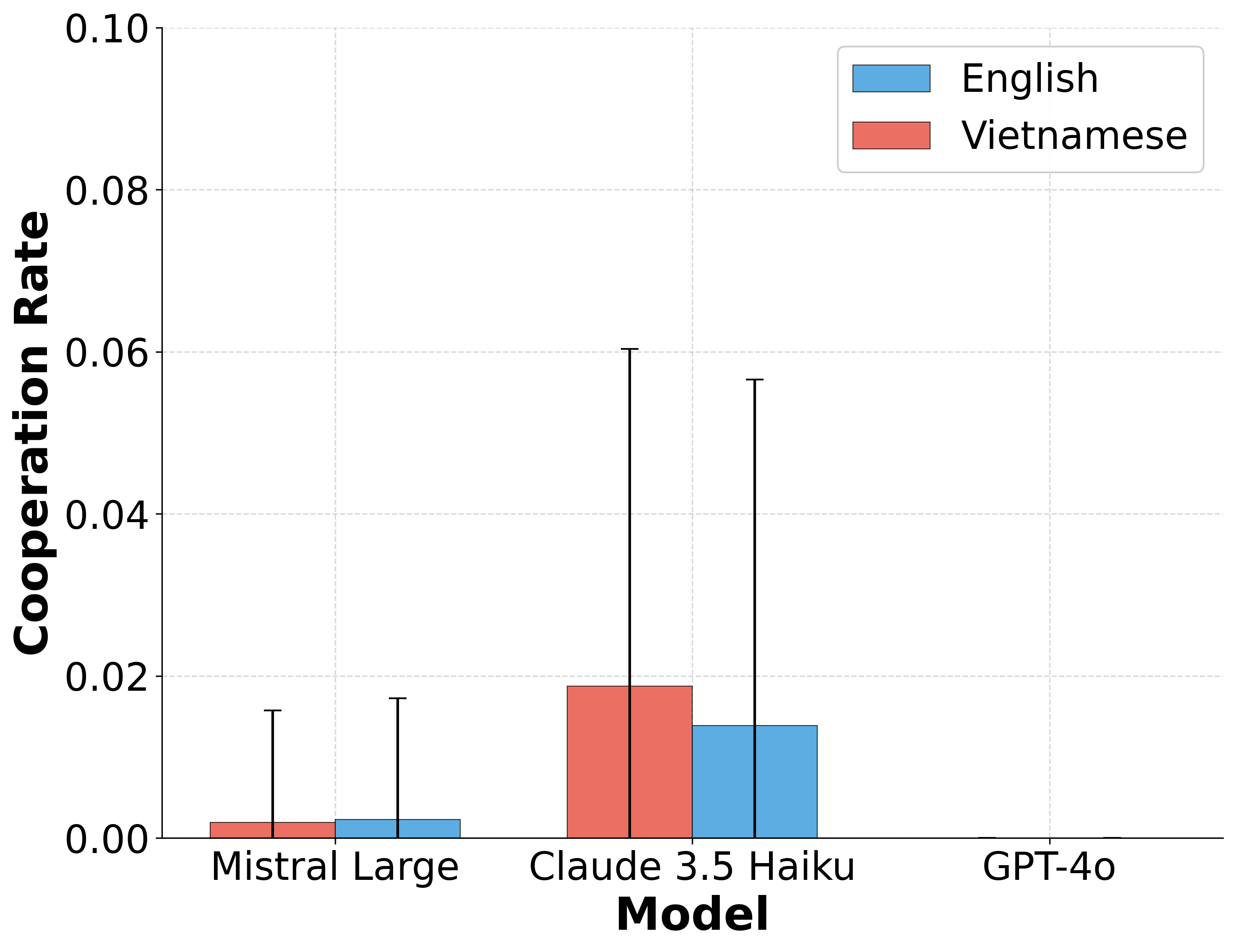
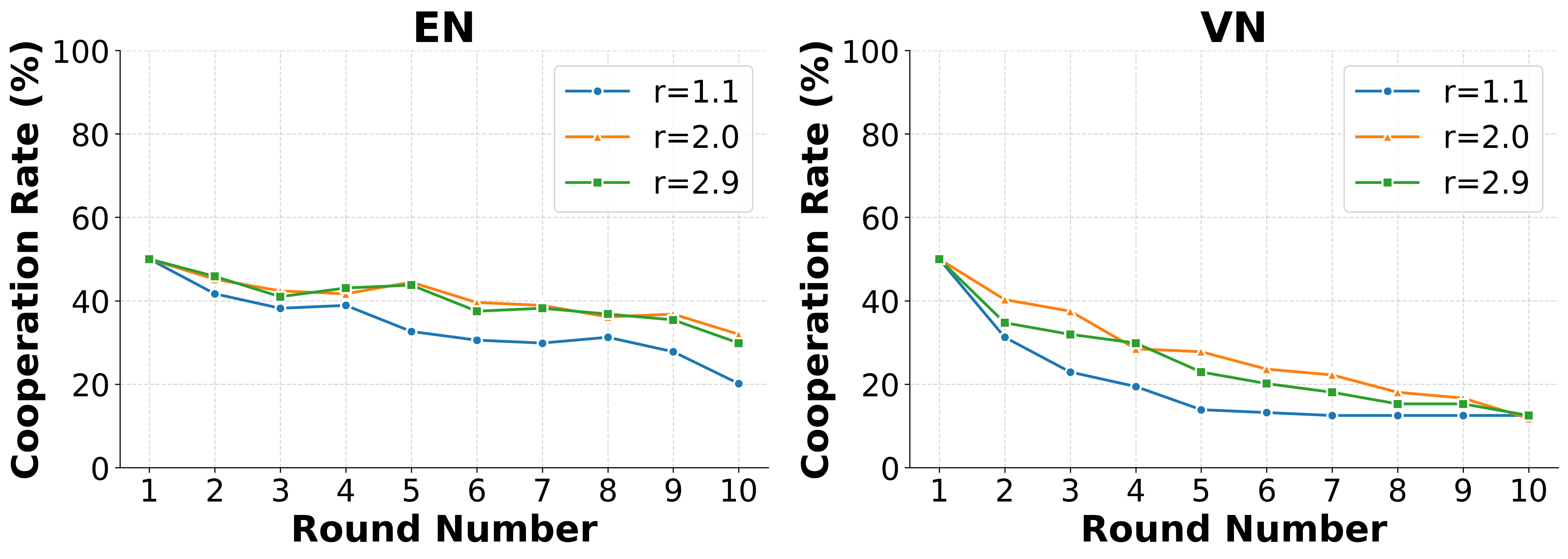
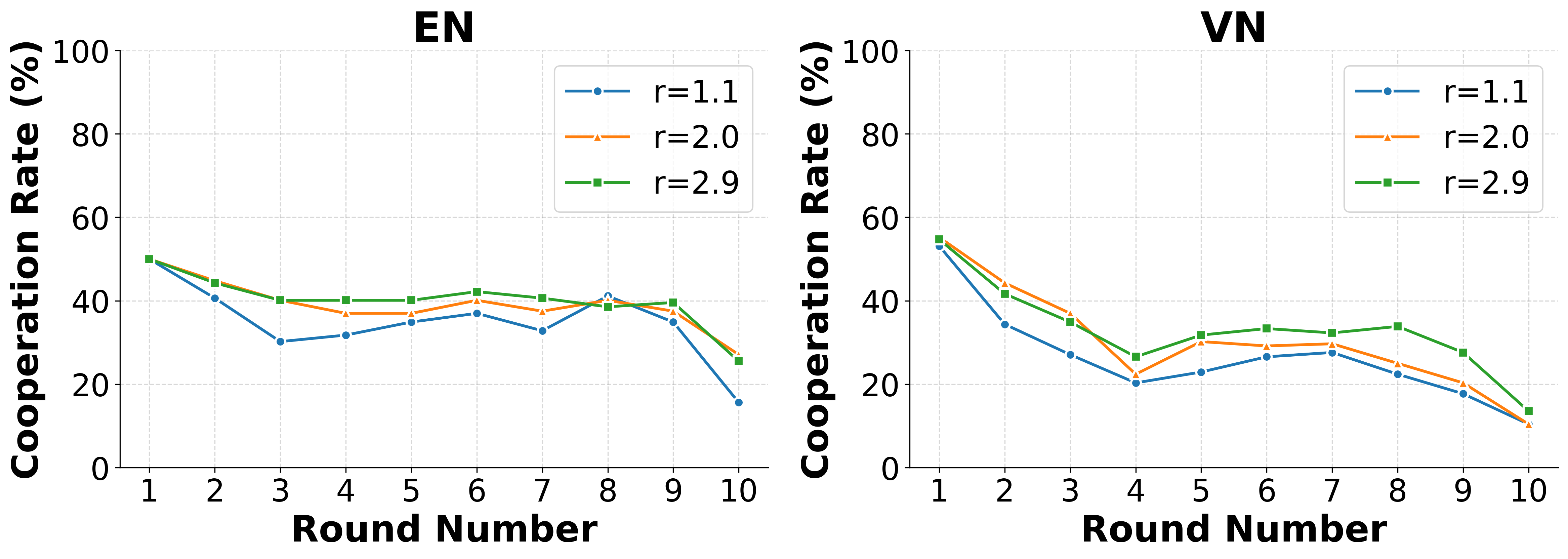
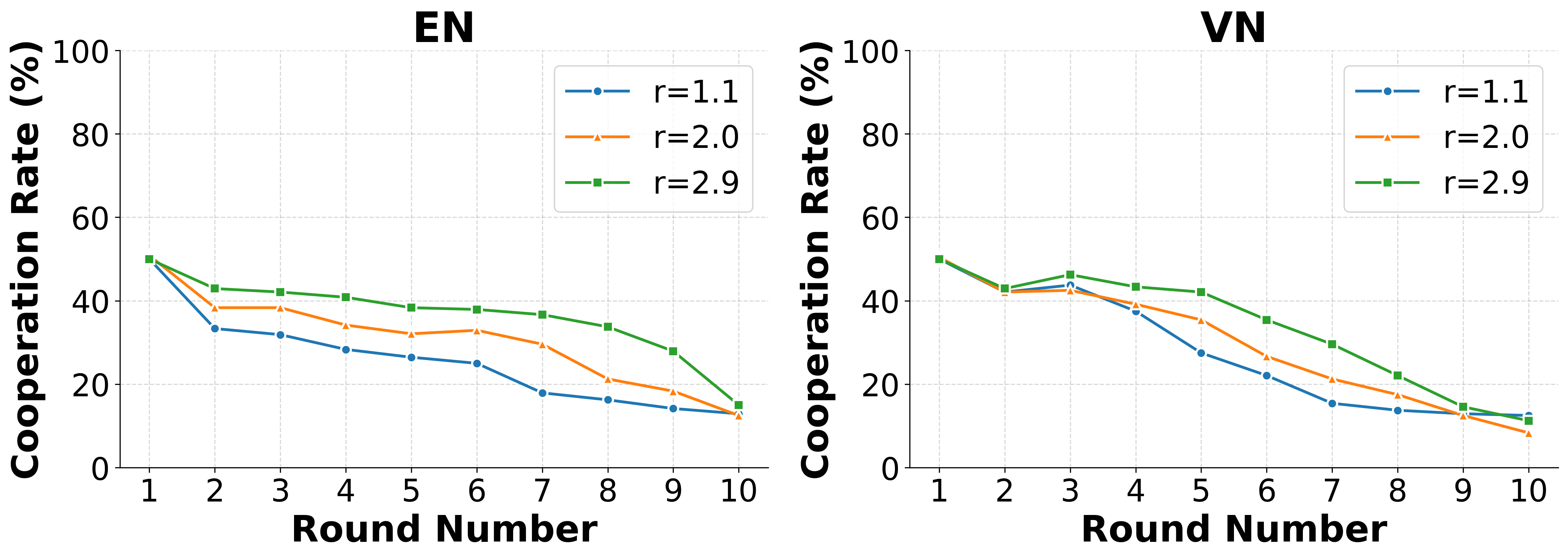
These environments reveal consistent behavioural signatures across models and languages, including
incentive-sensitive cooperation, cross-linguistic divergence and end-game alignment toward defec-
tion. To interpret these patterns, we train traditional supervised classification models on canonical
repeated-game strategies and apply them to LLM decisions in FAIRGAME, showing that LLMs ex-
hibit systematic, model- and language-dependent behavioural intentions, with linguistic framing at
times exerting effects as strong as architectural differences. Together, these findings provide a unified
methodological foundation for auditing LLMs as strategic agents and reveal systematic cooperation
biases with direct implications for AI governance, collective decision-making, and the design of safe
multi-agent systems.
1
Introduction
Large language models (LLMs) are increasingly deployed as agents that interact with human users
and with one another in recommendation systems, negotiation tools, and multi-agent assistants [1, 2,
3]. In these settings, LLMs are repeatedly exposed to cooperation dilemmas, where they may produce
behaviours that resemble contributing to a shared goal, free-riding on others, or enforcing social norms [4,
1, 5, ?]. Such behaviour does not reflect genuine intentions or internal goals. It is the result of statistical
patterns learned during training, combined with the incentives and context provided during interaction.
Evaluating these systems therefore requires more than verifying factual correctness or conversational
quality. It requires analysing the emergent strategies that LLM-based agents tend to exhibit over time,
1
arXiv:2512.07462v2 [cs.MA] 11 Dec 2025
how these strategies are shaped by prompting, reward structures, and role assignment, and how they
differ across languages and tasks [6, 7, 8, 9, 10, 11, 12, 13].
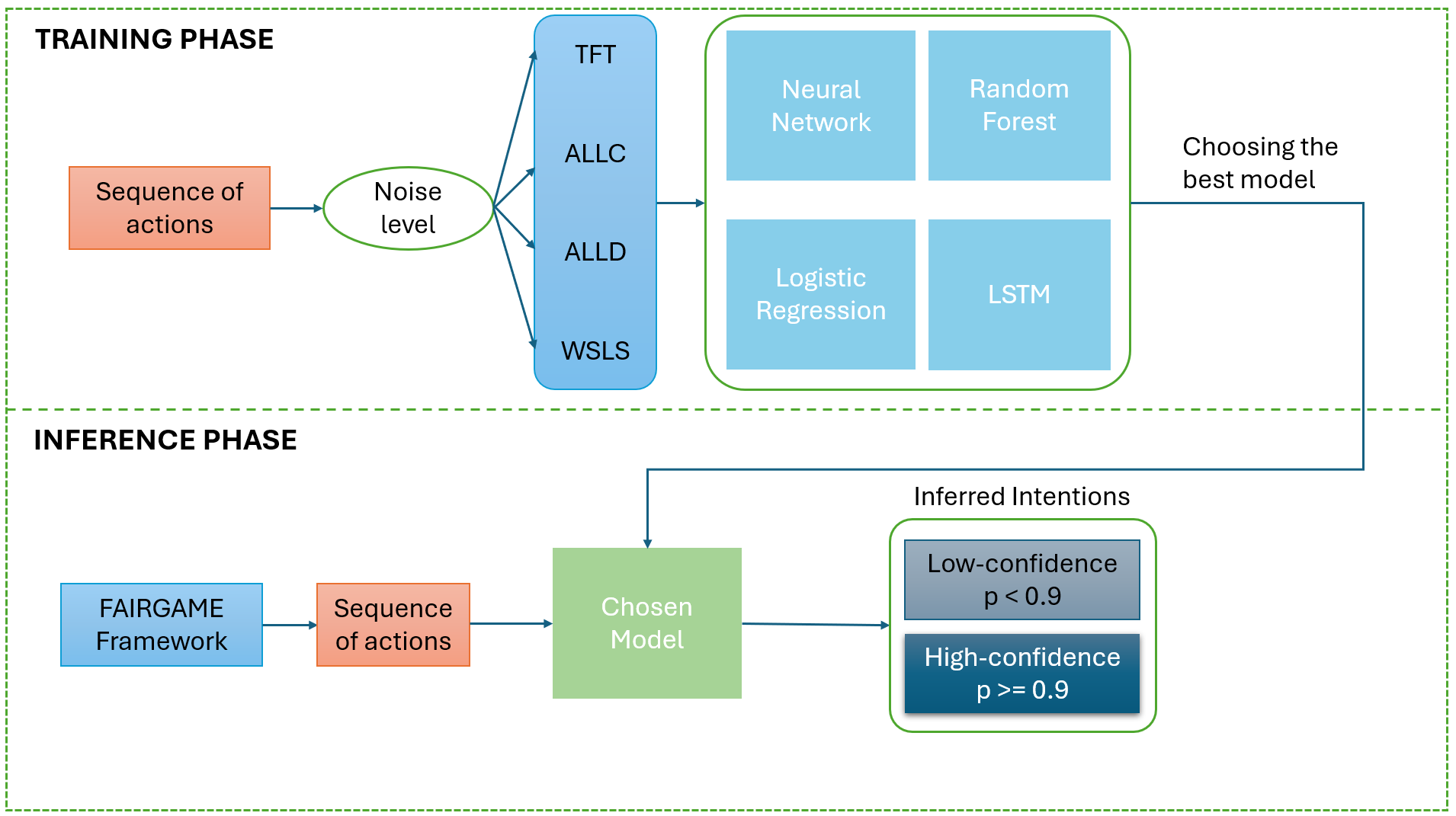
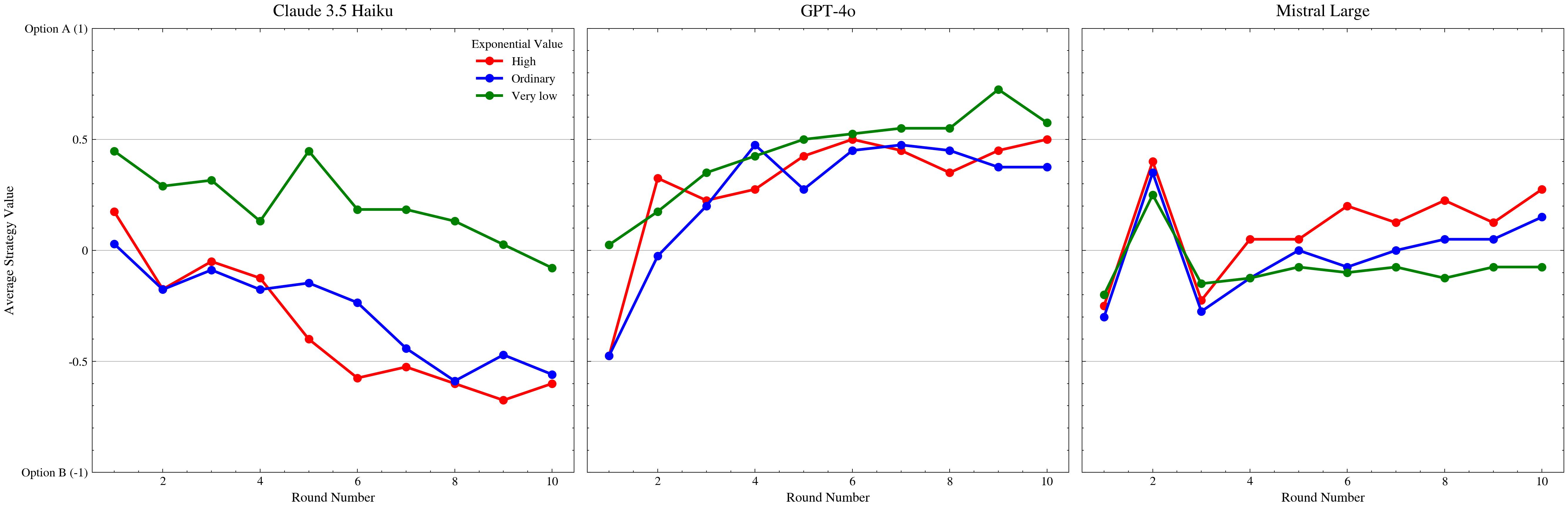
We adopt the notion of “behavioural intention” from the literature on repeated games, where an
intention is operationalised as a decision rule that maps past interaction histories to current actions.
Classical and evolutionary game theory has long studied how such strategies emerge, stabilise, and can
be inferred in repeated social dilemmas [14, 15]. Recent work builds on this by showing that canonical
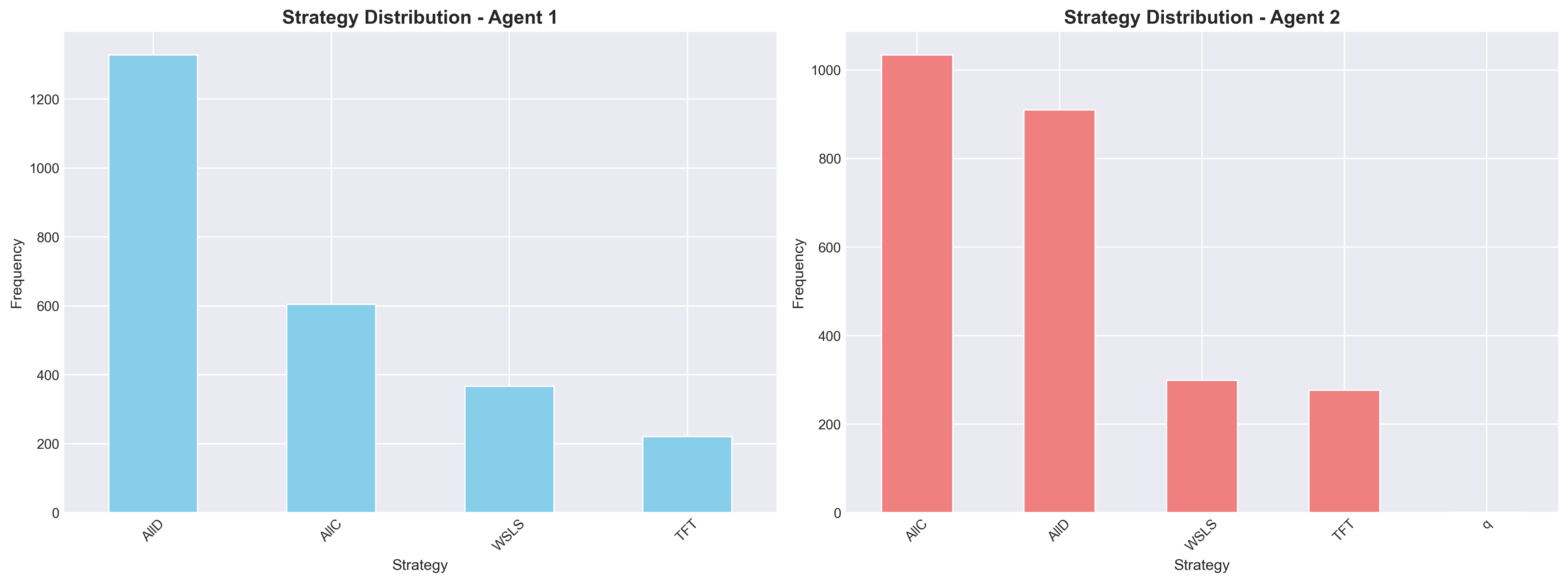
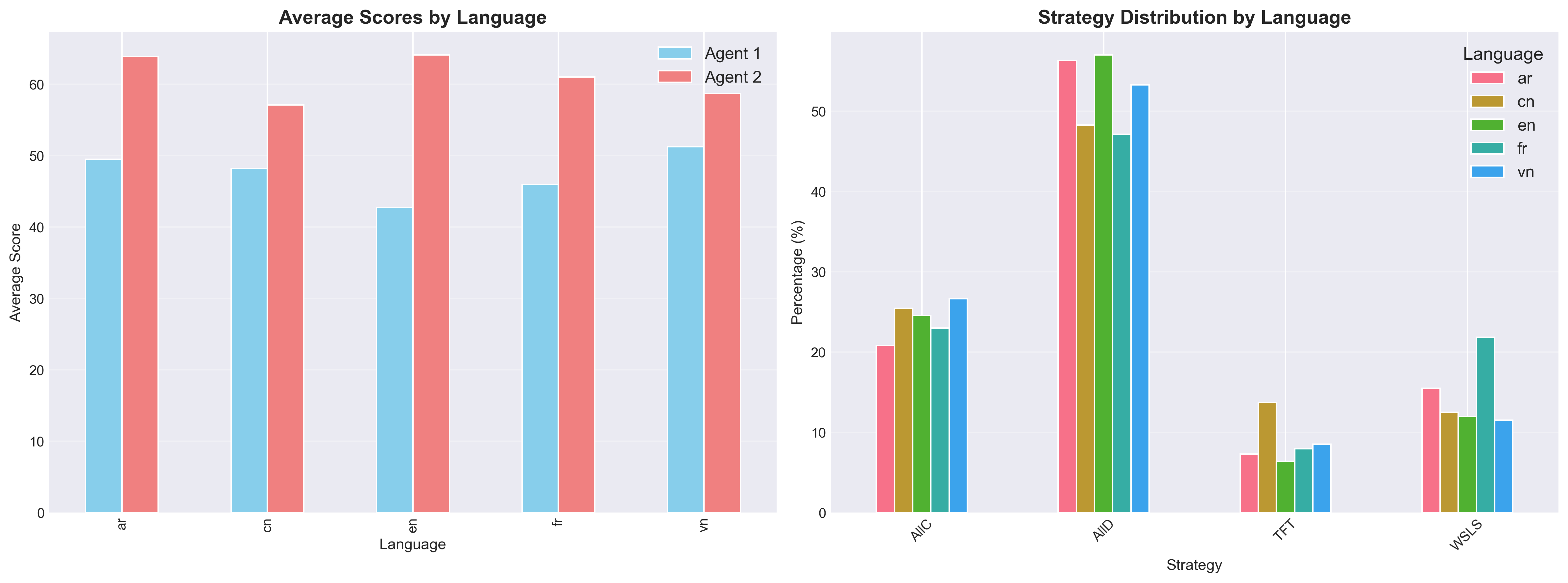
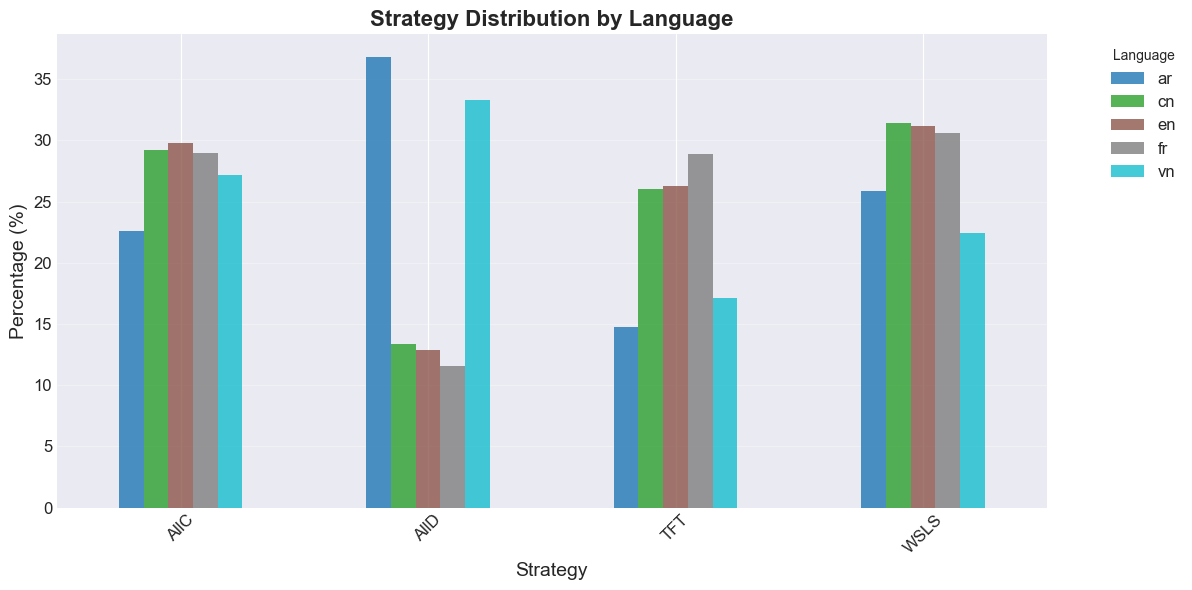
strategies—such as Always Cooperate (ALLC), Always Defect (ALLD), Tit-for-Tat (TFT), and Win-
Stay-Lose-Shift (WSLS) [16, 17]—can be recognised in the Iterated Prisoner’s Dilemma (IPD) by training
classifiers on noisy trajectories of play between artificial agents [14]. This line of research suggests that
behavioural intention can be treated as a learnable object: given enough action trajectories, we may
infer which strategy best explains an agent’s behaviour, even in the presence of execution noise.
In parallel, frameworks such as FAIRGAME (Framework for AI Agents Bias Recognition using Game
Theory) [18] have begun to systematically probe LLMs using repeated normal-form games. FAIRGAME
provides a controlled environment in which LLM agents are prompted to play a range of matrix games
under different payoff structures and experimental conditions, allowing researchers to measure fairness,
cooperation, and other social biases across models, la