Title: MIDG: Mixture of Invariant Experts with knowledge injection for Domain Generalization in Multimodal Sentiment Analysis
ArXiv ID: 2512.07430
Date: 2025-12-08
Authors: - Yangle Li¹ - Danli Luo¹ - Haifeng Hu¹*
📝 Abstract
Existing methods in domain generalization for Multimodal Sentiment Analysis (MSA) often overlook inter-modal synergies during invariant features extraction, which prevents the accurate capture of the rich semantic information within multimodal data. Additionally, while knowledge injection techniques have been explored in MSA, they often suffer from fragmented cross-modal knowledge, overlooking specific representations that exist beyond the confines of unimodal. To address these limitations, we propose a novel MSA framework designed for domain generalization. Firstly, the framework incorporates a Mixture of Invariant Experts model to extract domain-invariant features, thereby enhancing the model's capacity to learn synergistic relationships between modalities. Secondly, we design a Cross-Modal Adapter to augment the semantic richness of multimodal representations through cross-modal knowledge injection. Extensive domain experiments conducted on three datasets demonstrate that the proposed MIDG achieves superior performance.
💡 Deep Analysis
📄 Full Content
MIDG: MIXTURE OF INVARIANT EXPERTS WITH KNOWLEDGE INJECTION FOR
DOMAIN GENERALIZATION IN MULTIMODAL SENTIMENT ANALYSIS
Yangle Li1
Danli Luo1
Haifeng Hu1∗
1 School of Electronics and Information Technology, Sun Yat-Sen University
ABSTRACT
Existing methods in domain generalization for Multimodal Sen-
timent Analysis (MSA) often overlook inter-modal synergies during
invariant features extraction, which prevents the accurate capture of
the rich semantic information within multimodal data. Additionally,
while knowledge injection techniques have been explored in MSA,
they often suffer from fragmented cross-modal knowledge, over-
looking specific representations that exist beyond the confines of uni-
modal. To address these limitations, we propose a novel MSA frame-
work designed for domain generalization. Firstly, the framework in-
corporates a Mixture of Invariant Experts model to extract domain-
invariant features, thereby enhancing the model’s capacity to learn
synergistic relationships between modalities. Secondly, we design
a Cross-Modal Adapter to augment the semantic richness of mul-
timodal representations through cross-modal knowledge injection.
Extensive domain experiments conducted on three datasets demon-
strate that the proposed MIDG achieves superior performance.
Index Terms— Multimodal Sentiment Analysis, Domain Gen-
eralization , Knowledge Injection
1. INTRODUCTION
Sentiment analysis is a fundamental task in the field of Natural Lan-
guage Processing (NLP). With the rapid development of multime-
dia technology, artificial intelligence is gradually entering the mul-
timodal era.
As a result, researchers in sentiment analysis have
shifted their focus from text-based approaches to Multimodal Sen-
timent Analysis (MSA), which integrates information from multiple
dimensions such as text, audio, and visual signals to analyze human
sentiment expressions.
Most existing MSA methods rely on an unrealistic assumption
that training and testing data are drawn from an independent iden-
tical distribution. However, this assumption rarely holds in real-
world scenarios. To mitigate this limitation, previous studies em-
ployed sparse masking techniques and extracted invariant features
using a text-first-then-video strategy [1], achieving improved gener-
alization performance. Nevertheless, such methods suffer from issue
(i): the sequential processing of modalities fails to adequately model
and leverage the dynamic synergy and complementary relationships
among textual, acoustic, and visual signals, thus limiting accurate
sentimental analysis.
Furthermore, many existing MSA approaches predominantly
rely on general knowledge from pre-trained models such as BERT
[2] to encode each modality, which is insufficient to capture cross-
modal sentiment specific cues. A potential solution is knowledge
injection [3]. Prior work [4] introduced a multimodal Adapter that
leverages pan-knowledge within a modality to generate knowledge-
specific representations and inject them into pan-knowledge to
* Corresponding Author
facilitate prediction.
However, this approach suffers from issue
(ii): current Adapters focus on intra-modal learning and injection,
leading to fragmented cross-modal knowledge. They often over-
look extra-modal knowledge representations, making it difficult to
capture comprehensive semantic information.
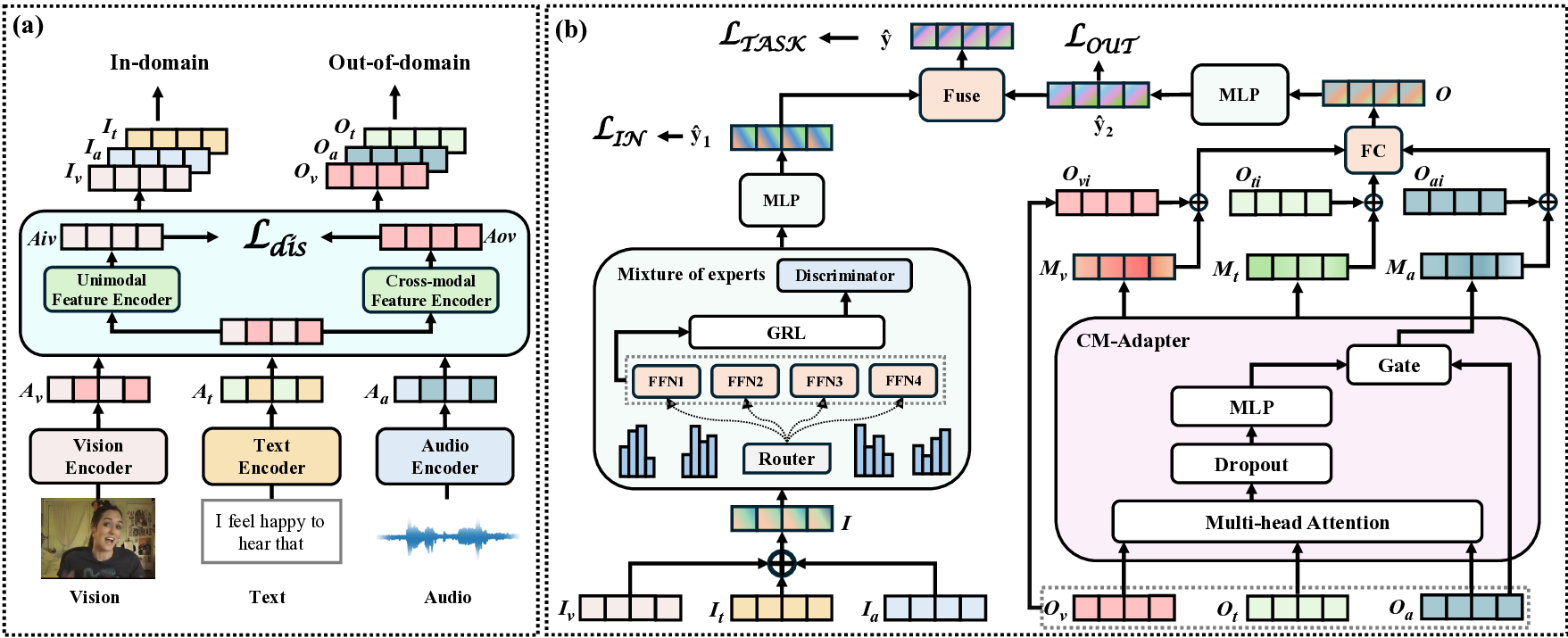
To address these two issues, we propose a MoIE with Knowl-
edge Injection for Domain Generalization Framework in MSA
(MIDG), which leverages a Mixture of Invariant Experts (MoIE) to
learn in-domain invariant features, effectively capturing multimodal
collaborative information.
Additionally, we introduce a Cross-
Modal Adapter to efficiently learn cross-modal specific knowledge
representations, thereby enhancing out-of-domain generalization
and improving the predictive accuracy of the MSA model. Specifi-
cally, to tackle issue (i), we propose a Mixture of Invariant Experts
(MoIE) module to extract invariant features.
A router network
dynamically assigns tasks to experts based on input features. To
address issue (ii), we simulate out-of-domain information using a
subset of raw data to train the model’s generalization capability.
For this purpose, we design a Cross-Modal Adapter for knowledge
injection to produce knowledge-specific representations. We further
employ an attention mechanism to dynamically integrate specific
knowledge from other modalities.The main contributions of our
work are summarized as follows:
·We propose a novel MoIE based knowledge injection domain
generalization framework for MSA, which specifically addresses the
challenge of extracting invariant features under out-of-distribution
scenarios.
·The Mixture of Invariant Experts module is employed to learn
multimodal domain-invariant features. Taking the multimodal fused
features as input, a routing network dynamically assigns learning
tasks to experts, thereby enhancing the learning of cross-modal in-
teractive knowledge.
·To fully leverage inter-