As machine learning (ML) becomes an integral part of high-autonomy systems, it is critical to ensure the trustworthiness of learning-enabled software systems (LESS). Yet, the nondeterministic and run-time-defined semantics of ML complicate traditional software refactoring. We define semantic preservation in LESS as the property that optimizations of intelligent components do not alter the system's overall functional behavior. This paper introduces an empirical framework to evaluate semantic preservation in LESS by mining model evolution data from HuggingFace. We extract commit histories, Model Cards, and performance metrics from a large number of models. To establish baselines, we conducted case studies in three domains, tracing performance changes across versions. Our analysis demonstrates how semantic drift can be detected via evaluation metrics across commits and reveals common refactoring patterns based on commit message analysis. Although API constraints limited the possibility of estimating a full-scale threshold, our pipeline offers a foundation for defining community-accepted boundaries for semantic preservation. Our contributions include: (1) a large-scale dataset of ML model evolution, curated from 1.7 million Hugging Face entries via a reproducible pipeline using the native HF hub API, (2) a practical pipeline for the evaluation of semantic preservation for a subset of 536 models and 4000+ metrics and (3) empirical case studies illustrating semantic drift in practice. Together, these contributions advance the foundations for more maintainable and trustworthy ML systems.
💡 Deep Analysis
📄 Full Content
An Empirical Framework for Evaluating Semantic Preservation Using
Hugging Face
Nan Jia
CUNY, the Graduate Center
njia@gradcenter.cuny.edu
Anita Raja
CUNY, Hunter College
CUNY, the Graduate Center
anita.raja@hunter.cuny.edu
Raffi Khatchadourian
CUNY, Hunter College
CUNY, the Graduate Center
khatchad@hunter.cuny.edu
Abstract
As machine learning (ML) becomes an integral part
of high-autonomy systems, it is critical to ensure the
trustworthiness of learning-enabled software systems
(LESS). Yet, the nondeterministic and run-time-defined
semantics
of
ML
complicate
traditional
software
refactoring. We define semantic preservation in LESS as
the property that optimizations of intelligent components
do not alter the system’s overall functional behavior.
This paper introduces an empirical framework to
evaluate semantic preservation in LESS by mining
model evolution data from HuggingFace.
We extract
commit histories,
Model Cards,
and performance
metrics
from
a
large
number
of
models.
To
establish baselines, we conducted case studies in
three domains, tracing performance changes across
versions.
Our analysis demonstrates how semantic
drift can be detected via evaluation metrics across
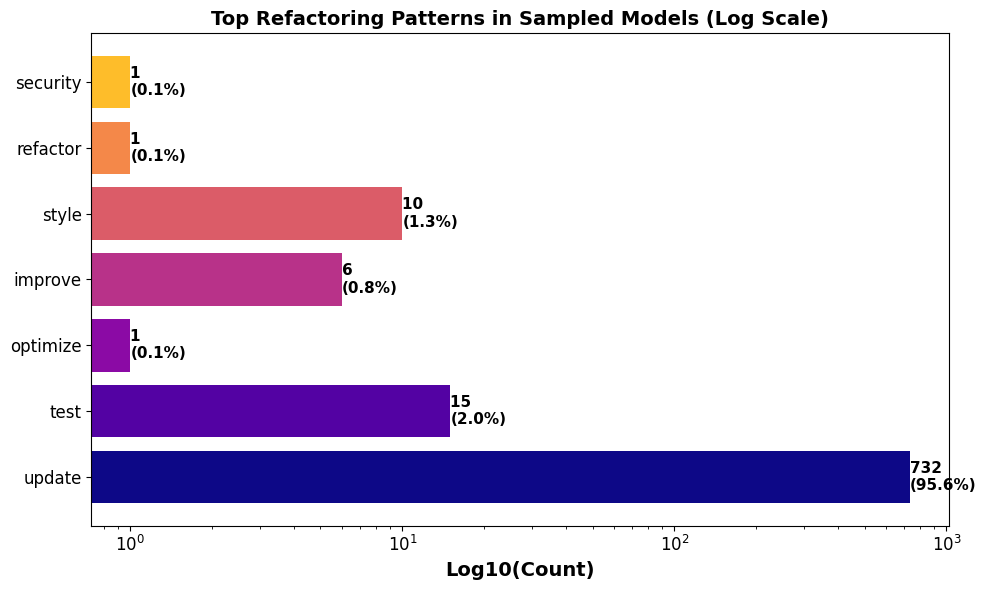
commits and reveals common refactoring patterns
based on commit message analysis.
Although API
constraints limited the possibility of estimating a
full-scale threshold, our pipeline offers a foundation for
defining community-accepted boundaries for semantic
preservation.
Our contributions include:
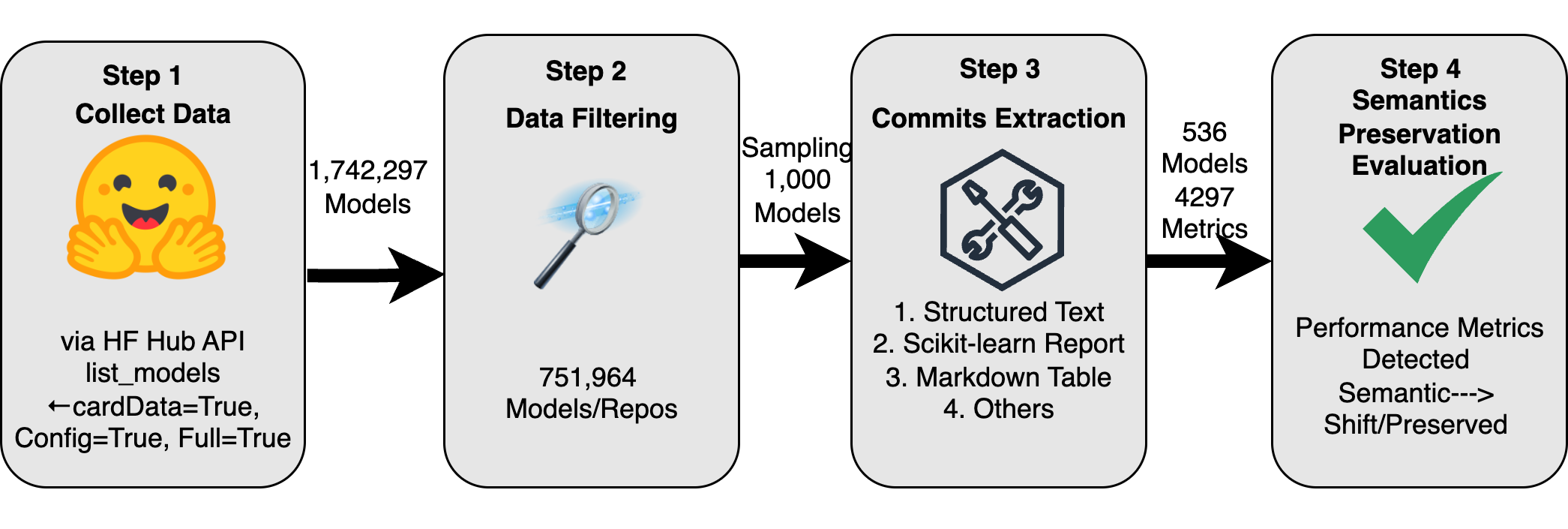
(1) a
large-scale dataset of ML model evolution, curated from
1.7 million Hugging Face entries via a reproducible
pipeline using the native HF hub API, (2) a practical
pipeline for the evaluation of semantic preservation
for a subset of 536 models and 4000+ metrics and
(3) empirical case studies illustrating semantic drift
in practice. Together, these contributions advance the
foundations for more maintainable and trustworthy ML
systems.
Keywords:
Refactoring,
Semantic
Drift,
Learning-enabled
Software
Systems,
Hugging
Face, Software Evolution
1.
Introduction
In
traditional
software
engineering,
behavior-preserving
system
transformation
is
a
well-understood concept.
As first introduced by
Opdyke
(1992),
refactoring
in
object-oriented
programming
involves
systematically
restructuring
code without altering its external behavior. However,
a learning-enabled software systems (LESS)—where
Machine Learning (ML) models and data drive system
behavior—refactoring is far more ambiguous.
How
can we verify that fine-tuning produces a trustworthy
transformation (Ao et al., 2023; Jia et al., 2024) that
maintains both the system’s behavioral integrity (Tang
et al., 2021) and interpretable decision-making (Molnar
et al., 2020)? The uncertainty is especially problematic
in high-autonomy domains such as safety-critical
infrastructure, finance, and healthcare (Hu et al., 2022;
Nahar et al., 2024; Pan & Rajan, 2020; Zhuo et al.,
2023), where ML components must remain reliable and
explainable under continuous evolution.
Yet, despite
this need, there is currently no empirical baseline for
what counts as a safe or semantics preserving change
when updating models, training data, or documentation.
This gap raises risks not only in performance regression
but also in trust, reproducibility, and downstream
system reliability.
To mitigate these risks, it is increasingly critical
to understand how ML models evolve while retaining
their original intent.
Unlike traditional software
artifacts, ML models are not static—they are rapidly
updated through fine-tuning, performance optimization,
and documentation updates.
Our goal in this paper
is to uncover patterns and boundaries of semantic
preservation during system transformation in widely
arXiv:2512.07983v1 [cs.SE] 8 Dec 2025
used pretrained ML models that are hosted on Hugging
Face.
Studying this semantic transformation in deployed
LESS is difficult due to proprietary constraints (H. V.
Nguyen, 2025) and dynamic environments (David,
2020;
Hu et al.,
2022;
Pollano et al.,
2023).
Fortunately, the Hugging Face platform, often referred
to as the “GitHub for ML models (Ait et al., 2023;
Pan et al., 2022), offers a uniquely rich and open
environment to observe these dynamics at scale. Each
model repository hosted on Hugging Face includes
not only model weights and configurations but also
version-controlled Model Card (Mitchell et al., 2019)
and commit histories. These artifacts allow researchers
to trace intra-repository evolution—how individual
models change over time within a single project—not
just at a snapshot, but across multiple versions.
In this paper, we present the first empirical study
to our knowledge of intra-repository evolution on
the Hugging Face (HF) platform by operationally
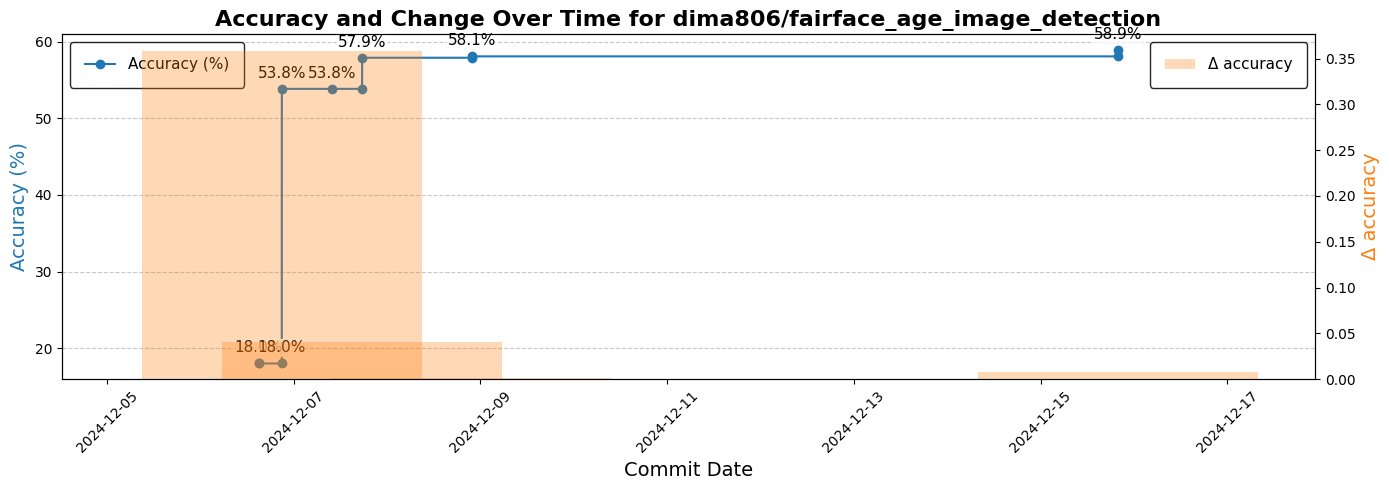
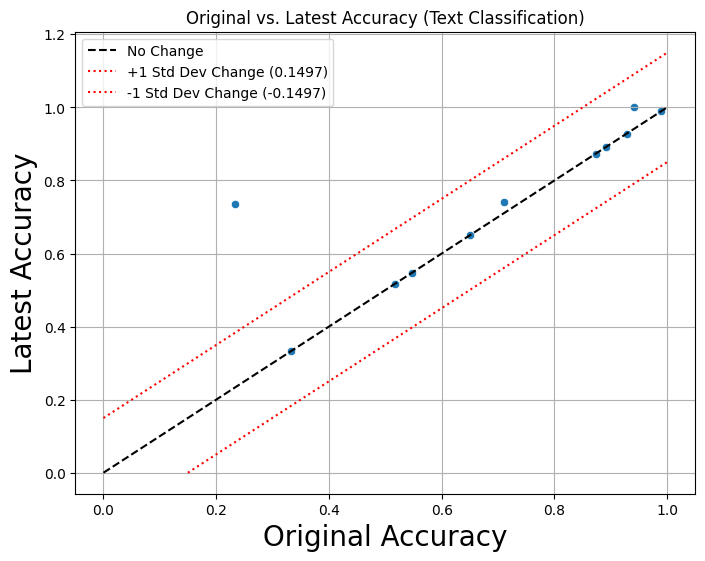
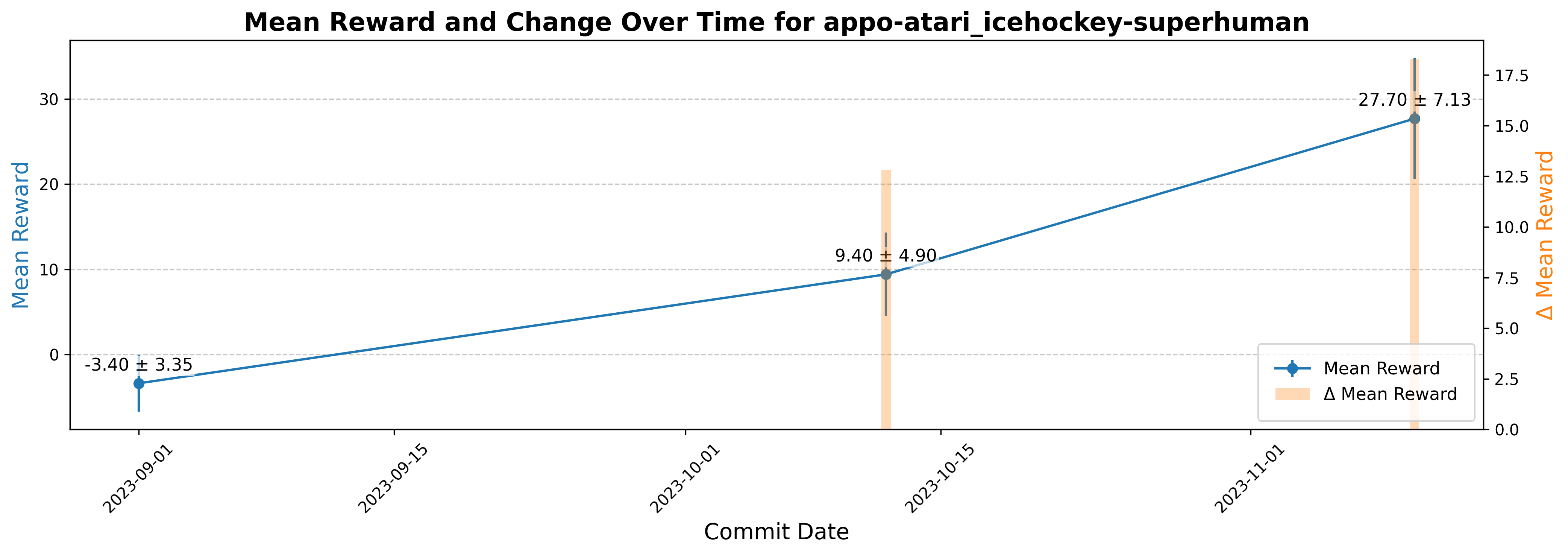
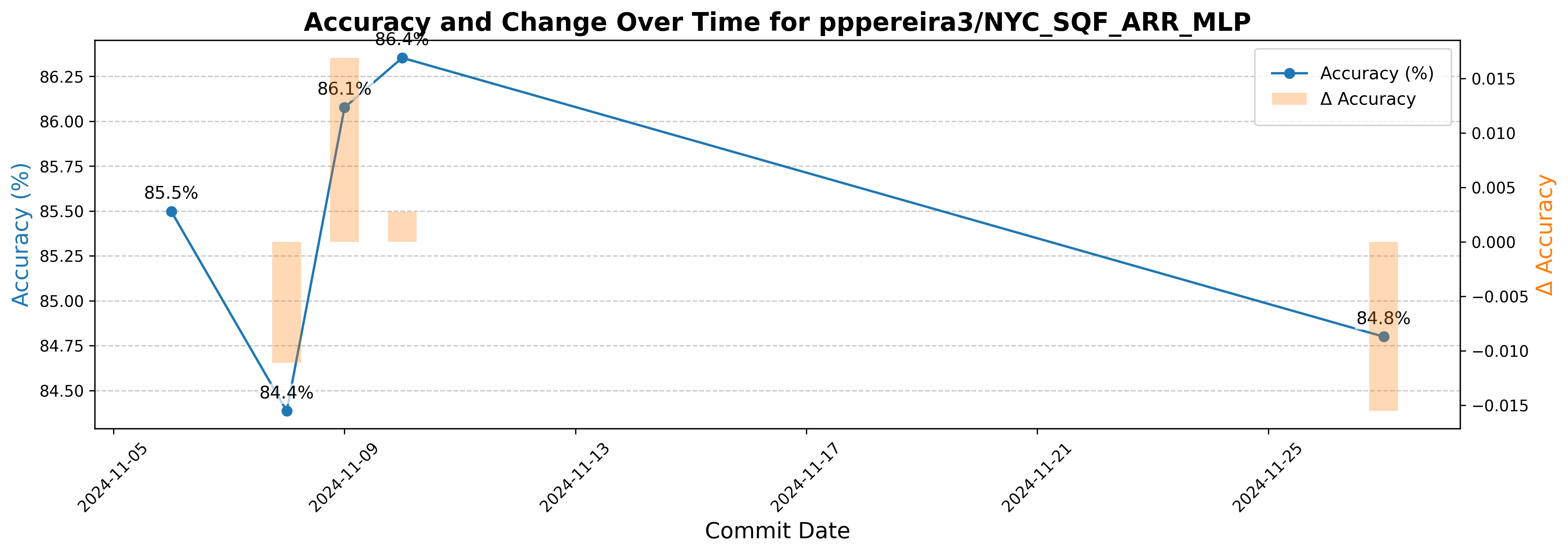
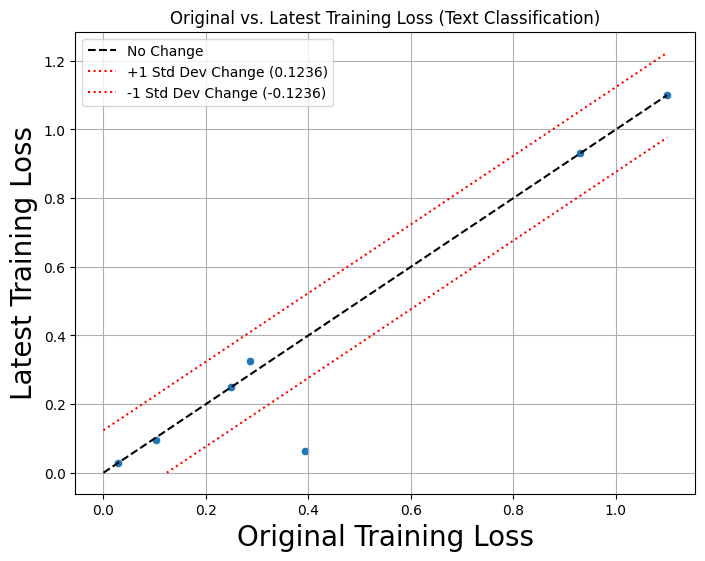
defining semantic preservation via metric stability,
which in our work is assessing and visualizing each
repository’s commit-specific trajectories over temporal
changes in their Model Card.
While our current
study defines semantic preservation