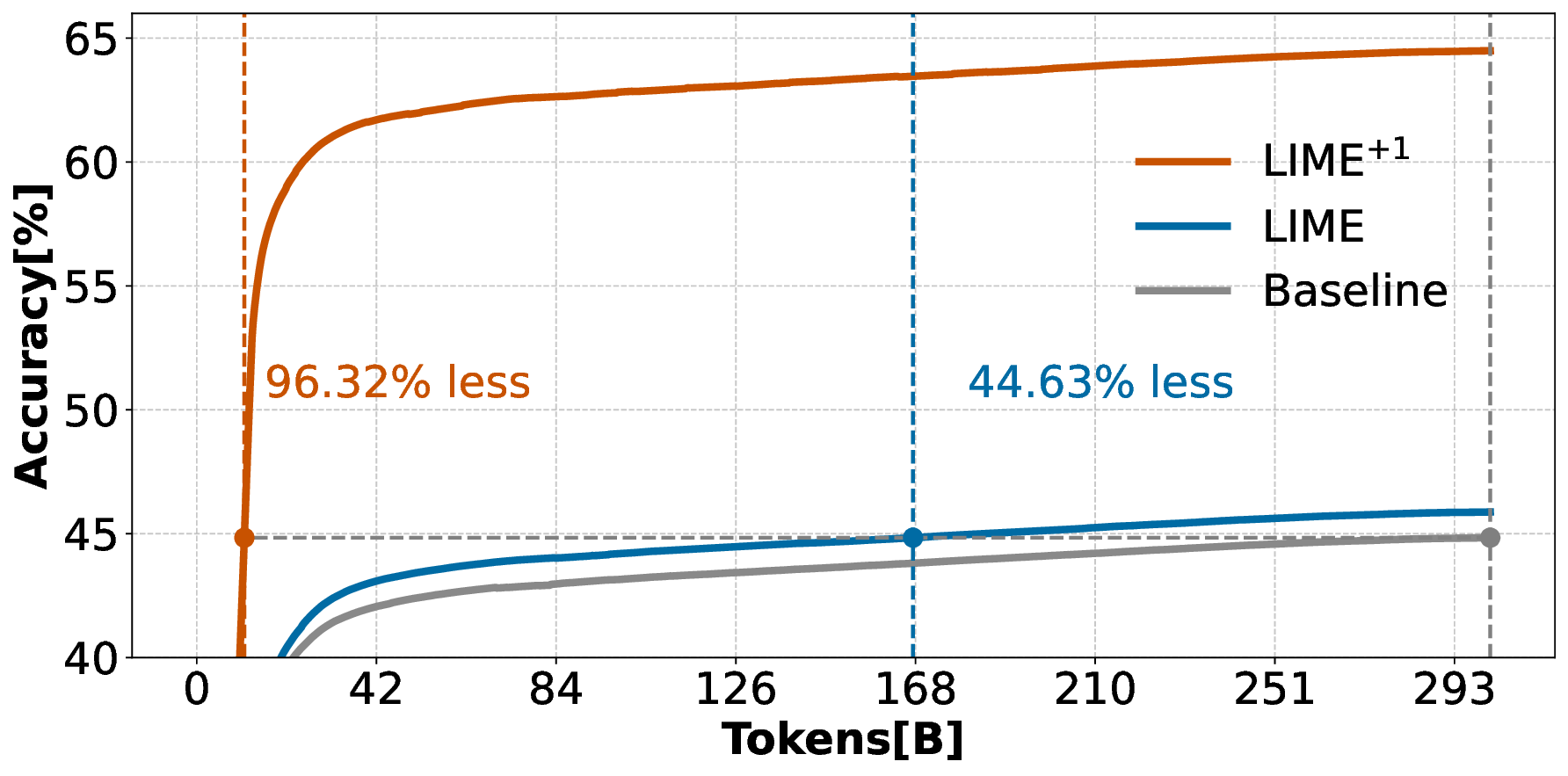
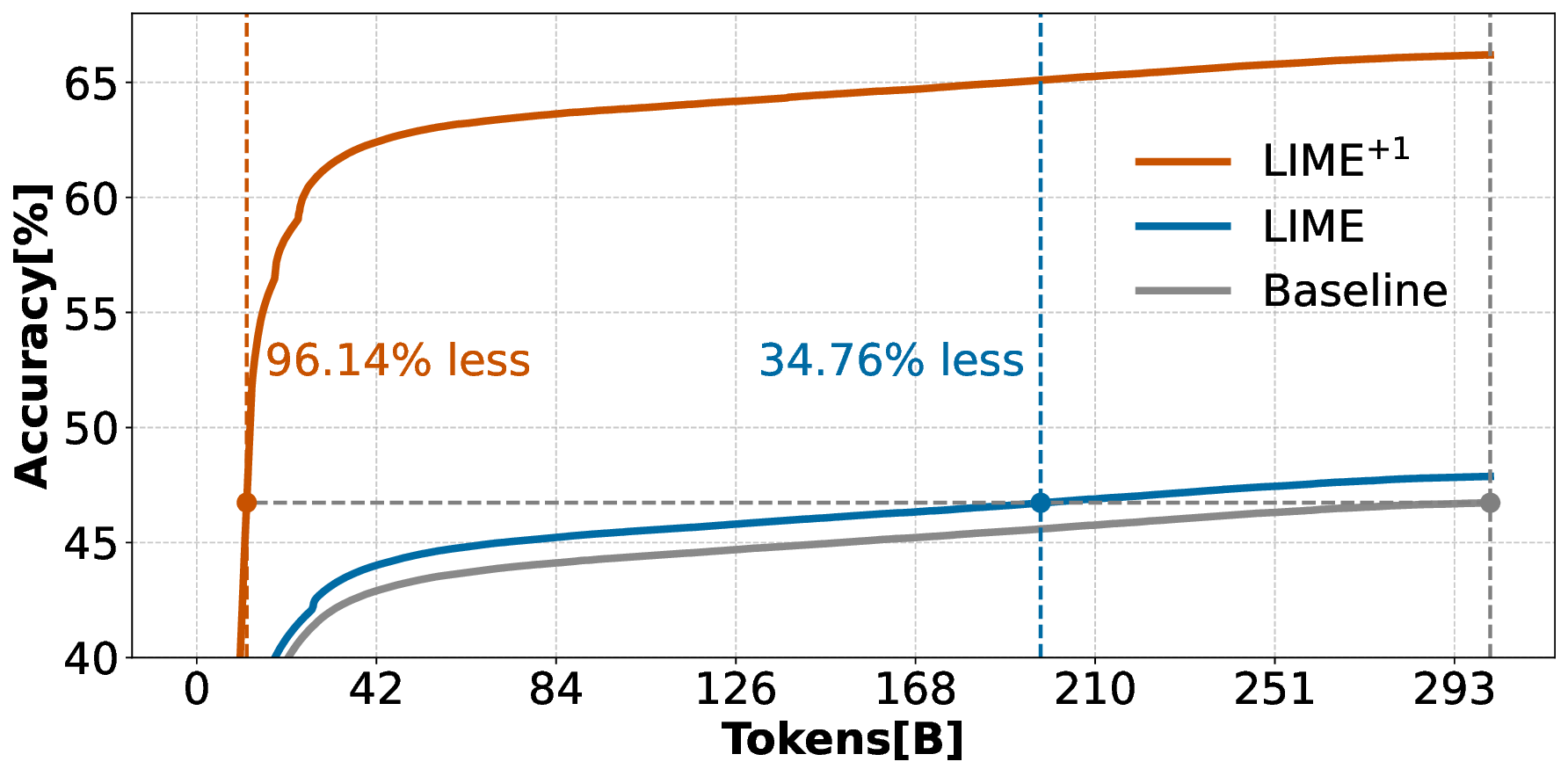
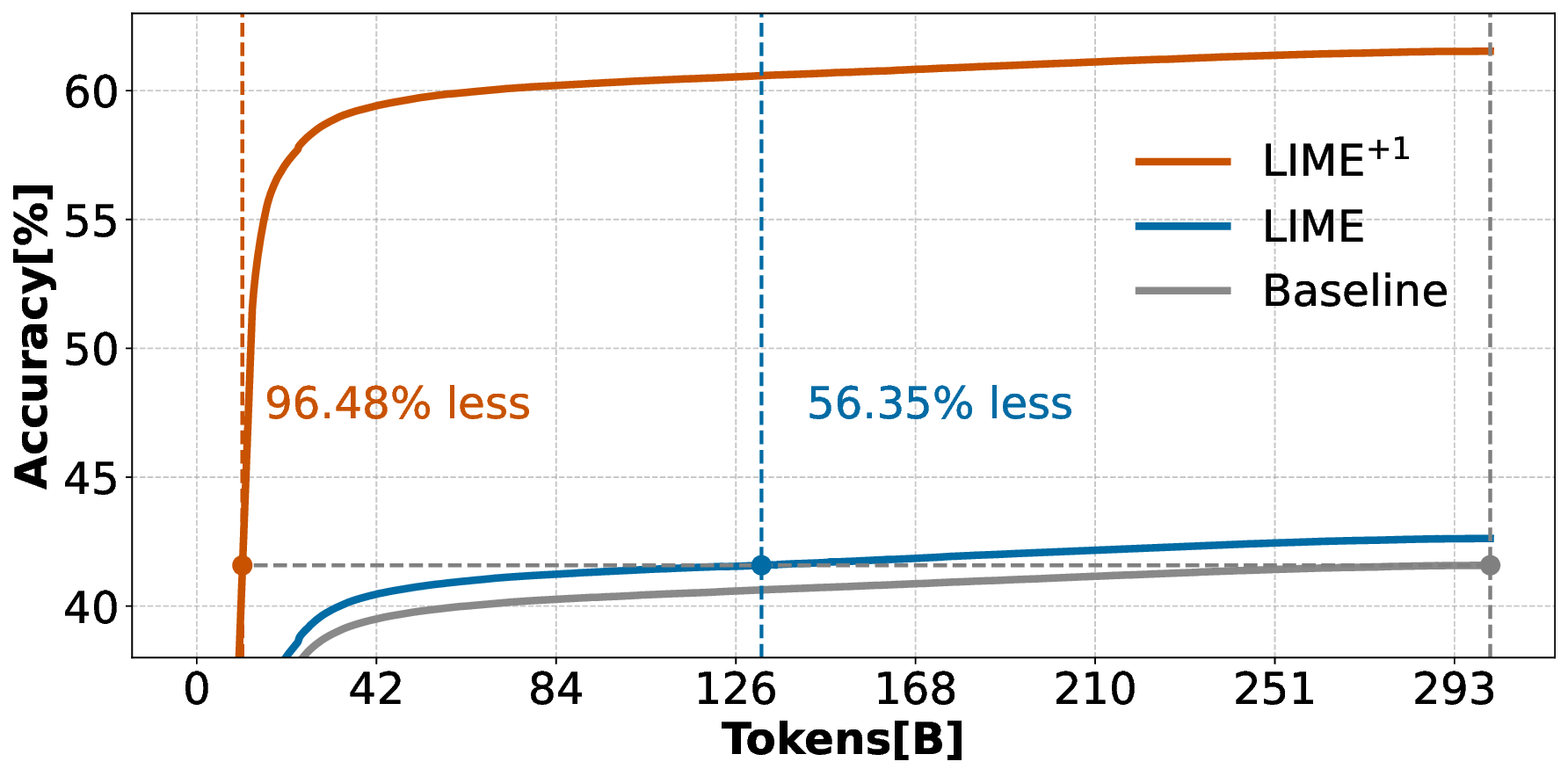
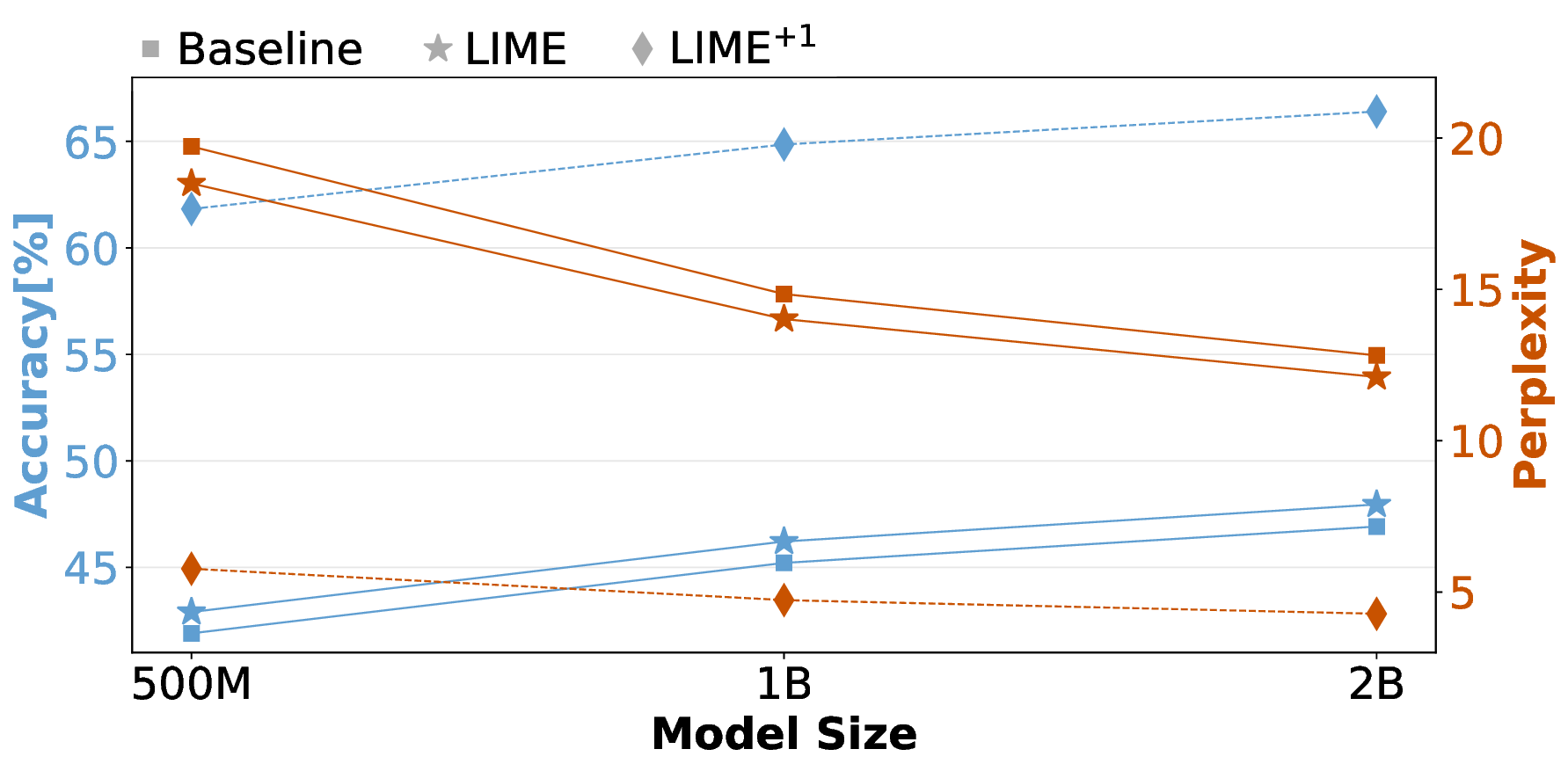
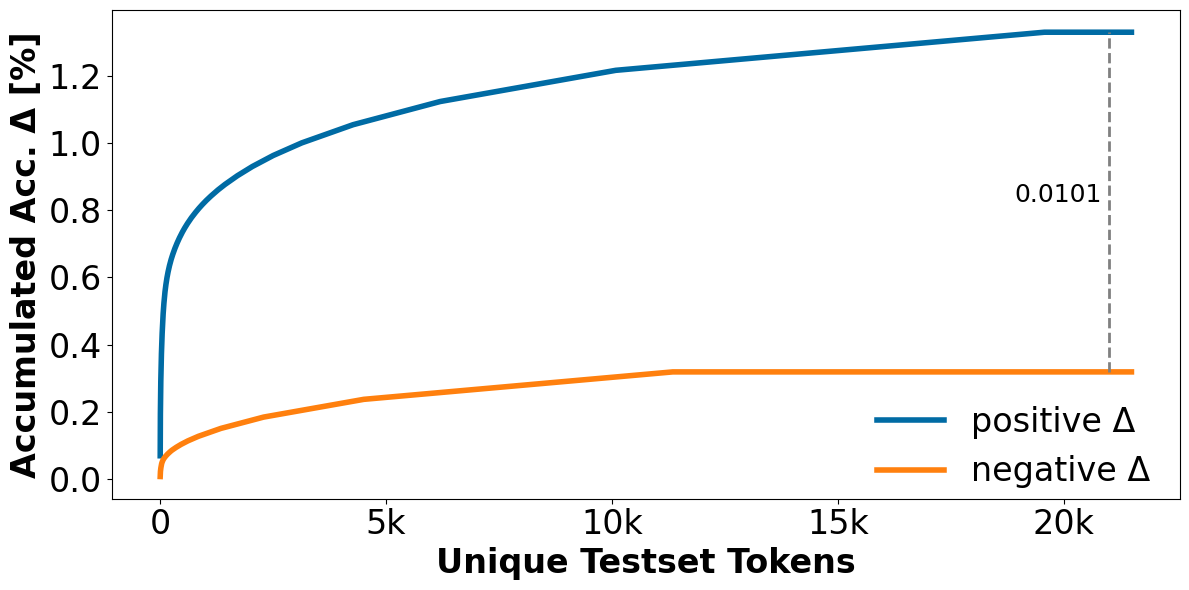
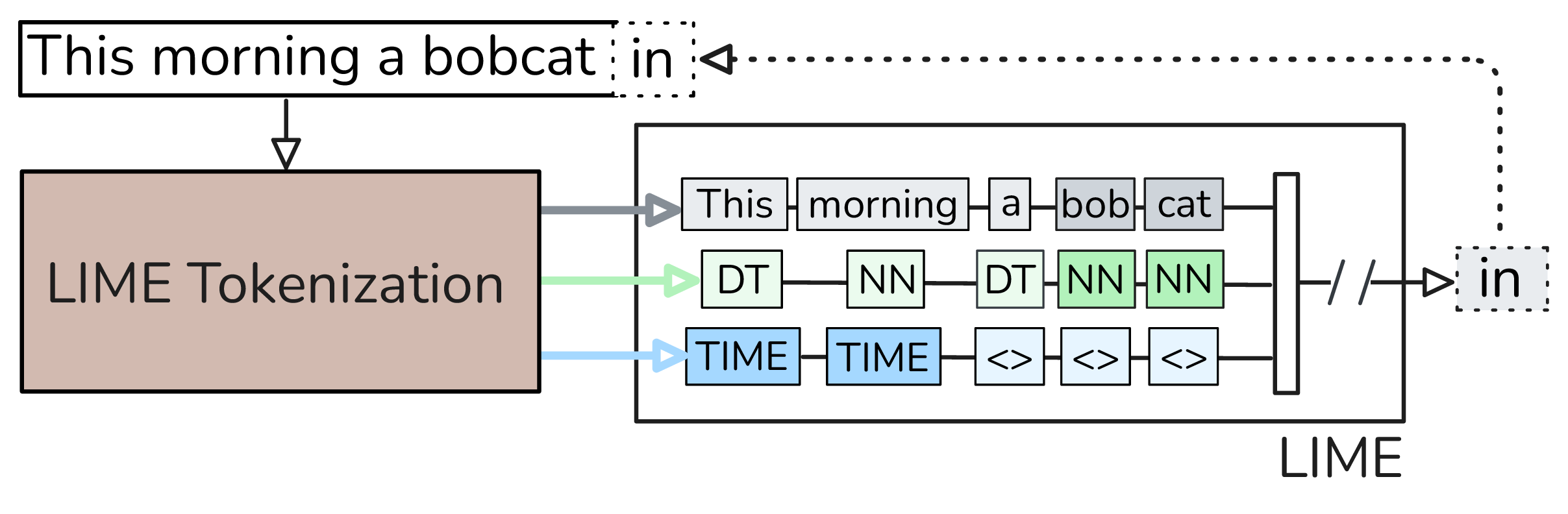
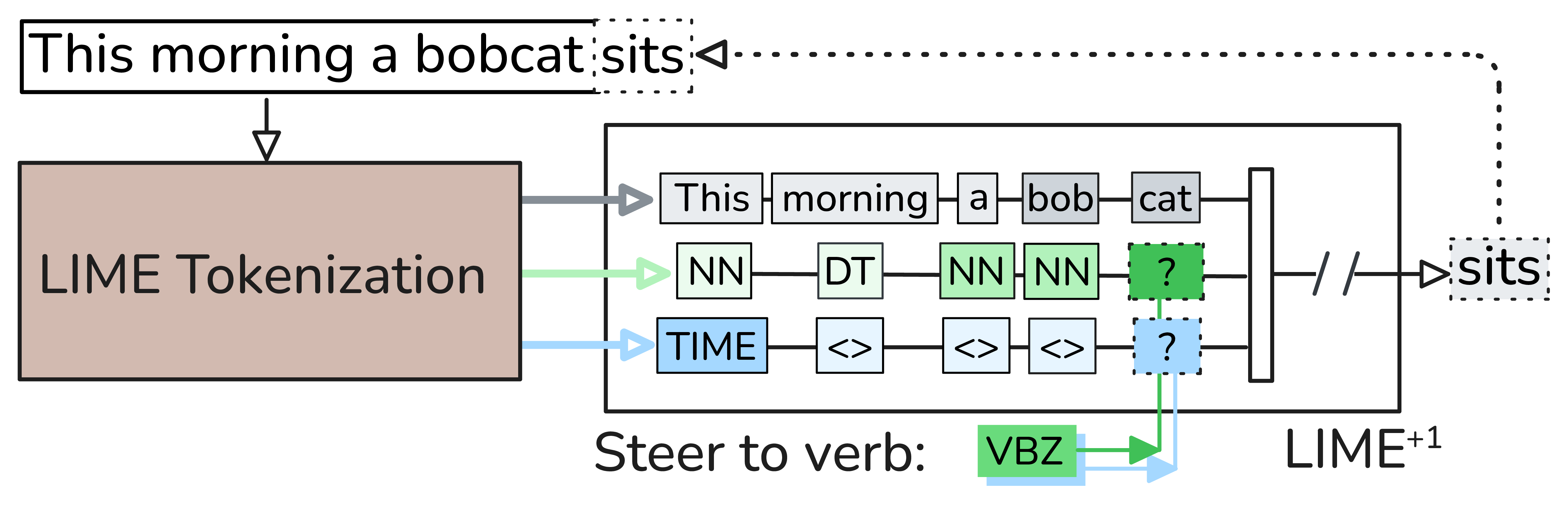
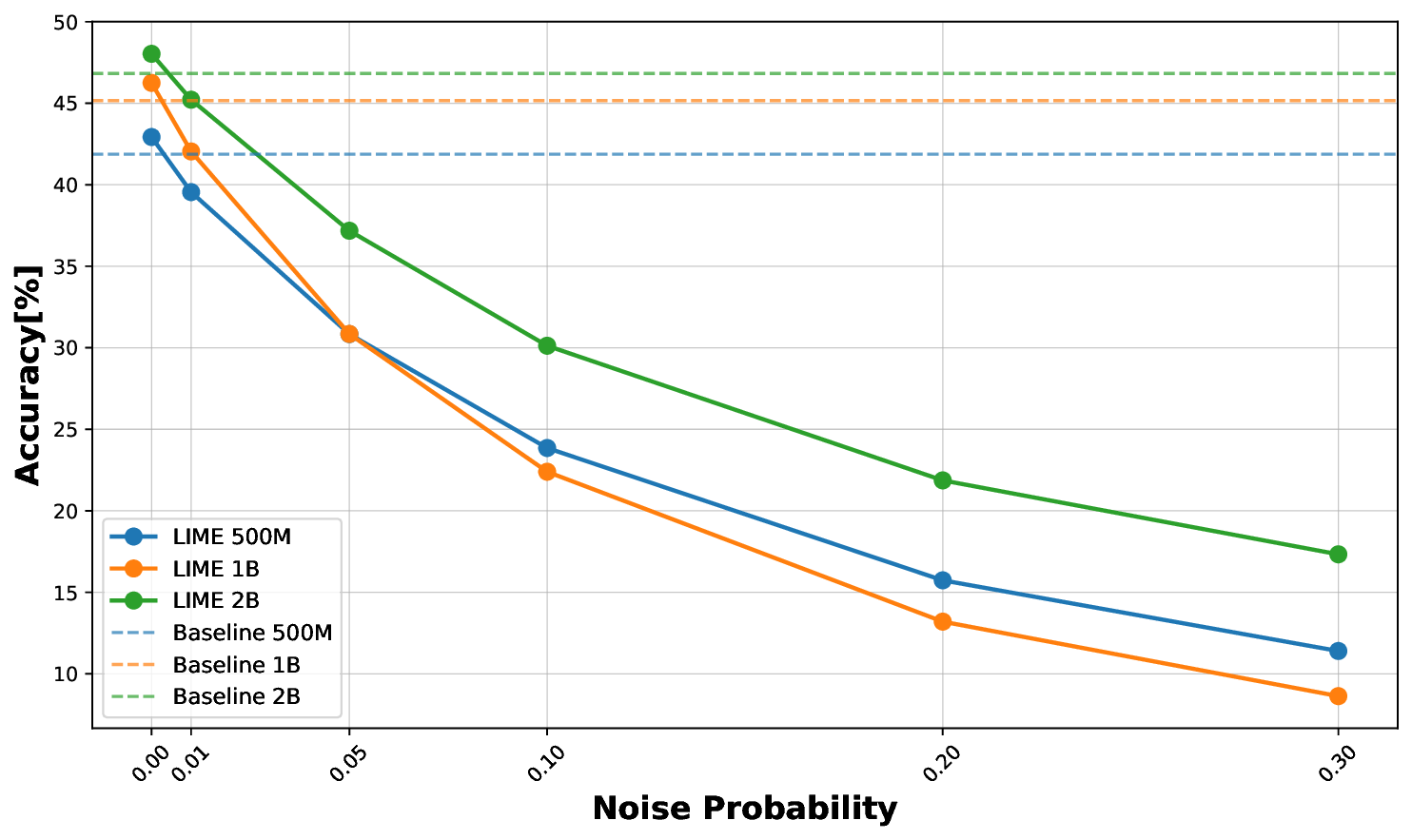
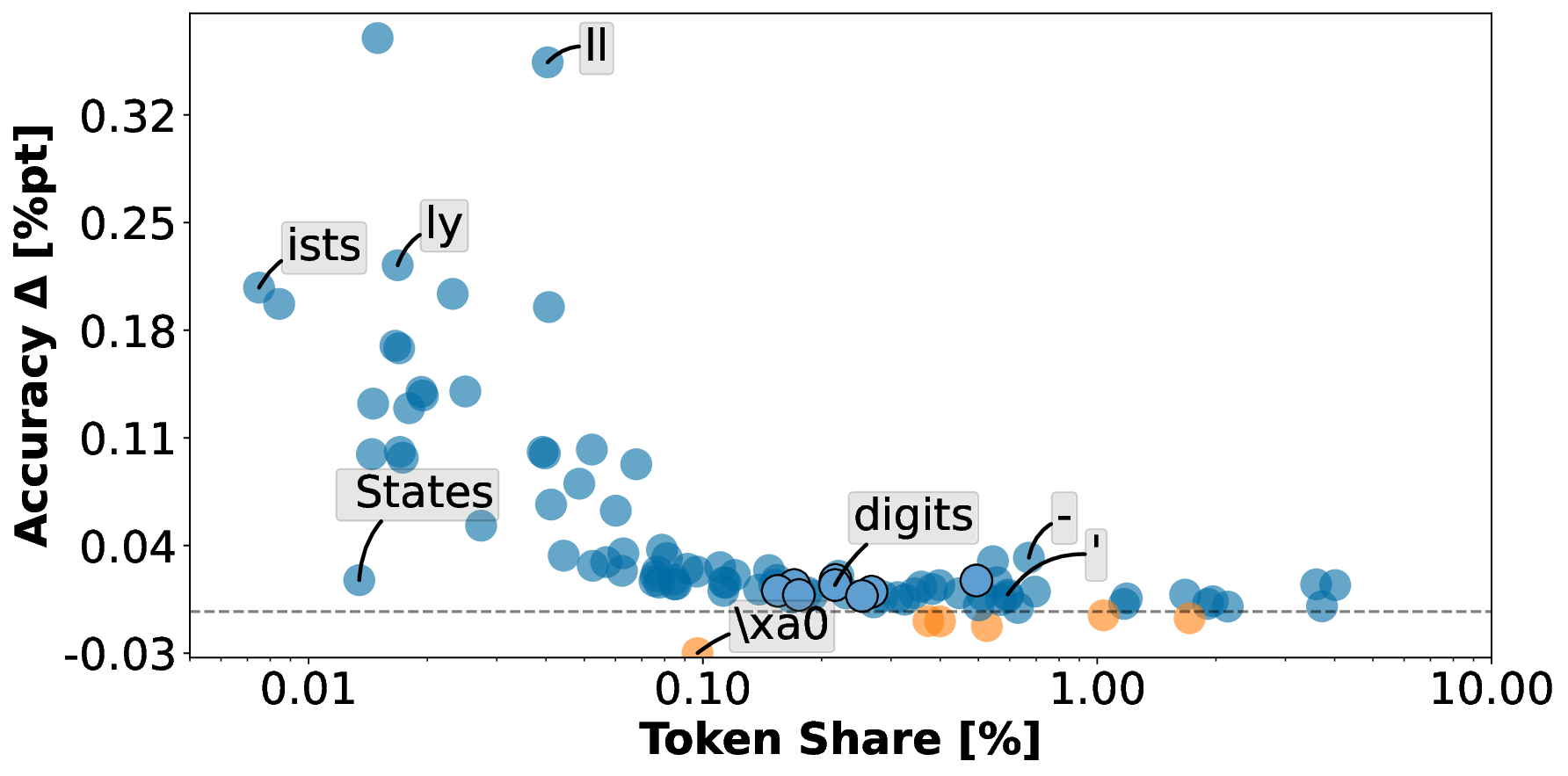
Pre-training decoder-only language models relies on vast amounts of high-quality data, yet the availability of such data is increasingly reaching its limits. While metadata is commonly used to create and curate these datasets, its potential as a direct training signal remains under-explored. We challenge this status quo and propose LIME (Linguistic Metadata Embeddings), a method that enriches token embeddings with metadata capturing syntax, semantics, and contextual properties. LIME substantially improves pre-training efficiency. Specifically, it adapts up to 56% faster to the training data distribution, while introducing only 0.01% additional parameters at negligible compute overhead. Beyond efficiency, LIME improves tokenization, leading to remarkably stronger language modeling capabilities and generative task performance. These benefits persist across model scales (500M to 2B). In addition, we develop a variant with shifted metadata, LIME+1, that can guide token generation. Given prior metadata for the next token, LIME+1 improves reasoning performance by up to 38% and arithmetic accuracy by up to 35%.
Autoregressive language models have emerged as a prominent area of research due to their impressive capabilities. However, training these large language models (LLMs) is computationally expensive and highly data-intensive. Smaller LLMs are particularly attractive because of their reduced resource requirements and accessibility. Nonetheless, models up to 2B parameters require the same-or even increased-amount of training data, as their language modeling performance tends to regress (Hoffmann et al., 2022).
At the same time, the availability of novel human-generated high-quality training data is decreasing (Xue et al., 2023;Villalobos et al., 2024), emphasizing the need of improving the utility of existing datasets. To compensate this shortcoming, methods of accumulating LLM pre-training datasets shift from mere quality filtering to synthetization through earlier model generations and staging of increasing data quality buckets (Su et al., 2025). In order to determine the stage and quality bucket, existing document-level metadata is used, along with more complex-and even model-based-scores that reflect attributes such as educational value, or factual reliability (Schuhmann et al., 2022;Li et al., 2024;Penedo et al., 2024;Wettig et al., 2025).
However, neither pre-existing nor created metadata are typically propagated downstream into the model during training. Modern LLM tokenizers are typically trained on yet another blended dataset with solely text compression as objective, neglecting linguistic research entirely. As such, tokenization can fragment meaningful content, distort sequence relationships, and ultimately degrade the efficiency and quality of model learning. Recent work indicate that linguistically motivated segmentation can improve model training (Hou et al., 2023;Schmidt et al., 2024). Moreover, early work suggests that linguistic token annotation can improve certain modeling capabilities such as in machine translation (Sennrich & Haddow, 2016).
Pre-Tokenization and Tokenizers. Pre-tokenization defines segment boundaries for subword tokenization by normalizing and splitting text (e.g., on whitespace or punctuation) into coherent units. Subword tokenizers, trained with compression-based methods like BPE (Sennrich et al., 2016), inherit biases from their training data: Ahia et al. (2023) report large cross-lingual disparities, with some languages requiring up to five times more tokens for the same content. Tokenizers optimized for one distribution may become inefficient under distribution shifts (Ahia et al., 2023;Deiseroth et al., 2024;Neitemeier et al., 2025). Thus, fragmentation, or more tokens per word, correlates with poorer model performance. Linguistically informed segmentation can improve results: Hou et al. (2023) find morphological splits reduce perplexity and maintain or improve downstream accuracy, while Schmidt et al. (2024) show ignoring morphology in pre-tokenization can harm performance. Recent work explores byte-level or tokenizer-free models such as ByT5 (Xue et al., 2023) and MegaByte (Yu et al., 2023), and T-FREE (Deiseroth et al., 2024), which embeds words via character trigrams, capturing morphological overlaps with smaller embeddings.
Metadata in LLM Pre-training. Pre-training refers to an LLM learning from scratch on large corpora to establish a foundation for downstream adaptation. LLM downstream performance is strongly influenced by the quality of pre-training data (Longpre et al., 2024;Wettig et al., 2024). To improve quality, pre-training data is filtered and deduplicated using metadata typically derived from heuristic approaches (Raffel et al., 2020;Rae et al., 2021) or model-based classifiers (Brown et al., 2020;Xie et al., 2023;Penedo et al., 2024;Li et al., 2024;Su et al., 2025). Further, several approaches have been proposed that, instead of leveraging metadata solely to improve data quality, propagate (2) Linguistic splits are annotated, e.g. with POS and NER tags. (3) Subword tokenization (T sw ) is applied to the linguistic tokens and annotations are aligned to the new splits. (4) Tokens and metadata are embedded, fused together and passed into consecutive transformer blocks. metadata directly into model training. For example, CTRL (Keskar et al., 2019) prepends sourcedomain metadata, Dhingra et al. (2022) prepend timestamps to improve memorization, Liu et al. (2020) add language identifiers for multilingual training, and Khalifa et al. (2024) include document identifiers to improve source attribution. Most recently, Allen-Zhu & Li (2025) demonstrated that prepending a special token to useful data significantly increases the model’s capacity ratio, while Gao et al. (2025) provided empirical evidence by showing a 33% improvement in pre-training efficiency when URL metadata was prepended. While effective, these methods rely on the existing vocabulary to encode metadata, which consumes valuable input token space, and they typically operate at the document level, l
This content is AI-processed based on open access ArXiv data.