Behavior-cloning based visuomotor policies enable precise manipulation but often inherit the slow, cautious tempo of human demonstrations, limiting practical deployment. However, prior studies on acceleration methods mainly rely on statistical or heuristic cues that ignore task semantics and can fail across diverse manipulation settings. We present ESPADA, a semantic and spatially aware framework that segments demonstrations using a VLM-LLM pipeline with 3D gripper-object relations, enabling aggressive downsampling only in non-critical segments while preserving precision-critical phases, without requiring extra data or architectural modifications, or any form of retraining. To scale from a single annotated episode to the full dataset, ESPADA propagates segment labels via Dynamic Time Warping (DTW) on dynamics-only features. Across both simulation and real-world experiments with ACT and DP baselines, ESPADA achieves approximately a 2x speed-up while maintaining success rates, narrowing the gap between human demonstrations and efficient robot control.
Imitation learning (IL) has emerged as a central paradigm in robot learning [1]- [7], offering a practical alternative to reinforcement learning by bypassing explicit reward design and costly online exploration. By leveraging expert demonstrations, IL enables robots to acquire manipulation skills in a data-efficient manner. While early applications were limited to simple pick-and-place tasks, recent advances have extended IL to long-horizon [3], contact-rich [8], and visually complex manipulations [1], [9]. Widely used policies such as Action Chunking Transformer (ACT) [1] and Diffusion Policy (DP) [2] illustrate this practicality and serve as strong baselines for imitation-based manipulation.
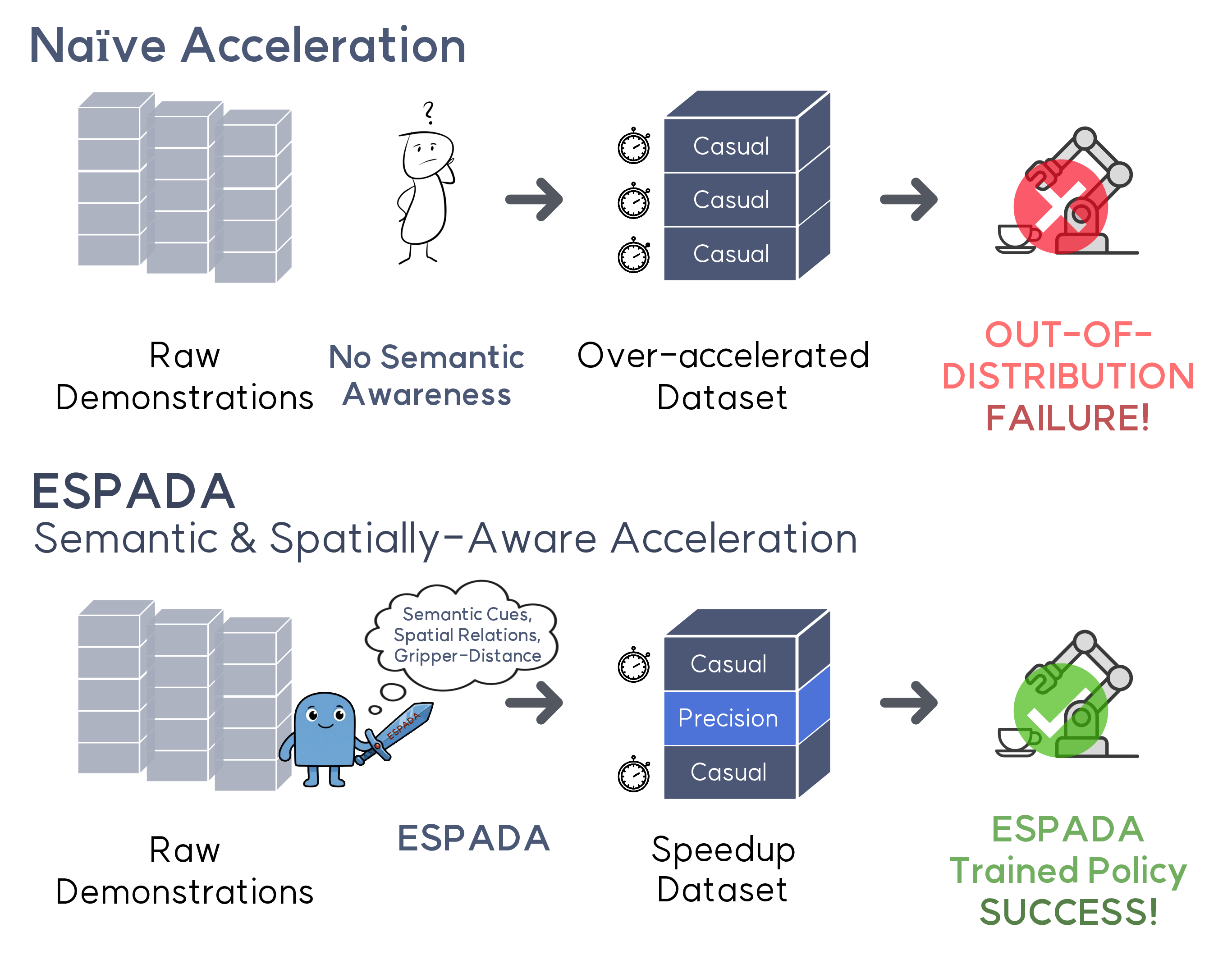
Despite these successes, deployments in IL often suffer from insufficient execution speed. Human demonstrators tend to act slowly and cautiously to ensure safety and maximize task success. Moreover, prior studies have intentionally adopted slow demonstrations due to three main factors: (i) camera frame-rate constraints, (ii) research that slower motions can improve training stability, and (iii) the anthropomorphism gap between human kinematics and robotic morphology [10]. In short, these factors collectively bias human operators toward conservative motions, producing Fig. 1: Naïve and heuristic-based acceleration breaks precision behavior in manipulation tasks. Our model, ESPADA uses semantics and 3D spatial cues to preserve contact-critical phases while accelerating transit motions.
trajectories that are far more temporally saturated than necessary, thereby causing learned policies to inherit this slow tempo at execution time [11].
Simply replaying demonstrations faster or uniformly subsampling observations can push trajectories out of distribution, inducing compounding error and degraded performance. In response, several methods have sought to improve execution efficiency; SAIL [12] leverages AWE [13] features with DBSCAN [14] clustering to identify coarse phases, and DemoSpeedup [15] identifies casual segments by estimating action-distribution entropy with a pre-trained proxy policy, treating high-entropy regions as safe to accelerate. However, these scenario-assumption based approaches rely on handcrafted heuristics, and the narrow scenario space makes them fragile to even mild deviations.
SAIL [12], for instance, implicitly assumes that precisioncritical behavior manifests as densely sampled regions in trajectory space and implements this assumption via clustering, but a density-based view of precision is intuitively valid only in highly restricted scenarios. On the other hand, DemoSpeedup [15] assumes that high action entropy signals accelerable segments, but entropy is not a reliable indicator of precision: (1) multimodal strategies arising from scenario variability (e.g., random object initialization) can yield high entropy despite strict precision demands, (2) repetitive pathfixed motions may have low entropy without actually requiring precision, causing accelerable segments to be sacrificed.
Fundamentally, both approaches rely on scenariodependent assumptions and attempt to infer precision from motion statistics rather than task semantics, limiting their ability to distinguish accelerable from precision-critical phases and preventing them from scaling robustly in a taskand scenario-agnostic manner.
Accordingly, we introduce ESPADA, a semantic-driven trajectory segmentation framework that selectively accelerates demonstrations without extra hardware, additional data, or additional policy trainings. Prior methods rely on heuristic motion statistics, such as density clusters or action entropy, to implicitly approximate precision. In contrast, ESPADA replaces these assumptions with explicit scene semantics and gripper-object 3D relations. These cues reveal the task intent (e.g., approach, align, adjust) and the actual interaction state between the gripper and the target object, enabling the system to determine exactly where acceleration is safe while preserving genuine precision-critical phases.
Concretely, we extract per-frame 3D coordinates of grippers and key objects using open-vocabulary segmentation [16], [17] and video-based depth estimation [18], [19], which we adopt instead of single-image estimators because depth can be computed offline and video models exploit temporal context across the entire sequence, yielding more stable and semantically coherent geometry. In addition, to remain compatible with the standard visuomotor imitationlearning formulation-where demonstrations rely solely on monocular onboard observations without auxiliary sensing-we derive all 3D cues from monocular video rather than requiring extra depth sensors.
These geometric cues, together with image observations, are summarized by a vision-language model [20] into semantic scene descriptions. We further convert all spatial and semantic observations into a compact language representation so that a large language model-currentl
This content is AI-processed based on open access ArXiv data.