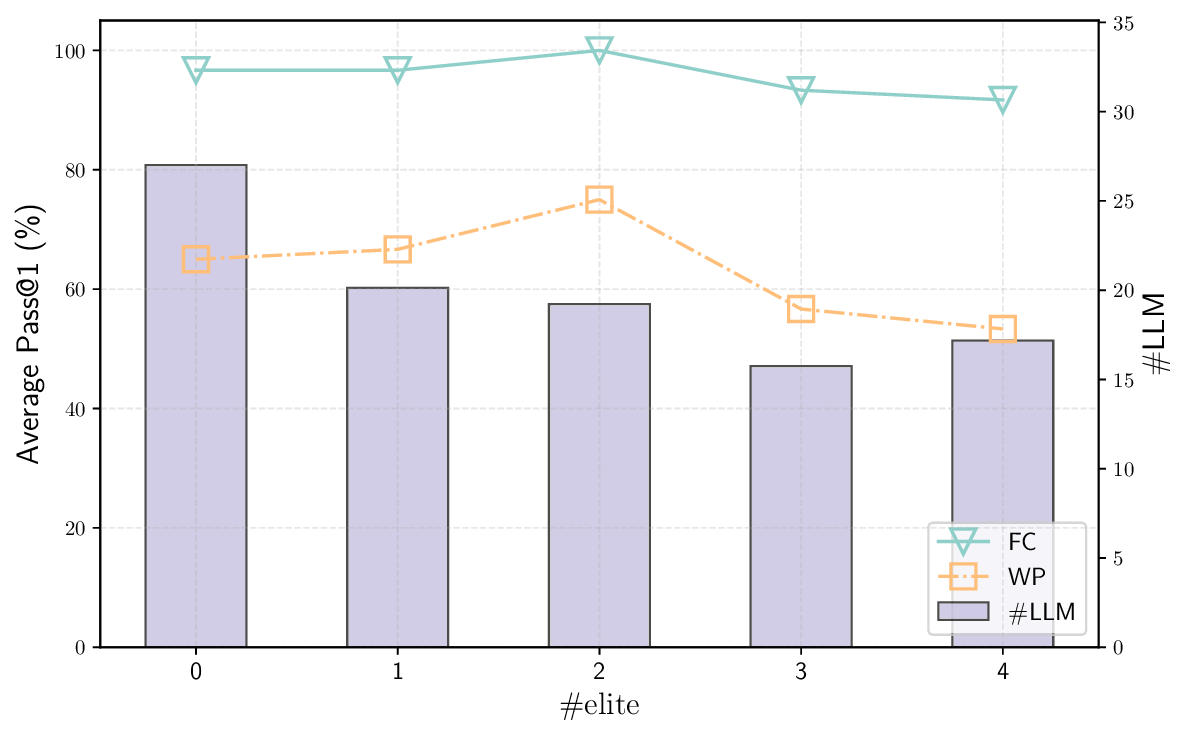
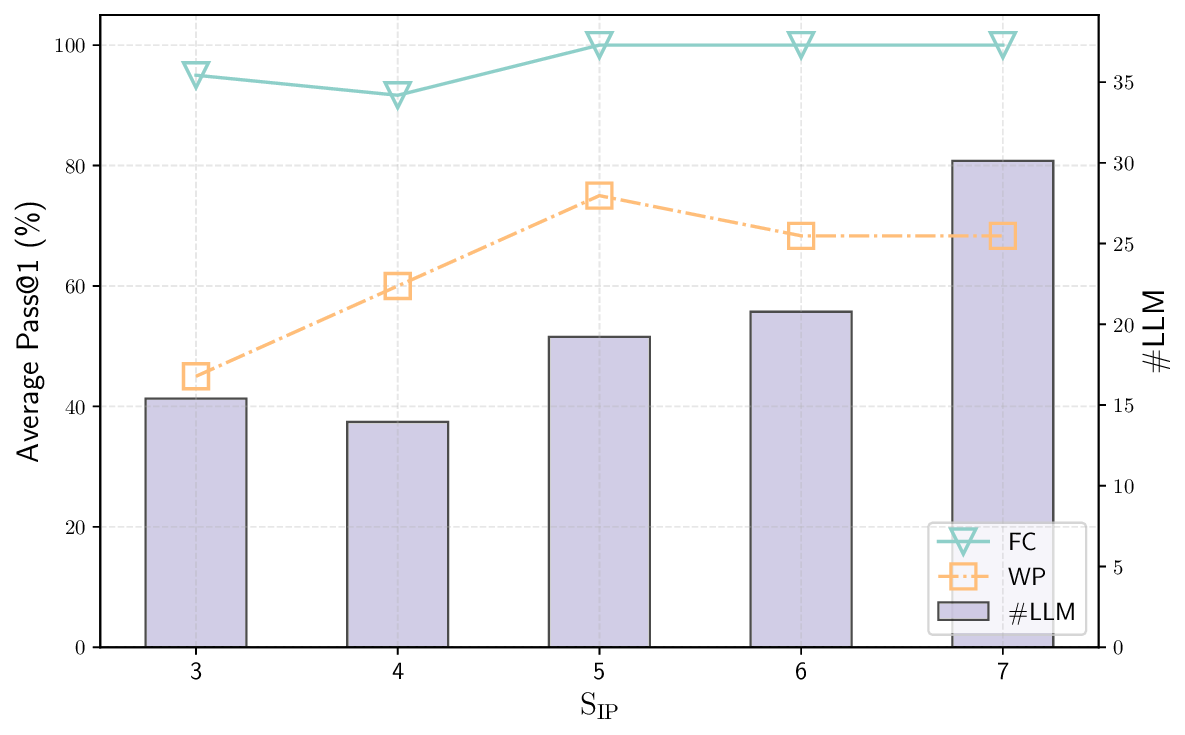
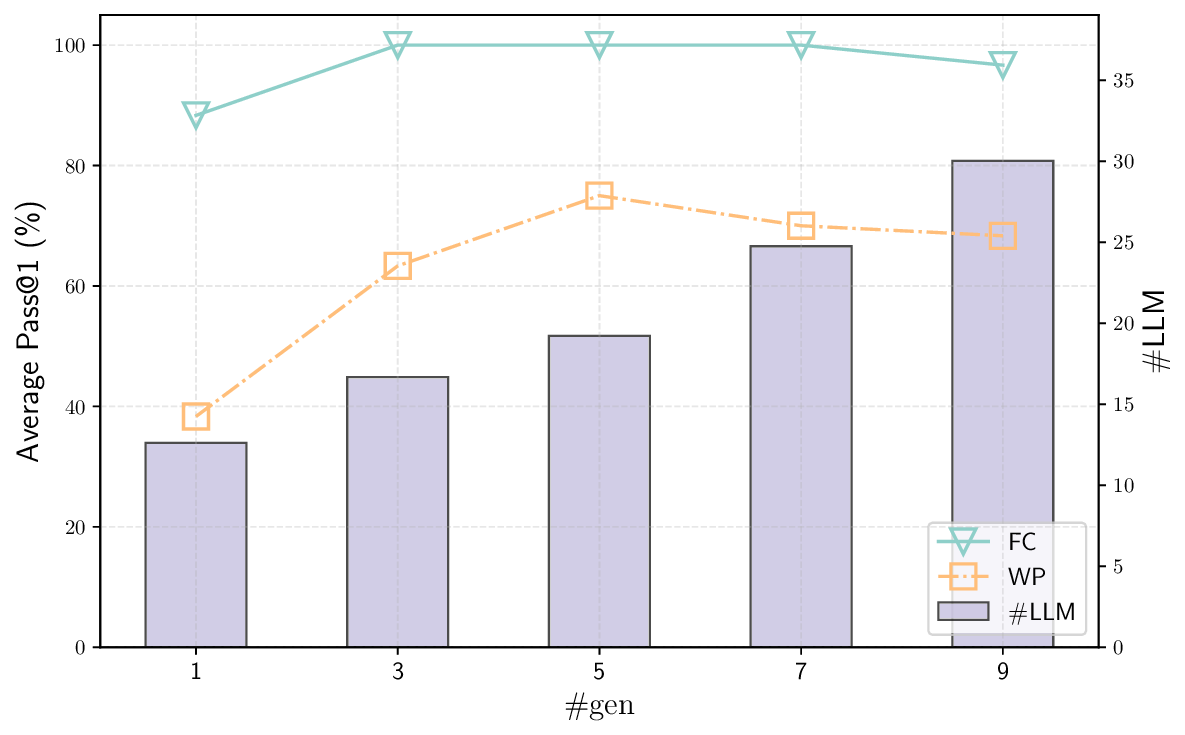
AutoICE: Automatically Synthesizing Verifiable C Code via LLM-driven Evolution
Reading time: 5 minute
...
📝 Original Info
Title: AutoICE: Automatically Synthesizing Verifiable C Code via LLM-driven Evolution
ArXiv ID: 2512.07501
Date: 2025-12-08
Authors: ** Weilin Luo, Xueyi Liang, Haotian Deng, Yanan Liu, Hai Wan Sun Yat‑sen University, School of Computer Science and Engineering, Guangzhou, China **
📝 Abstract
Automatically synthesizing verifiable code from natural language requirements ensures software correctness and reliability while significantly lowering the barrier to adopting the techniques of formal methods. With the rise of large language models (LLMs), long-standing efforts at autoformalization have gained new momentum. However, existing approaches suffer from severe syntactic and semantic errors due to the scarcity of domain-specific pre-training corpora and often fail to formalize implicit knowledge effectively. In this paper, we propose AutoICE, an LLM-driven evolutionary search for synthesizing verifiable C code. It introduces the diverse individual initialization and the collaborative crossover to enable diverse iterative updates, thereby mitigating error propagation inherent in single-agent iterations. Besides, it employs the self-reflective mutation to facilitate the discovery of implicit knowledge. Evaluation results demonstrate the effectiveness of AutoICE: it successfully verifies 90.36% of code, outperforming the state-of-theart (SOTA) approach. Besides, on a developer-friendly dataset variant, AutoICE achieves a 88.33% verification success rate, significantly surpassing the 65% success rate of the SOTA approach.
💡 Deep Analysis
📄 Full Content
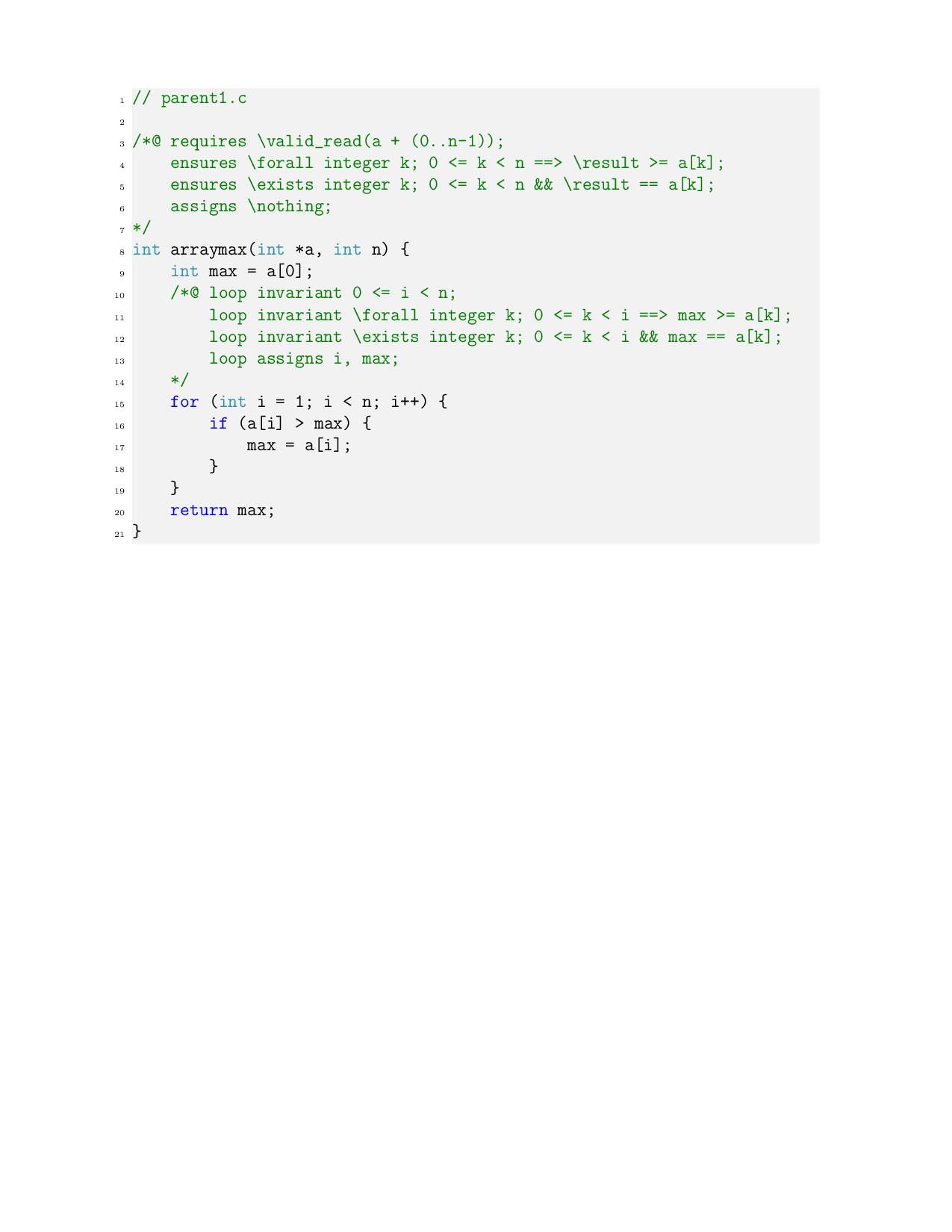
AutoICE: Automatically Synthesizing Verifiable C
Code via LLM-driven Evolution
Weilin Luo[0000−0002−3733−9361], Xueyi Liang[0009−0003−8661−8396], Haotian
Deng[0009−0007−7010−8278], Yanan Liu[0000−0001−7357−1793], and Hai
Wan[0000−0001−5357−9130]
Sun Yat-sen University, School of Computer Science and Engineering, Guangzhou,
China
{luowlin5,wanhai}@mail.sysu.edu.cn,
{liangxy233,denght7,liuyn56}@mail2.sysu.edu.cn
Abstract. Automatically synthesizing verifiable code from natural lan-
guage requirements ensures software correctness and reliability while
significantly lowering the barrier to adopting the techniques of formal
methods. With the rise of large language models (LLMs), long-standing
efforts at autoformalization have gained new momentum. However, ex-
isting approaches suffer from severe syntactic and semantic errors due
to the scarcity of domain-specific pre-training corpora and often fail
to formalize implicit knowledge effectively. In this paper, we propose
AutoICE, an LLM-driven evolutionary search for synthesizing verifiable
C code. It introduces the diverse individual initialization and the col-
laborative crossover to enable diverse iterative updates, thereby miti-
gating error propagation inherent in single-agent iterations. Besides, it
employs the self-reflective mutation to facilitate the discovery of implicit
knowledge. Evaluation results demonstrate the effectiveness of AutoICE:
it successfully verifies 90.36% of code, outperforming the state-of-the-
art (SOTA) approach. Besides, on a developer-friendly dataset variant,
AutoICE achieves a 88.33% verification success rate, significantly surpass-
ing the 65% success rate of the SOTA approach.
Keywords: Autoformalization · Verifiable C Code · Large Language
Model · Evolutionary Search.
1
Introduction
Autoformalization, the process of automatically translating informal require-
ments, e.g., natural language, into formal, machine-verifiable specifications, e.g.,
ANSI/ISO C specification language (ACSL) [3], plays an increasingly pivotal role
in formal methods. Due to the widespread use of C code, one of the practical
and impactful directions of autoformalization is the automated synthesis of ver-
ifiable C code, namely ACSL-annotated code. Unlike standard code generation,
synthesizing verifiable C code requires generating not only C code but also the
corresponding formal specifications, e.g., pre-conditions, post-conditions, and
arXiv:2512.07501v1 [cs.SE] 8 Dec 2025
2
W. Luo et al.
loop invariants. By leveraging mature symbolic solvers, the correctness of the
generated code can be mathematically proven. However, manually writing for-
mal specifications is a creative process that requires developers to invest a lot
of extra effort, experience, and expertise, because formal specification languages
are closer to mathematics than traditional programming languages [63, 45, 25,
65]. The automated generation of high-quality, verifiable C code is crucial and
urgent. It would significantly lower the barrier to entry for formal methods,
which is of paramount importance for safety-critical domains such as finance,
healthcare, and autonomous systems [40, 39, 45].
However, achieving high-quality autoformalization is challenging. Semantic
gap: natural language is ambiguous, polysemous, and expressive, whereas formal
languages require absolute precision and singularity. Data scarcity: high-quality
pairs of informal requirements and formal specifications are extremely rare, hin-
dering the development of learning-based approaches [47, 84, 58, 8].
With the rapid advancement of large language models (LLMs), their capabili-
ties in natural language understanding and code generation have garnered signif-
icant attention [7, 10, 96]. Trained on ultra-large-scale text and code, LLMs offer
a promising new avenue for autoformalization [11, 54]. LLMs demonstrate the
ability to handle the semantic gap based on context. For example, Wu et al. [86]
successfully utilized LLMs to translate mathematical competition problems into
Isabelle/HOL, a task previously considered intractable. Cosler et al. [15] pro-
posed a tool to interactively translate temporal properties in natural language
to temporal logics with LLMs.
Building on this potential, Cao et al. [8] have explored synthesizing verifiable
C code via LLMs. Despite some progress, existing LLM-based approaches still
face severe limitations.
– Due to data scarcity and inherent hallucinations, LLMs frequently generate
code with syntactic or semantic errors. While feedback from verifiers can
signal verification failures, this feedback is often sparse. Furthermore, relying
solely on LLMs to self-reflection code based on sparse feedback can lead to
error accumulation rather than resolution.
– Due to variations in expertise among developers and the differences between
formal languages and natural language, the requirements in natural lan-
guage are often incomplete, making it difficult to formalize implicit knowl-
edge. Natural