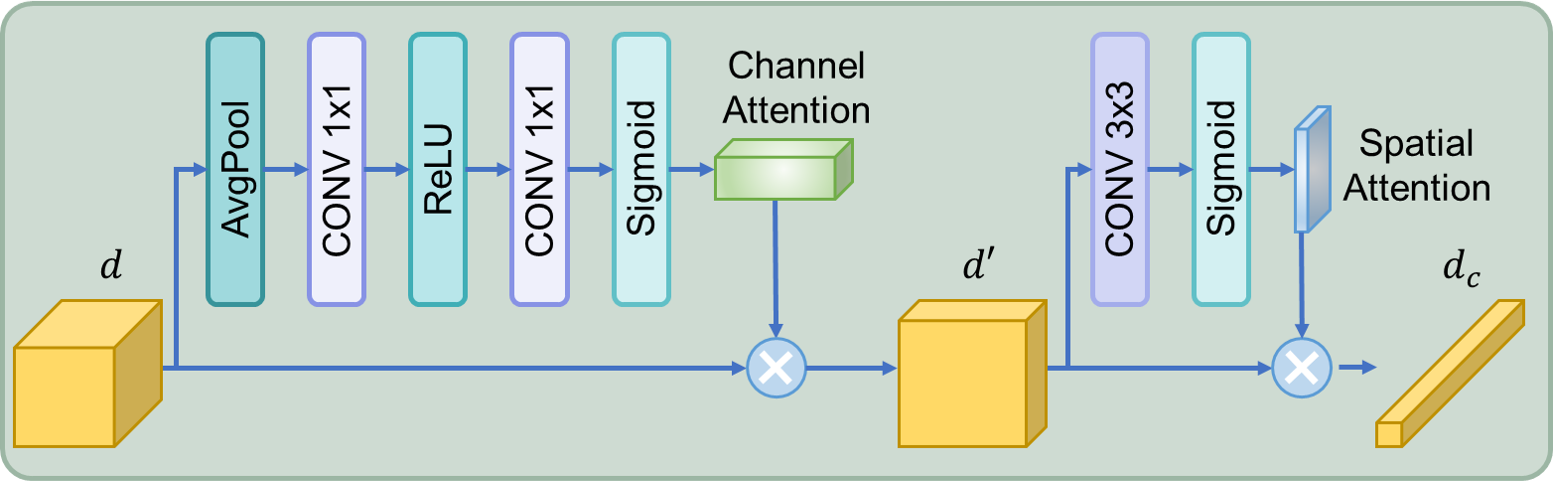
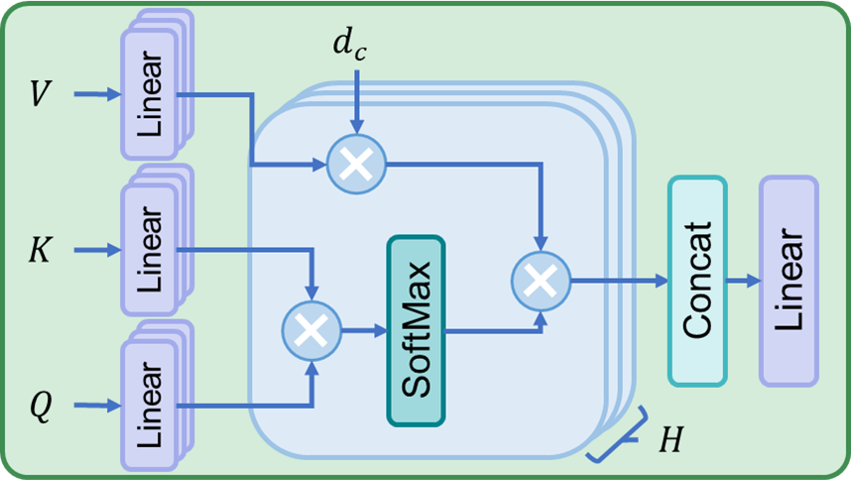
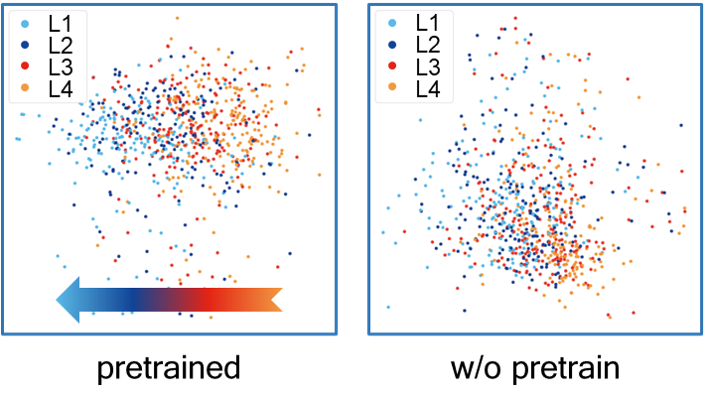
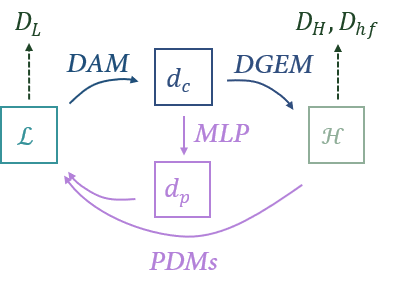
Title: DGGAN: Degradation Guided Generative Adversarial Network for Real-time Endoscopic Video Enhancement
ArXiv ID: 2512.07253
Date: 2025-12-08
Authors: Handing Xu, Zhenguo Nie, Tairan Peng, Huimin Pan, Xin-Jun Liu
📝 Abstract
Endoscopic surgery relies on intraoperative video, making image quality a decisive factor for surgical safety and efficacy. Yet, endoscopic videos are often degraded by uneven illumination, tissue scattering, occlusions, and motion blur, which obscure critical anatomical details and complicate surgical manipulation. Although deep learning-based methods have shown promise in image enhancement, most existing approaches remain too computationally demanding for real-time surgical use. To address this challenge, we propose a degradation-aware framework for endoscopic video enhancement, which enables real-time, high-quality enhancement by propagating degradation representations across frames. In our framework, degradation representations are first extracted from images using contrastive learning. We then introduce a fusion mechanism that modulates image features with these representations to guide a single-frame enhancement model, which is trained with a cycle-consistency constraint between degraded and restored images to improve robustness and generalization. Experiments demonstrate that our framework achieves a superior balance between performance and efficiency compared with several state-of-the-art methods. These results highlight the effectiveness of degradation-aware modeling for real-time endoscopic video enhancement. Nevertheless, our method suggests that implicitly learning and propagating degradation representation offer a practical pathway for clinical application.
💡 Deep Analysis
📄 Full Content
DGGAN: DEGRADATION GUIDED GENERATIVE ADVERSARIAL
NETWORK FOR REAL-TIME ENDOSCOPIC VIDEO ENHANCEMENT
Handing Xu, Zhenguo Nie ∗, Tairan Peng, Xin-Jun Liu
Department of Mechanical Engineering,
State Key Laboratory of Tribology in Advanced Equipment,
Beijing Key Laboratory of Transformative High-end Manufacturing Equipment and Technology
Tsinghua University
Beijing, China
{Handing Xu, Zhenguo Nie}xhd21@mails.tsinghua.edu.cn, zhenguonie@tsinghua.edu.cn
Huimin Pan
Department of Mechanical Engineering
Tsinghua University
Beijing, China
ABSTRACT
Endoscopic surgery relies on intraoperative video, making image quality a decisive factor for surgical
safety and efficacy. Yet, endoscopic videos are often degraded by uneven illumination, tissue scatter-
ing, occlusions, and motion blur, which obscure critical anatomical details and complicate surgical
manipulation. Although deep learning-based methods have shown promise in image enhancement,
most existing approaches remain too computationally demanding for real-time surgical use. To
address this challenge, we propose a degradation-aware framework for endoscopic video enhance-
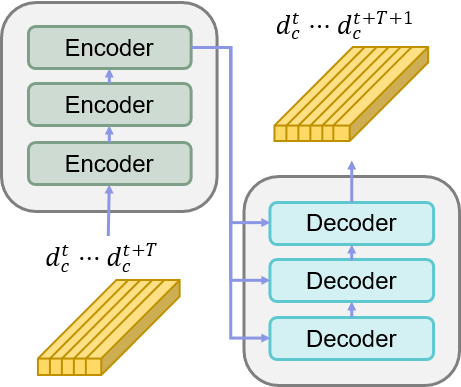
ment, which enables real-time, high-quality enhancement by propagating degradation representations
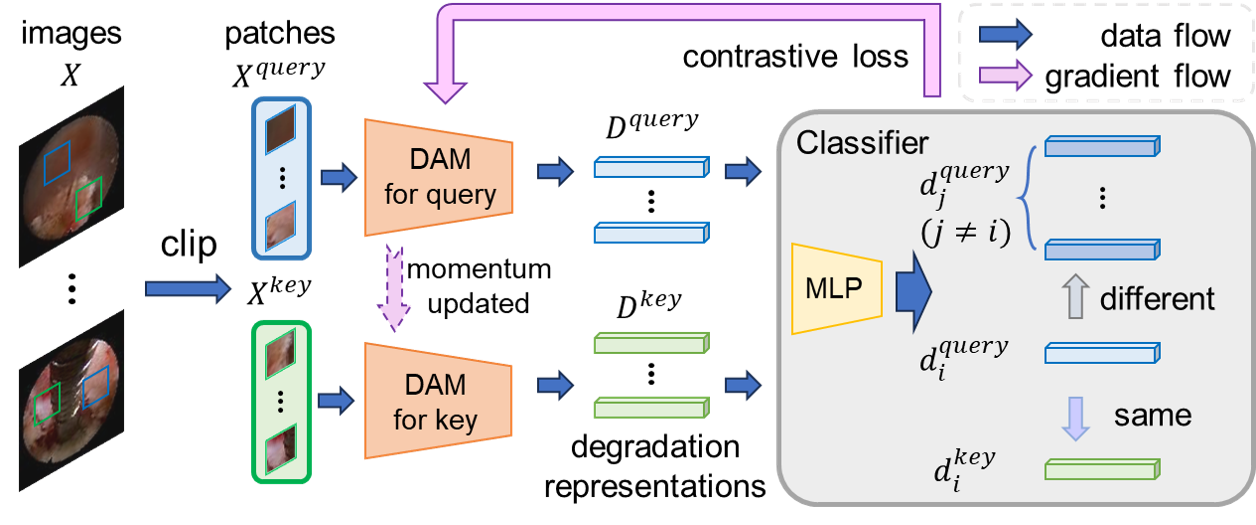
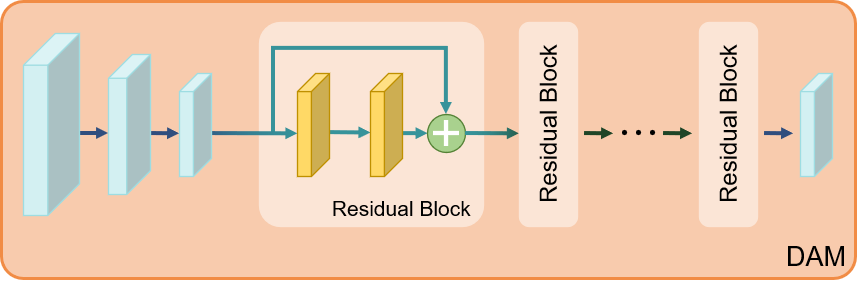
across frames. In our framework, degradation representations are first extracted from images using
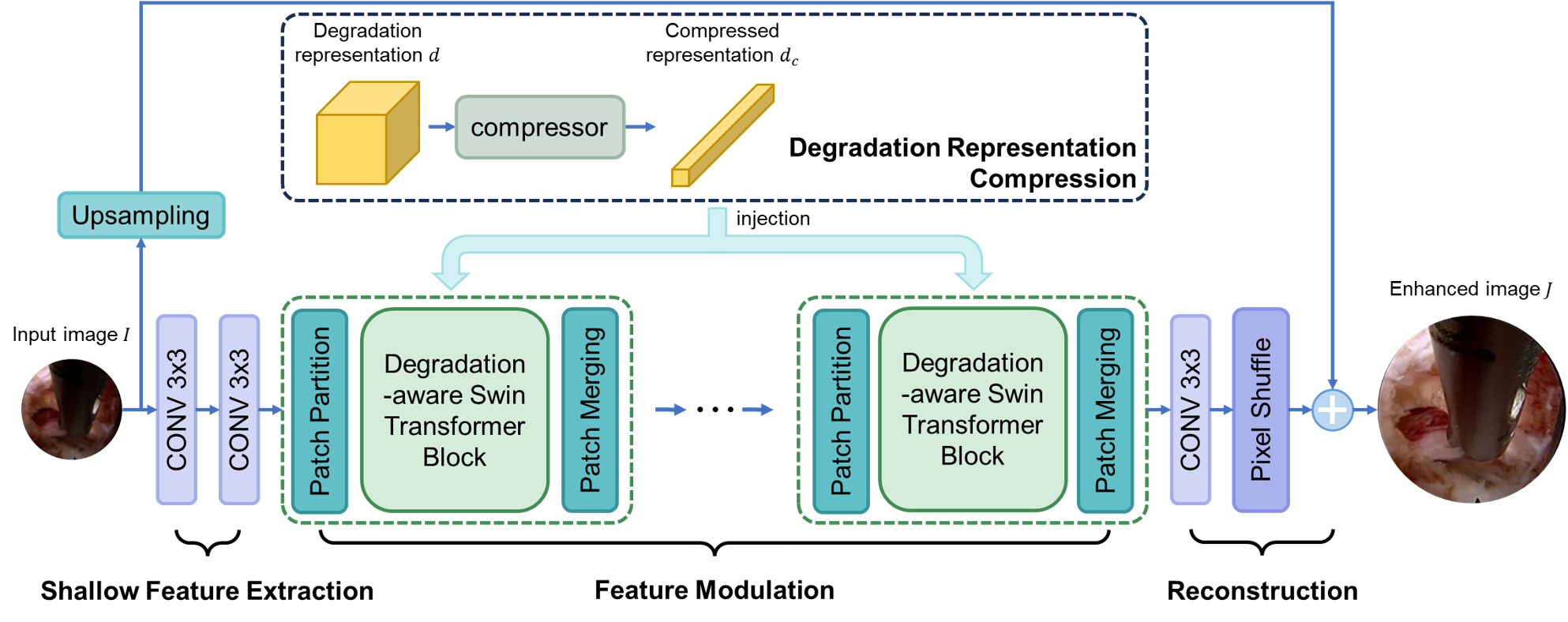
contrastive learning. We then introduce a fusion mechanism that modulates image features with these
representations to guide a single-frame enhancement model, which is trained with a cycle-consistency
constraint between degraded and restored images to improve robustness and generalization. Ex-
periments demonstrate that our framework achieves a superior balance between performance and
efficiency compared with several state-of-the-art methods. These results highlight the effectiveness of
degradation-aware modeling for real-time endoscopic video enhancement. Nevertheless, our method
suggests that implicitly learning and propagating degradation representation offer a practical pathway
for clinical application.
Keywords Real-time Video enhancement · Degradation representation · Cyclical consistency · Endoscopic video
1
Introduction
Minimally invasive surgery (MIS) has become a cornerstone of modern clinical practice, offering reduced surgical
trauma, shorter recovery times, and improved postoperative outcomes compared with traditional open procedures.
Among various MIS techniques, endoscopic surgery plays a particularly critical role, as it enables surgeons to access
deep or delicate anatomical regions through narrow working channels with minimal disruption of surrounding tissues.
For example, in spine surgery, endoscopic approaches have been increasingly adopted for the treatment of conditions
such as lumbar disc herniation, spinal stenosis, and degenerative diseases[1]. Unlike open spine procedures, spine
endoscopy relies entirely on intraoperative video as the sole source of visual feedback, making video quality a decisive
factor for surgical safety and efficacy.
∗Corresponding author
arXiv:2512.07253v1 [cs.CV] 8 Dec 2025
Endoscopic Video Enhancement
However, endoscopic videos are often far from ideal. The imaging environment inside the human body presents a
variety of challenges: illumination is highly non-uniform due to directional light sources; optical scattering by tissues
and fluids degrades image contrast; blood, smoke, and surgical instruments frequently occlude the field of view; and
camera motion or limited depth of field can introduce blur. These degradations collectively compromise the visibility of
fine anatomical structures, hinder accurate surgical manipulation, and may increase the risk of complications. In spine
endoscopy, where the operative corridor is typically only a few millimeters in diameter and critical neural structures lie
in close proximity, such limitations become particularly critical. Even subtle degradations in video clarity can obscure
vital anatomical cues and complicate intraoperative decision-making.
To address these challenges, video enhancement techniques have been widely investigated. Conventional approaches [2,
3, 4, 5] can provide modest improvements in brightness or contrast, but they often fail under severe degradations
and may amplify noise or introduce artifacts [6]. More recently, deep learning-based methods have demonstrated
remarkable success in image restoration tasks, including denoising, deblurring [7], and super-resolution [8, 9], by
leveraging large-scale data and learning complex degradation models. These techniques have been gradually extended
to the domain of endoscopic imaging, with promising results in improving surgical visibility.
Nevertheless, several critical limitations remain. Most existing methods are designed and evaluated in offline settings,
where computational efficiency is not a primary concern. As a result, they often involve complex models or iterative
optimization procedures that are computationally expensive and unsuitable for depl