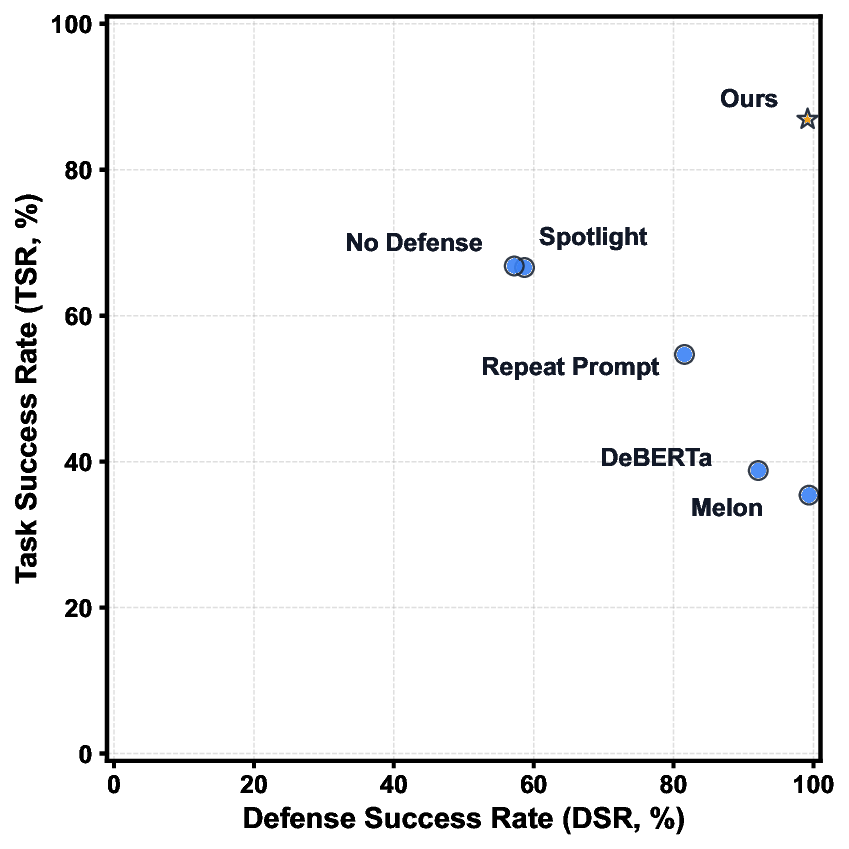
Autonomous Large Language Model (LLM) agents exhibit significant vulnerability to Indirect Prompt Injection (IPI) attacks. These attacks hijack agent behavior by polluting external information sources, exploiting fundamental trade-offs between security and functionality in existing defense mechanisms. This leads to malicious and unauthorized tool invocations, diverting agents from their original objectives. The success of complex IPIs reveals a deeper systemic fragility: while current defenses demonstrate some effectiveness, most defense architectures are inherently fragmented. Consequently, they fail to provide full integrity assurance across the entire task execution pipeline, forcing unacceptable multi-dimensional compromises among security, functionality, and efficiency. Our method is predicated on a core insight: no matter how subtle an IPI attack, its pursuit of a malicious objective will ultimately manifest as a detectable deviation in the action trajectory, distinct from the expected legitimate plan. Based on this, we propose the Cognitive Control Architecture (CCA), a holistic framework achieving full-lifecycle cognitive supervision. CCA constructs an efficient, dual-layered defense system through two synergistic pillars: (i) proactive and preemptive control-flow and data-flow integrity enforcement via a pre-generated "Intent Graph"; and (ii) an innovative "Tiered Adjudicator" that, upon deviation detection, initiates deep reasoning based on multi-dimensional scoring, specifically designed to counter complex conditional attacks. Experiments on the AgentDojo benchmark substantiate that CCA not only effectively withstands sophisticated attacks that challenge other advanced defense methods but also achieves uncompromised security with notable efficiency and robustness, thereby reconciling the aforementioned multi-dimensional trade-off.
💡 Deep Analysis
📄 Full Content
COGNITIVE CONTROL ARCHITECTURE (CCA): A
LIFECYCLE
SUPERVISION
FRAMEWORK
FOR
RO-
BUSTLY ALIGNED AI AGENTS
Zhibo Liang∗
Sichuan University
liangbo825@outlook.com
Tianze Hu∗
hutianze0218@163.com
Zaiye Chen
Mingjie Tang†
Sichuan University
tangrock@gmail.com
ABSTRACT
Autonomous Large Language Model (LLM) agents exhibit significant vulnerabil-
ity to Indirect Prompt Injection (IPI) attacks. These attacks hijack agent behavior
by polluting external information sources, exploiting fundamental trade-offs be-
tween security and functionality in existing defense mechanisms. This leads to
malicious and unauthorized tool invocations, diverting agents from their original
objectives. The success of complex IPIs reveals a deeper systemic fragility: while
current defenses demonstrate some effectiveness, most defense architectures are
inherently fragmented. Consequently, they fail to provide full integrity assurance
across the entire task execution pipeline, forcing unacceptable multi-dimensional
compromises among security, functionality, and efficiency. Our method is pred-
icated on a core insight: no matter how subtle an IPI attack, its pursuit of a ma-
licious objective will ultimately manifest as a detectable deviation in the action
trajectory, distinct from the expected legitimate plan. Based on this, we propose
the Cognitive Control Architecture (CCA), a holistic framework achieving full-
lifecycle cognitive supervision. CCA constructs an efficient, dual-layered defense
system through two synergistic pillars: (i) proactive and preemptive control-flow
and data-flow integrity enforcement via a pre-generated ”Intent Graph”; and (ii)
an innovative ”Tiered Adjudicator” that, upon deviation detection, initiates deep
reasoning based on multi-dimensional scoring, specifically designed to counter
complex conditional attacks. Experiments on the AgentDojo benchmark substan-
tiate that CCA not only effectively withstands sophisticated attacks that challenge
other advanced defense methods but also achieves uncompromised security with
notable efficiency and robustness, thereby reconciling the aforementioned multi-
dimensional trade-off.
1
INTRODUCTION
Large Language Model (LLM) agents are increasingly deployed in autonomous systems, capable of
accomplishing complex real-world tasks through extensive tool usage (Xi et al., 2025; Deng et al.,
2023). However, this growing autonomy introduces critical security challenges: their limited reason-
ing capabilities, particularly their failure to consistently recognize high-risk situations (Zhang et al.,
2024), significantly expands the attack surface. Among numerous threats, Indirect Prompt Injection
(IPI) is particularly concerning. IPI attacks hijack agent behavior by subtly contaminating exter-
nal information sources (Greshake et al., 2023; Debenedetti et al., 2024; Naihin et al., 2023; Zhan
et al., 2024), exploiting the fundamental vulnerability where agents struggle to distinguish between
‘instructions’ and ‘data’ within processing contexts. This allows attackers to hijack the agent’s tool
∗Equal contribution.
†Corresponding author.
1
arXiv:2512.06716v2 [cs.AI] 23 Jan 2026
usage, forcing agents to execute unauthorized operations and deviate from their intended purpose
(OWASP Foundation, 2023). Existing defense mechanisms are caught in a fundamental trade-off
between security and functionality, since overly strict safety rules often limit what the agent can
actually do, while greater autonomy expands the attack surface. The fragmented nature of these
defenses prevents end-to-end integrity assurance, leaving them ill-equipped to counter sophisticated
Indirect Prompt Injection (IPI) attacks. Such attacks succeed by inducing malicious operations,
such as data exfiltration, that are crafted to appear compliant with local task flows. This exposes the
inability of current paradigms to resolve the multi-dimensional trade-offs between security, func-
tionality, and efficiency against these threats (Yan et al., 2025; Yang et al., 2025; Jiang et al., 2025;
Eghtesad et al., 2023).
Current SOTA defense mechanisms are still largely fragmented and static, resulting in a difficult
compromise between security, functionality, and efficiency. Runtime checks (Zhu et al., 2025; Jia
et al., 2024) focus on isolated actions, making them blind to long-range malicious plans. Archi-
tectural defenses (Wu et al., 2024b;a) impose significant performance overhead or functional lim-
itations. Meanwhile, training-time approaches (Wallace et al., 2024; Chen et al., 2025) struggle
to generalize against unseen or optimization-based attacks (Zou et al., 2023). Consequently, these
single-point solutions are inherently ill-equipped to detect sophisticated deceptively aligned agents,
where a deceptive agent’s behavior appears locally coherent while globally deviating from user in-
tent. This phenomenon is not a corner case but rather a scalability challenge that inevitably emerges
as the reasoning and planning capabiliti