Leveraging KV Similarity for Online Structured Pruning in LLMs
Reading time: 5 minute
...
📝 Original Info
Title: Leveraging KV Similarity for Online Structured Pruning in LLMs
ArXiv ID: 2512.07090
Date: 2025-12-08
Authors: Jungmin Lee, Gwangeun Byeon, Yulhwa Kim, Seokin Hong
📝 Abstract
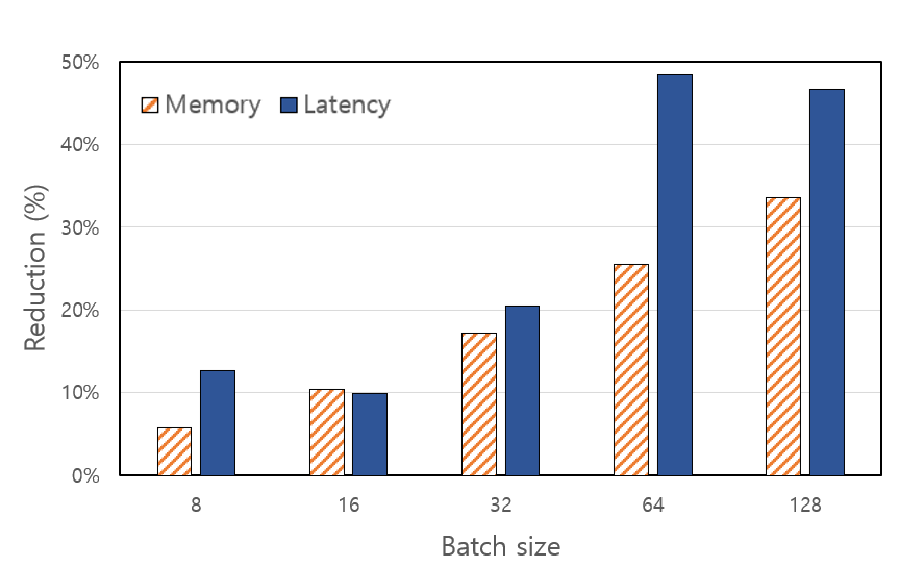
Pruning has emerged as a promising direction for accelerating large language model (LLM) inference, yet existing approaches often suffer from instability because they rely on offline calibration data that may not generalize across inputs. In this work, we introduce Token Filtering, a lightweight online structured pruning technique that makes pruning decisions directly during inference without any calibration data. The key idea is to measure token redundancy via joint key-value similarity and skip redundant attention computations, thereby reducing inference cost while preserving critical information. To further enhance stability, we design a variance-aware fusion strategy that adaptively weights key and value similarity across heads, ensuring that informative tokens are retained even under high pruning ratios. This design introduces no additional memory overhead and provides a more reliable criterion for token importance. Extensive experiments on LLaMA-2 (7B/13B), LLaMA-3 (8B), and Mistral (7B) demonstrate that Token Filtering consistently outperforms prior structured pruning methods, preserving accuracy on commonsense reasoning benchmarks and maintaining strong performance on challenging tasks such as MMLU, even with 50% pruning.
💡 Deep Analysis
📄 Full Content
Leveraging KV Similarity for Online Structured Pruning in LLMs
Jungmin Lee1, Gwangeun Byeon1, Yulhwa Kim1, Seokin Hong1
1Sungkyunkwan University
leejm518@g.skku.edu, kebyun@skku.edu, yulhwakim@skku.edu, seokin@skku.edu
Abstract
Pruning has emerged as a promising direction for accelerating large language model
(LLM) inference, yet existing approaches often suffer from instability because they rely
on offline calibration data that may not generalize across inputs. In this work, we
introduce Token Filtering, a lightweight online structured pruning technique that
makes pruning decisions directly during inference without any calibration data. The
key idea is to measure token redundancy via joint key–value similarity and skip redun-
dant attention computations, thereby reducing inference cost while preserving critical
information. To further enhance stability, we design a variance-aware fusion strategy
that adaptively weights key and value similarity across heads, ensuring that informa-
tive tokens are retained even under high pruning ratios. This design introduces no
additional memory overhead and provides a more reliable criterion for token impor-
tance. Extensive experiments on LLaMA-2 (7B/13B), LLaMA-3 (8B), and Mistral (7B)
demonstrate that Token Filtering consistently outperforms prior structured pruning
methods, preserving accuracy on commonsense reasoning benchmarks and maintain-
ing strong performance on challenging tasks such as MMLU, even with 50% pruning.
1
Introduction
Large Language Models (LLMs) [Touvron et al., 2023, Vaswani et al., 2017] have achieved remark-
able success across a wide range of tasks, including natural language understanding, reasoning,
and generation, and they now serve as the foundation for many state-of-the-art AI applications
[OpenAI, 2023]. However, their deployment in real-world scenarios remains challenging due to the
models’ highly complex architectures and massive parameter counts, which result in substantial
inference latency and considerable resource consumption.
Pruning is a widely studied technique for accelerating neural networks. Unstructured pruning
[Frantar and Alistarh, 2023] adaptively removes individual weights and achieves high compression
with modest accuracy loss, but practical speedups often require specialized hardware. Structured
pruning [Ma et al., 2023] removes larger components such as attention heads or modules, which is
more hardware-friendly but typically causes non-trivial accuracy degradation.
While effective in certain settings, most pruning methods are applied offline using a calibration
dataset, which can lead to overfitting and reduced generalization to downstream tasks [Williams
and Aletras, 2023]. To overcome these limitations, online pruning has emerged as a promising
alternative, making pruning decisions dynamically during inference based on real inputs. Unlike
offline approaches, it cannot rely on global profiling with calibration data and must instead operate
adaptively on local features at runtime.
This design presents new challenges: the absence of
1
arXiv:2512.07090v1 [cs.CL] 8 Dec 2025
global saliency information and the need for extremely lightweight decision mechanisms, since any
additional computation directly increases inference latency.
Recently, token pruning has emerged as a complementary strategy that directly reduces the
sequence length by discarding tokens deemed less informative during inference. By shortening the
effective context, token pruning alleviates the quadratic complexity of self-attention and yields
substantial reductions in FLOPs and latency. Learned Token Pruning (LTP) [Kim et al., 2022]
adaptively drops tokens based on learned attention thresholds, while Zero-TPrune [Wang et al.,
2024] leverages attention graphs of pre-trained models to enable zero-shot pruning without retrain-
ing. More recently, LazyLLM [Fu et al., 2024] applied token pruning to large language models
and achieved over 2× speedup in long-context inference, but such methods still rely on computing
attention scores to estimate token importance, which reduces the potential benefits of pruning by
adding extra computation.
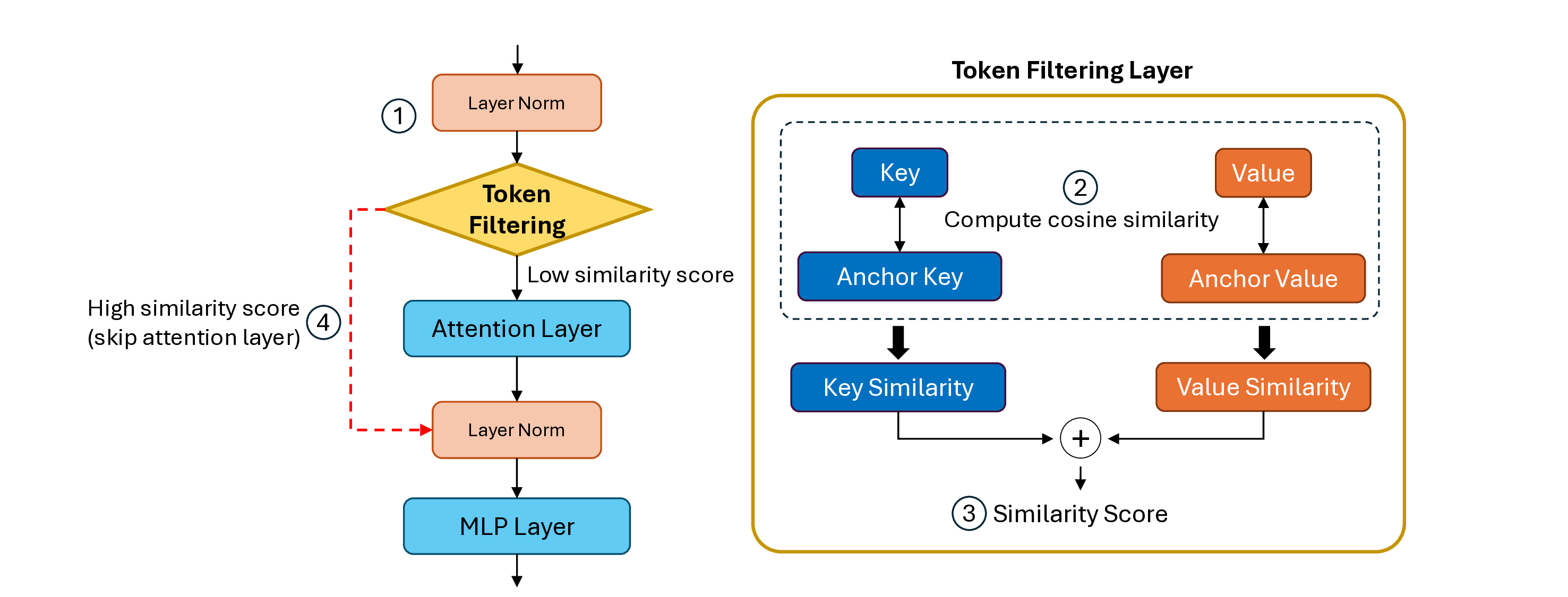
In this work, we propose Token Filtering, an online dynamic structured pruning technique
that directly reduces inference cost by filtering out redundant tokens in real time and skipping
their attention computations. Unlike prior token pruning methods that rely on attention scores
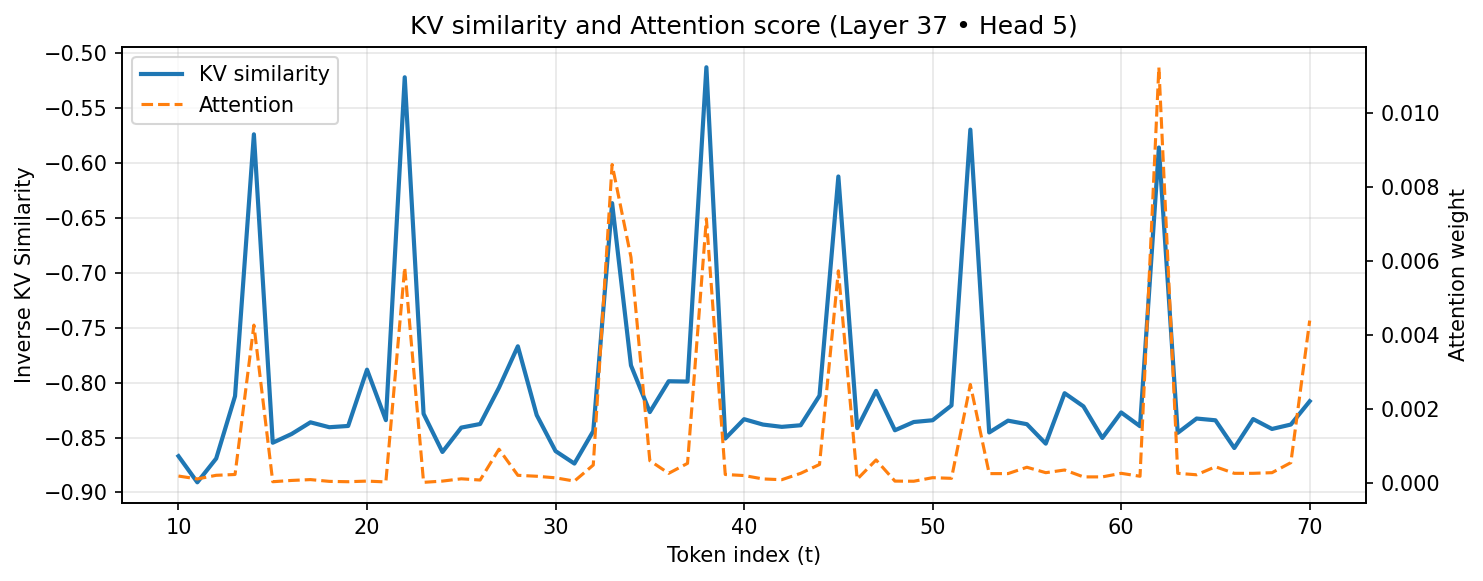
to estimate token importance, our approach leverages key–value similarity as a lightweight
redundancy signal, thereby avoiding the overhead of score computation. The key idea is that tokens
highly similar to past context are unlikely to contribute novel information and can thus be pruned
without harming accuracy. To quantify this redundancy, Token Filtering uses both key similarity
and value similarity, defined as the cosine similarity between the current key or value and the
mean representation of all previous tokens. In multi-head attention, where