Current autonomous driving systems often favor end-to-end frameworks, which take sensor inputs like images and learn to map them into trajectory space via neural networks. Previous work has demonstrated that models can achieve better planning performance when provided with a prior distribution of possible trajectories. However, these approaches often overlook two critical aspects: 1) The appropriate trajectory prior can vary significantly across different driving scenarios. 2) Their trajectory evaluation mechanism lacks policy-driven refinement, remaining constrained by the limitations of one-stage supervised training. To address these issues, we explore improvements in two key areas. For problem 1, we employ MoE to apply different trajectory priors tailored to different scenarios. For problem 2, we utilize Reinforcement Learning to fine-tune the trajectory scoring mechanism. Additionally, we integrate models with different perception backbones to enhance perceptual features. Our integrated model achieved a score of 51.08 on the navsim ICCV benchmark, securing third place.
💡 Deep Analysis
📄 Full Content
TrajMoE: Scene-Adaptive Trajectory Planning with Mixture of Experts
and Reinforcement Learning
Zebin Xing1
Pengxuan Yang1
Linbo Wang1
Yichen Zhang1
Yiming Hu1
Yupeng Zheng†1
Junli Wang1,2
Yinfeng Gao1,2
Guang Li2
Kun Ma2
Long Chen2
Zhongpu Xia1
Qichao Zhang1
Hangjun Ye2
Dongbin Zhao1
1Institute of Automation, Chinese Academy of Sciences 2Xiaomi
†Project Leader
Abstract— Current autonomous driving systems often favor
end-to-end frameworks, which take sensor inputs like images
and learn to map them into trajectory space via neural net-
works. Previous work has demonstrated that models can achieve
better planning performance when provided with a prior distri-
bution of possible trajectories. However, these approaches often
overlook two critical aspects: 1) The appropriate trajectory
prior can vary significantly across different driving scenarios.
2) Their trajectory evaluation mechanism lacks policy-driven
refinement, remaining constrained by the limitations of one-
stage supervised training. To address these issues, we explore
improvements in two key areas. For problem 1, we employ
MoE to apply different trajectory priors tailored to different
scenarios. For problem 2, we utilize Reinforcement Learning
to fine-tune the trajectory scoring mechanism. Additionally,
we integrate models with different perception backbones to
enhance perceptual features. Our integrated model achieved a
score of 51.08 on the navsim ICCV benchmark, securing third
place.
Index Terms— End-to-end Autonomous driving, Trajectory
Planning, Model Ensembling.
I. INTRODUCTION
Frameworks like UniAD [2] utilize transformers with
distinct functional modules to process and pass information,
enabling mapping from sensor data to trajectory action space.
Others, such as VAD [3], adopt sparser perceptual representa-
tions to reduce computational demands. In recent end-to-end
research, several works incorporate action anchors or priors.
For instance, VADv2 [4], and GTRS [9] first cluster a large
set of trajectories from the training dataset and then learn to
select the optimal trajectory for the current scene from this
cluster. DiffusionDrive [5] adds and removes noise based on
a trajectory cluster, while GoalFlow [6] clusters trajectory
endpoints to serve as prior information for goal points. A
key finding from recent methods is that incorporating a prior
distribution over trajectories in some form helps the model
generate safer and more reliable planned trajectories.
However, these methods typically rely on a fixed trajectory
vocabulary or prior, despite the fact that action distributions
can differ greatly across scenarios (e.g., going straight vs.
turning). To address this limitation, we introduce Sparse
MoE [10] to differentiate between trajectory distributions.
Specifically, trajectories from the vocabulary are routed to
different experts based on the router’s decision. Furthermore,
we extend the standard supervised learning framework by
performing additional fine-tuning using GRPO [8], following
initial supervised learning on various driving score metrics.
This aims to enhance the model’s accuracy in predicting
driving scores. Finally, building upon the GTRS baseline,
we experiment with replacing different perception backbones
and ensemble the outputs of our models. This approach led
to a score of 51.08 on the navsimv2 [1] ICCV competition,
earning a third-place ranking.
In summary, our main contributions are as follows:
• We explore integrating Sparse MoE with a standard tra-
jectory vocabulary, allowing trajectories to be processed
by different experts to account for varying scenario-
specific distributions.
• We investigate augmenting supervised learning on driv-
ing scores with subsequent GRPO fine-tuning to im-
prove the model’s understanding and prediction of these
scores.
• We ensemble models with different perception back-
bones, achieving strong performance on the navsim
ICCV benchmark.
II. METHODOLOGY
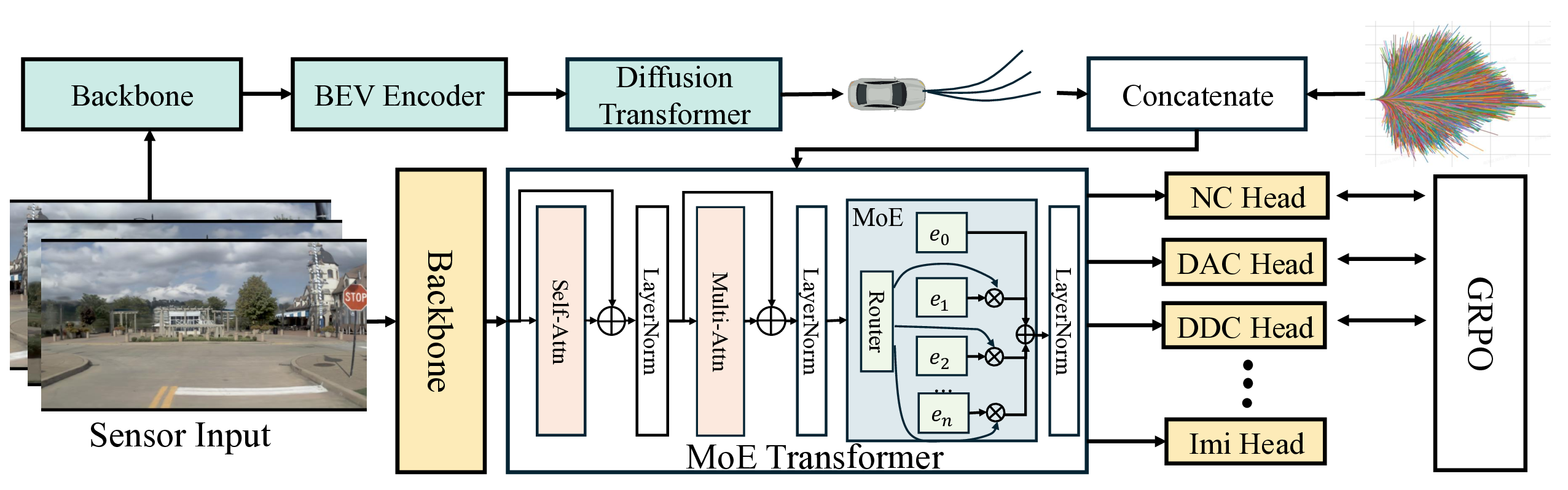
A. Base Model
Based on the established anchor trajectory paradigm, our
architectural foundation is built upon the state-of-the-art
GTRS framework [9]. The input to GTRS comprises a con-
catenated tensor C ∈RH×W ×3, formed by spatially stitching
image data from the front, front-left, and front-right cameras.
A powerful perception backbone, specifically V299 [7], is
employed to extract a dense and informative scene feature
representation, denoted as Fcam ∈RTcam×Dcam, from this
composite input.
Subsequently, a predefined set of trajectory anchors,
termed the trajectory vocabulary V, is embedded into a latent
space Ftraj. The camera feature Fcam and the trajectory
vocabulary feature Ftraj interact through a transformer ar-
chitecture to produce an enhanced representation Ffusion.
To facilitate discriminative scoring within the vocabulary,
the GTRS model is optimized under a multi-task learning
objective, supervising the predicted trajectory scores from
several critical aspects.
arXiv:2512.07135v2 [cs.CV] 9 Dec 2025
Sensor Input
Backbone
Mo