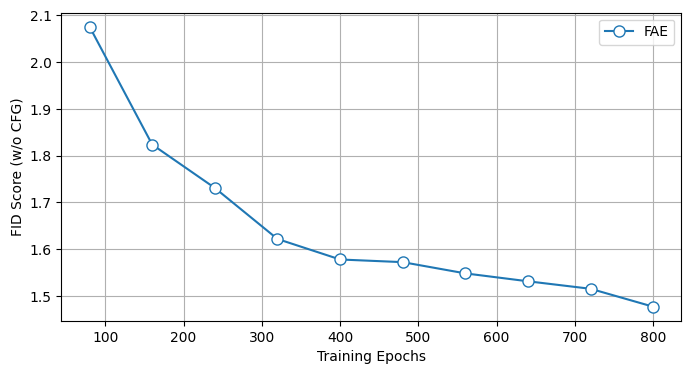
Visual generative models (e.g., diffusion models) typically operate in compressed latent spaces to balance training efficiency and sample quality. In parallel, there has been growing interest in leveraging high-quality pre-trained visual representations, either by aligning them inside VAEs or directly within the generative model. However, adapting such representations remains challenging due to fundamental mismatches between understanding-oriented features and generation-friendly latent spaces. Representation encoders benefit from high-dimensional latents that capture diverse hypotheses for masked regions, whereas generative models favor low-dimensional latents that must faithfully preserve injected noise. This discrepancy has led prior work to rely on complex objectives and architectures. In this work, we propose FAE (Feature Auto-Encoder), a simple yet effective framework that adapts pre-trained visual representations into low-dimensional latents suitable for generation using as little as a single attention layer, while retaining sufficient information for both reconstruction and understanding. The key is to couple two separate deep decoders: one trained to reconstruct the original feature space, and a second that takes the reconstructed features as input for image generation. FAE is generic; it can be instantiated with a variety of self-supervised encoders (e.g., DINO, SigLIP) and plugged into two distinct generative families: diffusion models and normalizing flows. Across class-conditional and text-to-image benchmarks, FAE achieves strong performance. For example, on ImageNet 256x256, our diffusion model with CFG attains a near state-of-the-art FID of 1.29 (800 epochs) and 1.70 (80 epochs). Without CFG, FAE reaches the state-of-the-art FID of 1.48 (800 epochs) and 2.08 (80 epochs), demonstrating both high quality and fast learning.
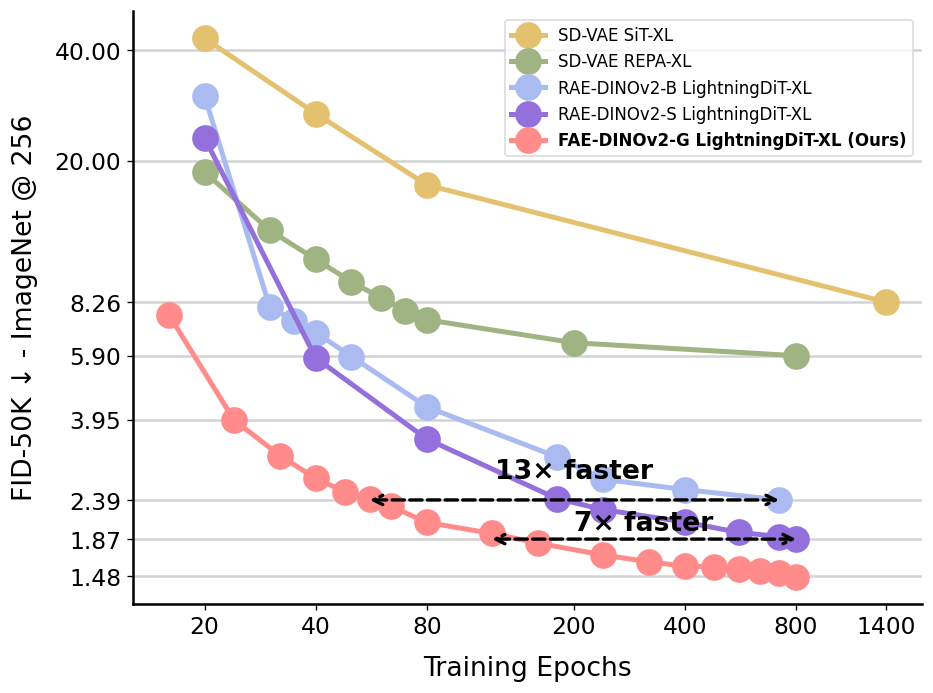
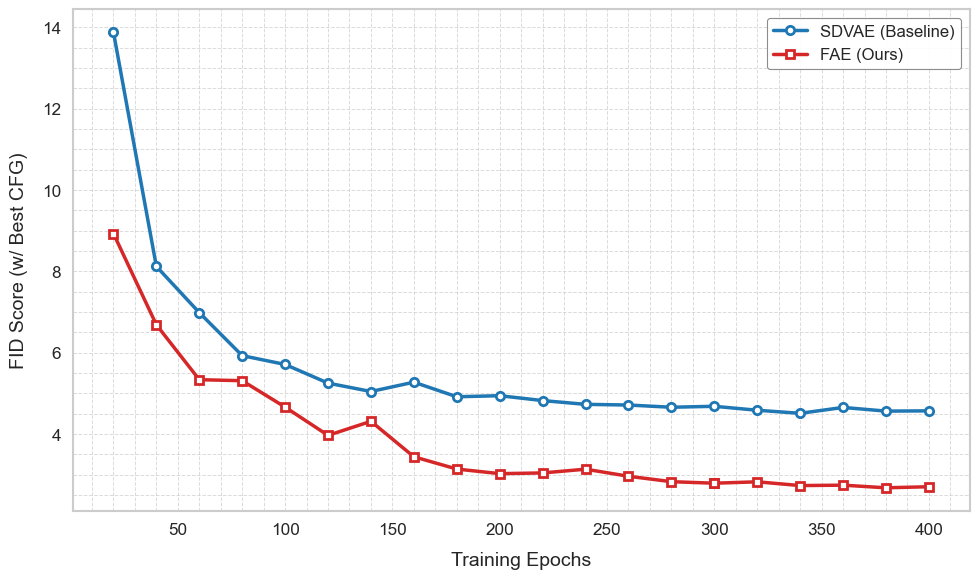
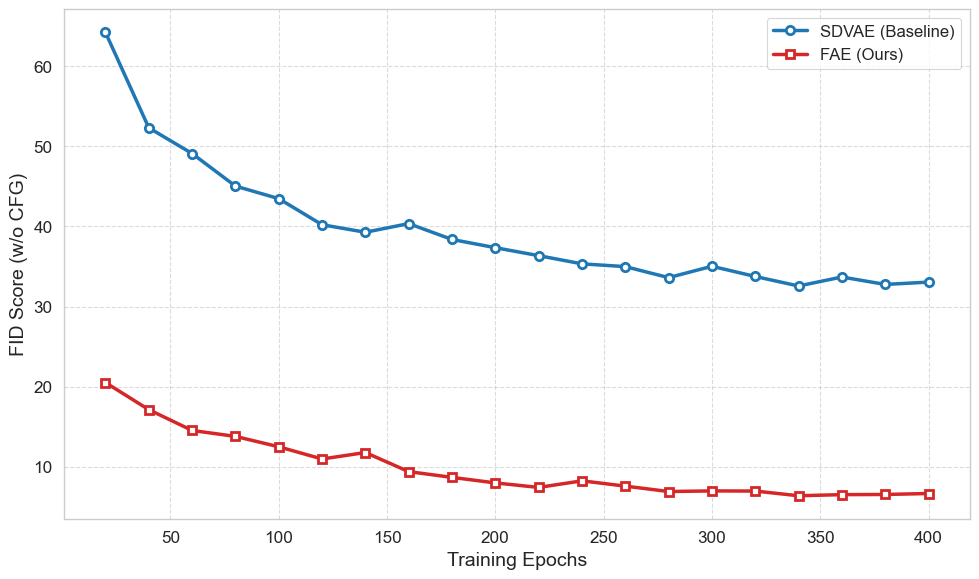
Figure 1 Training convergence on ImageNet 256×256. FAE achieves strong sample quality and converges 7-13× faster than concurrent baselines (Zheng et al., 2025).
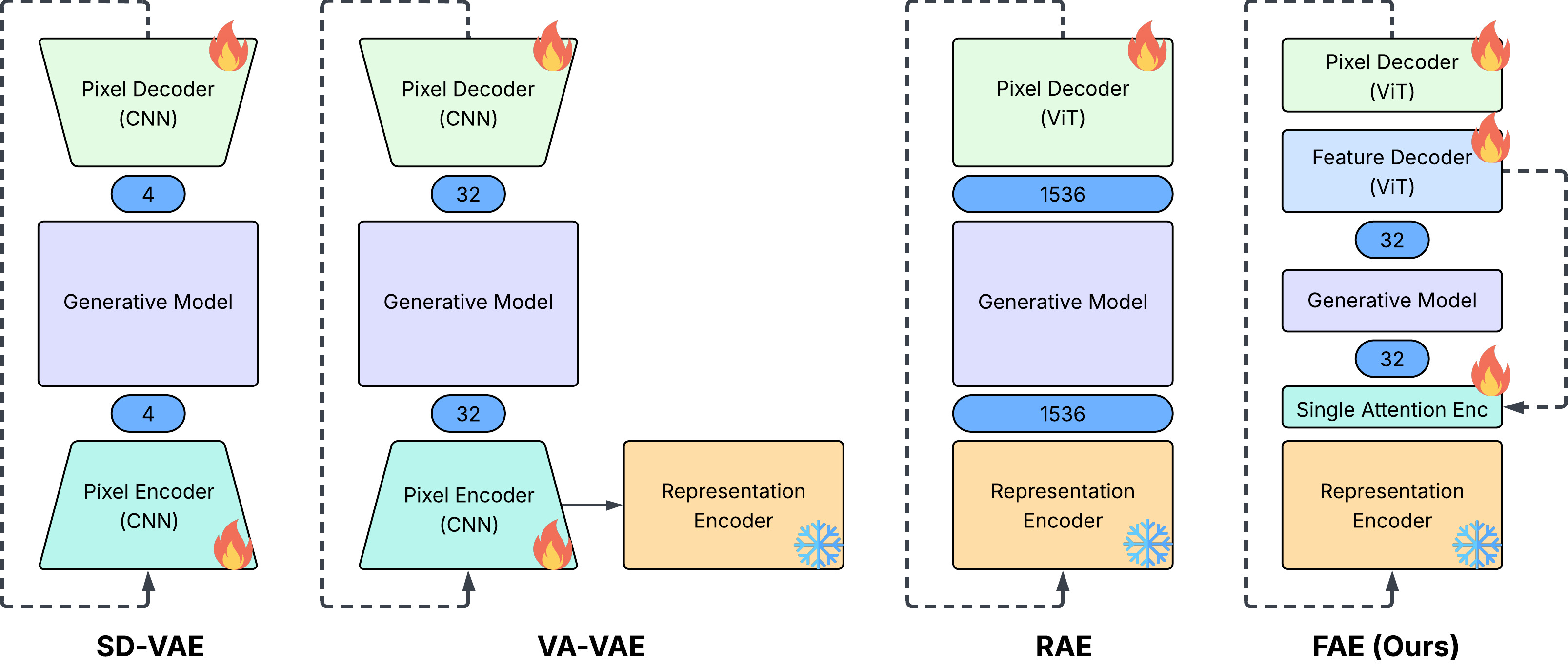
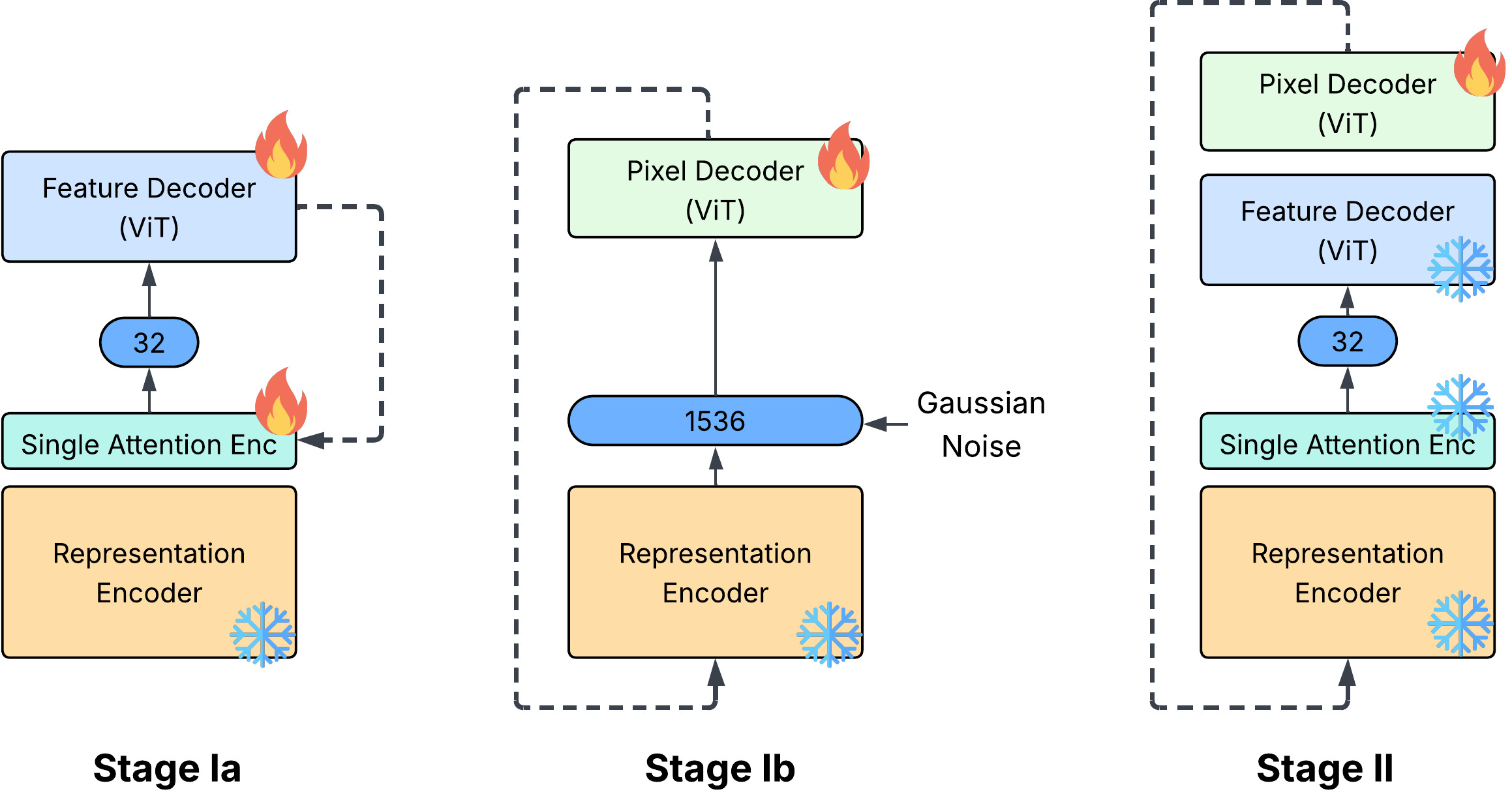
In past years, diffusion models (Nichol and Dhariwal, 2021;Saharia et al., 2021;Rombach et al., 2022) have significantly advanced the quality and flexibility of visual generation, making them the dominant framework for producing high-resolution images and videos. A key recent change driving this progress is the integration of powerful pretrained visual representations, typically obtained from large-scale self-supervised learning frameworks based on masked image prediction (Oquab et al., 2023;Tschannen et al., 2025). Such frameworks-exemplified by models like REPA (Yu et al., 2024b) and VA-VAE (Yao et al., 2025) utilize the rich semantic and structural information from the large models trained on unlabeled data. When incorporated into the diffusion pipeline-either within the denoising process or in variational autoencoders (VAEs)-these represen-Figure 2 Comparison between standard VAE (Rombach et al., 2022), VA-VAE (Yao et al., 2025), RAE (Zheng et al., 2025) and our proposed FAE. The number shows the channel dimension of the generative modeling space.
tations substantially improve both training efficiency and generative fidelity.
Despite this progress, adapting pre-trained visual representations to generative models remains challenging due to the inherent mismatches between understanding-oriented representations and generation-friendly latent spaces. Self-supervised models, in order to build up a hard task with the unlabelled data, masking and prediction tasks are used, not only in the image area but also text and audio. To capture the complicated distribution of different possibilities of the masked regions, especially to simulate the distribution with simple embedding multiplication and softmax function, a large latent dimension is required. In contrast, generation models such as diffusion models and normalizing flow models, are often formulated as denoising processes, evolving a noisy input toward a clean signal through an iterative refinement process. In diffusion models, for instance, the input is perturbed by Gaussian noise and repeatedly denoised through multiple timesteps. To ensure trajectory stability throughout this process, the hidden representations must simultaneously encode the information of both the noised input and its clean predicted target. When the latent dimension is large, this dual encoding becomes more resource demanding, and the diffusion dynamics become sensitive to noise-level scheduling, often leading to instability or slower convergence. Therefore, generative models favor compact, low-dimensional latent spaces, which make the denoising trajectory smoother, reduce the training burden, and preserve generative fidelity under limited model capacity. This discrepancy often results in inefficiencies and necessitates complex architectural modifications when integrating pre-trained representations.
In this paper, we revisit this problem from a different perspective and ask: Is it truly necessary to preserve the high-dimensional structure of pre-trained visual representations when just zero-shot adapting them? In fact, although self-supervised models are trained on masked prediction tasks, the adaptation only involves unmasked inputs where the need for modeling diverse distribution is diminished. Instead, the goal is to leverage the rich semantics and spatial information from the pre-train features.
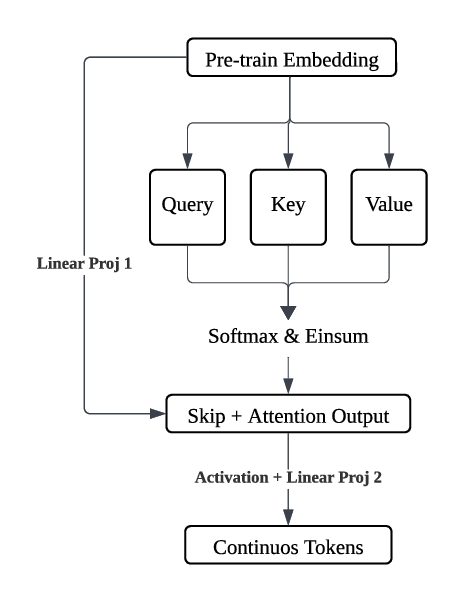
Building on this insight, we introduce FAE (Feature Auto-Encoder), a simple yet effective framework that compresses the pre-train embedding into a compact, generation-friendly space. We employ only a single attention layer followed by a linear projection to map the embeddings into a continuous low-dimensional code, and use a lightweight decoder to reconstruct the original features. During experiments, we observed that the adaptation task is substantially weaker than the original self-supervised pre-training task; as a result, overly complex adapting frameworks tend to lose information from the pre-trained embeddings. Empirically maintaining a closer distance between the compressed code and the original embedding leads to higher reconstruction quality. Therefore, we adopt a minimal design, using only a single attention layer as the encoder to remove redundant global information shared across patch embeddings.
We validate our method by integrating it into existing diffusion frameworks, including SiT (Ma et al., 2024) and LightningDiT (Yao et al., 2025) and normaling-flow based models (e.g., STARFlow (Gu et al., 2025a)). On ImageNet 256×256 generation, with CFG, diffusion model using FAE attains a near-state-of-the-art FID of 1.29 in 800 epochs and reaches an FID of 1.70 within only 80 training epochs. Without CFG, diffusion model using FAE achieves a state-of-the-art FID of 1.48 in 800 epochs and reaches an FID of 2.08 with only
This content is AI-processed based on open access ArXiv data.