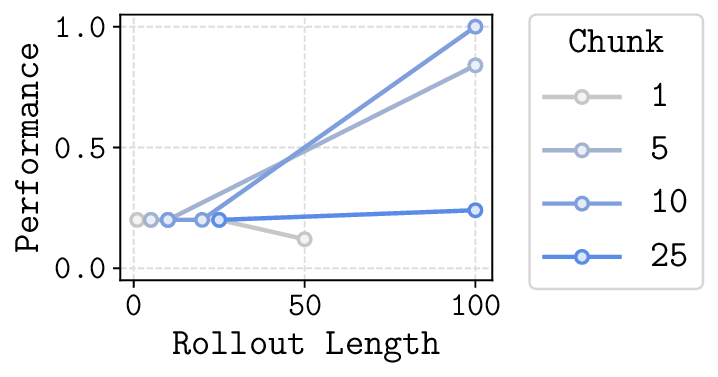
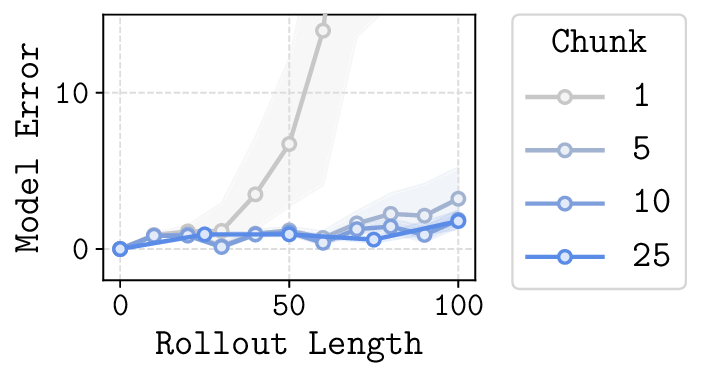
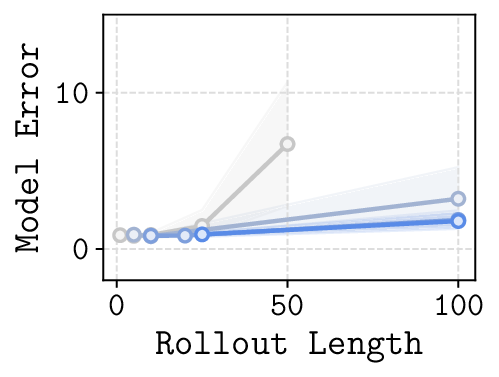
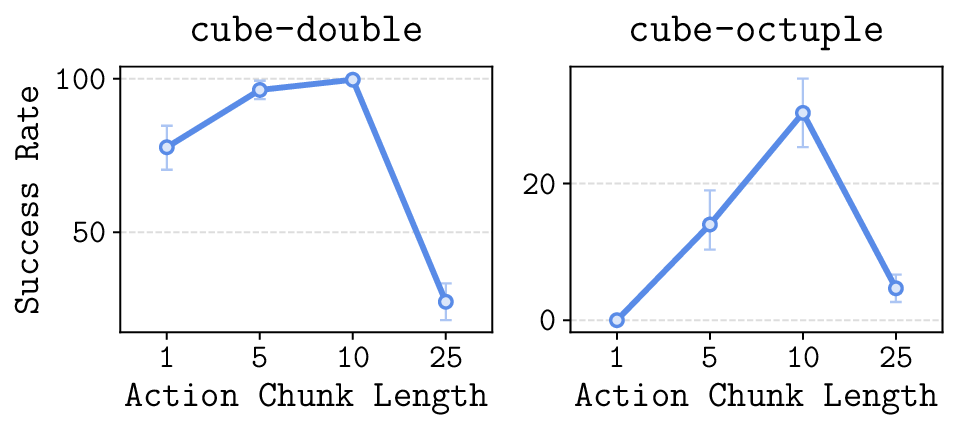
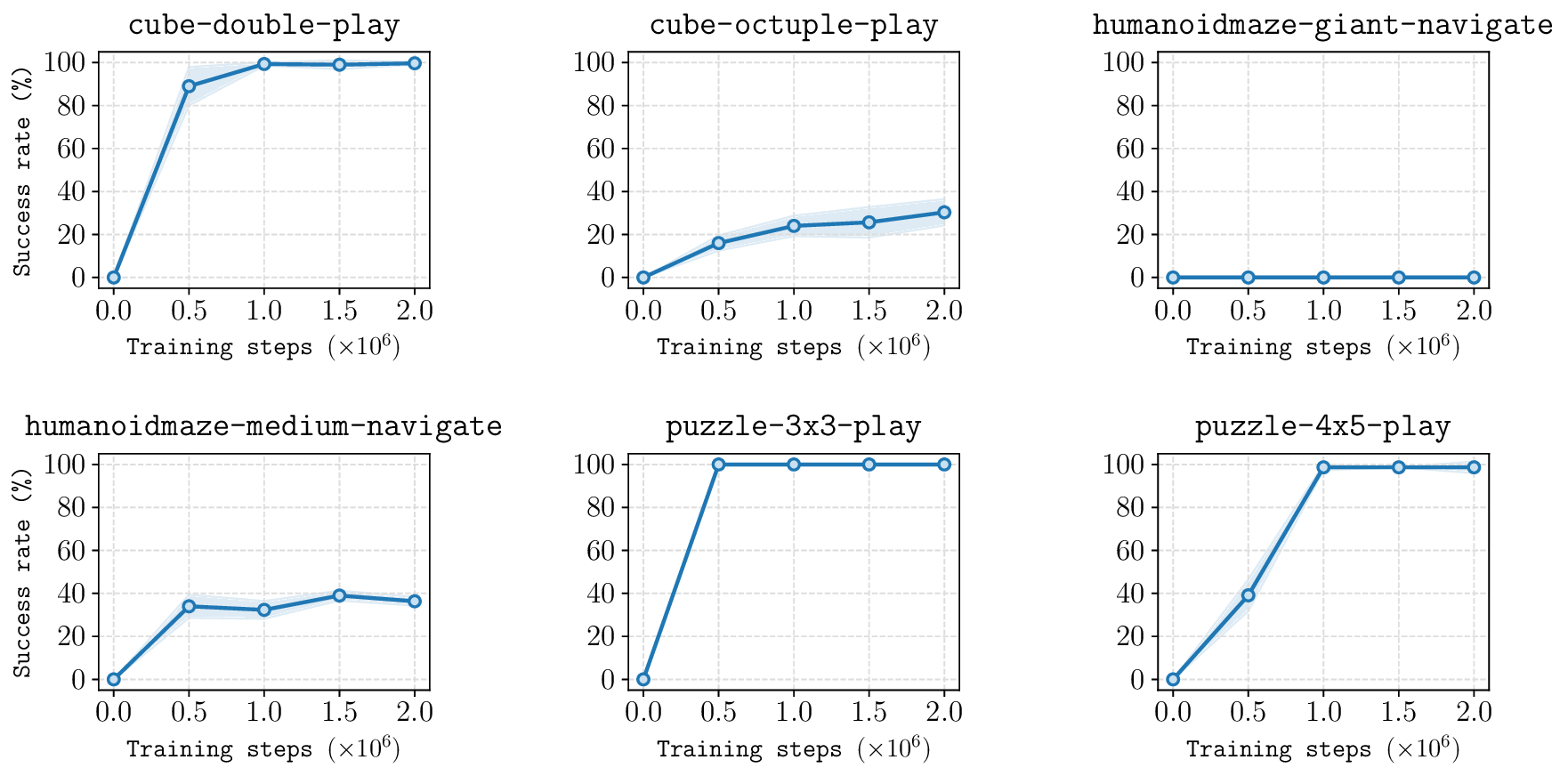
In this paper, we study whether model-based reinforcement learning (RL), in particular model-based value expansion, can provide a scalable recipe for tackling complex, long-horizon tasks in offline RL. Model-based value expansion fits an on-policy value function using length-n imaginary rollouts generated by the current policy and a learned dynamics model. While larger n reduces bias in value bootstrapping, it amplifies accumulated model errors over long horizons, degrading future predictions. We address this trade-off with an \emph{action-chunk} model that predicts a future state from a sequence of actions (an "action chunk") instead of a single action, which reduces compounding errors. In addition, instead of directly training a policy to maximize rewards, we employ rejection sampling from an expressive behavioral action-chunk policy, which prevents model exploitation from out-of-distribution actions. We call this recipe \textbf{Model-Based RL with Action Chunks (MAC)}. Through experiments on highly challenging tasks with large-scale datasets of up to 100M transitions, we show that MAC achieves the best performance among offline model-based RL algorithms, especially on challenging long-horizon tasks.
Figure 1: Two main components of MAC. (Left) Action-chunk models predict a future state given a sequence of actions (an "action chunk"), reducing compounding errors and enabling long-horizon model rollouts. (Right) Rejection sampling from an expressive (flow) behavioral action-chunk policy enables modeling multi-modal action distributions, while preventing model exploitation from out-of-distribution actions.
Offline reinforcement learning (RL) holds the promise of training effective decision-making agents from data, leveraging large-scale datasets. While offline RL has achieved successes in diverse domains (Kumar et al., 2023;Springenberg et al., 2024), its ability to handle complex, long-horizon tasks remains an open question. Prior work has shown that standard, model-free offline RL often struggles to scale to such tasks (Park et al., 2025b), hypothesizing that the cause lies in the pathologies of off-policy, temporal difference (TD) value learning.
In this work, we investigate whether an alternative paradigm, namely model-based RL, and in particular model-based value expansion (Feinberg et al., 2018), provides a more effective recipe for long-horizon offline RL. In this recipe, we first train a dynamics model, and fit an on-policy value function by rolling out the current policy within the learned model, which is then used to update the policy. Since on-policy value learning has demonstrated promising scalability to long-horizon tasks (Berner et al., 2019;Guo et al., 2025), in contrast to the relatively limited evidence for off-et al., 2020;Yu et al., 2021;Rigter et al., 2022;Sun et al., 2023;Sims et al., 2024;Lu et al., 2023a), (2) planning (Testud et al., 1978;Argenson & Dulac-Arnold, 2021;Chitnis et al., 2024;Zhou et al., 2025), and (3) value estimation (Feinberg et al., 2018;Jeong et al., 2023;Park & Lee, 2025;Hafner et al., 2025), with diverse techniques to prevent model exploitation and distributional shift, such as ensemble-based uncertainty estimation. Our method is based on model-based value expansion and falls in the third category. However, unlike most of the previous works in this category, we employ an action-chunk model instead of a single-step dynamics model to reduce effective horizons and thus error accumulation.
Horizon reduction and model-based RL. The curse of horizon is a fundamental challenge in reinforcement learning (Liu et al., 2018;Park et al., 2025b). In the context of model-free RL, previous studies have proposed diverse techniques to reduce effective horizon lengths, such as n-step returns to reduce the number of Bellman updates (Sutton & Barto, 2005), and hierarchical policies to reduce the length of the effective policy horizon (Nachum et al., 2018;Park et al., 2023). Long horizons are a central challenge in model-based RL too, since model rollouts suffer from compounding errors as the horizon grows. Prior works in model-based RL address this challenge with trajectory modeling (Janner et al., 2021;2022), hierarchical planning (Li et al., 2023;Chen et al., 2024), skillbased action abstraction (Shi et al., 2022), and action-chunk multi-step dynamics modeling (Asadi et al., 2019;Lambert et al., 2021;Zhao et al., 2024;Zhou et al., 2025). Our work is closest to prior works that use action-chunk dynamics models. However, these works either use the action-chunk model only for planning without having the full actor-critic loop (Asadi et al., 2019;Lambert et al., 2021;Zhou et al., 2025), or model the entire state-action chunks (Zhao et al., 2024). Unlike these prior works, we perform on-policy value learning with an action-chunk model and policy, while not involving additional planning or full trajectory generation.
Problem setting. We consider a Markov decision process (MDP) defined as M = (S, A, r, µ, p), where S is the state space, A = R d is the action space, r(s, a) : S × A → R is the reward function, µ(s) ∈ ∆(S) is the initial state distribution, and p(s ′ | s, a) : S × A → ∆(S) is the transition dynamics kernel. ∆(X ) denotes the set of probability distributions on a space X , and we denote placeholder variables in gray. For a policy π(a | s) : S → ∆(A), we define
where γ ∈ (0, 1) denotes the discount factor, τ = (s 0 , a 0 , r 0 , s 1 , . . .) denotes a trajectory, and p π denotes the trajectory distribution induced by µ, p, and π. The goal of offline RL is to find a policy π that maximizes E s0∼µ(s0) [V π (s 0 )] from an offline dataset D = {τ (i) } consisting of previously collected trajectories, with no environment interactions.
Flow matching. Flow matching (Lipman et al., 2023;Albergo & Vanden-Eijnden, 2023;Liu et al., 2023) is a technique in generative modeling to train a velocity field whose flow generates a target distribution of interest. As with diffusion models (Sohl-Dickstein et al., 2015;Ho et al., 2020), flow models iteratively transform a noise distribution to the target distribution, and have been shown to be highly expressive and scalable (Esser et al.,
This content is AI-processed based on open access ArXiv data.