Title: Exploring possible vector systems for faster training of neural networks with preconfigured latent spaces
ArXiv ID: 2512.07509
Date: 2025-12-08
Authors: ** Nikita Gabdullin¹ ¹Joint Stock “Research and Production Company “Kryptonite” (러시아) E‑mail: n.gabdullin@kryptonite.ru **
📝 Abstract
The overall neural network (NN) performance is closely related to the properties of its embedding distribution in latent space (LS). It has recently been shown that predefined vector systems, specifically A n root system vectors, can be used as targets for latent space configurations (LSC) to ensure the desired LS structure. One of the main LSC advantages is the possibility of training classifier NNs without classification layers, which facilitates training NNs on datasets with extremely large numbers of classes (n classes ). This paper provides a more general overview of possible vector systems for NN training along with their properties and methods for vector system construction. These systems are used to configure LS of encoders and visual transformers to significantly speed up ImageNet-1K and 50k-600k classes LSC training. It is also shown that using the minimum number of LS dimensions (n min ) for specific n classes results in faster convergence. The latter has potential advantages for reducing the size of vector databases used to store NN embeddings.
💡 Deep Analysis
📄 Full Content
Exploring possible vector systems for faster training of neural
networks with preconfigured latent spaces
Nikita Gabdullin1
1Joint Stock "Research and production company "Kryptonite"
E-mail: n.gabdullin@kryptonite.ru
Abstract
The overall neural network (NN) performance is closely related to the properties of its
embedding distribution in latent space (LS). It has recently been shown that predefined
vector systems, specifically An root system vectors, can be used as targets for latent
space configurations (LSC) to ensure the desired LS structure. One of the main LSC
advantages is the possibility of training classifier NNs without classification layers, which
facilitates training NNs on datasets with extremely large numbers of classes (nclasses).
This paper provides a more general overview of possible vector systems for NN training
along with their properties and methods for vector system construction. These systems
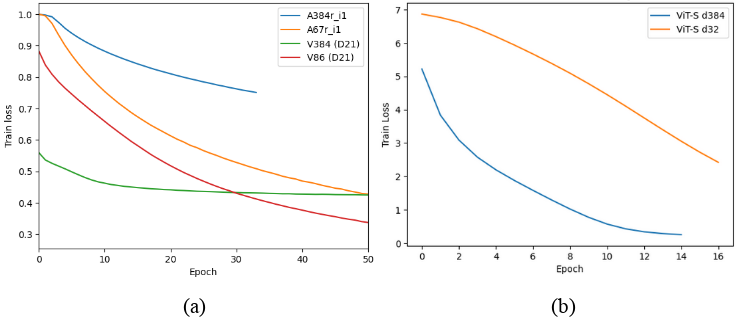
are used to configure LS of encoders and visual transformers to significantly speed up
ImageNet-1K and 50k-600k classes LSC training. It is also shown that using the minimum
number of LS dimensions (nmin) for specific nclasses results in faster convergence. The
latter has potential advantages for reducing the size of vector databases used to store NN
embeddings.
Keywords: Neural networks, supervised learning, latent space configuration, vector sys-
tems.
1
Introduction
Rapid spreading of neural networks (NNs) over the last decade has increased the demand
for NNs capable of producing high-accuracy predictions for unprecedented amounts of unseen
data. More and more applications require multi-domain capabilities like, for instance, simul-
taneously working with images and text, or sound and text, etc [1, 2]. This is achieved by
projecting data of different domains into the same NN latent space (LS). As in case of single-
domain data, the overall NN performance is closely related to the properties of its embedding
distribution. This has inspired researchers to propose methods that take LS properties into
consideration during training and inference [3, 4, 5].
It has previously been proposed that identifying key LS properties and using vector systems
with similar properties for LS configuration (LSC) can allow one to train classifier NNs which
have no classification layers [6]. This allows using the same NN architecture for datasets with
large and even variable numbers of classes (nclasses). The configuration used in that study
corresponded to root system An which has very well-spaced vectors used as targets for cluster
centers of NN embedding distributions. However, An interpolation is required to obtain a
1
arXiv:2512.07509v2 [cs.LG] 10 Dec 2025
sufficiently large number of vectors (nvects) for reasonable LS dimension (ndim) on datasets
with large nclasses. In this paper we study methods for constructing other vector systems with
a desired set of properties which do not require interpolation to accommodate a large number
of vectors while having an acceptable vector spacing. These vector systems are used to train
NNs to attain LSC features previously summarized in Section 6 in [6] (references to Sections
in [6] are hereafter referred to using forward slashes, e.g. Section /6/).
The rest of the paper is organized as follows: Section 2 provides a framework for vector
system search and their properties’ estimation, Section 3 experimentally verifies the feasi-
bility of vector system training and compares it with the conventional Cross-Entropy (CE)
loss training, Section 4 discusses the implications of the experimental results, and Section 5
concludes the paper.
2
Vector systems for latent space configuration
2.1
Obtaining vector systems through base vector coordinates permuta-
tions
For the purposes of this work, we define vector systems Vn as sets of unique n-dimensional
vectors obtained using specific rules, or generating functions, for a family of individual vectors
v
Vn = fgen(n) = set (vi) , i = 1...nvects,
(1)
where nvects is the number of vectors in the system. We are primarily interested in vector
systems with a large number of vectors which properties could facilitate fast NN training and
good inference performance. It has been previously shown that one of the most important
properties of vector systems is the separation between vectors used as training targets for NN
embedding cluster centers. Hence, we will use nvects and minimum cosine similarity (mcs) as
criteria for assessing the suitability of the vector system. The latter is defined as
mcs = min(abs(cossim(vi, vj))), i ̸= j, v ∈Vn.
(2)
As mentioned above, the main target is finding Vn with large nvects and low mcs. It has
been shown that NN training becomes complicated when mcs approaches 0.9 [6], so we obtain
the following inequality
0.5 < mcs ≪0.9,
(3)
which uses An vector spacing as the lower bound.
In general, vector systems can be constructed by choosing some base vector and obtaining
the complete system as its unique permutations [