Title: Automating High Energy Physics Data Analysis with LLM-Powered Agents
ArXiv ID: 2512.07785
Date: 2025-12-08
Authors: Eli Gendreau-Distler, Joshua Ho, Dongwon Kim, Luc Tomas Le Pottier, Haichen Wang, Chengxi Yang
📝 Abstract
We present a proof-of-principle study demonstrating the use of large language model (LLM) agents to automate a representative high energy physics (HEP) analysis. Using the Higgs boson diphoton cross-section measurement as a case study with ATLAS Open Data, we design a hybrid system that combines an LLM-based supervisor-coder agent with the Snakemake workflow manager. In this architecture, the workflow manager enforces reproducibility and determinism, while the agent autonomously generates, executes, and iteratively corrects analysis code in response to user instructions. We define quantitative evaluation metrics including success rate, error distribution, costs per specific task, and average number of API calls, to assess agent performance across multi-stage workflows. To characterize variability across architectures, we benchmark a representative selection of state-of-the-art LLMs spanning the Gemini and GPT-5 series, the Claude family, and leading open-weight models. While the workflow manager ensures deterministic execution of all analysis steps, the final outputs still show stochastic variation. Although we set the temperature to zero, other sampling parameters (e.g., top-p, top-k) remained at their defaults, and some reasoning-oriented models internally adjust these settings. Consequently, the models do not produce fully deterministic results. This study establishes the first LLM-agent-driven automated data-analysis framework in HEP, enabling systematic benchmarking of model capabilities, stability, and limitations in real-world scientific computing environments. The baseline code used in this work is available at https://huggingface.co/HWresearch/LLM4HEP. This work was accepted as a poster at the Machine Learning and the Physical Sciences (ML4PS) workshop at NeurIPS 2025. The initial submission was made on August 30, 2025.
💡 Deep Analysis
📄 Full Content
Automating High Energy Physics Data Analysis with LLM-Powered Agents
Eli Gendreau-Distler,1, 2, ∗Joshua Ho,1, 2, † Dongwon Kim,1, 2, ‡ Luc
Tomas Le Pottier,1, 2, § Haichen Wang,1, 2, ¶ and Chengxi Yang1, 2, ∗∗
1Department of Physics, University of California, Berkeley, Berkeley, CA 94720, USA
2Physics Division, Lawrence Berkeley National Laboratory, Berkeley, CA 94720, USA
We present a proof-of-principle study demonstrating the use of large language model (LLM)
agents to automate a representative high energy physics (HEP) analysis. Using the Higgs boson
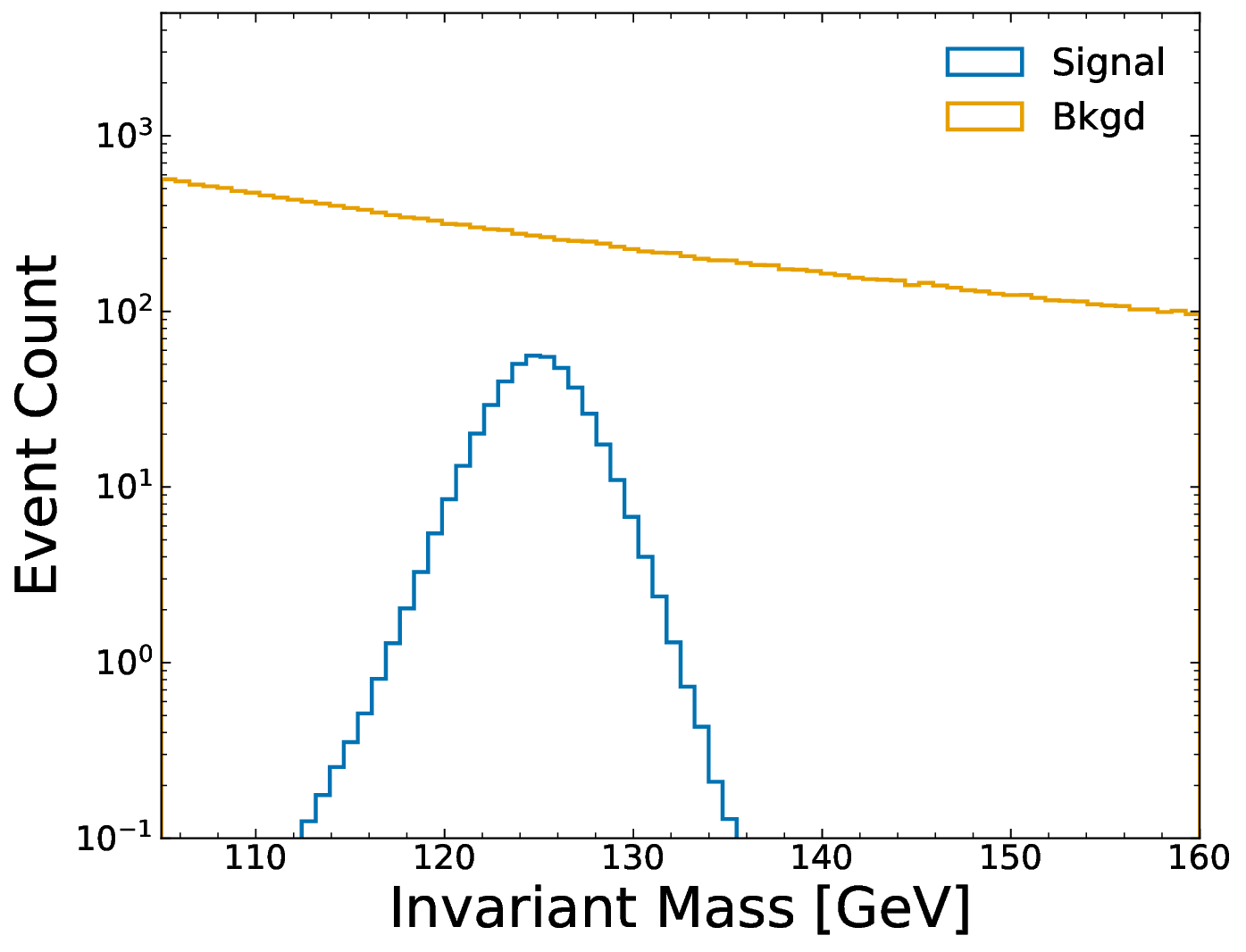
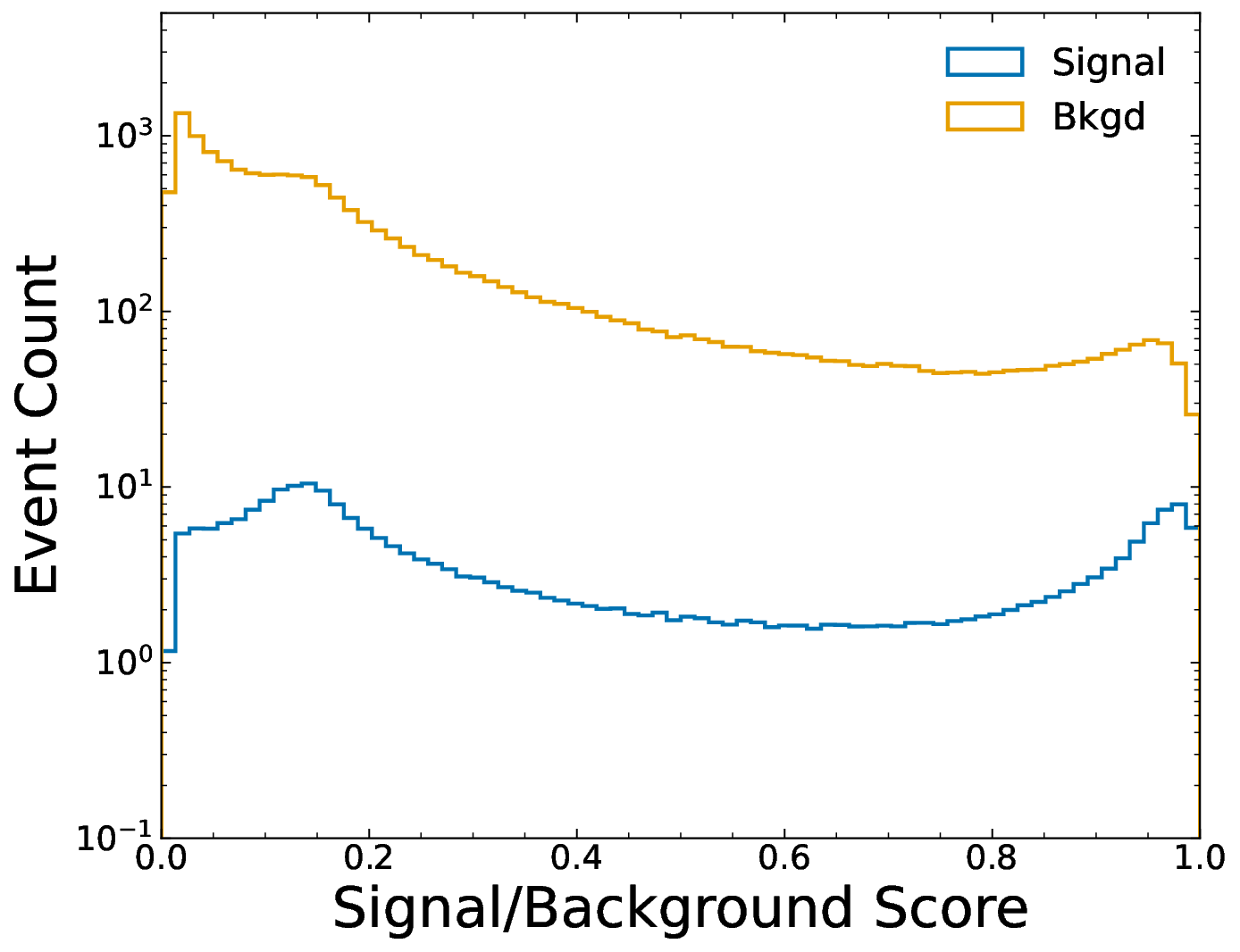
diphoton cross-section measurement as a case study with ATLAS Open Data, we design a hybrid
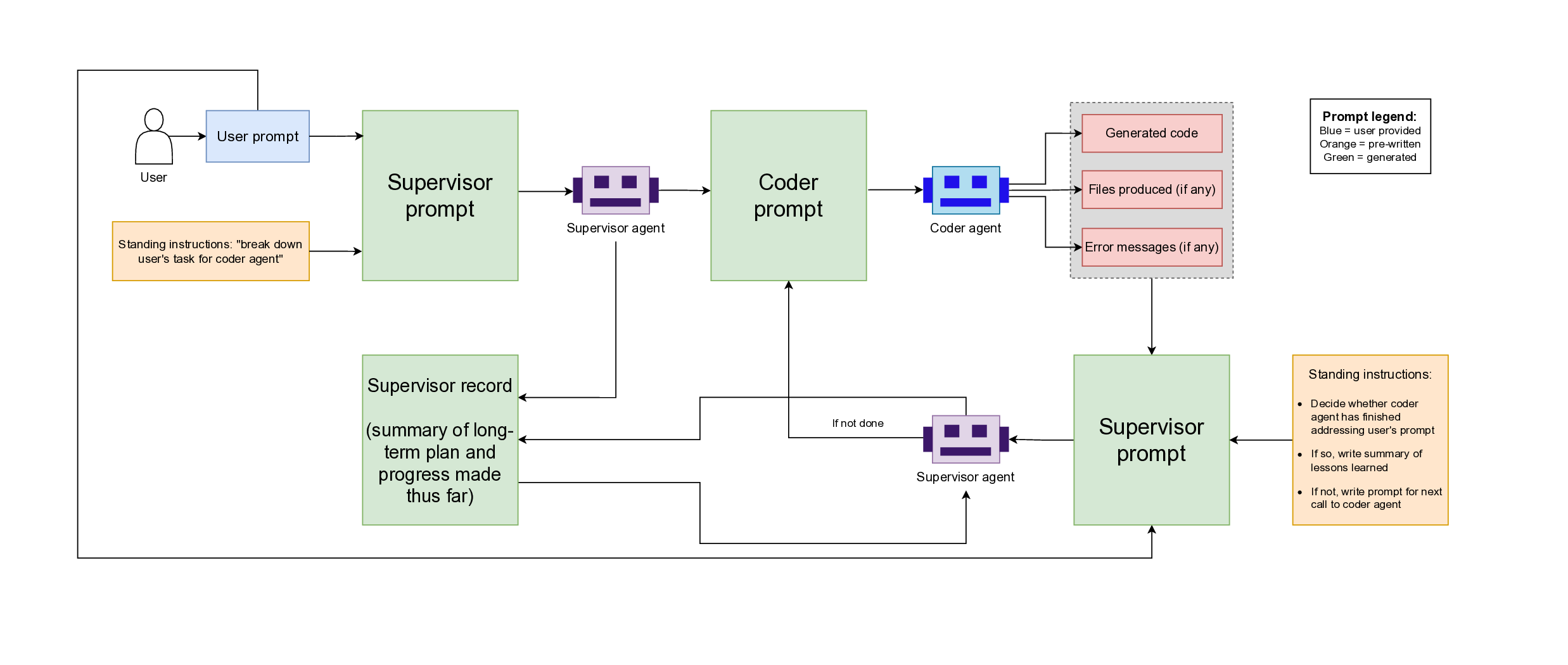
system that combines an LLM-based supervisor–coder agent with the Snakemake workflow manager.
In this architecture, the workflow manager enforces reproducibility and determinism, while the
agent autonomously generates, executes, and iteratively corrects analysis code in response to user
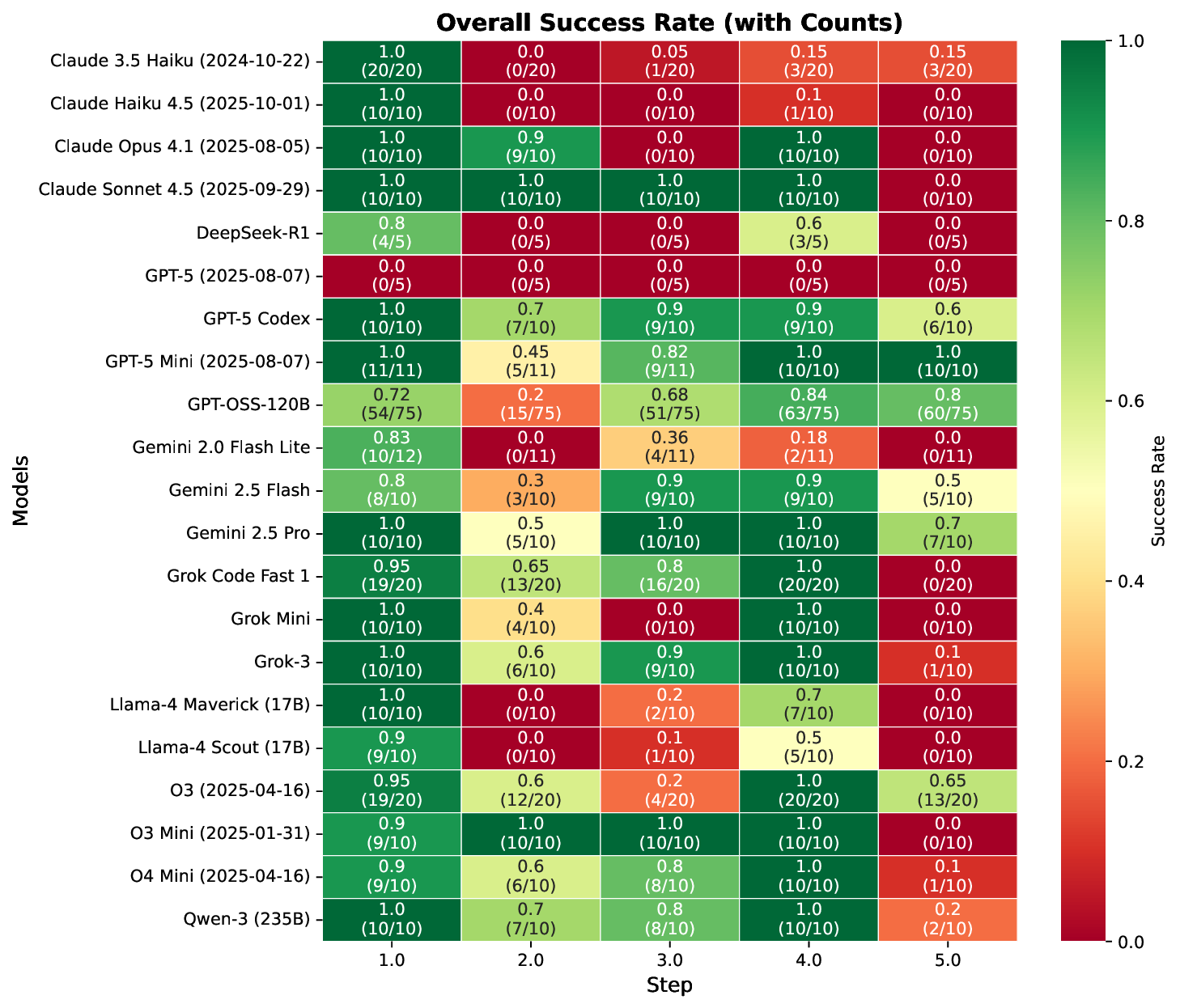
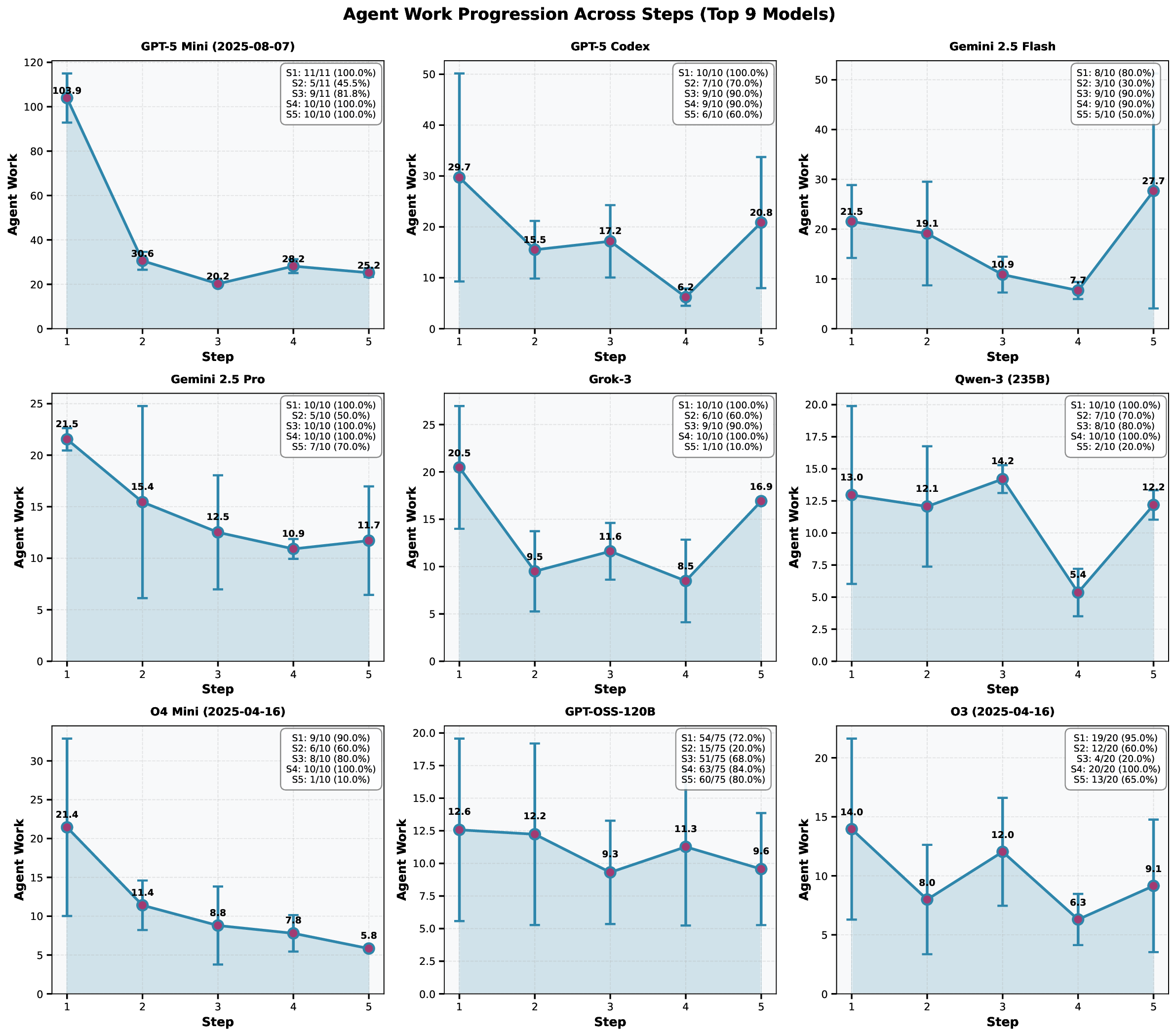
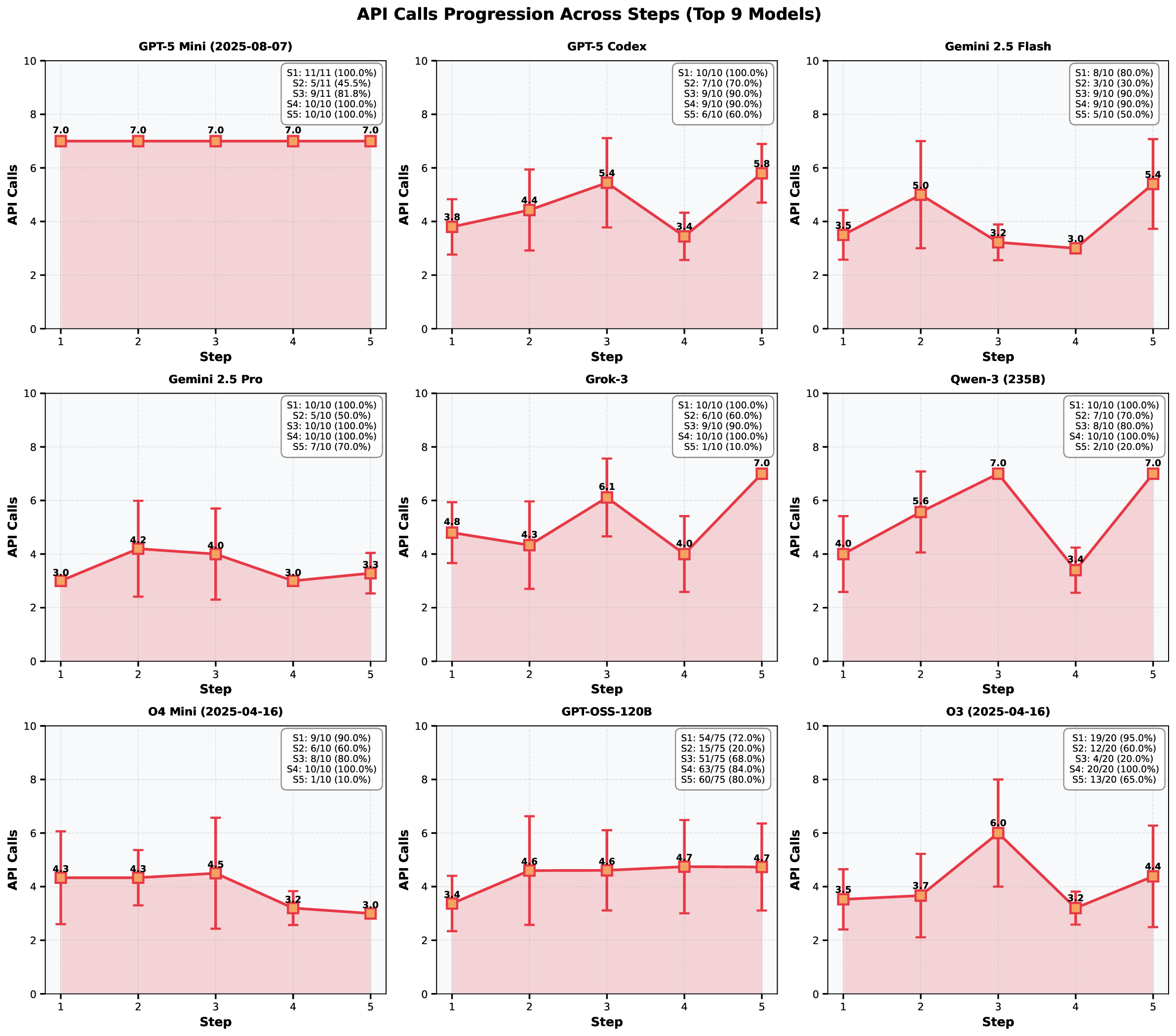
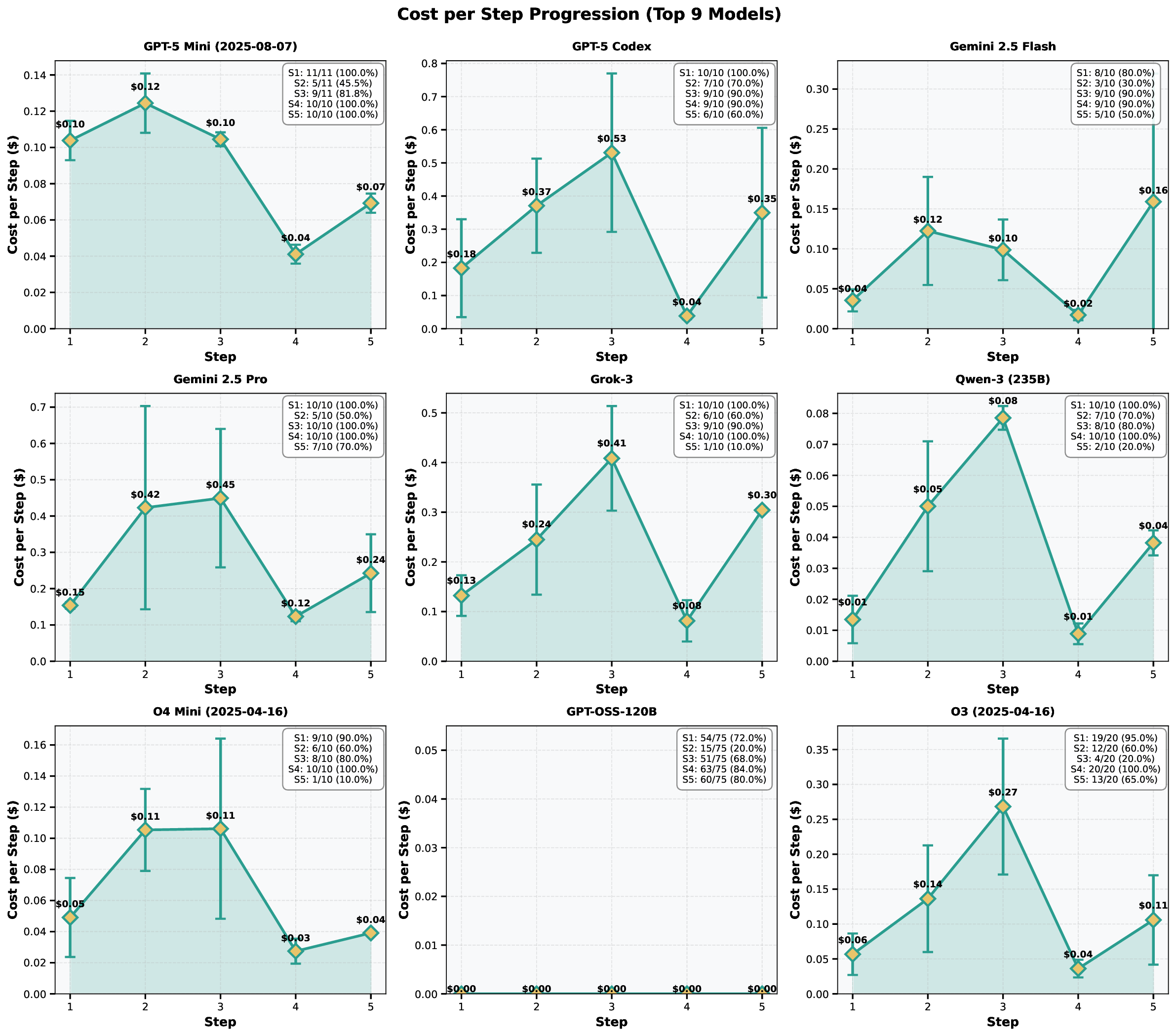
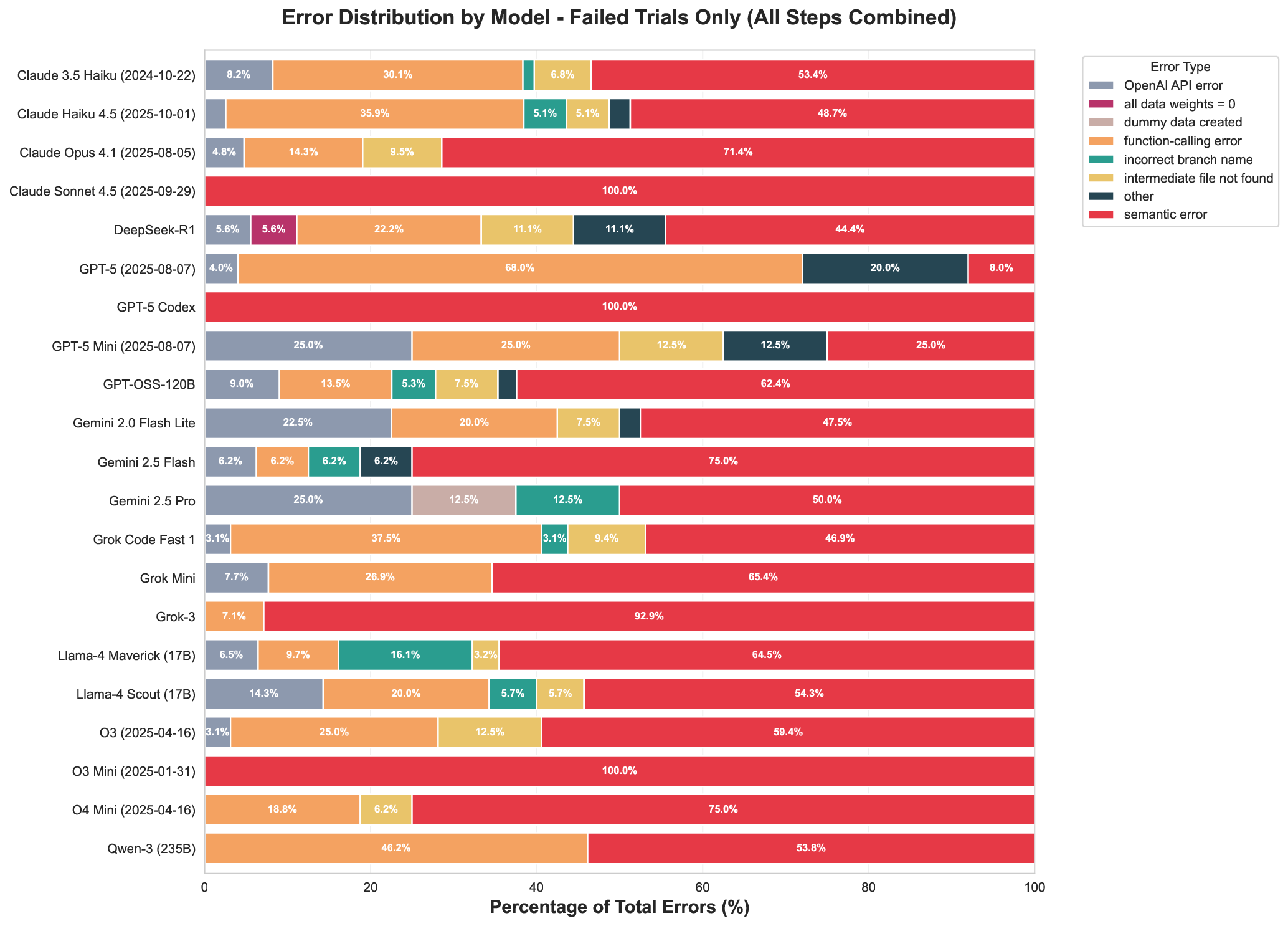
instructions. We define quantitative evaluation metrics – success rate, error distribution, costs per
specific task, and average number of API call for the task – to assess agent performance across
multi-stage workflows. To characterize variability across architectures, we benchmark a representative
selection of state-of-the-art LLMs, spanning the Gemini and GPT-5 series, the Claude family, and
leading open-weight models. While the workflow manager ensures deterministic execution of all
analysis steps, the final outputs still show stochastic variation. Although we set the temperature to
zero, other sampling parameters (e.g., top-p, top-k) remained at their defaults, and some reasoning-
oriented models internally adjust these settings. Consequently, the models do not produce fully
deterministic results. This study establishes the first LLM-agent-driven automated data-analysis
framework in HEP, enabling systematic benchmarking of model capabilities, stability, and limitations
in real-world scientific computing environments. The baseline code used in this work is available at
https://huggingface.co/HWresearch/LLM4HEP. This work was accepted as a poster at the Machine
Learning and the Physical Sciences (ML4PS) workshop of the 39th Conference on Neural Information
Processing Systems (NeurIPS 2025). The initial submission was made on August 30, 2025.
I.
INTRODUCTION
Large language models (LLMs) and agent-based sys-
tems are increasingly being explored in scientific comput-
ing, with applications appearing in areas such as genomics
and software engineering [1, 2]. Despite the inherently
structured nature of collider-related data analyses and the
potential advantages of automated, reproducible work-
flows, the usage of LLMs in high energy physics (HEP)
is still at an early stage. Existing efforts in HEP have
focused mainly on event-level inference or on domain-
adapted language models [3–5], leaving open questions
about how LLMs might participate directly in end-to-end
analysis procedures.
Related work in agentic methodologies, including the
Agents of Discovery study [6], demonstrates growing inter-
est in structuring collider physics tasks through modular
agent behavior. While such efforts examine agent-based
reasoning in HEP contexts, they address different ob-
jectives and operational settings. Our study is situated
within a workflow-management environment and consid-
ers how agentic components may be incorporated into a
directed, reproducible analysis pipeline.
∗egendreaudistler@berkeley.edu
† ho22joshua@berkeley.edu
‡ dwkim@berkeley.edu
§ luclepot@berkeley.edu
¶ haichenwang@berkeley.edu
∗∗cxyang@berkeley.edu
We introduce a framework in which LLM-based agents
are integrated into a Snakemake-managed workflow [7].
Agent interventions are bounded to well-defined tasks
such as code generation, event selection, and validation
while the underlying directed acyclic graph (DAG) main-
tains determinism and provenance. This design enables a
controlled evaluation of the practicality and reliability of
agent-driven steps within a full collider-analysis setting.
II.
BACKGROUND AND MOTIVATION
Research connecting LLMs with HEP is rapidly devel-
oping, though the existing literature remains concentrated
on a small number of application areas – for instance, en-
hancements to event-level prediction tasks, improvements
to simulation, or tools for navigating domain knowledge.
A substantial body of work applies transformer-based
architectures to established HEP tasks such as classifica-
tion, regression, and generative modeling [8–11]. These
studies demonstrate the effectiveness of modern model
architectures within conventional workflows but are not
designed to automate or restructure the broader analysis
process.
LLMs have also been used to improve access to
experiment-specific documentation and technical re-
sources. Systems such as Chatlas [12], LLMTuner [13],
and Xiwu [14] demonstrate the usefulness of natural-
language interfaces for accessing experiment-specific doc-
umentation and technical information