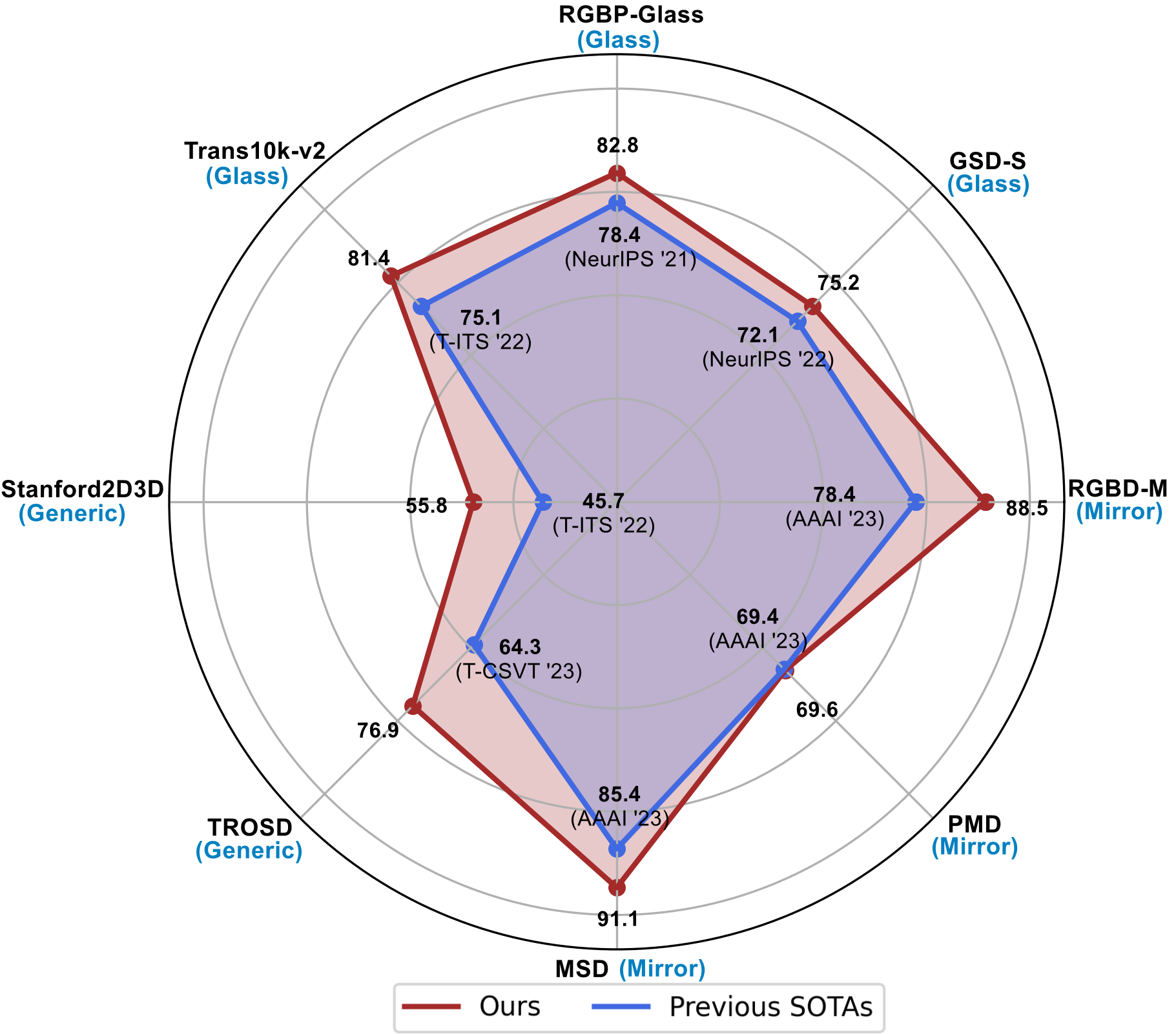
Glass is a prevalent material among solid objects in everyday life, yet segmentation methods struggle to distinguish it from opaque materials due to its transparency and reflection. While it is known that human perception relies on boundary and reflective-object features to distinguish glass objects, the existing literature has not yet sufficiently captured both properties when handling transparent objects. Hence, we propose incorporating both of these powerful visual cues via the Boundary Feature Enhancement and Reflection Feature Enhancement modules in a mutually beneficial way. Our proposed framework, TransCues, is a pyramidal transformer encoder-decoder architecture to segment transparent objects. We empirically show that these two modules can be used together effectively, improving overall performance across various benchmark datasets, including glass object semantic segmentation, mirror object semantic segmentation, and generic segmentation datasets. Our method outperforms the state-of-the-art by a large margin, achieving +4.2% mIoU on Trans10K-v2, +5.6% mIoU on MSD, +10.1% mIoU on RGBD-Mirror, +13.1% mIoU on TROSD, and +8.3% mIoU on Stanford2D3D, showing the effectiveness of our method against glass objects.
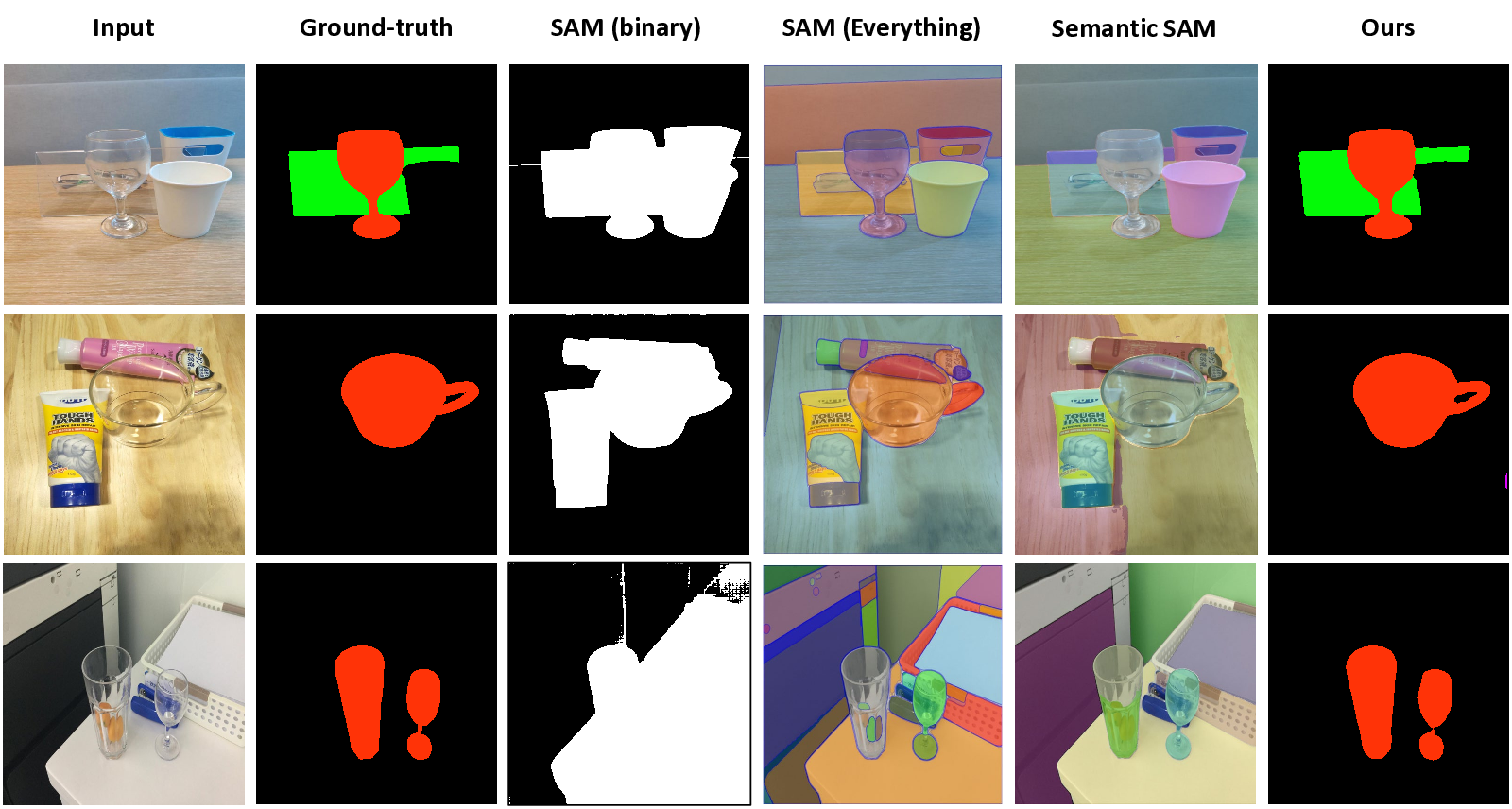
Glass objects, such as windows, bottles, walls, and glass, have presented significant challenges to image segmentation due to their appearances being heavily influenced by the surrounding environment. Also, many robotic systems [73,74,87] rely on sensor fusion techniques that use sonars or lidars, but these methods often struggle to detect transparent objects and misinterpret reflections as actual objects, leading to scan-matching issues. This is because transparent objects exhibit properties of refraction Figure 1. Our method achieves competitive performance compared to previous methods across glass, mirror, and generic segmentation tasks. To maintain fairness, we only compare with methods that use the same input (only RGB image). and reflection, which cause light to be reflected and to appear in surrounding areas, thereby misleading robot sensors and negatively impacting robot navigation, depth estimation, and 3D reconstruction. Hence, visual systems must deal with reflective surfaces, which would help them accurately identify glass barriers for effective collision prevention in workplaces, supermarkets, or hotels. Furthermore, in domestic and professional settings, visual systems should also be able to navigate fragile items such as vases and glasses. Therefore, a practical, robust, cost-effective, vision-based approach for transparent object segmentation is essential. However, current semantic segmentation algorithms [7,75,79,84,92] and even powerful foundation models, such as SAM [29] and Semantic SAM [5,31], were not designed to address transparent and reflective objects, resulting in decreased performance in the presence of such objects. Importantly, the SAM model does not include semantics; in other words, it cannot yield masks with semantic information. The SAM model also presents the challenge of over-segmentation, thereby increasing the likelihood of false positives (see Supplementary for details).
Recent works on the human visual system [28,53,54] prove that “humans rely on specular reflections and boundaries as key indicators of a transparent layer”. Recent methods for segmenting transparent or glass objects have been proposed, along with various strategies to improve performance when dealing with glass objects. These strategies include focusing on the object’s edges [59,74,87], using depth information [55,59], analyzing reflections [35], looking at how light polarizes [45,72], and utilizing the object’s context or semantic information [36]. However, techniques that rely on polarization, depth, and semantic information [36,45,55,59,72] often require specialized equipment to collect data or extensive human labor to label it, which is inefficient. As far as we know, no method has combined both visual cues of boundary and reflection to improve segmentation performance.
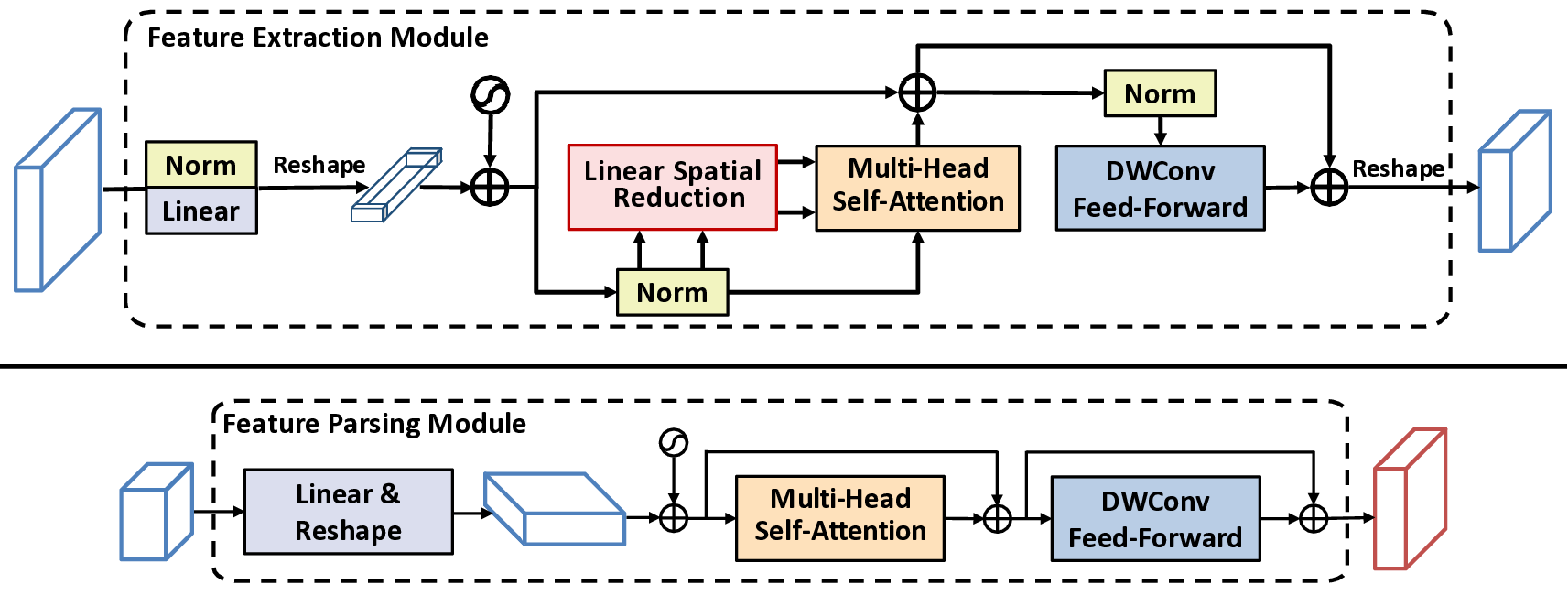
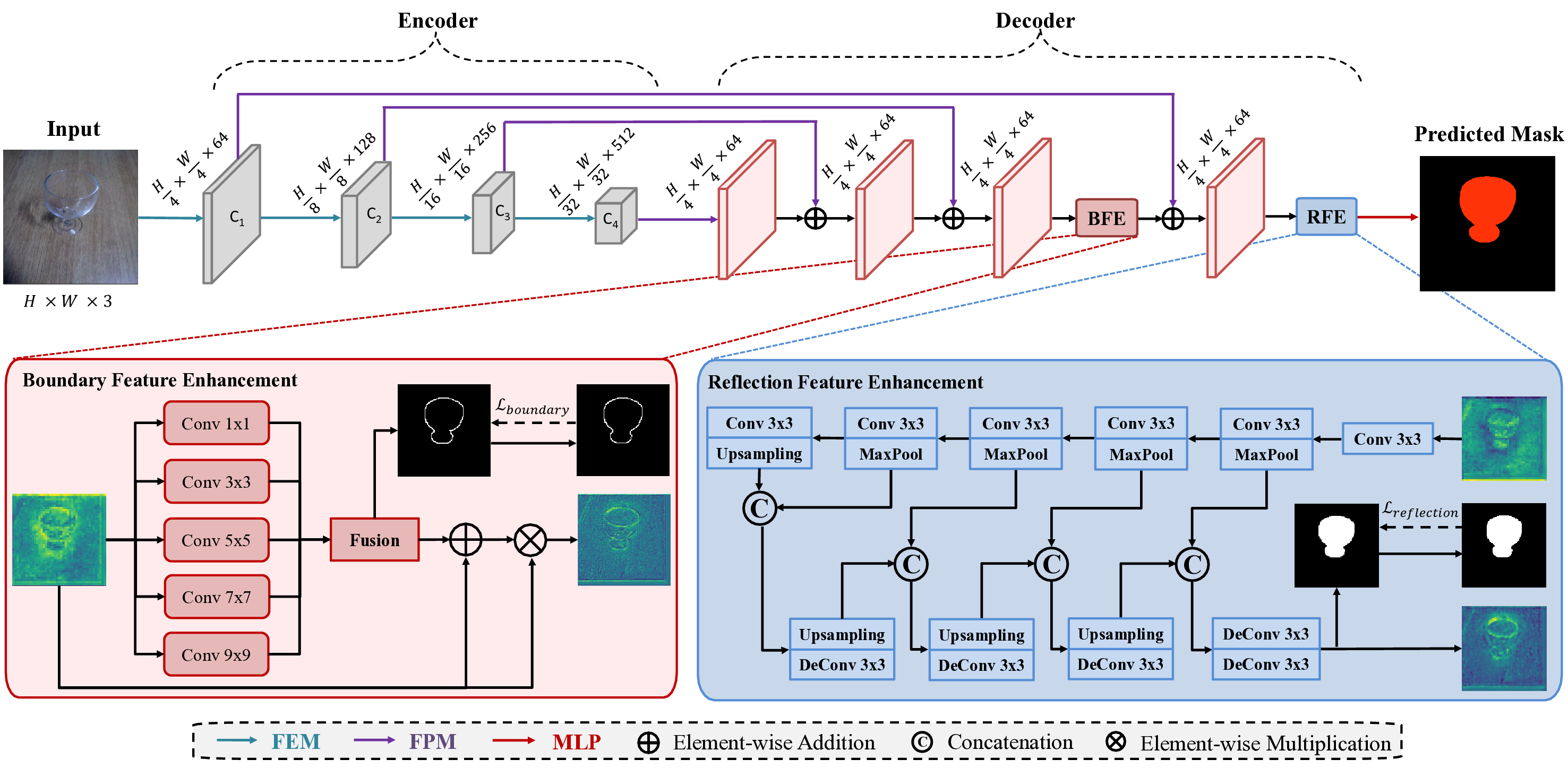
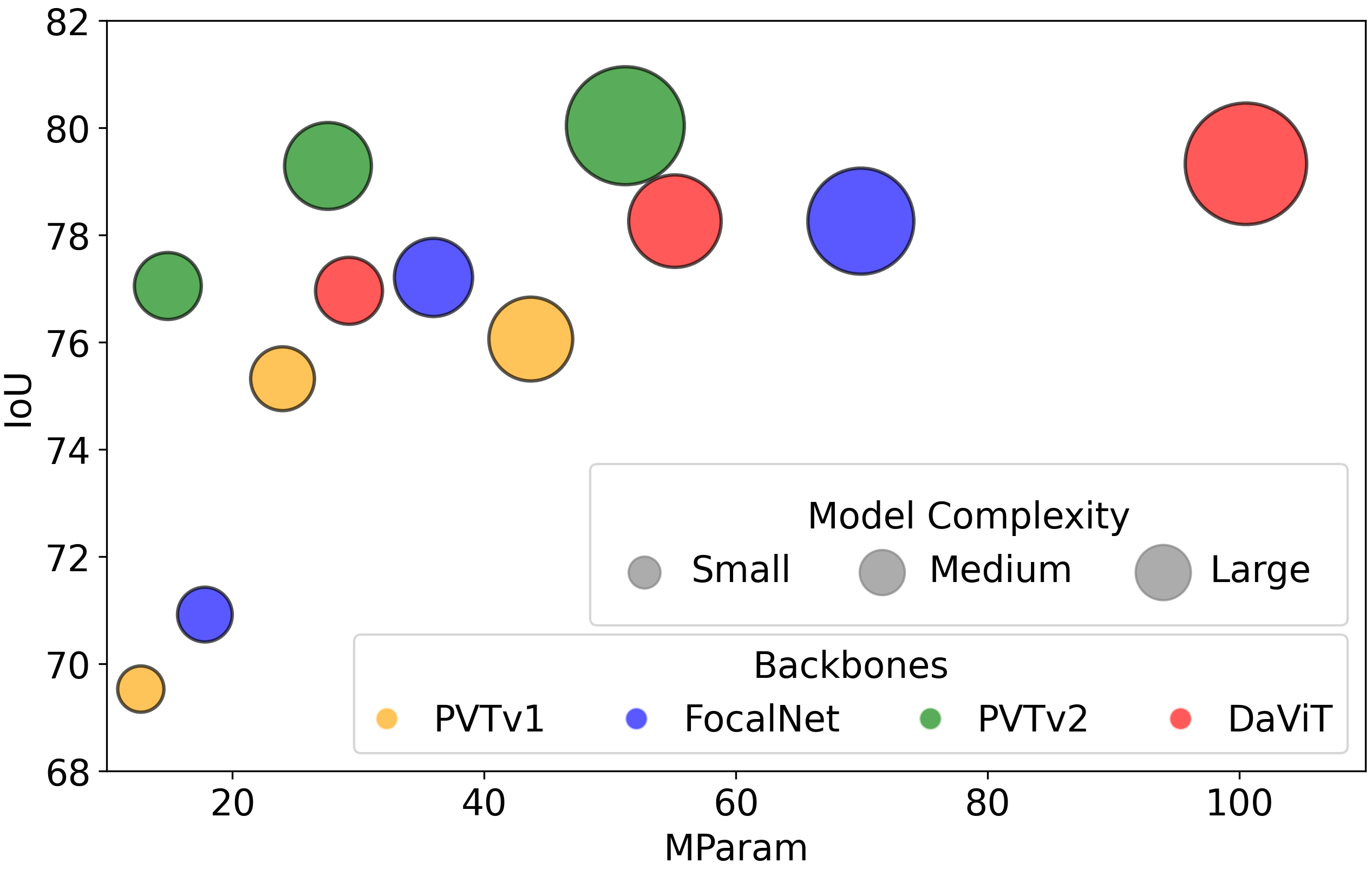
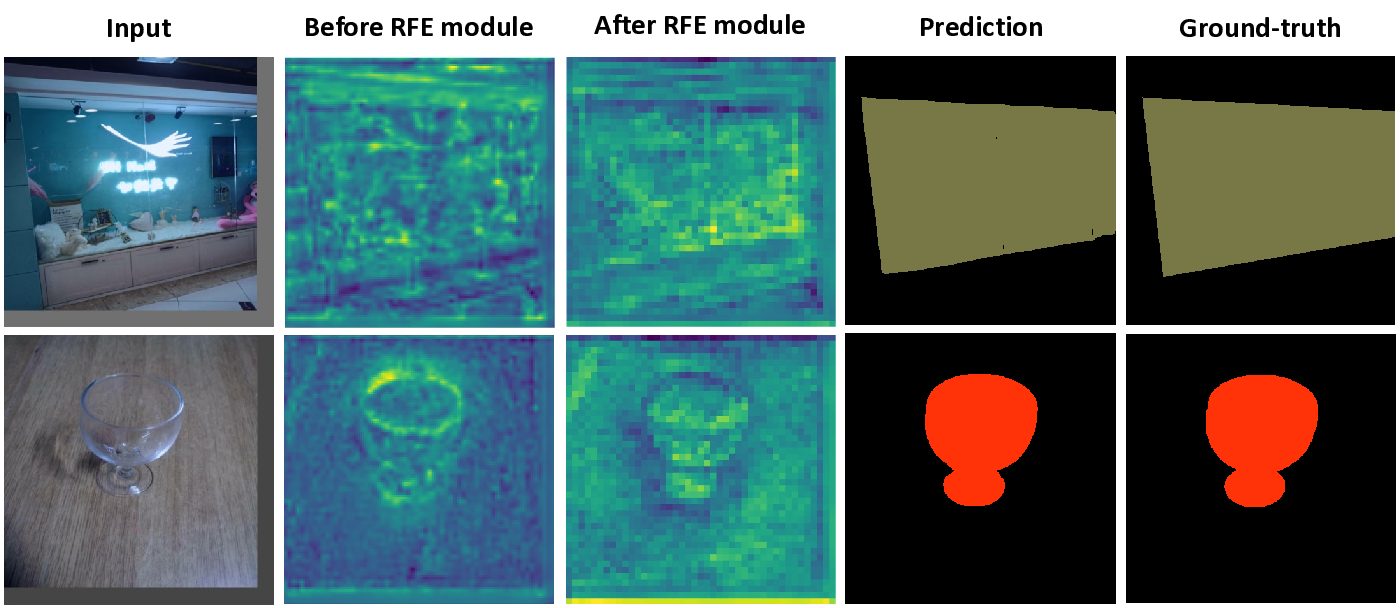
Therefore, we will focus on capturing the two visual cues into the segmentation models: boundary localization for shape inference and reflections for glass surface recognition. We introduce an efficient transformer-based architecture tailored for segmenting transparent and reflective objects along with general objects. Then, our method captures the glass boundaries based on geometric cues and the glass reflections based on appearance cues within an enhanced feature module in our network. In doing so, we developed a Boundary Feature Enhancement (BFE) module to learn and integrate glass-boundary features to improve the localization and segmentation of glass-like regions. We supervise this module with a new boundary loss that uses the Sobel kernel to extract boundaries from the gradients of the predictions and the ground-truth objects’ masks. Then, we introduce a Reflection Feature Enhancement (RFE) module that decomposes reflections into foreground and background layers, providing the network with additional features to distinguish glass-like from non-glass areas. By harnessing the power of transformer-based encoders and decoders, our framework can capture long-range contextual information, unlike previous methods that relied heavily on stacked attention layers [16,78] or on combining CNN backbones with transformers [65,74,92]. These long-range visual cues are essential to reliably identify transparent objects, especially when they lack distinctive textures or share similar content with their surroundings [74]. More importantly, we demonstrate that our method is robust to both transparent object segmentation and generic semantic segmentation tasks, with state-of-the-art performance for both scenarios across various datasets.
In summary, our contributions are as follows:
• We introduce TransCues, an efficient transformer-based segmentation architecture that segments both transparent, reflective, and general objects. • We propose the Boundary Feature Enhancement (BFE) module and a boundary loss that improves the accuracy of glass detection. • We present the Reflection Feature Enhancement (RFE) module, facilitating the differentiatio
This content is AI-processed based on open access ArXiv data.