Background: The deployment of personalized Large Language Models (LLMs) is currently constrained by the stability-plasticity dilemma. Prevailing alignment methods, such as Supervised Fine-Tuning (SFT), rely on stochastic weight updates that often incur an "alignment tax" -- degrading general reasoning capabilities.
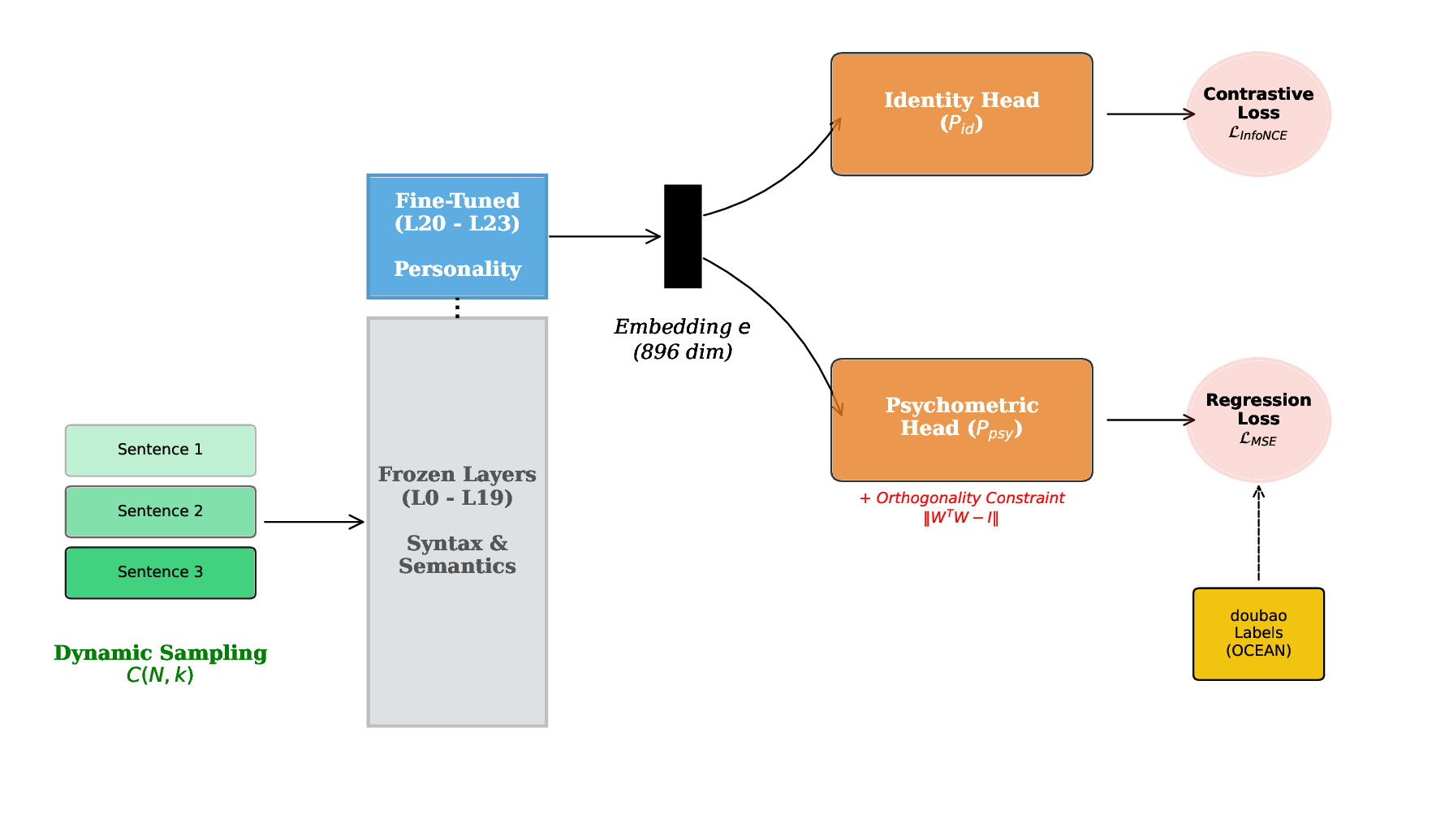
Methods: We propose the Soul Engine, a framework based on the Linear Representation Hypothesis, which posits that personality traits exist as orthogonal linear subspaces. We introduce SoulBench, a dataset constructed via dynamic contextual sampling. Using a dual-head architecture on a frozen Qwen-2.5 base, we extract disentangled personality vectors without modifying the backbone weights.
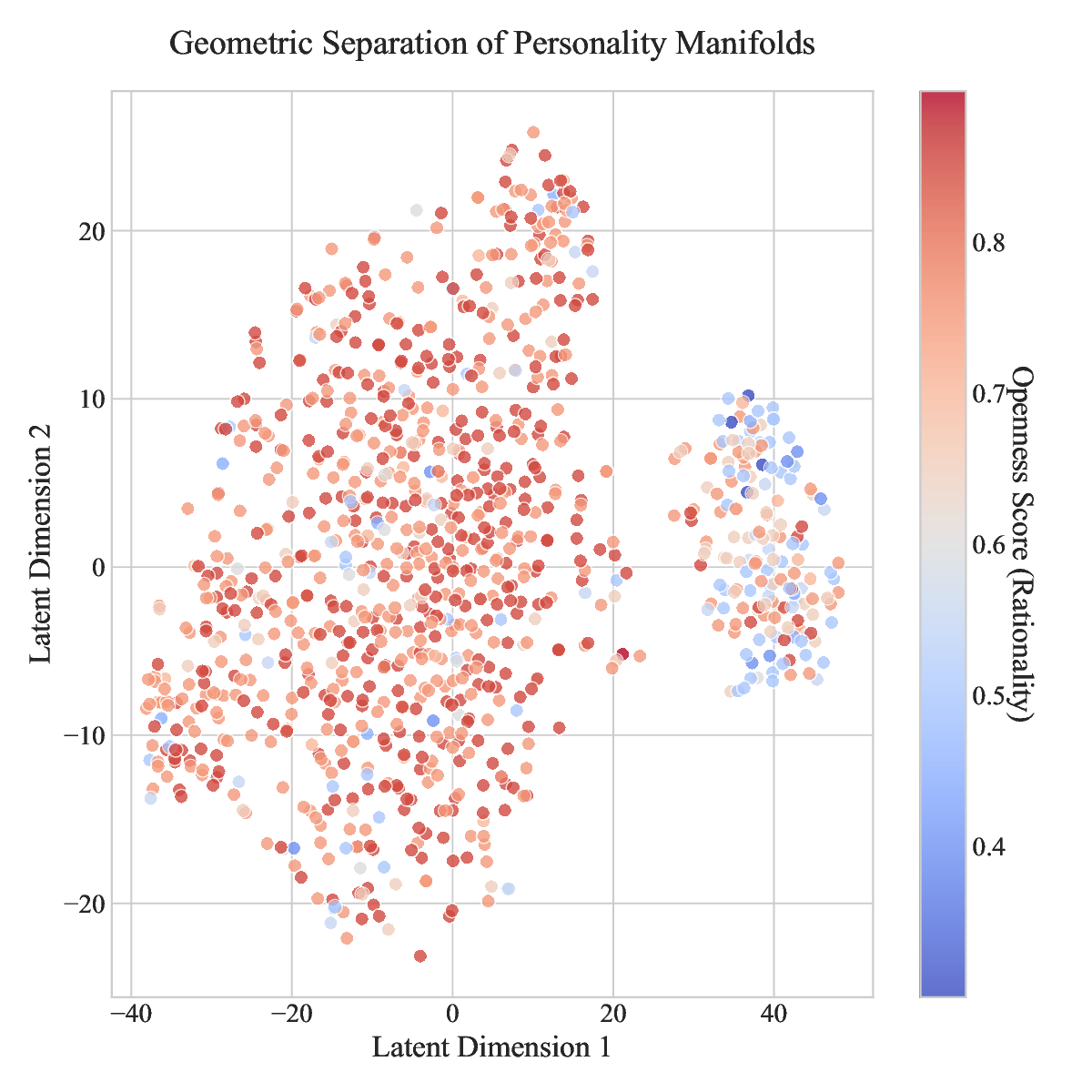
Results: Our experiments demonstrate three breakthroughs. First, High-Precision Profiling: The model achieves a Mean Squared Error (MSE) of 0.011 against psychological ground truth. Second, Geometric Orthogonality: T-SNE visualization confirms that personality manifolds are distinct and continuous, allowing for "Zero-Shot Personality Injection" that maintains original model intelligence. Third, Deterministic Steering: We achieve robust control over behavior via vector arithmetic, validated through extensive ablation studies.
Conclusion: This work challenges the necessity of fine-tuning for personalization. By transitioning from probabilistic prompting to deterministic latent intervention, we provide a mathematically rigorous foundation for safe, controllable AI personalization.
The evolution of Large Language Models (LLMs) is shifting from the pursuit of general-purpose reasoning to the creation of specialized, coherent agents [1,2]. Whether for immersive role-playing in open-world environments [3] or empathetic engagement in therapeutic settings, the utility of an AI agent increasingly depends on its ability to maintain a stable, distinct psychological profile. However, achieving this "personality alignment" without degrading the model's core intelligence remains one of the field's most persistent challenges.
The Stability-Plasticity Dilemma. Current paradigms for steering LLM behavior are trapped in a trade-off between stability and capability. The dominant approach, Supervised Fine-Tuning (SFT) and its parameter-efficient variants like LoRA [4], treats personality as a distribution of tokens to be learned via gradient descent. While effective for short-term style mimicry, this method is fundamentally destructive. By updating the model’s weights to fit a narrow stylistic corpus (e.g., “speak like a pirate”), SFT frequently induces catastrophic forgetting of the pre-trained general knowledge [5]. This phenomenon, known as the “alignment tax” [6], results in agents that possess strong stylistic traits but suffer from degraded logical reasoning and reduced problem-solving capabilities (e.g., lower MMLU scores).
Alternatively, In-Context Learning (ICL) or “System Prompting” attempts to steer behavior without weight updates. However, this approach lacks determinism. LLMs are prone to “persona drift” or “catastrophic amnesia” during extended interactions, as the transient instructions in the context window are diluted by the model’s inherent reinforcement learning (RLHF) priors [7]. Consequently, prompt-based agents are fragile, inconsistent, and easily “jailbroken.”
The Linear Representation Hypothesis. We posit that these limitations arise from a category error: treating personality as “knowledge” to be memorized rather than a “state” to be activated. Recent breakthroughs in Mechanistic Interpretability and Representation Engineering suggest a radical alternative: the Linear Representation Hypothesis [8,9]. This hypothesis suggests that high-level semantic concepts-such as sentiment, truthfulness, and potentially psychometric traits-are encoded as linear, orthogonal directions within the high-dimensional latent space of the Transformer [10]. If valid, this implies that the “soul” of the model (its personality) is geometrically distinct from its “brain” (its reasoning circuits). Therefore, steering a persona should not require global weight modification, but rather precise navigation within the existing latent manifold.
The Soul Engine. In this work, we introduce the Soul Engine, a framework that validates this hypothesis and mathematically disentangles personality from intelligence. Unlike the “black box” nature of SFT, our approach is geometric and deterministic. We identify the specific linear subspaces corresponding to the Big Five (OCEAN) personality traits and develop a method to manipulate them via vector arithmetic.
Our contributions are threefold:
Data Engineering (SoulBench): We address the scarcity of psychological ground truth by constructing a multi-source dataset using a novel Dynamic Contextual Sampling strategy (C(N, k)). This forces the encoder to learn invariant stylistic fingerprints rather than semantic content.
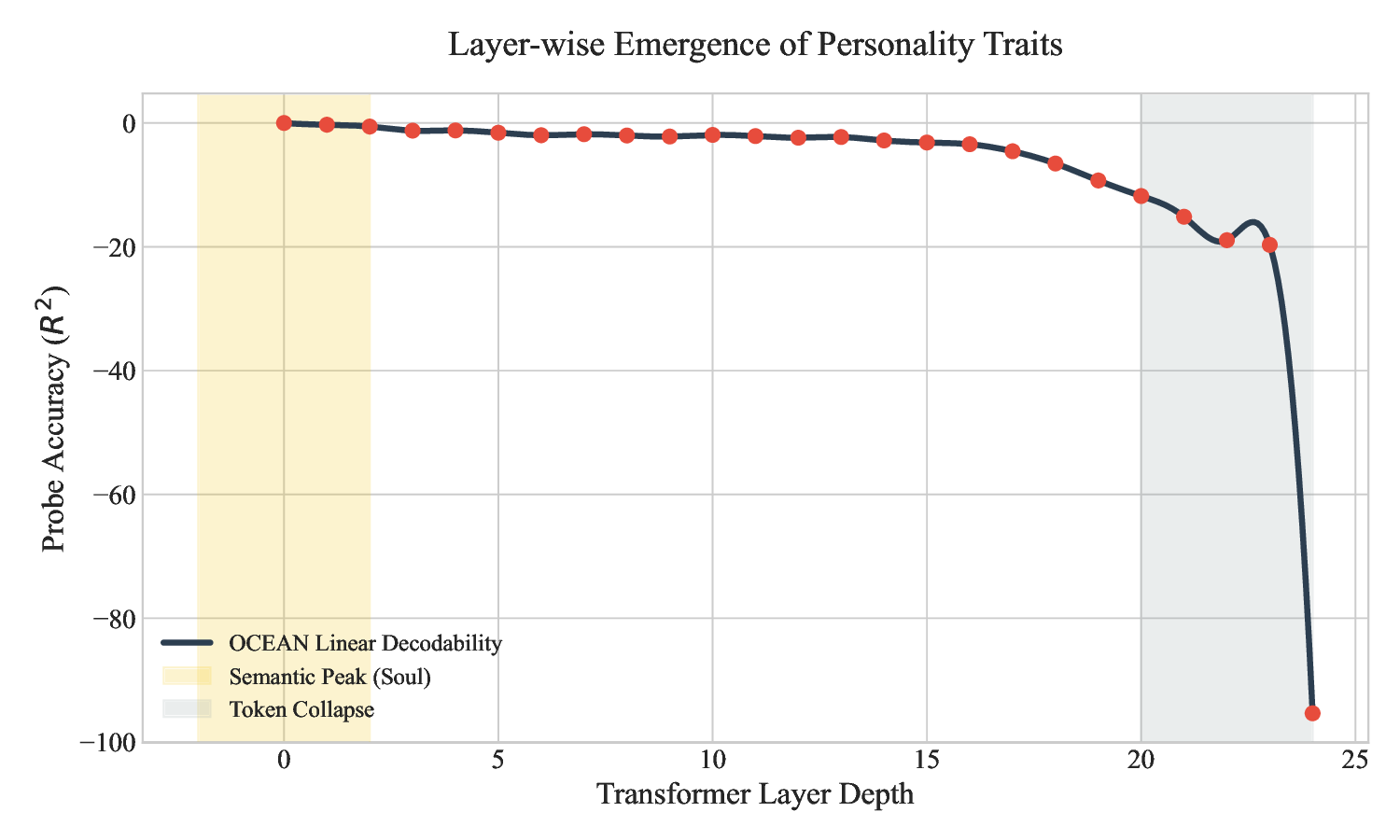
Mechanistic Discovery: Through layer-wise probing on a frozen Qwen-2.5 backbone [11], we demonstrate that personality representations emerge in the upper transformer blocks (Layers 18-24) and are largely orthogonal to reasoning vectors.
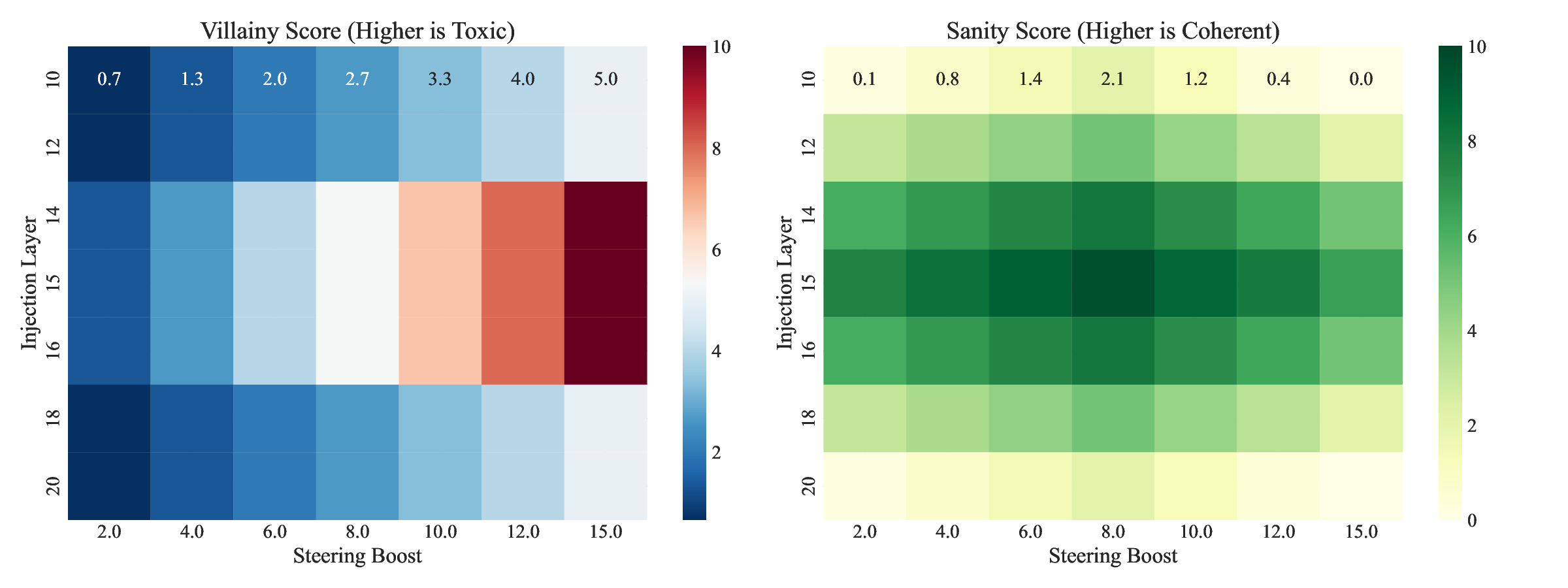
We achieve “Zero-Shot Personality Injection.” By adding computed vectors to the hidden states (e.g., ⃗ v N eutral + α • ⃗ v V illain ), we demonstrate precise control over behavior (MSE < 0.01) with negligible degradation in general intelligence benchmarks.
This work marks a paradigm shift from stochastic, destructive fine-tuning to deterministic, noninvasive latent intervention.
We propose the Soul Engine, a framework designed to extract and manipulate the geometric representation of personality within Large Language Models. Our approach is grounded in the premise that personality is a high-level abstraction that is linearly separable from low-level semantic content. The framework consists of three components: (1) SoulBench, a dataset constructed via combinatorial sampling; (2) The Scientific Soul Encoder, a dual-head probe architecture; and (3) A Deterministic Steering mechanism based on vector arithmetic.
A critical challenge in personality modeling is disentangling “style” (how something is said) from “content” (what is said). Static datasets often lead models to overfit to specific semantic phrases (e.g., associating “Joker” solely with the word “Batman”).
To address this, we introduce a Dynamic Contextual Sampling strategy. Let D c = {s 1 , s 2 , …, s M } be the corpus of sentences for a specific p
This content is AI-processed based on open access ArXiv data.